
Автоматизация сопровождает нас повсюду и является спутником и признаком прогресса, снимая с человека необходимость выполнения рутинных действий и принятия рутинных решений. Но для принятия решений о будущем необходима информация о прошлом, поэтому автоматизация неизбежно связана с необходимостью накапливать, хранить и обрабатывать данные, чем и занимаются базы данных и системы управления базами данных. Объём данных не уменьшается, а только увеличивается, поэтому я всегда говорю своим студентам:
Что и зачем тут вообще
В этой статье собран мой опыт обучения студентов программистских специальностей проектированию реляционных баз данных. Конечно, по этой теме написана пара-тройка монографий, множество книг, словарь статей, список интерактивных курсов, но у меня есть своё оправдание тому, что я собираюсь написать ещё одну статью (TODO надо не забыть придумать и вставить сюда это оправдание перед публикацией). Заранее согласен с теми, кто скажет: «Зачем, если уже всё есть», – но у меня есть основания думать, что статья окажется полезной, и её оценят как минимум те, кто очень хочет получить от меня положительную оценку в зачётку. Да, всё, что написано здесь, можно прочитать в другом месте, поэтому если вы – не мой студент, но всё-таки решите потратить своё время на чтение – вы сами себе злобный Буратино, на меня не обижайтесь.
Я преподаватель и я люблю свою работу. Мне нравится разбираться в проблеме самому и потом объяснять её другим так, чтобы было понятно. Мне доставляет кайф придумывание способов донесения сложной идеи до очередного юного носителя естественной нейронной сети. Не заходит один способ – придумаем другой, не работает другой – придумаем третью аналогию, это такой своеобразный, особенный преподавательский азарт. Разум каждого человека уникален, у каждого из нас свой собственный способ мышления. Нельзя просто так взять и дать человеку знания, нужно провести его тернистой дорогой познания так, чтобы он самостоятельно отжёг в своём мозгу правильные дорожки из аксонов. В идеале, ученик должен сам изобрести всю теорию от начала до конца, а моя задача – подталкивать и тормозить его так, чтобы очевидные решения рождались у него как бы сами собой.
Здесь не будет IDEF1X-диаграмм «сущность-связь». Мой личный опыт показывает, что при обучении проектированию реляционных баз данных они только вредят, потому что на них полностью отсутствуют сами данные. Умение видеть за диаграммами хранимые данные приходит гораздо позже (и, увы, не ко всем). Поэтому мы будем просто рисовать таблички с данными и учиться видеть проблемы в хранимых данных, и, что ещё важнее, видеть потенциальные проблемы в тех данных, которые ещё не появились.
Кроме этого, я не собираюсь описывать самую общую теорию реляционных баз данных, поэтому неизбежно буду упрощать, забывать, курощать, низводить и дуракавалять. Заранее согласен с теми, кто считает, что это неправильно, контрпродуктивно и антиметодично. Здесь и сейчас я хочу научить хранить информацию реляционным образом, не более того.
Я специально не начинаю обучение реляционным базам данных с громких слов про ссылочную целостность, целостную ссылочность, избыточность, недостаточность, изостаточность, недобыточность, аномалии, отношения, справочники, ключи, нормальные формы и так далее – ко всем этим идеям нужно прийти через практику. Самое вредное, что можно придумать – это учить правила типа «В любой таблице должен быть столбец ID», без понимания того, что означают эти правила, и вообще, правила ли это.
Кроме этого, я ничего не говорю про отношения, нормальные формы отношений, модальность отношений, и так далее, потому что являюсь консерватором, и, несмотря на некоторые модные веяния, до сих пор продолжаю считать, что нормальные человеческие отношения 1-к-1 являются основой этичного поведения, хотя в художественной литературе описаны и драматические, почти нормальные, отношения 1-ко-многим. Отношения многие-ко-многим мы отринем, как вопиюще ненормальные и неэтичные.
Я преподаватель и я люблю свою работу. Мне нравится разбираться в проблеме самому и потом объяснять её другим так, чтобы было понятно. Мне доставляет кайф придумывание способов донесения сложной идеи до очередного юного носителя естественной нейронной сети. Не заходит один способ – придумаем другой, не работает другой – придумаем третью аналогию, это такой своеобразный, особенный преподавательский азарт. Разум каждого человека уникален, у каждого из нас свой собственный способ мышления. Нельзя просто так взять и дать человеку знания, нужно провести его тернистой дорогой познания так, чтобы он самостоятельно отжёг в своём мозгу правильные дорожки из аксонов. В идеале, ученик должен сам изобрести всю теорию от начала до конца, а моя задача – подталкивать и тормозить его так, чтобы очевидные решения рождались у него как бы сами собой.
Здесь не будет IDEF1X-диаграмм «сущность-связь». Мой личный опыт показывает, что при обучении проектированию реляционных баз данных они только вредят, потому что на них полностью отсутствуют сами данные. Умение видеть за диаграммами хранимые данные приходит гораздо позже (и, увы, не ко всем). Поэтому мы будем просто рисовать таблички с данными и учиться видеть проблемы в хранимых данных, и, что ещё важнее, видеть потенциальные проблемы в тех данных, которые ещё не появились.
Кроме этого, я не собираюсь описывать самую общую теорию реляционных баз данных, поэтому неизбежно буду упрощать, забывать, курощать, низводить и дуракавалять. Заранее согласен с теми, кто считает, что это неправильно, контрпродуктивно и антиметодично. Здесь и сейчас я хочу научить хранить информацию реляционным образом, не более того.
Я специально не начинаю обучение реляционным базам данных с громких слов про ссылочную целостность, целостную ссылочность, избыточность, недостаточность, изостаточность, недобыточность, аномалии, отношения, справочники, ключи, нормальные формы и так далее – ко всем этим идеям нужно прийти через практику. Самое вредное, что можно придумать – это учить правила типа «В любой таблице должен быть столбец ID», без понимания того, что означают эти правила, и вообще, правила ли это.
Кроме этого, я ничего не говорю про отношения, нормальные формы отношений, модальность отношений, и так далее, потому что являюсь консерватором, и, несмотря на некоторые модные веяния, до сих пор продолжаю считать, что нормальные человеческие отношения 1-к-1 являются основой этичного поведения, хотя в художественной литературе описаны и драматические, почти нормальные, отношения 1-ко-многим. Отношения многие-ко-многим мы отринем, как вопиюще ненормальные и неэтичные.
Мы сегодня будем играть в разработку базы данных кинотеатра. Все были в кинотеатрах, хотя, с нашей пандемией, возможно, и подзабыли уже, как это делается – но вы помните, что там всё автоматизировано, а значит, база данных обязательно есть.
Здесь мы сделаем неожиданный прыжок и начнём говорить про реляционные базы данных, хотя «база данных» совсем не равно «реляционная база данных», но нас просто
Реляционные базы данных хранят все данные в виде таблиц. Правильно спроектированные таблицы позволяют избежать потенциальных проблем, поэтому для начала надо научиться видеть эти самые проблемы. Давайте попробуем описать в виде таблиц данные, которые хранит (ну или мог бы хранить) какой-нибудь обычный кинотеатр. Очевидно, что для нормального функционирования системы бронирования и продажи билетов и проведения хоть какой-нибудь аналитики, нужно информацию об этих продаваемых билетах где-то хранить.
Попробуем представить, как может выглядеть хранение информации о проданных билетах в виде таблицы. Мы намеренно не будем пользоваться никаким там ораклом, эмэсэскуэлом, постгресом или даже акцессом, – только

Мы начнём с такой таблицы и посмотрим, куда она нас приведёт. Должна получиться логичная, непротиворечивая цепочка рассуждений, которая должна нас привести от такого экселя или бумажки к нормальной БД, и на этом пути не должно быть заклинаний типа «справочники нужны» или «больше таблиц» или «приведём эту таблицу к третьей нормальной форме». Просто посмотрите на эту таблицу и спросите себя: «А какие могут быть в ней проблемы с данными?»
И главное, прочувствуйте разницу: какие проблемы с данными уже есть, а какие проблемы с данными в такой структуре могут быть. Вот, например, внесу я такую информацию в эту таблицу. Какую проблему вы уже в ней видите?

Очень сомнительно, что в этом кинотеатре есть ряд 1313 и место 131313. Скорее всего, это ошибка. Ещё пример:

Так кто режиссёр у фильма «Форрест Гамп» и какая длительность у этого фильма? Следующий пример:

Что-то сомнительно, что в одном и том же зале в одно и то же время могут начинаться два разных фильма, не так ли? А вот тут?

Я что-то не понимаю, это один и тот же фильм, или нет?
Можно накидать ещё несколько таких примеров, но общая идея, я надеюсь, уже ясна: с нашей таблицей что-то не так. То и дело в нашей таблице оказываются кривые данные, но, возможно, причиной этого являются кривые руки того, кто в эту таблицу заносит данные?
Это очень часто используемый аргумент, кстати. «Чтобы данные не были кривыми, не надо просто заносить в базу данных кривые данные», – скажет кто-то. Другой скажет, что всё равно эту таблицу будет заполнять не человек, а какая-то программа, и мы, как программисты, напишем эту программу так, чтобы она не принимала и не заполняла кривые данные. Понятно, что ни первое, ни второе решение не годится, и это именно нашей проблемой и задачей является создание такой базы данных, куда просто «не влезут» кривые данные.
Мораль
Нельзя полагаться и рассчитывать на то, что кто-то будет определённым образом работать с вашей базой данных. Она должна быть такой, чтобы испортить её нельзя было никакой работой.
Какие у нас для этого механизмы есть, мы поймём чуть позже, а пока снова посмотрим на нашу таблицу.
Как будто бы это таблица с билетами. Но как быть, если ни одного билета ещё не продано? У нас получается, что фильма вообще не существует, пока нет ни одного билета на этот фильм, но это очевидно не так. Как хранить информацию о фильмах, пока нет ещё ни одного билета на этот фильм? Правильно заданный вопрос – это уже половина ответа. Раз фильмы существуют даже когда на них не продано ещё ни одного билета, значит, они существуют где-то в

Это всё один фильм с несколькими режиссёрами, или это разные фильмы? Снимал ли Федор Бондарчук в 1924 году Годзиллу? Снял ли Кодзи Хасимото в 1984 году два фильма про Годзиллу с разной длительностью? Кто в 1998 году снял очередной ремейк, Роланд Эммерих или Роланд Эмерих, и зачем два раза повторяется информация о самом первом фильме про Годзиллу 1954 года, и самый ли это первый фильм. Как будто, вопросов становится только больше. Если хорошенько обдумать эту проблему, можно прийти к неутешительному выводу.
Мораль
База данных может противоречить реальности, и с этим, к сожалению, ничего не поделать.
Нет, Федор Бондарчук в 1924 году Годзиллу не снимал, но
Но вот что мы можем и обязаны сделать – это чтобы информация в базе данных не противоречила самой себе. Мы знаем, что Кодзи Хасимото в 1984 году снял только один фильм про Годзиллу, и мы хотим что-то сделать такое с базой данных, чтобы туда нельзя было добавить два фильма Кодзи Хасимото про Годзиллу в 1984 году. Для этого нам нужен специальный механизм, который называется механизмом уникальных ключей. Нам надо на таблицу наложить ограничение уникальности: ни в каком состоянии таблицы, не должно быть двух строк, в которых данные в столбцах «Название», «Режиссёр» и «Год выпуска» совпадают, потому что именно эта комбинация однозначно определяет фильм. Почему так? Может быть, двух столбцов «Название» и «Режиссёр» достаточно? Может быть и достаточно, это именно наша задача: решить, есть ли (и могут ли появиться в будущем) фильмы такие, что они сняты одним и тем же режиссёром и имеют одно и то же название и принять решение о том, какая комбинация является уникальной.
Мы не допускаем полных повторений, потому что они или не несут информации, как две строки про Исиро Хонду, или приводят к противоречиям, как две строки про Кодзи Хасимото с разной длительностью, и это универсальный принцип.
Мораль
Дублирование данных не несёт информации и приводит к потенциальным противоречиям.

Значком UK1 («unique key» 1) мы обозначили наложенное ограничение уникальности на соответствующие три столбца, они теперь в таблице никогда не повторятся. Но проблема с Роландом Эммерихом и его почти тёзкой осталась, потому что это другая проблема.
Понимая, что сначала, как человек, появляется сам режиссёр, а только потом появляется его привязка к фильму, мы должны и режиссёров вынести в отдельную таблицу.

Для режиссёров мы сделали смелое предположение о том, что их ФИО является уникальным, и двух режиссёров Иванов Ивановых в нашей базе данных не окажется. Но самое обидное, что проблема всё равно не решилась. Во-первых, в таблице персон, где мы перечислили всех режиссёров, ничего не мешает перечисляться рядом двум ошибочным, но уникальным
С первой проблемой, как я уже говорил, ничего не поделать. Если такой человек внесён в таблицу персон, то его отличие одной буквой от другого человека делает его уникальным, и это можно решить только ручным контролем и административными

Вот теперь, чтобы назначить какого-то режиссёра фильму, обязательно сначала придётся добавить его в таблицу персон, а из таблицы персон не получится его удалить, пока он назначен хоть одному фильму.
Мораль
Этих двух механизмов (уникальных ключей и внешних ключей) достаточно, чтобы реализовать большинство требований к непротиворечивости данных в базе данных. Нужно просто научиться правильно ими пользоваться.
Теперь давайте попробуем вернуться к нашей таблице билетов и посмотреть, что там поменяется, с учётом наличия двух новых таблиц.

Похоже, стало только хуже. Во-первых, пока мы разбирались с фильмами, мы выяснили, что фильма и режиссёра недостаточно для уникальности фильма, нужен ещё и год выпуска. Поэтому неизбежно пришлось столбец с годом выпуска добавлять и в таблицу билетов. Во-вторых, информация об актёрах теперь хранится в двух местах: в таблице билетов и в таблице фильмов, а дублирование, как мы знаем – потенциальный источник противоречий, каковые мы в таблице и наблюдаем.
С дублированием актёров справиться просто: столбцы с актёрами просто удаляются из таблицы билетов. Как же так, скажете вы, ведь эта информация должна распечатываться на билете? Должна, но противоречий тут нет: когда мы будем распечатывать билет, эту информацию можно будет достать из другой таблицы без проблем.
Мораль
Структура хранения данных в таблицах не обязана соответствовать тому, как эти данные будут заполняться или наоборот, выводиться. Структура хранения не обязана совпадать со структурой представления информации. Хранятся таблицы одни, а выводится информация, возможно, вообще не в таблице, а в виде красивого флайера.
А вот как избавиться от многократного дублирования информации о том, что в 1997 году Роберт Земекис снял свой гимн агностицизму, замечательный фильм «Контакт»?

Для решения этой проблемы можно использовать такую вещь, как суррогатный ключ. В таблице фильмов, как и в таблице персон, появляется новый уникальный числовой столбец, единственное предназначение которого – заменять собой прежнюю уникальную комбинацию столбцов там, где эту комбинацию нужно упомянуть:

Видите, как теперь в таблице билетов вместо трёх столбцов для фильма остался только один, а именно идентификатор фильма? Это одна из фишек суррогатных ключей. Кроме этого, посмотрите на таблицу фильмов: там вместо имени режиссёра теперь тоже суррогатный ключ, идентификатор режиссёра. Казалось бы, при этом решении столбцов в таблице не стало меньше, просто столбец с именем режиссёра заменён на столбец с идентификатором, но и у этого решения есть плюсы.
Во-первых, идентификатор, суррогатный ключ, обычно представляет собой число, и такой столбец занимает меньше места в любой памяти, чем строка. Во-вторых, идентификатор меньшей вероятностью придётся изменять, тогда как, возможно, понадобится «Земякиса» заменять на «Земекиса» и наоборот – мы сможем изменить его фамилию только в одном месте, тогда как иначе пришлось бы изменять её во многих местах. В-третьих, даже если идентификаторы понадобится менять (например, при слиянии двух однотипных баз данных), для пользователя такое изменение пройдёт незаметно, потому что сами идентификаторы пользователю могут быть даже не видны.
Теперь вернёмся к фильмам и посмотрим на две колонки с актёрами. С первого взгляда становится очевидно, что с ними нужно поступить так же, как с режиссёрами: воспользоваться таблицей персон и вместо имён актёров вписать их идентификаторы, сделав их внешними ключами.
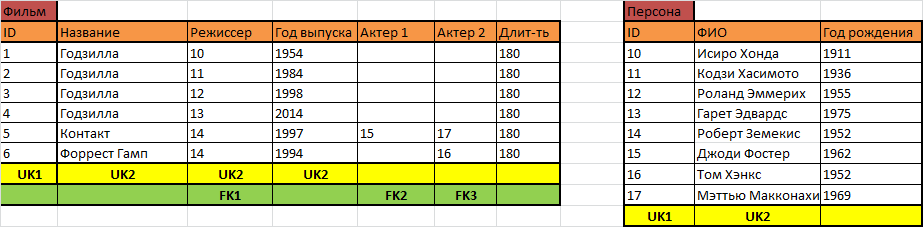
Но понятно, что это решение неудобно и тогда, когда информации по актёрам нет, и тогда, когда актёров требуется прописать больше двух. Можно было бы добавлять новые столбцы «Актёр 3», «Актёр 4» и так далее, но это решение не только плохо масштабируется, но потом приведёт к очень большим проблемам, когда нужно будет найти фильм с заданной парой актёров.
И тут нам поможет очередное типовое решение и важно понять логику того, как оно появляется. Мы не можем хранить информацию об актёрах в таблице фильмов, потому что на каждый фильм – одна строчка, а добавлять переменное количество столбцов мы не можем. Но аналогичным образом мы не можем хранить информацию о фильмах в таблице актёров, потому что на каждого актёра в этой таблице – одна строчка, а переменное количество столбцов для фильмов в таблице актёров мы тоже создавать не можем. Значит, эта информация должна храниться где-то ещё! Что это за информация? Это информация о том, что какой-то актёр играл в каком-то фильме – вот и ответ, что должно храниться в такой таблице.
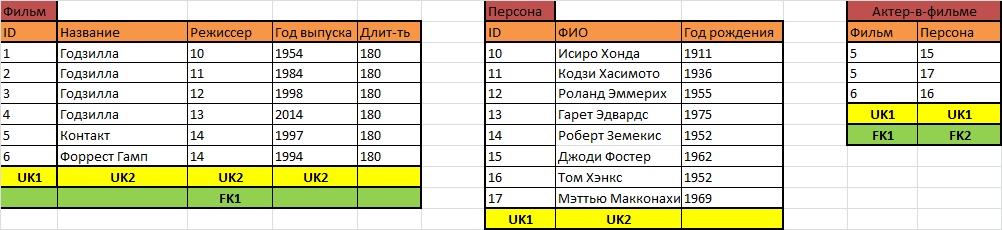
К каждому фильму теперь привязан один режиссёр в виде его идентификатора, хранимого прямо в таблице фильмов, и произвольное число актёров, в виде строк, хранимых в отдельной таблице «Актёр-в-фильме». В этой таблице есть только два столбца с идентификаторами персон и фильмов, они оба являются внешними ключами (чтобы идентификатор фильма обязательно встречался в таблице фильмов, а идентификатор персоны – в таблице персон), и они оба входят в уникальный ключ, чтобы исключить дублирование строк в таблице.
Гипотетически в этой же таблице может быть ещё один столбец, где может храниться качество, в котором эта персона участвует в фильме, и тогда в этой таблице можно хранить информацию не только об актёрах фильма, но и о продюссерах, композиторах, сценаристах, баристах, дублёрах, каскадёрах и так далее.
Интересный вопрос – нужен ли в такой таблице свой ID, свой суррогатный ключ? Похоже, что нет – а зачем? Пока никакой другой таблице не требуется ссылаться на строчку этой таблицы, суррогатный ключ будет лишним.
Мораль
Суррогатный ключ ID нужен не в каждой таблице, а только в тех, где нет другого ключа, и на строчки которых нужно ссылаться в других таблицах.
Давайте ещё раз потренируемся. Допустим, нам надо хранить информацию о жанрах. Жанр – это произвольная строка? Или мы где-то перечислим список возможных жанров, чтобы можно было искать по определённому жанру из этого списка? Конечно, второе:
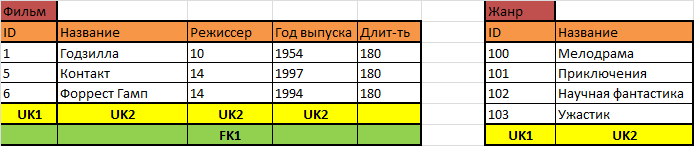
Ну что, как теперь соединить фильмы и жанры? Может быть, надо каждому фильму приписать какой-то жанр?

Можно, но тогда не получится фильму приписать сразу несколько жанров, а значит, нашу реальность такая база данных будет описывать неправильно. Может быть, надо каждому жанру приписать какой-то фильм?
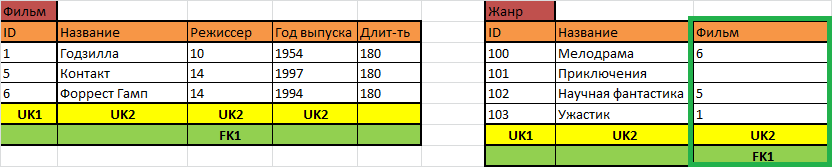
Так тоже можно, тогда у фильма может быть несколько жанров, но тогда у каждого жанра есть только один фильм. Я думаю, вы уже догадались, какое типовое решение тут нужно применить – нужна отдельная таблица, где будет храниться информация о том, какой фильм имеет какой жанр:

Теперь вернёмся обратно к таблице билетов и посмотрим на неё, остались ли там какие-то проблемы:
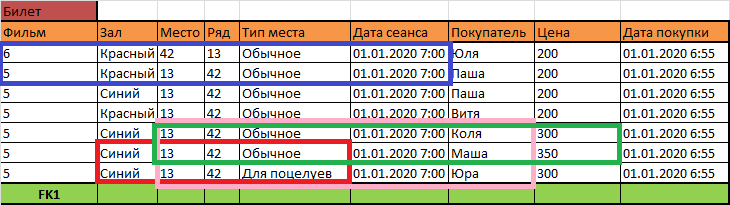
Оказывается, в уже имеющихся данных проблем много, а в потенциальных данных в этой таблице проблем ещё больше. Место 13 в ряду 42 – непонятно, какого типа. Кроме этого, на это место купили сразу три билета на одно и то же время, причём почему-то по разной цене, а к тому же в это время в зале идёт сразу два фильма. Полнейший бардак. А если все данные из этой таблицы удалить, бардак пропадёт? Или только спрячется, затаится так, что его сложнее будет увидеть?
Применим тот же самый приём, который мы уже применяли. Представим, что в этой таблице ещё нет данных, потому что не продан никакой билет. Очевидно, что ещё до появления в нашей реальности билета, в этой реальности уже есть много чего в кинотеатре, что требуется описать. Чтобы продать билет на какое-то место, это место должно быть. Спросим себя, какая информация существует ещё до продажи билета?
Очевидно, что в кинотеатре есть залы, в залах есть ряды и места разного типа, и это не зависит от того, какие фильмы поступают в прокат и какие билеты на них продаются. Для нас это главный признак того, что это – информация независимая, она не связана с билетами и существует отдельно от них, а значит должна и храниться отдельно.
И вот тут важный момент. У зала есть место, а у места есть тип. Мы используем один и тот же глагол русского языка, «есть», но важно научиться чувствовать и видеть разницу между этими ситуациями. В одном случае тип места является признаком, свойством места, и поэтому у места есть только один тип. А в другом случае само место совсем не является признаком зала, а существует само по себе, но с залом как-то связано, и при этом в зале может быть несколько мест. Потом, на умном языке мы, конечно, будем рассуждать о том, что превратится в сущности, а что – в признаки сущностей, но пока мы зададим себе гораздо более простой вопрос: какие таблицы нам создавать и какие колонки в них делать.
Должна быть таблица с залами, где каждый зал – одна строчка с идентификатором, чтобы на неё можно было ссылаться? Конечно, должна быть, потому что зал – это отдельный объект, требующий описания.

Должна быть таблица с местами, где каждое место – одна строчка с идентификатором, чтобы на неё можно было ссылаться, или мы просто в билете будем писать номер ряда и номер места? Это гораздо более сложный вопрос, но у нас есть подсказка, направляющая нас к нужному решению. Что такое «Обычное», «Для поцелуев»? Это тип места, признак места. А значит, каждое место должно существовать в виде отдельной строчки, чтобы нам было, где прописать его тип. Залов у нас может быть много, мест тоже может быть много – нужно ли для хранения мест каждого зала заводить отдельную таблицу? Очевидно, что гораздо удобнее хранить все места в одной таблице, но чтобы помнить, какое место находится в каком зале, для каждого места нужно хранить идентификатор зала, к которому оно принадлежит.
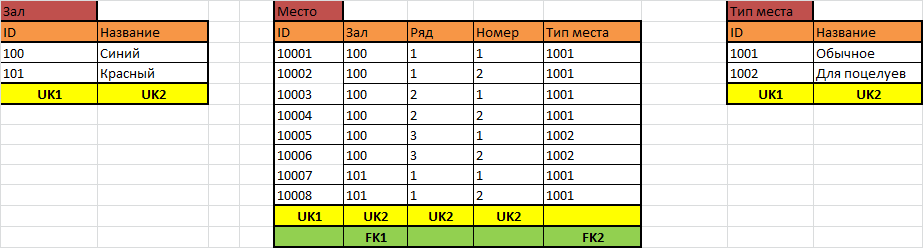
Вы, конечно, заметили, что тип места мы не стали оставлять в виде строкового значения, потому что оно не может быть произвольной строкой, а должно браться из набора определённых возможных значений. Такие таблицы, с идентификатором и названием, будут у нас плодиться быстрее всего, и мы будем их называть справочниками.
Может возникнуть вопрос, стоит ли и ряды хранить в виде отдельной таблицы тоже? Я думаю, главное тут – есть ли у рядов свои собственные свойства: как только они появятся – придётся и ряды вынести в отдельную таблицу, но прямо сейчас этого, судя по всему, не требуется.
В таблице с местами – два внешних ключа, потому что зал и тип места – это идентификаторы, которые должны браться из соответствующих таблиц. Уникальных ключа тоже два: один из них – суррогатный, чтобы в любой другой таблице можно было ссылаться на конкретное место просто по идентификатору. Другой уникальный ключ включает зал, ряд и номер, чтобы в каждом зале комбинация ряда и номера была уникальной.
Вот и ещё одна часть реальности кинотеатра корректно описана. Что теперь осталось в таблице билетов?

Что мы видим? Во-первых, всё так же пока остались нерешёнными проблемы с продажей нескольких билетов на одно место и разной ценой на одно и то же место. Во-вторых, если видеть, каким залам принадлежат места, на которые продаются билеты, можно видеть, что два первых билета проданы на одно и то же место, но при этом не понятно, на какой именно фильм. Второй и третий билет проданы на разные места, но на один и тот же фильм. Это, конечно, возможно, но как-то сомнительно. А самое главное – пока не продано ни одного билета, невозможно понять, какой фильм когда идёт в каком зале, потому что эта информация нигде не хранится, кроме таблицы билетов. Как всегда, достаточно правильно сформулировать проблему, чтобы нечаянно сформулировать и её решение: информация о том, какой фильм, когда и где идёт, должна храниться не в таблице билетов, а в отдельной таблице.
А как должна называться таблица, в которой хранится информация о том, какой фильм, когда и где идёт? А что это такое, что это за явление, к которому привязана информация о фильме, зале и времени? Очевидно, что это явление и называется «Сеанс», и информация о нём появляется задолго до того, как появляется первый проданный билет! Более того, источником данных для таблицы билетов является касса, а источником данных для таблицы сеансов является рабочее место то ли аналитика, то ли администратора.
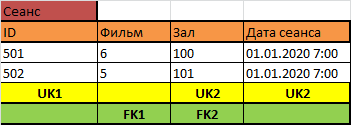
В таблице сеансов каждая строка – это показ конкретного фильма в конкретном зале в конкретное время, и мы видим, что помимо уникального суррогатного ключа, второй уникальный ключ показывает, что в каждом зале в каждое конкретное время может начинаться только один фильм (обратите внимание, фильм теперь не входит в уникальный ключ, он вообще является признаком сеанса, а сеанс может начинаться в конкретное время). И ключевое слово здесь – «начинаться». Ничего не мешает добавить сюда дату-время, отличающееся на 1 минуту, и тогда уникальный ключ не будет нас спасать от пересечения разных сеансов друг с другом в каком-то одном зале.
Последнее замечание – иллюстрация того, что не все ограничения из реальной жизни легко или вообще возможно перенести в базу данных так, чтобы они обеспечивались уникальными и внешними ключами. И в этом случае или модифицируют саму базу данных так, чтобы все-таки спасали ключи, или же проверяют и обеспечивают выполнение условий с помощью программного кода, который вместе с базой данных живёт (такое тоже возможно, но выходит за пределы этой статьи, — интересующиеся будут гуглить слово «триггеры»). В нашем случае можно поступиться возможностью начинать сеансы в произвольное время и выкрутиться с помощью ещё одной таблицы непересекающихся интервалов:
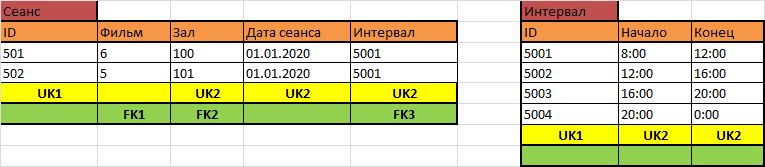
Тогда два сеанса в одном зале вообще не могут пересекаться, но и начинаться они могут только в заданный набор времён началов сеансов.
Ну и теперь, мы готовы в очередной раз вернуться к тому, с чего начинали, – с таблицы билетов. Я надеюсь, что вы уже достаточно разобрались в подходе, чтобы догадаться, что билет продаётся не на фильм, а на сеанс!

Уникальный ключ теперь не даёт возможности продать на одно место на одном сеансе несколько билетов, внешние ключи позволяют продать билеты только на реальный сеанс и на реальное место. Нужна ли в этой таблице дата покупки? Конечно, нужна! Зачем? А фиг знает.
Простая мораль...
автоматизации процессов и разработки информационных систем – сохраняй всю появляющуюся входную информацию, вплоть до того, сколько времени перед кассой тупил очередной покупатель, потому что ты не можешь предположить, когда и кому как эту информацию можно будет продать использовать.
Остался нераскрыт вопрос с ценой. Сейчас всё ещё можно два билета на один сеанс на соседние места увидеть в этой таблице по разной цене
А это зависит от того, как будет строиться ценообразование в рассматриваемом кинотеатре. Если цена устанавливается единой для всех билетов фильма, то это вообще признак и свойство фильма:
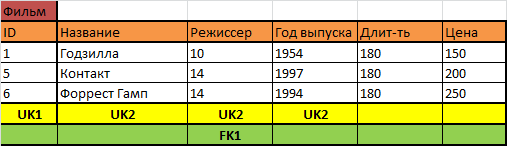
Если цена устанавливается единой для всех билетов одного сеанса, но для разных сеансов она может быть различной, то это признак и свойство сеанса:
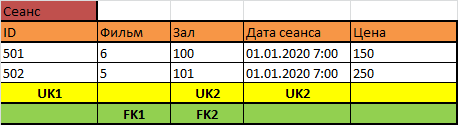
Если цена определяется фильмом и типом места, или если цена определяется сеансом и типом места, то придётся заполнять, соответственно, одну из двух таких таблиц:

Короче говоря, что является определяющим цену билета, то и будет, скорее всего, уникальным ключом в таблице, где хранятся цены билетов. В самой таблице билетов тогда останется только та информация, которая появляется в момент возникновения самого билета, и информация, необходимая для уникальной идентификации самого билета и обеспечения уникальности нужных комбинаций его свойств. Будет ли у билета свой собственный уникальный суррогатный ключ? Пока он вроде бы никак не нужен самой базе данных (на билет не ссылается никакая другая таблица), но скорее всего он будет нужен информационной системе, которая будет такую базу данных использовать. Всё, что нам осталось – собрать все примеры таких табличек на одном А3 (как повезёт, может и А2 и А1) листе и применить метод внимательного взгляда.

На этом я завершу эту статью. Полчаса уже прошло, а я, похоже, так никого и не научил проектированию реляционных баз данных. Но надеюсь, мои объяснения помогут кому-нибудь научиться организовывать данные реальных информационных систем в реляционном виде. Напоследок (в качестве домашнего задания) я сделаю то, что обычно делаю для всех студентов, которые проектируют свою первую нетривиальную реляционную базу данных. Заполню пару табличек, созданных нами данными, и предложу внимательно на эти данные посмотреть.
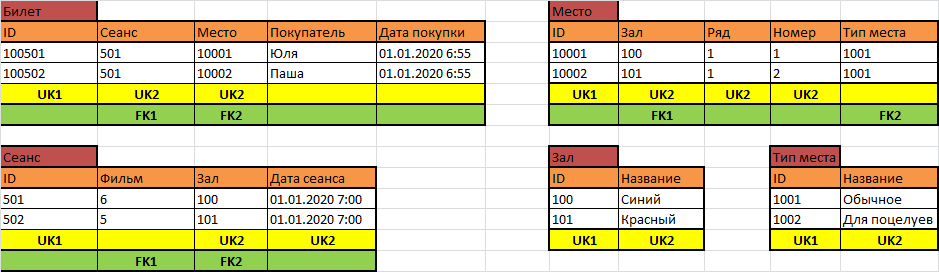
Видите ли вы тут проблему? А сможете её решить в реляционном виде? Или триггеры неизбежны? Но это уже совсем другая история.

