
В предыдущей статье мы узнали, как использовать модели ИИ для определения формы лиц. В этой статье мы используем ключевые ориентиры лица, чтобы получить больше информации о лице из изображений.
В этой статье мы используем ключевые ориентиры лица, чтобы получить больше информации о лице из изображений. Мы используем глубокое обучение на отслеженных лицах из набора данных FER+ и попытаемся точно определить эмоции человека по точкам лица в браузере с помощью TensorFlow.js.
Соединив наш код отслеживания лица с набором данных об эмоциях на лице FER, мы обучим вторую нейросетевую модель определять эмоции человека по нескольким трехмерным ключевым точкам.
Вы можете загрузить демоверсию этого проекта. Для обеспечения необходимой производительности может потребоваться включить в веб-браузере поддержку интерфейса WebGL. Вы также можете загрузить код и файлы для этой серии.
Настройка по данным об эмоциях на лице FER2013
Мы используем код для отслеживания лиц из предыдущей статьи, чтобы создать две веб-страницы. Одна страница будет использоваться для обучения модели ИИ на точках отслеженных лиц в наборе данных FER, а другая будет загружать обученную модель и применять её к тестовому набору данных.
Давайте изменим окончательный код из проекта отслеживания лиц, чтобы обучить нейросетевую модель и применить её к данным о лицах. Набор данных FER2013 состоит более чем из 28 тысяч помеченных изображений лиц; он доступен на веб-сайте Kaggle. Мы загрузили эту версию, в которой набор данных уже преобразован в файлы изображений, и поместили её в папку web/fer2013. Затем мы обновили код сервера NodeJS в index.js, чтобы он возвращал список ссылок на изображения по адресу http://localhost:8080/data/. Поэтому вы можете получить полный объект JSON, если запустите сервер локально.
Чтобы упростить задачу, мы сохранили этот объект JSON в файле web/fer2013.js, чтобы вы могли использовать его напрямую, не запуская сервер локально. Вы можете включить его в другие файлы скриптов в верхней части страницы:
<script src="web/fer2013.js"></script>Мы собираемся работать с изображениями, а не с видео с веб-камеры (не беспокойтесь, мы вернёмся к видео в следующей статье). Поэтому нам нужно заменить элемент<video> элементом <img>и переименовать его ID в «image». Мы также можем удалить функцию setupWebcam, так как для этого проекта она не нужна.
<img id="image" style="
visibility: hidden;
width: auto;
height: auto;
"/>Далее добавим служебную функцию, чтобы задать изображение для элемента, и ещё одну, чтобы перетасовать массив данных. Так как исходные изображения имеют размер всего 48x48 пикселей, давайте для большего выходного размера зададим 500 пикселей, чтобы получить более детальное отслеживание лиц и возможность видеть результат в более крупном элементе canvas. Также обновим служебные функции для линий и многоугольников, чтобы масштабировать в соответствии с выходными данными.
async function setImage( url ) {
return new Promise( res => {
let image = document.getElementById( "image" );
image.src = url;
image.onload = () => {
res();
};
});
}
function shuffleArray( array ) {
for( let i = array.length - 1; i > 0; i-- ) {
const j = Math.floor( Math.random() * ( i + 1 ) );
[ array[ i ], array[ j ] ] = [ array[ j ], array[ i ] ];
}
}
const OUTPUT_SIZE = 500;Нам понадобятся некоторые глобальные переменные: для списка категорий эмоций, списка агрегированных массивов данных FER и индекса массива:
const emotions = [ "angry", "disgust", "fear", "happy", "neutral", "sad", "surprise" ];
let ferData = [];
let setIndex = 0;Внутри блока async мы можем подготовить и перетасовать данные FER и изменить размер элемента canvas до 500x500 пикселей:
const minSamples = Math.min( ...Object.keys( fer2013 ).map( em => fer2013[ em ].length ) );
Object.keys( fer2013 ).forEach( em => {
shuffleArray( fer2013[ em ] );
for( let i = 0; i < minSamples; i++ ) {
ferData.push({
emotion: em,
file: fer2013[ em ][ i ]
});
}
});
shuffleArray( ferData );
let canvas = document.getElementById( "output" );
canvas.width = OUTPUT_SIZE;
canvas.height = OUTPUT_SIZE;Нам нужно в последний раз обновить шаблон кода перед обучением модели ИИ на одной странице и применением обученной модели на второй странице. Необходимо обновить функцию trackFace, чтобы она работала с элементом image, а не video. Также требуется масштабировать ограничивающий прямоугольник и выходные данные сетки для лица в соответствии с размером элемента canvas. Мы зададим приращение setIndex в конце функции для перехода к следующему изображению.
async function trackFace() {
// Set to the next training image
await setImage( ferData[ setIndex ].file );
const image = document.getElementById( "image" );
const faces = await model.estimateFaces( {
input: image,
returnTensors: false,
flipHorizontal: false,
});
output.drawImage(
image,
0, 0, image.width, image.height,
0, 0, OUTPUT_SIZE, OUTPUT_SIZE
);
const scale = OUTPUT_SIZE / image.width;
faces.forEach( face => {
// Draw the bounding box
const x1 = face.boundingBox.topLeft[ 0 ];
const y1 = face.boundingBox.topLeft[ 1 ];
const x2 = face.boundingBox.bottomRight[ 0 ];
const y2 = face.boundingBox.bottomRight[ 1 ];
const bWidth = x2 - x1;
const bHeight = y2 - y1;
drawLine( output, x1, y1, x2, y1, scale );
drawLine( output, x2, y1, x2, y2, scale );
drawLine( output, x1, y2, x2, y2, scale );
drawLine( output, x1, y1, x1, y2, scale );
// Draw the face mesh
const keypoints = face.scaledMesh;
for( let i = 0; i < FaceTriangles.length / 3; i++ ) {
let pointA = keypoints[ FaceTriangles[ i * 3 ] ];
let pointB = keypoints[ FaceTriangles[ i * 3 + 1 ] ];
let pointC = keypoints[ FaceTriangles[ i * 3 + 2 ] ];
drawTriangle( output, pointA[ 0 ], pointA[ 1 ], pointB[ 0 ], pointB[ 1 ], pointC[ 0 ], pointC[ 1 ], scale );
}
});
setText( `${setIndex + 1}. Face Tracking Confidence: ${face.faceInViewConfidence.toFixed( 3 )} - ${ferData[ setIndex ].emotion}` );
setIndex++;
requestAnimationFrame( trackFace );
}Теперь наш изменённый шаблон готов. Создайте две копии этого кода, чтобы можно было одну страницу задать для глубокого обучения, а другую страницу – для тестирования.
1. Глубокое изучение эмоций на лице
В этом первом файле веб-страницы мы собираемся задать обучающие данные, создать нейросетевую модель, а затем обучить её и сохранить веса в файл. В код включена предварительно обученная модель (см. папку web/model), поэтому при желании можно пропустить эту часть и перейти к части 2.
Добавьте глобальную переменную для хранения обучающих данных и служебную функцию для преобразования меток эмоций в унитарный вектор, чтобы мы могли использовать его для обучающих данных:
let trainingData = [];
function emotionToArray( emotion ) {
let array = [];
for( let i = 0; i < emotions.length; i++ ) {
array.push( emotion === emotions[ i ] ? 1 : 0 );
}
return array;
}Внутри функции trackFace мы возьмём различные ключевые черты лица, масштабируем их относительно размера ограничивающего прямоугольника и добавим их в набор обучающих данных, если значение достоверности отслеживания лица достаточно велико. Мы закомментировали некоторые дополнительные черты лица, чтобы упростить данные, но вы можете добавить их обратно, если хотите поэкспериментировать. Если вы это делаете, не забудьте сопоставить эти функции при применении модели.
// Add just the nose, cheeks, eyes, eyebrows & mouth
const features = [
"noseTip",
"leftCheek",
"rightCheek",
"leftEyeLower1", "leftEyeUpper1",
"rightEyeLower1", "rightEyeUpper1",
"leftEyebrowLower", //"leftEyebrowUpper",
"rightEyebrowLower", //"rightEyebrowUpper",
"lipsLowerInner", //"lipsLowerOuter",
"lipsUpperInner", //"lipsUpperOuter",
];
let points = [];
features.forEach( feature => {
face.annotations[ feature ].forEach( x => {
points.push( ( x[ 0 ] - x1 ) / bWidth );
points.push( ( x[ 1 ] - y1 ) / bHeight );
});
});
// Only grab the faces that are confident
if( face.faceInViewConfidence > 0.9 ) {
trainingData.push({
input: points,
output: ferData[ setIndex ].emotion,
});
}Скомпилировав достаточное количество обучающих данных, мы можем передать их функции trainNet. В верхней части функции trackFace давайте закончим цикл отслеживания лиц и выйдем из него после 200 изображений и вызовем функцию обучения:
async function trackFace() {
// Fast train on just 200 of the images
if( setIndex >= 200 ) {
setText( "Finished!" );
trainNet();
return;
}
...
}Наконец, мы пришли к той части, которую так долго ждали: давайте создадим функцию trainNet и обучим нашу модель ИИ!
Эта функция разделит данные обучения на входной массив ключевых точек и выходной массив унитарных векторов эмоций, создаст категорийную модель TensorFlow с несколькими скрытыми слоями, выполнит обучение за 1000 итераций и загрузит обученную модель. Чтобы дополнительно обучить модель, число итераций можно увеличить.
async function trainNet() {
let inputs = trainingData.map( x => x.input );
let outputs = trainingData.map( x => emotionToArray( x.output ) );
// Define our model with several hidden layers
const model = tf.sequential();
model.add(tf.layers.dense( { units: 100, activation: "relu", inputShape: [ inputs[ 0 ].length ] } ) );
model.add(tf.layers.dense( { units: 100, activation: "relu" } ) );
model.add(tf.layers.dense( { units: 100, activation: "relu" } ) );
model.add(tf.layers.dense( {
units: emotions.length,
kernelInitializer: 'varianceScaling',
useBias: false,
activation: "softmax"
} ) );
model.compile({
optimizer: "adam",
loss: "categoricalCrossentropy",
metrics: "acc"
});
const xs = tf.stack( inputs.map( x => tf.tensor1d( x ) ) );
const ys = tf.stack( outputs.map( x => tf.tensor1d( x ) ) );
await model.fit( xs, ys, {
epochs: 1000,
shuffle: true,
callbacks: {
onEpochEnd: ( epoch, logs ) => {
setText( `Training... Epoch #${epoch} (${logs.acc.toFixed( 3 )})` );
console.log( "Epoch #", epoch, logs );
}
}
} );
// Download the trained model
const saveResult = await model.save( "downloads://facemo" );
}
На этом всё! На этой веб-странице модель ИИ будет обучена распознавать выражения лиц в различных категориях, и вы получите модель для загрузки и применения. Это мы и сделаем далее.
1. Финишная прямая
Вот полный код обучения модели на наборе данных FER:
<html>
<head>
<title>Training - Recognizing Facial Expressions in the Browser with Deep Learning using TensorFlow.js</title>
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@2.4.0/dist/tf.min.js"></script>
<script src="https://cdn.jsdelivr.net/npm/@tensorflow-models/face-landmarks-detection@0.0.1/dist/face-landmarks-detection.js"></script>
<script src="web/triangles.js"></script>
<script src="web/fer2013.js"></script>
</head>
<body>
<canvas id="output"></canvas>
<img id="image" style="
visibility: hidden;
width: auto;
height: auto;
"/>
<h1 id="status">Loading...</h1>
<script>
function setText( text ) {
document.getElementById( "status" ).innerText = text;
}
async function setImage( url ) {
return new Promise( res => {
let image = document.getElementById( "image" );
image.src = url;
image.onload = () => {
res();
};
});
}
function shuffleArray( array ) {
for( let i = array.length - 1; i > 0; i-- ) {
const j = Math.floor( Math.random() * ( i + 1 ) );
[ array[ i ], array[ j ] ] = [ array[ j ], array[ i ] ];
}
}
function drawLine( ctx, x1, y1, x2, y2, scale = 1 ) {
ctx.beginPath();
ctx.moveTo( x1 * scale, y1 * scale );
ctx.lineTo( x2 * scale, y2 * scale );
ctx.stroke();
}
function drawTriangle( ctx, x1, y1, x2, y2, x3, y3, scale = 1 ) {
ctx.beginPath();
ctx.moveTo( x1 * scale, y1 * scale );
ctx.lineTo( x2 * scale, y2 * scale );
ctx.lineTo( x3 * scale, y3 * scale );
ctx.lineTo( x1 * scale, y1 * scale );
ctx.stroke();
}
const OUTPUT_SIZE = 500;
const emotions = [ "angry", "disgust", "fear", "happy", "neutral", "sad", "surprise" ];
let ferData = [];
let setIndex = 0;
let trainingData = [];
let output = null;
let model = null;
function emotionToArray( emotion ) {
let array = [];
for( let i = 0; i < emotions.length; i++ ) {
array.push( emotion === emotions[ i ] ? 1 : 0 );
}
return array;
}
async function trainNet() {
let inputs = trainingData.map( x => x.input );
let outputs = trainingData.map( x => emotionToArray( x.output ) );
// Define our model with several hidden layers
const model = tf.sequential();
model.add(tf.layers.dense( { units: 100, activation: "relu", inputShape: [ inputs[ 0 ].length ] } ) );
model.add(tf.layers.dense( { units: 100, activation: "relu" } ) );
model.add(tf.layers.dense( { units: 100, activation: "relu" } ) );
model.add(tf.layers.dense( {
units: emotions.length,
kernelInitializer: 'varianceScaling',
useBias: false,
activation: "softmax"
} ) );
model.compile({
optimizer: "adam",
loss: "categoricalCrossentropy",
metrics: "acc"
});
const xs = tf.stack( inputs.map( x => tf.tensor1d( x ) ) );
const ys = tf.stack( outputs.map( x => tf.tensor1d( x ) ) );
await model.fit( xs, ys, {
epochs: 1000,
shuffle: true,
callbacks: {
onEpochEnd: ( epoch, logs ) => {
setText( `Training... Epoch #${epoch} (${logs.acc.toFixed( 3 )})` );
console.log( "Epoch #", epoch, logs );
}
}
} );
// Download the trained model
const saveResult = await model.save( "downloads://facemo" );
}
async function trackFace() {
// Fast train on just 200 of the images
if( setIndex >= 200 ) {//ferData.length ) {
setText( "Finished!" );
trainNet();
return;
}
// Set to the next training image
await setImage( ferData[ setIndex ].file );
const image = document.getElementById( "image" );
const faces = await model.estimateFaces( {
input: image,
returnTensors: false,
flipHorizontal: false,
});
output.drawImage(
image,
0, 0, image.width, image.height,
0, 0, OUTPUT_SIZE, OUTPUT_SIZE
);
const scale = OUTPUT_SIZE / image.width;
faces.forEach( face => {
// Draw the bounding box
const x1 = face.boundingBox.topLeft[ 0 ];
const y1 = face.boundingBox.topLeft[ 1 ];
const x2 = face.boundingBox.bottomRight[ 0 ];
const y2 = face.boundingBox.bottomRight[ 1 ];
const bWidth = x2 - x1;
const bHeight = y2 - y1;
drawLine( output, x1, y1, x2, y1, scale );
drawLine( output, x2, y1, x2, y2, scale );
drawLine( output, x1, y2, x2, y2, scale );
drawLine( output, x1, y1, x1, y2, scale );
// Draw the face mesh
const keypoints = face.scaledMesh;
for( let i = 0; i < FaceTriangles.length / 3; i++ ) {
let pointA = keypoints[ FaceTriangles[ i * 3 ] ];
let pointB = keypoints[ FaceTriangles[ i * 3 + 1 ] ];
let pointC = keypoints[ FaceTriangles[ i * 3 + 2 ] ];
drawTriangle( output, pointA[ 0 ], pointA[ 1 ], pointB[ 0 ], pointB[ 1 ], pointC[ 0 ], pointC[ 1 ], scale );
}
// Add just the nose, cheeks, eyes, eyebrows & mouth
const features = [
"noseTip",
"leftCheek",
"rightCheek",
"leftEyeLower1", "leftEyeUpper1",
"rightEyeLower1", "rightEyeUpper1",
"leftEyebrowLower", //"leftEyebrowUpper",
"rightEyebrowLower", //"rightEyebrowUpper",
"lipsLowerInner", //"lipsLowerOuter",
"lipsUpperInner", //"lipsUpperOuter",
];
let points = [];
features.forEach( feature => {
face.annotations[ feature ].forEach( x => {
points.push( ( x[ 0 ] - x1 ) / bWidth );
points.push( ( x[ 1 ] - y1 ) / bHeight );
});
});
// Only grab the faces that are confident
if( face.faceInViewConfidence > 0.9 ) {
trainingData.push({
input: points,
output: ferData[ setIndex ].emotion,
});
}
});
setText( `${setIndex + 1}. Face Tracking Confidence: ${face.faceInViewConfidence.toFixed( 3 )} - ${ferData[ setIndex ].emotion}` );
setIndex++;
requestAnimationFrame( trackFace );
}
(async () => {
// Get FER-2013 data from the local web server
// https://www.kaggle.com/msambare/fer2013
// The data can be downloaded from Kaggle and placed inside the "web/fer2013" folder
// Get the lowest number of samples out of all emotion categories
const minSamples = Math.min( ...Object.keys( fer2013 ).map( em => fer2013[ em ].length ) );
Object.keys( fer2013 ).forEach( em => {
shuffleArray( fer2013[ em ] );
for( let i = 0; i < minSamples; i++ ) {
ferData.push({
emotion: em,
file: fer2013[ em ][ i ]
});
}
});
shuffleArray( ferData );
let canvas = document.getElementById( "output" );
canvas.width = OUTPUT_SIZE;
canvas.height = OUTPUT_SIZE;
output = canvas.getContext( "2d" );
output.translate( canvas.width, 0 );
output.scale( -1, 1 ); // Mirror cam
output.fillStyle = "#fdffb6";
output.strokeStyle = "#fdffb6";
output.lineWidth = 2;
// Load Face Landmarks Detection
model = await faceLandmarksDetection.load(
faceLandmarksDetection.SupportedPackages.mediapipeFacemesh
);
setText( "Loaded!" );
trackFace();
})();
</script>
</body>
</html>2. Обнаружение эмоций на лице
Мы почти достигли своей цели. Применение модели обнаружения эмоций проще, чем её обучение. На этой веб-странице мы собираемся загрузить обученную модель TensorFlow и протестировать её на случайных лицах из набора данных FER.
Мы можем загрузить модель обнаружения эмоций в глобальную переменную прямо под кодом загрузки модели обнаружения ориентиров лица. Обучив свою модель в части 1, вы можете обновить путь в соответствии с местом сохранения своей модели.
let emotionModel = null;
(async () => {
...
// Load Face Landmarks Detection
model = await faceLandmarksDetection.load(
faceLandmarksDetection.SupportedPackages.mediapipeFacemesh
);
// Load Emotion Detection
emotionModel = await tf.loadLayersModel( 'web/model/facemo.json' );
...
})();После этого мы можем написать функцию, которая применяет модель к входным данным ключевых точек лица и возвращает название обнаруженной эмоции:
async function predictEmotion( points ) {
let result = tf.tidy( () => {
const xs = tf.stack( [ tf.tensor1d( points ) ] );
return emotionModel.predict( xs );
});
let prediction = await result.data();
result.dispose();
// Get the index of the maximum value
let id = prediction.indexOf( Math.max( ...prediction ) );
return emotions[ id ];
}Чтобы между тестовыми изображениями можно было делать паузу в несколько секунд, давайте создадим служебную функцию wait:
function wait( ms ) {
return new Promise( res => setTimeout( res, ms ) );
}Теперь, чтобы привести ее в действие, мы можем взять ключевые точки отслеженного лица, масштабировать их до ограничивающего прямоугольника для подготовки в качестве входных данных, запустить распознавание эмоций и отобразить ожидаемый и обнаруженный результат с интервалом 2 секунды между изображениями.
async function trackFace() {
...
let points = null;
faces.forEach( face => {
...
// Add just the nose, cheeks, eyes, eyebrows & mouth
const features = [
"noseTip",
"leftCheek",
"rightCheek",
"leftEyeLower1", "leftEyeUpper1",
"rightEyeLower1", "rightEyeUpper1",
"leftEyebrowLower", //"leftEyebrowUpper",
"rightEyebrowLower", //"rightEyebrowUpper",
"lipsLowerInner", //"lipsLowerOuter",
"lipsUpperInner", //"lipsUpperOuter",
];
points = [];
features.forEach( feature => {
face.annotations[ feature ].forEach( x => {
points.push( ( x[ 0 ] - x1 ) / bWidth );
points.push( ( x[ 1 ] - y1 ) / bHeight );
});
});
});
if( points ) {
let emotion = await predictEmotion( points );
setText( `${setIndex + 1}. Expected: ${ferData[ setIndex ].emotion} vs. ${emotion}` );
}
else {
setText( "No Face" );
}
setIndex++;
await wait( 2000 );
requestAnimationFrame( trackFace );
}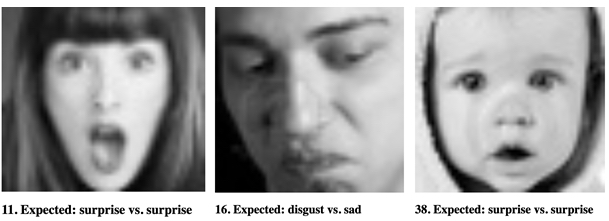
Готово! Наш код должен начать определять эмоции на изображениях FER в соответствии с ожидаемой эмоцией. Попробуйте, и увидите, как он работает.
2. Финишная прямая
Взгляните на полный код применения обученной модели к изображениям из набора данных FER:
<html>
<head>
<title>Running - Recognizing Facial Expressions in the Browser with Deep Learning using TensorFlow.js</title>
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@2.4.0/dist/tf.min.js"></script>
<script src="https://cdn.jsdelivr.net/npm/@tensorflow-models/face-landmarks-detection@0.0.1/dist/face-landmarks-detection.js"></script>
<script src="web/fer2013.js"></script>
</head>
<body>
<canvas id="output"></canvas>
<img id="image" style="
visibility: hidden;
width: auto;
height: auto;
"/>
<h1 id="status">Loading...</h1>
<script>
function setText( text ) {
document.getElementById( "status" ).innerText = text;
}
async function setImage( url ) {
return new Promise( res => {
let image = document.getElementById( "image" );
image.src = url;
image.onload = () => {
res();
};
});
}
function shuffleArray( array ) {
for( let i = array.length - 1; i > 0; i-- ) {
const j = Math.floor( Math.random() * ( i + 1 ) );
[ array[ i ], array[ j ] ] = [ array[ j ], array[ i ] ];
}
}
function drawLine( ctx, x1, y1, x2, y2, scale = 1 ) {
ctx.beginPath();
ctx.moveTo( x1 * scale, y1 * scale );
ctx.lineTo( x2 * scale, y2 * scale );
ctx.stroke();
}
function drawTriangle( ctx, x1, y1, x2, y2, x3, y3, scale = 1 ) {
ctx.beginPath();
ctx.moveTo( x1 * scale, y1 * scale );
ctx.lineTo( x2 * scale, y2 * scale );
ctx.lineTo( x3 * scale, y3 * scale );
ctx.lineTo( x1 * scale, y1 * scale );
ctx.stroke();
}
function wait( ms ) {
return new Promise( res => setTimeout( res, ms ) );
}
const OUTPUT_SIZE = 500;
const emotions = [ "angry", "disgust", "fear", "happy", "neutral", "sad", "surprise" ];
let ferData = [];
let setIndex = 0;
let emotionModel = null;
let output = null;
let model = null;
async function predictEmotion( points ) {
let result = tf.tidy( () => {
const xs = tf.stack( [ tf.tensor1d( points ) ] );
return emotionModel.predict( xs );
});
let prediction = await result.data();
result.dispose();
// Get the index of the maximum value
let id = prediction.indexOf( Math.max( ...prediction ) );
return emotions[ id ];
}
async function trackFace() {
// Set to the next training image
await setImage( ferData[ setIndex ].file );
const image = document.getElementById( "image" );
const faces = await model.estimateFaces( {
input: image,
returnTensors: false,
flipHorizontal: false,
});
output.drawImage(
image,
0, 0, image.width, image.height,
0, 0, OUTPUT_SIZE, OUTPUT_SIZE
);
const scale = OUTPUT_SIZE / image.width;
let points = null;
faces.forEach( face => {
// Draw the bounding box
const x1 = face.boundingBox.topLeft[ 0 ];
const y1 = face.boundingBox.topLeft[ 1 ];
const x2 = face.boundingBox.bottomRight[ 0 ];
const y2 = face.boundingBox.bottomRight[ 1 ];
const bWidth = x2 - x1;
const bHeight = y2 - y1;
drawLine( output, x1, y1, x2, y1, scale );
drawLine( output, x2, y1, x2, y2, scale );
drawLine( output, x1, y2, x2, y2, scale );
drawLine( output, x1, y1, x1, y2, scale );
// Add just the nose, cheeks, eyes, eyebrows & mouth
const features = [
"noseTip",
"leftCheek",
"rightCheek",
"leftEyeLower1", "leftEyeUpper1",
"rightEyeLower1", "rightEyeUpper1",
"leftEyebrowLower", //"leftEyebrowUpper",
"rightEyebrowLower", //"rightEyebrowUpper",
"lipsLowerInner", //"lipsLowerOuter",
"lipsUpperInner", //"lipsUpperOuter",
];
points = [];
features.forEach( feature => {
face.annotations[ feature ].forEach( x => {
points.push( ( x[ 0 ] - x1 ) / bWidth );
points.push( ( x[ 1 ] - y1 ) / bHeight );
});
});
});
if( points ) {
let emotion = await predictEmotion( points );
setText( `${setIndex + 1}. Expected: ${ferData[ setIndex ].emotion} vs. ${emotion}` );
}
else {
setText( "No Face" );
}
setIndex++;
await wait( 2000 );
requestAnimationFrame( trackFace );
}
(async () => {
// Get FER-2013 data from the local web server
// https://www.kaggle.com/msambare/fer2013
// The data can be downloaded from Kaggle and placed inside the "web/fer2013" folder
// Get the lowest number of samples out of all emotion categories
const minSamples = Math.min( ...Object.keys( fer2013 ).map( em => fer2013[ em ].length ) );
Object.keys( fer2013 ).forEach( em => {
shuffleArray( fer2013[ em ] );
for( let i = 0; i < minSamples; i++ ) {
ferData.push({
emotion: em,
file: fer2013[ em ][ i ]
});
}
});
shuffleArray( ferData );
let canvas = document.getElementById( "output" );
canvas.width = OUTPUT_SIZE;
canvas.height = OUTPUT_SIZE;
output = canvas.getContext( "2d" );
output.translate( canvas.width, 0 );
output.scale( -1, 1 ); // Mirror cam
output.fillStyle = "#fdffb6";
output.strokeStyle = "#fdffb6";
output.lineWidth = 2;
// Load Face Landmarks Detection
model = await faceLandmarksDetection.load(
faceLandmarksDetection.SupportedPackages.mediapipeFacemesh
);
// Load Emotion Detection
emotionModel = await tf.loadLayersModel( 'web/model/facemo.json' );
setText( "Loaded!" );
trackFace();
})();
</script>
</body>
</html>Что дальше? Позволит ли это определять наши эмоции на лице?
В этой статье мы объединили выходные данные модели обнаружения ориентиров лица TensorFlow с независимым набором данных, чтобы создать новую модель, которая позволяет извлекать из изображения больше информации, чем раньше. Настоящей проверкой стало бы применение этой новой модели для определения эмоций на любом лице.
В следующей статье этой серии мы, используя полученное с веб-камеры видео нашего лица, узнаем, сможет ли модель реагировать на выражение лица в реальном времени. До встречи завтра, в это же время.

Узнайте подробности, как получить Level Up по навыкам и зарплате или востребованную профессию с нуля, пройдя онлайн-курсы SkillFactory со скидкой 40% и промокодом HABR, который даст еще +10% скидки на обучение.
Другие профессии и курсы
ПРОФЕССИИ
КУРСЫ
