За последние 5 лет мне приходилось работать над несколькими крупными проектами, и во всех из них неизменным было одно: сервисы релизили в наименее нагруженные часы, релиз подразумевал отказ в обслуживании клиентов, а любые проблемы стоили неимоверно дорого, потому что план отхода подразумевал сложные манипуляции с БД и с сопутствующими сервисами. В этой статье я расскажу, как изменить подход к релизам таким образом, чтобы этот процесс становился абсолютно рутинным и не требовал большого количества ресурсов. Замечу, что это не единственно возможный вариант.
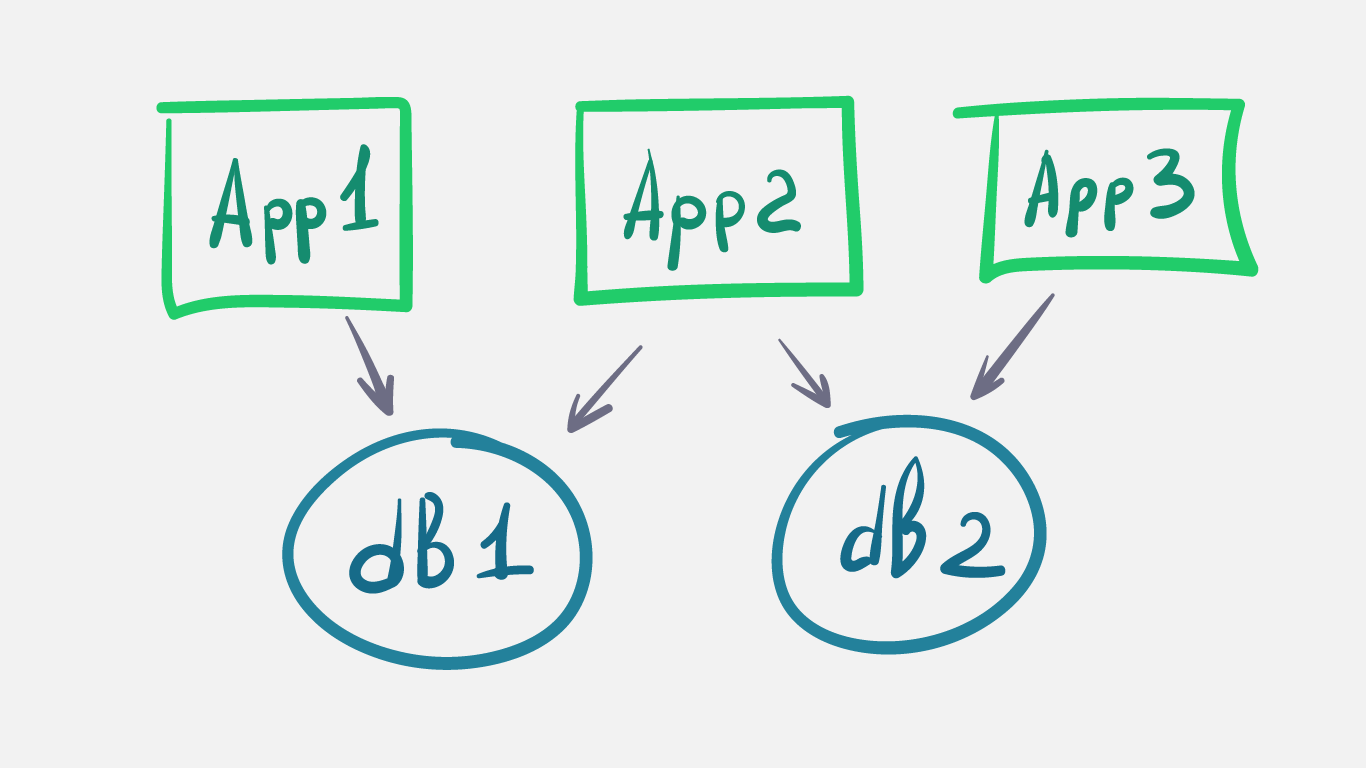
В качестве примера я взял приложение, которое использует PostgreSQL в качестве БД и имеет публичный и приватный REST API. Основным клиентом у нас будет SPA, написанное на Angular. И вот со всем этим добром мы попытаемся взлететь :)
Двумя основными целями всех изменений будут:
Другими словами, мы хотим реализовать вариацию Canary release. Подробнее с концептом Canary можно ознакомиться у Мартина Фаулера.
Основной идеей подхода является сохранение обратной совместимости на одну версию по всем контрактам: БД, REST, MQ и т. д.
Так как мы в ДомКлике используем Kubernetes, то новую версию приложения мы развёртываем с помощью стратегии RollingUpdate, которая запускает новые поды приложения параллельно старым, а старые гасит только после того, как запущены новые. Таким образом это уже canary в облегченном варианте, 2 разные версии приложения работают на одной БД, а запрос от клиента может попасть как на новую, так и на старую версию.
В конечном итоге наш релиз будет выглядеть следующим образом:

Для достижения этих условий мы должны уметь делать следующее:
В этой статье я не буду рассматривать проблемы одновременного запуска нескольких экземпляров приложения, которые не связаны со схемой БД.
Обратная совместимость по БД нас интересует по следующим причинам:
Если мы можем погасить сервис, то миграция данных и БД выглядит следующим образом и проводится за один подход:
Если же нам необходима обратная совместимость, то процедура разбивается на несколько подряд идущих релизов, потому что на каждом этапе нам необходимо поддерживать обратную совместимость. Рассмотрим несколько примеров изменений с поддержкой обратной совместимости.
Обозначения и условия:
Предположим, что сейчас мы имеем следующую таблицу:
На ранней стадии разработки требовалось, чтобы каждый пользователь сервиса указывал свой возраст, но от этого решили отказаться, и колонка
Если бы мы не думали об обратной совместимости, то:

И всё это делается в рамках одного релиза.
Если же мы сохраняем обратную совместимость, то процесс немного усложняется, и поставка новой функциональности разбивается на несколько релизов:
Через какие этапы мы проходим, чтобы удостовериться, что всё в порядке:
В этой версии мы продолжаем использовать колонку, но только с тем ограничением, что в БД может быть NULL, хотя пока что она записана как NOT NULL. Это необходимо для того, чтобы в случае отката версии app2 (в которой уже могут быть null) мы не получили ошибок.
Следующая версия:
Здесь мы убрали ограничение с колонки и перестали записывать ее в БД. Откат на предыдущую версию также возможен, ведь мы подготовились к возможному отсутствию значения в таблице.
Следующая версия:
В этой версии мы полностью изменили схему БД, а исходный код больше не работает с колонкой, при этом мы еще можем откатиться на старую версию.
Эта миграция ощутимо сложнее, чем может показаться на первый взгляд. Рассмотрим такую структуру:
У нас есть таблица пользователя, в которой есть колонка
Чтобы провести релиз без даунтайма и с обратной совместимостью, нам нужно сделать следующее:
Релиз 1 (app1, db1):
После релиза этой версии мы должны убедиться, что для всех новых записей и тех, в которых менялась
Релиз 2 (app2, db2):
Релиз 3 (app3, db3):
Приведенные выше примеры не исчерпывающие, и каждая конкретная ситуация требует отдельного планирования и подготовки к миграциям.
Но в рамках миграции схемы БД существует еще одна проблема, которая не может быть не затронута хотя бы поверхностно: блокировки БД в момент миграции. Надо не забывать, что в момент миграции БД мы также обслуживаем пользователей, и неправильно составленная миграция может как не выполниться (хотя без нагрузки всё будет хорошо), так и «положить» приложение. Чтобы грамотно составлять миграции предлагаю ознакомиться с несколькими статьями:
Со знанием всего этого мы получаем схему, когда приложение обратно совместимо с БД, но у нас есть еще несколько точек взаимодействия с другими сущностями, которые до сих пор мешают нам проводить бесшовные релизы.
Как я уже говорил выше, у нас есть SPA, написанное на Angular, которое общается с нашим бэкендом посредством REST API. Весь фронтенд хостится отдельно от бэкенда и, в целом, независим от него. Обеспечение обратной совместимости по API следует тем же базовым принципам, что и по схеме БД, но сильно отличается в деталях.
Сам по себе подход, когда фронтовое приложение сразу же полностью загружается пользователю и общается с бэкендом посредством REST, доказал свою практичность, но для разработки это принесло дополнительные проблемы. Основные из них:
Если у нас есть сервис типа CRM или какой-либо соцсети, то пользователи могут неделями не перезагружать страницу, что не позволяет нам оперативно доставлять обновления. Для решения этой проблемы можно использовать подход, когда фронтенд периодически опрашивает сервер о текущей актуальной версии, и в случае расхождения с текущей версией предлагает пользователю перезагрузить страницу (но не делает этого автоматически, никто не любит принудительные обновления во время работы). Также надо корректно настроить кэширование, подходящее для всех браузеров и позволяющее оперативно инвалидировать кэш.
Версионирование REST API довольно подробно описано в многочисленных руководствах, но очень часто мы этим пренебрегаем, потому что у нас только один клиент (наше фронтовое приложение).
Создание новой версии REST API занимает значительное время и ведет к дублированию и временной поддержке старого кода. Поэтому часто изменения производятся в существующем API: добавляются/убираются параметры, меняются форматы ответов и т. д. Соответственно, к этим изменениям готовится новая версия фронтенда, которая должна быть развёрнута «одновременно» с бэкендом.
Часто такие изменения оправданы и мы действительно можем не обработать корректно небольшое число запросов. Но в случае с SPA, как я писал выше, это становится сложнее, потому что фронтенд может долго не обновляться и несовместимые изменения просто сломают работу всего приложения.
Чтобы избежать этого, стоит использовать следующие подходы:
Разговор об обратной совместимости будет неполным, если не упомянуть про feature-management.
Первое, что приходит на ум, это kill-switches, которые позволяют быстро включать/выключать функциональность без переразвёртывания приложения. Kill-switch, по сути, это просто булево значение
Feature-management через feature-flags позволяет нам делать более хитрые изменения, которые помогают избежать «факапов» в проде.
Важным заметить, что мы можем предоставлять feature-flags и для фронта, при этом вычисляться они будут на бэке.
С помощью этого подхода мы существенно упрощаем как релиз, так и дальнейшую поддержку приложения. Мы можем:
Но этот подход, как и любой другой, требует свой плату, а именно:
В качестве примера я взял приложение, которое использует PostgreSQL в качестве БД и имеет публичный и приватный REST API. Основным клиентом у нас будет SPA, написанное на Angular. И вот со всем этим добром мы попытаемся взлететь :)
Двумя основными целями всех изменений будут:
- релиз без даунтайма;
- возможность без проблем вернуться на предыдущую версию приложения.
Другими словами, мы хотим реализовать вариацию Canary release. Подробнее с концептом Canary можно ознакомиться у Мартина Фаулера.
Основной идеей подхода является сохранение обратной совместимости на одну версию по всем контрактам: БД, REST, MQ и т. д.
Так как мы в ДомКлике используем Kubernetes, то новую версию приложения мы развёртываем с помощью стратегии RollingUpdate, которая запускает новые поды приложения параллельно старым, а старые гасит только после того, как запущены новые. Таким образом это уже canary в облегченном варианте, 2 разные версии приложения работают на одной БД, а запрос от клиента может попасть как на новую, так и на старую версию.
В конечном итоге наш релиз будет выглядеть следующим образом:
- Развёртывание новой версии приложения параллельно с текущей версией на одной и той же БД, а клиентский трафик балансируется между разными экземплярами. В это время все старые клиенты продолжают работать как с новой, так и со старой версией.
- Проверка работоспособности новой версии.
- Релиз сопутствующих сервисов, которые используют новый API приложения.
- В случае каких-либо проблем с новой версией должен быть выполнен быстрый откат на предыдущую версию. Откат подразумевает только исполняемый код.
Для достижения этих условий мы должны уметь делать следующее:
- Возможность запуска приложения в несколько экземпляров на одной БД с балансированием трафика между экземплярами.
- Обратная совместимость приложения по всем существующим контрактам: схема БД, REST API, MQ и т. д.
- И feature-toggle, как опциональная возможность.
В этой статье я не буду рассматривать проблемы одновременного запуска нескольких экземпляров приложения, которые не связаны со схемой БД.
Совместимость по БД
Обратная совместимость по БД нас интересует по следующим причинам:
- Возможность развёртывания приложения без остановки (canary release, когда у нас одновременно оказываются запущены две версии приложения).
- Откат новой версии приложения без отката БД.
Если мы можем погасить сервис, то миграция данных и БД выглядит следующим образом и проводится за один подход:
- Изменение схемы БД в планируемую.
- Миграция старых данных в новые сущности.
- Навешивание ограничений.
- Удаление больше ненужных колонок и таблиц.
Если же нам необходима обратная совместимость, то процедура разбивается на несколько подряд идущих релизов, потому что на каждом этапе нам необходимо поддерживать обратную совместимость. Рассмотрим несколько примеров изменений с поддержкой обратной совместимости.
Обозначения и условия:
- appN — приложение с версией N, где 0 — базовая версия до всех изменений;
- dbN — схема БД N, где 0 — базовая схема до всех изменений;
- новая версия развёртывается как Rolling update, то есть текущая версия продолжает работать в момент релиза новой версии;
- новая версия выполняет миграцию схемы БД до того, как начинает обслуживать клиентов;
- миграции БД выполняется только самим приложением, то есть смена схемы БД подразумевает релиз новой версии приложения (это не ограничение подхода).
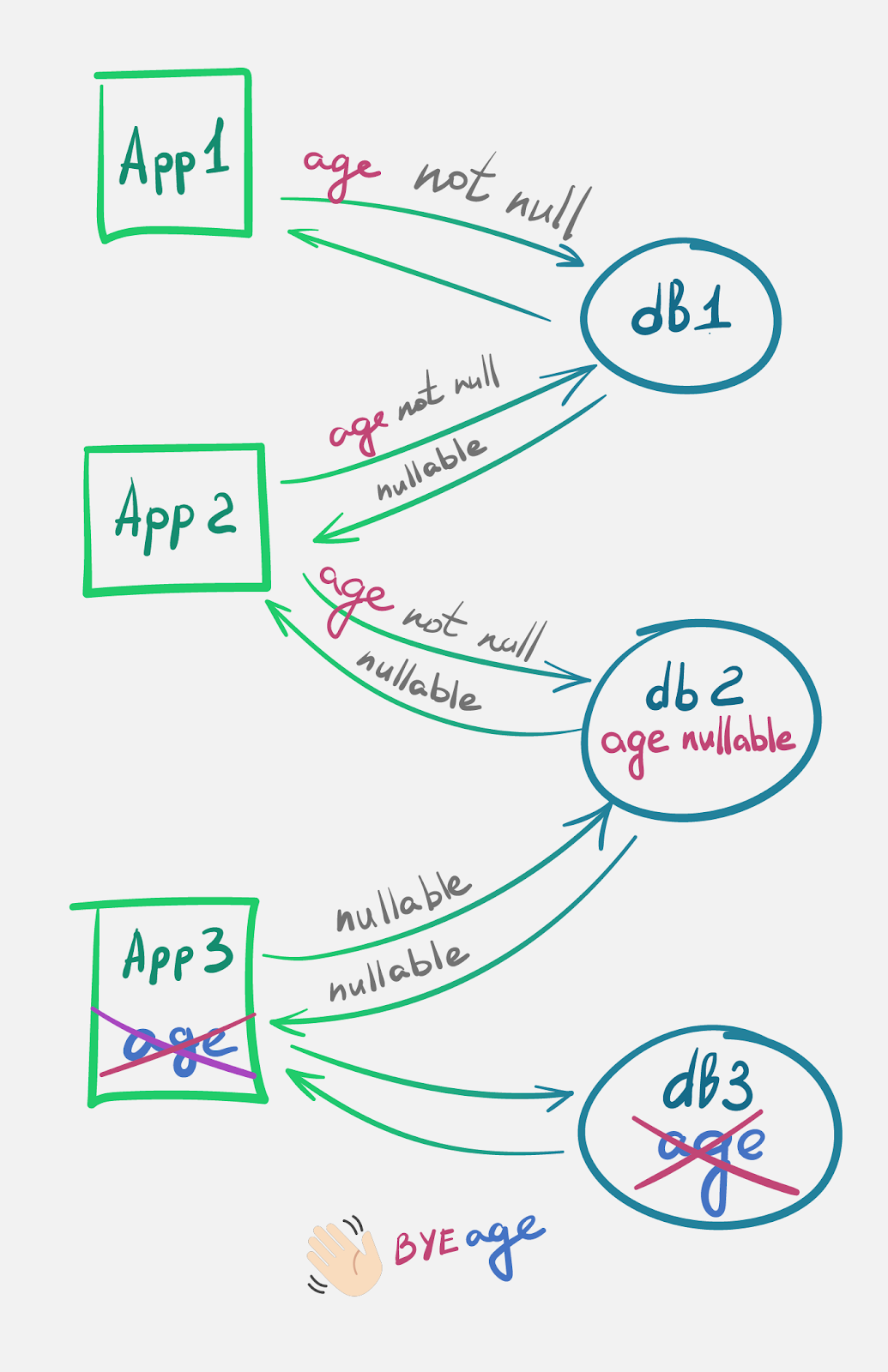
Удаление колонки
Предположим, что сейчас мы имеем следующую таблицу:
CREATE TABLE account( id serial PRIMARY KEY, username VARCHAR (50) UNIQUE NOT NULL, password VARCHAR (50) NOT NULL, email VARCHAR (355) UNIQUE NOT NULL, age INT NOT NULL );
На ранней стадии разработки требовалось, чтобы каждый пользователь сервиса указывал свой возраст, но от этого решили отказаться, и колонка
age нам больше не нужна.Если бы мы не думали об обратной совместимости, то:
- перестали использовать колонку
ageв коде приложения; - удалили колонку из БД.
И всё это делается в рамках одного релиза.
Если же мы сохраняем обратную совместимость, то процесс немного усложняется, и поставка новой функциональности разбивается на несколько релизов:
| Релиз 1 | Релиз 2 | Релиз 3 |
|
Снятие ограничения NOT NULL с колонки age.Перестаем использовать age в коде приложения. |
|
Через какие этапы мы проходим, чтобы удостовериться, что всё в порядке:
- app0-db1
- app0-app1-db1
- app1-db1
В этой версии мы продолжаем использовать колонку, но только с тем ограничением, что в БД может быть NULL, хотя пока что она записана как NOT NULL. Это необходимо для того, чтобы в случае отката версии app2 (в которой уже могут быть null) мы не получили ошибок.
Следующая версия:
- app1-db1
- app1-app2-db2
- app2-db2
Здесь мы убрали ограничение с колонки и перестали записывать ее в БД. Откат на предыдущую версию также возможен, ведь мы подготовились к возможному отсутствию значения в таблице.
Следующая версия:
- app2-db2
- app2-app3-db3
- app3-db3
В этой версии мы полностью изменили схему БД, а исходный код больше не работает с колонкой, при этом мы еще можем откатиться на старую версию.
Переименование колонки (сократить, упростить, все уже всё поняли)
Эта миграция ощутимо сложнее, чем может показаться на первый взгляд. Рассмотрим такую структуру:
CREATE TABLE account( id serial PRIMARY KEY, username VARCHAR (50) UNIQUE NOT NULL, first_name VARCHAR (50) NOT NULL, surname VARCHAR (50) NOT NULL, password VARCHAR (50) NOT NULL, email VARCHAR (355) UNIQUE NOT NULL );
У нас есть таблица пользователя, в которой есть колонка
surname. Предположим, что нас не устраивает ее название и мы решили сменить его на last_name. В случае, если мы можем погасить сервис, то процесс миграции выглядит довольно просто:- Создаем новую колонку
last_name. - Копируем в нее значения из
surname. - Добавляем на нее ограничение NOT NULL.
- Меняем исходный код таким образом, чтобы он работал с новой колонкой.
Чтобы провести релиз без даунтайма и с обратной совместимостью, нам нужно сделать следующее:
Релиз 1 (app1, db1):
- Создаем колонку
last_nameв БД без ограничения NOT NULL. - Снимаем ограничение NOT NULL с
surname. - В коде приложения начинаем записывать значения как в
surname, так и вlast_name. - Чтение должно быть из
last_name, но колонкаsurnameдолжна быть как fallback в случае, еслиlast_nameне содержит значения.
После релиза этой версии мы должны убедиться, что для всех новых записей и тех, в которых менялась
surname, колонка last_name содержит значения, а surname всё также остается заполненной.Релиз 2 (app2, db2):
- Копируем данные из
surnameвlast_nameдля всех записей. - Перестаем записывать и читать данные в
surname, потому чтоlast_nameтеперь всегда содержит корректные значения. - Добавляем ограничение NOT_NULL на
last_name.
Релиз 3 (app3, db3):
- Удаляем колонку
surnameиз БД.
Приведенные выше примеры не исчерпывающие, и каждая конкретная ситуация требует отдельного планирования и подготовки к миграциям.
Но в рамках миграции схемы БД существует еще одна проблема, которая не может быть не затронута хотя бы поверхностно: блокировки БД в момент миграции. Надо не забывать, что в момент миграции БД мы также обслуживаем пользователей, и неправильно составленная миграция может как не выполниться (хотя без нагрузки всё будет хорошо), так и «положить» приложение. Чтобы грамотно составлять миграции предлагаю ознакомиться с несколькими статьями:
- https://medium.com/braintree-product-technology/postgresql-at-scale-database-schema-changes-without-downtime-20d3749ed680
- https://leopard.in.ua/2016/09/20/safe-and-unsafe-operations-postgresql#.Xtsrep4zZ95
- https://www.braintreepayments.com/blog/safe-operations-for-high-volume-postgresql/
Со знанием всего этого мы получаем схему, когда приложение обратно совместимо с БД, но у нас есть еще несколько точек взаимодействия с другими сущностями, которые до сих пор мешают нам проводить бесшовные релизы.
Frontend REST API
Как я уже говорил выше, у нас есть SPA, написанное на Angular, которое общается с нашим бэкендом посредством REST API. Весь фронтенд хостится отдельно от бэкенда и, в целом, независим от него. Обеспечение обратной совместимости по API следует тем же базовым принципам, что и по схеме БД, но сильно отличается в деталях.
SPA
Сам по себе подход, когда фронтовое приложение сразу же полностью загружается пользователю и общается с бэкендом посредством REST, доказал свою практичность, но для разработки это принесло дополнительные проблемы. Основные из них:
- Обновление фронтенда с внесением новой функциональности или исправлением ошибок, возможно, критических.
- Несовместимые изменения в API сервиса.
Изменения только фронтенда
Если у нас есть сервис типа CRM или какой-либо соцсети, то пользователи могут неделями не перезагружать страницу, что не позволяет нам оперативно доставлять обновления. Для решения этой проблемы можно использовать подход, когда фронтенд периодически опрашивает сервер о текущей актуальной версии, и в случае расхождения с текущей версией предлагает пользователю перезагрузить страницу (но не делает этого автоматически, никто не любит принудительные обновления во время работы). Также надо корректно настроить кэширование, подходящее для всех браузеров и позволяющее оперативно инвалидировать кэш.
Изменения в REST API
Версионирование REST API довольно подробно описано в многочисленных руководствах, но очень часто мы этим пренебрегаем, потому что у нас только один клиент (наше фронтовое приложение).
Создание новой версии REST API занимает значительное время и ведет к дублированию и временной поддержке старого кода. Поэтому часто изменения производятся в существующем API: добавляются/убираются параметры, меняются форматы ответов и т. д. Соответственно, к этим изменениям готовится новая версия фронтенда, которая должна быть развёрнута «одновременно» с бэкендом.
Часто такие изменения оправданы и мы действительно можем не обработать корректно небольшое число запросов. Но в случае с SPA, как я писал выше, это становится сложнее, потому что фронтенд может долго не обновляться и несовместимые изменения просто сломают работу всего приложения.
Чтобы избежать этого, стоит использовать следующие подходы:
- Вносить в API только обратно совместимые изменения. Если мы меняем конкретные параметры одного запроса, то не навешивать ограничения обязательности и т. д. Если мы вводим новый API, то не удалять старый.
- Необходимо понимать, сколько пользователей какие версии используют. Предположим, что мы создали вторую версию метода получения данных о пользователе, и сохранили при этом первую версию. Мы не можем просто так удалить первую версию, потому что мы не знаем, сколько человек осталось на старой версии API. Для этого необходимо иметь конкретные метрики и сегментах пользователей, и уже на основе этих данных принимать решения об отказе от старого API.
- Предложение пользователю о загрузке новой версии приложения. Как уже говорил выше, эта функциональность не должна быть принудительной, потому что пользователь может активно пользоваться приложением, а неожиданная перезагрузка будет воспринята очень негативно.
Feature-management
Разговор об обратной совместимости будет неполным, если не упомянуть про feature-management.
Первое, что приходит на ум, это kill-switches, которые позволяют быстро включать/выключать функциональность без переразвёртывания приложения. Kill-switch, по сути, это просто булево значение
enabled/disabled. С помощью kill-switch мы можем перейти к парадигме release ≠ deploy, что позволяет нам избежать стресса релиза и сделать его более контролируемым.Feature-management через feature-flags позволяет нам делать более хитрые изменения, которые помогают избежать «факапов» в проде.
- Тестирование в проде. Звучит очень страшно, но на самом деле это довольно полезная возможность. Часто мы не можем воспроизвести полное окружение в среде разработки, и полноценное тестирование возможно только в боевом окружении. При таком подходе мы можем выбирать группы и количество пользователей, которым «выпала честь» попробовать новую функциональность. В таком варианте мы получаем абсолютно контролируемое тестирование, а не тысячи одновременно проблемных пользователей.
- Контролируемые миграции. Переключение на новые версии смежных сервисов, смена адресов других сервисов и т. д.
- A/B-тестирование, по сути немного схоже с тестированием в проде, но позволяет нам проверять бизнесовые гипотезы.
Важным заметить, что мы можем предоставлять feature-flags и для фронта, при этом вычисляться они будут на бэке.
Что в итоге?
С помощью этого подхода мы существенно упрощаем как релиз, так и дальнейшую поддержку приложения. Мы можем:
- релизиться в любой момент, не беспокоясь за отказ в обслуживании клиентов;
- откатить приложение на стабильную версию в случае каких-либо проблем в новой версии;
- плавно развернуть новую функциональность в удобное для нас время, а также отключать её в случае неработоспособности или отказа сегмента.
Но этот подход, как и любой другой, требует свой плату, а именно:
- увеличивается время разработки;
- изменения требуют более вдумчивого планирования;
- в код вносится техдолг, который подразумевает его периодическую чистку;
- в некоторых случаях новая функциональность дольше доставляется в прод.
