Возникла необходимость поставить дома еще один сервер, и я задался целью мониторить его показатели в домашнем умном доме, в качестве которого используется Home Assistant. Быстрое и потом вдумчивое гугление не дало устраивающих меня универсальных решений, поэтому построил свой велосипед.
Вводные: мониторить будем загрузку и температуру процессора, загрузку оперативной памяти и свопа, свободное место на дисках, продолжительность аптайма, общую загрузку системы, температуру и состояние smart дисков по отдельности, и состояние raid (на сервере с ubuntu server 20 поднят простой софтовый raid1). Диски WD Green, материнская плата GA-525 со встроенным atom525.
На сервере умного дома уже поднят брокер mosquitto, поэтому в качестве метода передачи данных выбран mqtt.
В первых разделах сего труда приведены принципы примененных методов сбора данных, а в конце - скрипты передачи данных и настройки HA.
Все команды в примерах выполняются от пользователя root
Оглавление
Показания системных датчиков
Для получения встроенных датчиков воспользуемся утилитой sensors
Если она не установлена, поставим ее: apt-get install lm-sensors
Сначала надо найти все имеющиеся датчики. Запускаем команду sensors-detect
и отвечаем y на все вопросы. После этого можно поглядеть что получилось: sensors
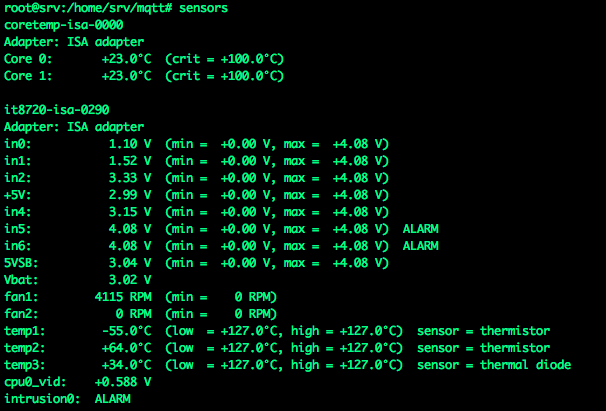
Надо отметить, что лично у меня sensors стал выводить все найденные датчики только после перезагрузки. Может какой то баг, не знаю.
Надо бы как то формализовать вывод. К счастью у sensors есть удобный режим вывода в json, и можно скрыть название адаптора. sensors -A -u -j выдаст длинный json. Вот мой, например.
Ну вот, с этим работать удобнее. Для передачи показаний дальше надо разобрать данные. Для разбора json прямо в консоли есть шикарнейшая утилита - jp. Если она не установлена - для ubuntu она есть в пакетах:apt-get install jq
Определяем xpath нужного параметра. Можно глазами, можно с помощью например этого удобного онлайн-инструмента.
Теперь прямо одной строкой можно получить интересующие нас данные. Я хочу сохранять температуру процессора, одного ядра хватит, частоту вращения кулера, и еще какой то третий сенсор temp3, который показался мне подходящим для косвенной оценки температуры внутри корпуса:sensors -A -u -j | jq '.["coretemp-isa-0000"]["Core 0"].temp2_input'
sensors -A -u -j | jq '.["it8720-isa-0290"].fan1.fan1_input'
sensors -A -u -j | jq '.["it8720-isa-0290"].temp3.temp3_input'

Нагруженность системы
Будем получать процент занятости памяти и свапа, свободное место на диске, интегральную загрузку системы, загрузку процессора, продолжительность аптайма.
Утилизация памяти. Самый простой способ по моему - воспользоваться командой free. Чтобы не ломать глаза, есть параметр -m, выводящий все значения в мегабайтах.

Берем знаничения всего и использовано, и из них вычисляем процент использования. Наверное можно где-нибудь добыть готовый процент, но вдруг понадобится потом исходное значение. free -m | grep "Mem" | awk '{print $2}'

Соответственно в параметр grep отдаем название строки, а в параметр awk - номер столбца, в результате получаем готовую цифру. Дальше по аналогии можно получить остальные данные, а процент вычислить по формуле. В разделе передача данных в скрипте можно найти алгоритм расчета.
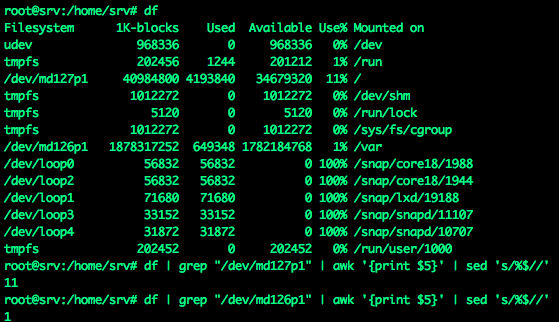
Свободное место на дисках получаем по аналогии, с помощью команды df. Нужные мне данные уже посчитаны в процентах, просто берем готовое, используя тот же подход, что и с памятью. Есть только одно отличие - нам нужна цифра, а тут получится строка. Для удаления символа процента последняя команда: df
df | grep "/dev/md127p1" | awk '{print $5}' | sed 's/%$//'
df | grep "/dev/md126p1" | awk '{print $5}' | sed 's/%$//'
Суммированную загрузку системы можно получить в файле /proc/loadavg. Надо понимать, что цифры там - показатель, измеренный в попугаях. Первые три строки означают среднее количество процессов или потоков, которые выполняются, находятся в очереди на выполнение или ждут завершения операций ввода/вывода за 1, 5 и 15 минут. То есть это не процент и не доля от целого. Просто если это значение представить в виде числа, то большое (больше единицы) число там это плохо, п'нятненько? Я буду брать за 15 минут:cat /proc/loadavg | awk '{print $3}'

Аптайм нам даст команда uptime:uptime | awk '{print $3}' | sed 's/,$//'

Ну и наконец загрузку процессора возьмем у программы mpstat. Я использую именно эту программу, потому что она по умолчанию суммирует ядра, кроме того выдает информацию и тут же заканчивает свой процесс. Тут тоже потребуются арифметические вычисления, потому что все распространенные утилиты отдельно считают задачи пользователя и системы, но зато суммируют время простоя. Таким образом, если мы хотим получить просто цифру загруженности, то надо или из единицы вычесть простой, или сложить все направления. Если mpstat у вас не установлена, то это можно сделать командой apt install sysstat. Итак,mpstat | grep all | awk '{print $13}'

Получение из этого числа конкретного процента загрузки процессора реализовано почти так же как и в случае с вычислением занятой памяти будет в скрипте выгрузки, но есть нюанс.
Дело в том, что му почти наверняка получим нецелое число, и в зависимости от текущей локали там может быть не запятая а точка. Да и вообще bash бывает плохо умеет работать в числами с точкой. Поэтому вычисление текущей загрузки передано программе bccpuidle=$(mpstat | grep all | awk '{print $13}')
cpuload=$(echo "100-$cpuidle" | bc -l)
echo "Текущая загрузка процессора: $cpuload"
Показания состояния жестких дисков
Для получения температуры дисков воспользуемся утилитой hddtemp. Если ее нет, ставим:apt-get install hddtemp
Работать вообще просто: для получения температуры ей указывается устройство, и с параметром -n не будет лишних данных:

Для получения данных со SMART воспользуемся smartmontoolsapt-get install smartmontools
Для использования надо указать на какой диск смотреть, и ключ -a, иначе будет выведена просто короткая справка о диске.smartctl -a /dev/sda
Утилита вываливает целую гору информации, несколько экранов. Не буду приводить тут скриншоты, слишком много. Из всей этой кучи надо выделить интересующие показатели. Я для себя выделил эти:
Raw_Read_Error_Rate — количество ошибок чтения. Ненулевые значения уже требуют внимания, а большие говорят о скором выходе диска из строя. В интернетах пишут, что у некоторых моделей большое значение в этом поле является нормальным. В общем случае значение должно быть равно нулю. А поскольку мы все таки мониторим, нас будет волновать увеличение этого числа;
Reallocated_Sector_Ct — количество перераспределённых секторов. Большое значение говорит о большом количестве ошибок диска;
Seek_Error_Rate — количество ошибок позиционирования. Большое значение говорит о плохом состоянии диска;
Spin_Retry_Count — количество попыток повторной раскрутки. Большое значение говорит о плохом состоянии диска;
Reallocated_Event_Count — количество операций перераспределения секторов;
Offline_Uncorrectable — количество неисправных секторов. Большое значение говорит о повреждённой поверхности.
Чтобы их вытащить из ответа утилиты, можно воспользоваться удобной функцией - вывод значений в формате json. Для этого к строке запуска добавляем параметр -j, вот так:smartctl -a -j /dev/sda
В ответ получим длинный json, для удобства анализа сохраняем в файл. Вот мой. Ваш, скорее всего будет несколько иным. В этом внушительном файле надо глазами или иным образом получить json xpath к интересующим параметрам.
Получив xpath, выделяем конкретную цифру с помощью той же утилиты jq, вот так (в конце в комментарии имя параметра):
smartctl -a /dev/sda -j | jq '.ata_smart_attributes.table[0].raw.value' #Raw_Read_Error_Rate
smartctl -a /dev/sda -j | jq '.ata_smart_attributes.table[3].raw.value' #Reallocated_Sector_Ct
smartctl -a /dev/sda -j | jq '.ata_smart_attributes.table[4].raw.value' #Seek_Error_Rate
smartctl -a /dev/sda -j | jq '.ata_smart_attributes.table[6].raw.value' #Spin_Retry_Count
smartctl -a /dev/sda -j | jq '.ata_smart_attributes.table[12].raw.value' #Reallocated_Event_Count
smartctl -a /dev/sda -j | jq '.ata_smart_attributes.table[14].raw.value' #Offline_Uncorrectable
Кроме того, есть такой ответ на вопрос типа "ты нормально скажи - здоров ты или нет" - запустив утилиту с параметром -H, можно получить суммарный вывод о здоровье диска. У режима тоже есть параметр -j, выводящий структурированный json.

Также выделям его из json:smartctl -a /dev/sda -j | jq '.smart_status.passed' #smart_status
Не забываем о необходимости вовремя тестировать диск, само себя оно не протестирует (наверное)
Некоторые модели дисков тестируют себя сами автоматически, некоторые нет, поэтому чтобы застраховаться, надо запланировать в cron запуск теста. В общем случае достаточно короткого ежедневно и длинного еженедельно.smartctl -t short /dev/sda
быстрое тестирование, занимает около 2 минутsmartctl -t long /dev/sda
расширенный тест, занимает около 1 часа.
Если этот вариант не нравится, у программы есть режим демона, smartd, который сам будет запускать тестирование, и может даже слать отчеты. Отчетов нам не нужно, а вот автотестирование пригодится. Настройку smartd легко нагуглить.
Показания состояния RAID
Дисклеймер
На контролируемом сервере поднят просто raid на mdadm. На разделах дисков создано два массива, для системы и для /var. Рассматривается мониторинг именно такой конфигурации, для иной конфигурации на mdadm можно адаптировать, а про аппаратный raid ничего не знаю.
Самый простой способ узнавать что происходит, что я нашел - это брать уже готовые данные в виртуальной файловой системе sys. [1] [2]
Тут есть определённая проблема - я не нашел способа проверить работоспособность этого метода. Буду исходить из мысли что все хорошо.
Итак, получаем названия разделов cat /proc/mdstat
Вижу что-то такое:
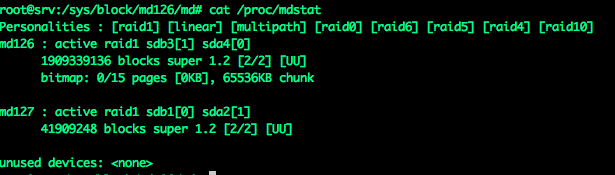
Сначала надо вызвать проверкуecho 'check' >/sys/block/md126/md/sync_action
echo 'check' >/sys/block/md127/md/sync_action
А потом просто взять готовоеcat /sys/block/md126/md/mismatch_cnt
cat /sys/block/md127/md/mismatch_cnt
если команды возвращают 0, то все ок.
Команды запуска проверки запускаем из крона периодически, иначе данные будут неактуальны.
Сбор и передача данных
Если на сервере не установлен клиент mosquitto, то ставим его:apt-get install mosquitto-clients
Создаем где-нибудь скрипты, куда сведем все команды сбора и публикации. Я разделил все операции на три группы - частые (показатели системы), средние (состяние raid и свободного места), и редкие (данные smart):touch system.sh && touch drives.sh && touch smart.sh
chmod u+x system.sh && chmod u+x drives.sh && chmod u+x smart.sh
В созданные файлы пишем:
system.sh
#!/bin/bash #Укажите адрес вашего брокера и учетные данные ip=xx.xx.xx.xx usr="xx" pass="xx" tempdrive1=$(hddtemp "/dev/sda" -n) echo "Температура диска 1: $tempdrive1" tempdrive2=$(hddtemp "/dev/sdb" -n) echo "Температура диска 2: $tempdrive2" tempcpu=$(sensors -A -u -j | jq '.["coretemp-isa-0000"]["Core 0"].temp2_input') echo "Температура процессора: $tempcpu" fan=$(sensors -A -u -j | jq '.["it8720-isa-0290"].fan1.fan1_input') echo "Скорость кулера процессора: $fan" temp3=$(sensors -A -u -j | jq '.["it8720-isa-0290"].temp3.temp3_input') echo "Температура системы: $temp3" totalram=$(free -m | grep "Mem" | awk '{print $2}') echo "Всего памяти: $totalram" usedram=$(free -m | grep "Mem" | awk '{print $3}') echo "Всего использовано памяти: $usedram" usedrampercent=$(($usedram * 100 / $totalram)) echo "Всего использовано памяти в процентах: $usedrampercent" totalswap=$(free -m | grep "Swap" | awk '{print $2}') echo "Всего свопа: $totalswap" usedswap=$(free -m | grep "Swap" | awk '{print $3}') echo "Всего использовано свопа: $usedswap" usedswappercent=$(($usedswap * 100 / $totalswap)) echo "Всего использовано свопа в процентах: $usedswappercent" averageload=$(cat /proc/loadavg | awk '{print $3}') echo "Средняя загрузка системы: $averageload" uptimedata=$(uptime | awk '{print $3}' | sed 's/,$//') echo "Аптайм: $uptimedata" cpuidle=$(mpstat | grep all | awk '{print $13}') cpuload=$(echo "100-$cpuidle" | bc -l) #небольшой костыль, для того чтобы bash нормально обработал точку в поданных данных echo "Текущая загрузка процессора: $cpuload" echo " " echo "Публикация данных" mosquitto_pub -h $ip -t "srv/tempdrive1" -m $tempdrive1 -u $usr -P $pass mosquitto_pub -h $ip -t "srv/tempdrive2" -m $tempdrive2 -u $usr -P $pass mosquitto_pub -h $ip -t "srv/tempcpu" -m $tempcpu -u $usr -P $pass mosquitto_pub -h $ip -t "srv/fan" -m $fan -u $usr -P $pass mosquitto_pub -h $ip -t "srv/temp3" -m $temp3 -u $usr -P $pass mosquitto_pub -h $ip -t "srv/usedrampercent" -m $usedrampercent -u $usr -P $pass mosquitto_pub -h $ip -t "srv/usedswappercent" -m $usedswappercent -u $usr -P $pass mosquitto_pub -h $ip -t "srv/averageload" -m $averageload -u $usr -P $pass mosquitto_pub -h $ip -t "srv/uptimedata" -m $uptimedata -u $usr -P $pass mosquitto_pub -h $ip -t "srv/cpuload" -m $cpuload -u $usr -P $pass
drives.sh
#!/bin/bash #Укажите адрес вашего брокера и учетные данные ip=xx.xx.xx.xx usr="xx" pass="xx" raid_system_status=$(cat /sys/block/md126/md/mismatch_cnt) echo "Исправность RAID системного раздела: $raid_system_status" raid_var_status=$(cat /sys/block/md127/md/mismatch_cnt) echo "Исправность RAID раздела данных: $raid_var_status" freesystemdisk=$(df | grep "/dev/md127p1" | awk '{print $5}' | sed 's/%$//') echo "Занято места на системном разделе: $freesystemdisk" freedatadisk=$(df | grep "/dev/md126p1" | awk '{print $5}' | sed 's/%$//') echo "Занято места на разделе данных: $freedatadisk" echo " " echo "Публикация данных" mosquitto_pub -h $ip -t "srv/raid_system_status" -m $raid_system_status -u $usr -P $pass mosquitto_pub -h $ip -t "srv/raid_var_status" -m $raid_var_status -u $usr -P $pass mosquitto_pub -h $ip -t "srv/freesystemdisk" -m $freesystemdisk -u $usr -P $pass mosquitto_pub -h $ip -t "srv/freedatadisk" -m $freedatadisk -u $usr -P $pass
smart.sh
#!/bin/bash #Укажите адрес вашего брокера и учетные данные ip=xx.xx.xx.xx usr="xx" pass="xx" Raw_Read_Error_Rate1=$(smartctl -a /dev/sda -j | jq '.ata_smart_attributes.table[0].raw.value') echo "SMART Raw_Read_Error_Rate диска 1: $Raw_Read_Error_Rate1" Reallocated_Sector_Ct1=$(smartctl -a /dev/sda -j | jq '.ata_smart_attributes.table[3].raw.value') echo "SMART Reallocated_Sector_Ct диска 1: $Reallocated_Sector_Ct1" Seek_Error_Rate1=$(smartctl -a /dev/sda -j | jq '.ata_smart_attributes.table[4].raw.value') echo "SMART Seek_Error_Rate диска 1: $Seek_Error_Rate1" Spin_Retry_Count1=$(smartctl -a /dev/sda -j | jq '.ata_smart_attributes.table[6].raw.value') echo "SMART Spin_Retry_Count диска 1: $Spin_Retry_Count1" Reallocated_Event_Count1=$(smartctl -a /dev/sda -j | jq '.ata_smart_attributes.table[12].raw.value') echo "SMART Reallocated_Event_Count диска 1: $Reallocated_Event_Count1" Offline_Uncorrectable1=$(smartctl -a /dev/sda -j | jq '.ata_smart_attributes.table[14].raw.value') echo "SMART Offline_Uncorrectable диска 1: $Offline_Uncorrectable1" smart_status1=$(smartctl -a /dev/sda -j | jq '.smart_status.passed') echo "Исправность диска 1: $smart_status1" Raw_Read_Error_Rate2=$(smartctl -a /dev/sdb -j | jq '.ata_smart_attributes.table[0].raw.value') echo "SMART Raw_Read_Error_Rate диска 2: $Raw_Read_Error_Rate2" Reallocated_Sector_Ct2=$(smartctl -a /dev/sdb -j | jq '.ata_smart_attributes.table[3].raw.value') echo "SMART Reallocated_Sector_Ct диска 2: $Reallocated_Sector_Ct2" Seek_Error_Rate2=$(smartctl -a /dev/sdb -j | jq '.ata_smart_attributes.table[4].raw.value') echo "SMART Seek_Error_Rate диска 2: $Seek_Error_Rate2" Spin_Retry_Count2=$(smartctl -a /dev/sdb -j | jq '.ata_smart_attributes.table[6].raw.value') echo "SMART Spin_Retry_Count диска 2: $Spin_Retry_Count2" Reallocated_Event_Count2=$(smartctl -a /dev/sdb -j | jq '.ata_smart_attributes.table[12].raw.value') echo "SMART Reallocated_Event_Count диска 2: $Reallocated_Event_Count2" Offline_Uncorrectable2=$(smartctl -a /dev/sdb -j | jq '.ata_smart_attributes.table[14].raw.value') echo "SMART Offline_Uncorrectable диска 2: $Offline_Uncorrectable2" smart_status2=$(smartctl -a /dev/sdb -j | jq '.smart_status.passed') echo "Исправность диска 2: $smart_status2" echo " " echo "Публикация данных" mosquitto_pub -h $ip -t "srv/Raw_Read_Error_Rate1" -m $Raw_Read_Error_Rate1 -u $usr -P $pass mosquitto_pub -h $ip -t "srv/Reallocated_Sector_Ct1" -m $Reallocated_Sector_Ct1 -u $usr -P $pass mosquitto_pub -h $ip -t "srv/Seek_Error_Rate1" -m $Seek_Error_Rate1 -u $usr -P $pass mosquitto_pub -h $ip -t "srv/Spin_Retry_Count1" -m $Spin_Retry_Count1 -u $usr -P $pass mosquitto_pub -h $ip -t "srv/Reallocated_Event_Count1" -m $Reallocated_Event_Count1 -u $usr -P $pass mosquitto_pub -h $ip -t "srv/Offline_Uncorrectable1" -m $Offline_Uncorrectable1 -u $usr -P $pass mosquitto_pub -h $ip -t "srv/Raw_Read_Error_Rate2" -m $Raw_Read_Error_Rate2 -u $usr -P $pass mosquitto_pub -h $ip -t "srv/Reallocated_Sector_Ct2" -m $Reallocated_Sector_Ct2 -u $usr -P $pass mosquitto_pub -h $ip -t "srv/Seek_Error_Rate2" -m $Seek_Error_Rate2 -u $usr -P $pass mosquitto_pub -h $ip -t "srv/Spin_Retry_Count2" -m $Spin_Retry_Count2 -u $usr -P $pass mosquitto_pub -h $ip -t "srv/Reallocated_Event_Count2" -m $Reallocated_Event_Count2 -u $usr -P $pass mosquitto_pub -h $ip -t "srv/Offline_Uncorrectable2" -m $Offline_Uncorrectable2 -u $usr -P $pass mosquitto_pub -h $ip -t "srv/smart_status1" -m $smart_status1 -u $usr -P $pass mosquitto_pub -h $ip -t "srv/smart_status2" -m $smart_status2 -u $usr -P $pass
Запускаем, убеждаемся что в логах Mosquitto broker в Home Assistant светятся обращения
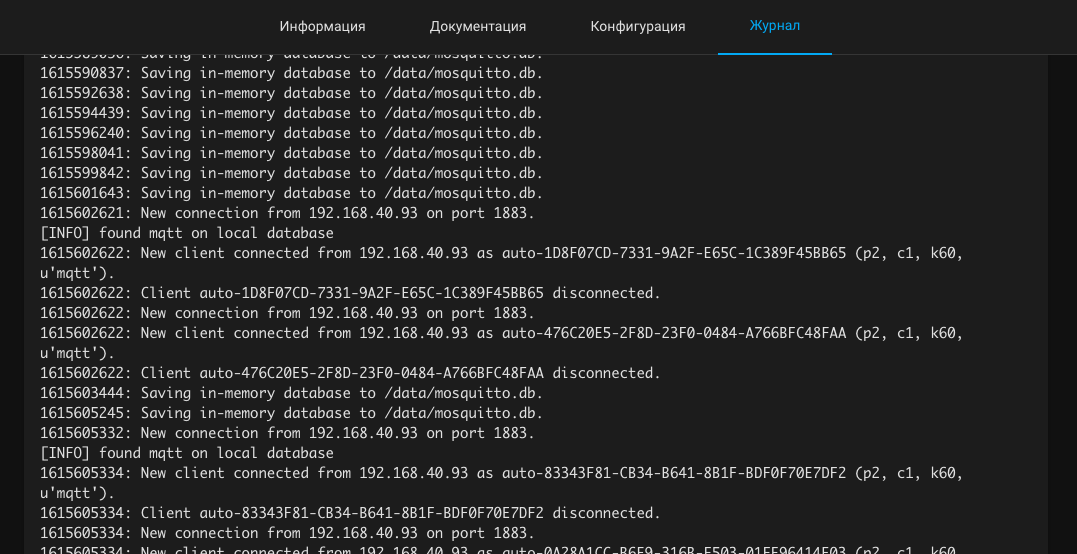
Если не светятся, то или неверно заданы параметры подключения, или брокер закрыт для обращения извне, или не знаю.
Настройка в Home Assistant
Ну, почти все. Осталось в конфиге Home Assistant добавить датчики.
Длинный кусок конфига
sensor: - platform: mqtt state_topic: "srv/tempdrive1" name: "Сервер nextcloud температура диска 1" unit_of_measurement: °C - platform: mqtt state_topic: "srv/tempdrive2" name: "Сервер nextcloud температура диска 2" unit_of_measurement: °C - platform: mqtt state_topic: "srv/tempcpu" name: "Сервер nextcloud температура процессора" unit_of_measurement: °C - platform: mqtt state_topic: "srv/fan" name: "Сервер nextcloud частота кулера" unit_of_measurement: ppm - platform: mqtt state_topic: "srv/temp3" name: "Сервер nextcloud температура системы" unit_of_measurement: °C - platform: mqtt state_topic: "srv/usedrampercent" name: "Сервер nextcloud использовано RAM" unit_of_measurement: "%" - platform: mqtt state_topic: "srv/usedswappercent" name: "Сервер nextcloud использовано SWAP" unit_of_measurement: "%" - platform: mqtt state_topic: "srv/freesystemdisk" name: "Сервер nextcloud занято места на системном разделе" unit_of_measurement: "%" - platform: mqtt state_topic: "srv/freedatadisk" name: "Сервер nextcloud занято места на разделе данных" unit_of_measurement: "%" - platform: mqtt state_topic: "srv/averageload" name: "Сервер nextcloud средняя загрузка системы" - platform: mqtt state_topic: "srv/uptimedata" name: "Сервер nextcloud аптайм" - platform: mqtt state_topic: "srv/cpuload" name: "Сервер nextcloud текущая загрузка процессора" unit_of_measurement: "%" - platform: mqtt state_topic: "srv/Raw_Read_Error_Rate1" name: "Сервер nextcloud диск 1 SMART Raw_Read_Error_Rate" - platform: mqtt state_topic: "srv/Reallocated_Sector_Ct1" name: "Сервер nextcloud диск 1 SMART Reallocated_Sector_Ct" - platform: mqtt state_topic: "srv/Seek_Error_Rate1" name: "Сервер nextcloud диск 1 SMART Seek_Error_Rate" - platform: mqtt state_topic: "srv/Spin_Retry_Count1" name: "Сервер nextcloud диск 1 SMART Spin_Retry_Count" - platform: mqtt state_topic: "srv/Reallocated_Event_Count1" name: "Сервер nextcloud диск 1 SMART Reallocated_Event_Count" - platform: mqtt state_topic: "srv/Offline_Uncorrectable1" name: "Сервер nextcloud диск 1 SMART Offline_Uncorrectable" - platform: mqtt state_topic: "srv/smart_status1" name: "Сервер nextcloud диск 1 SMART статус" - platform: mqtt state_topic: "srv/Raw_Read_Error_Rate2" name: "Сервер nextcloud диск 2 SMART Raw_Read_Error_Rate" - platform: mqtt state_topic: "srv/Reallocated_Sector_Ct2" name: "Сервер nextcloud диск 2 SMART Reallocated_Sector_Ct" - platform: mqtt state_topic: "srv/Seek_Error_Rate2" name: "Сервер nextcloud диск 2 SMART Seek_Error_Rate" - platform: mqtt state_topic: "srv/Spin_Retry_Count2" name: "Сервер nextcloud диск 2 SMART Spin_Retry_Count" - platform: mqtt state_topic: "srv/Reallocated_Event_Count2" name: "Сервер nextcloud диск 2 SMART Reallocated_Event_Count" - platform: mqtt state_topic: "srv/Offline_Uncorrectable2" name: "Сервер nextcloud диск 2 SMART Offline_Uncorrectable" - platform: mqtt state_topic: "srv/smart_status2" name: "Сервер nextcloud диск 2 SMART статус" - platform: mqtt state_topic: "srv/raid_system_status" name: "Сервер nextcloud RAID статус системного раздела" - platform: mqtt state_topic: "srv/raid_var_status" name: "Сервер nextcloud RAID статус раздела данных"
Перезагружаем, запускаем еще разок скрипты на сервере, чтобы данные опубликовались первый раз, и все! Для красоты можно создать карточку на дашборде. Смысла в ней особенно нет, какие то критические показатели можно вынести на главный дашборд, а остальные использовать только в автоматизациях. Но пусть будет:
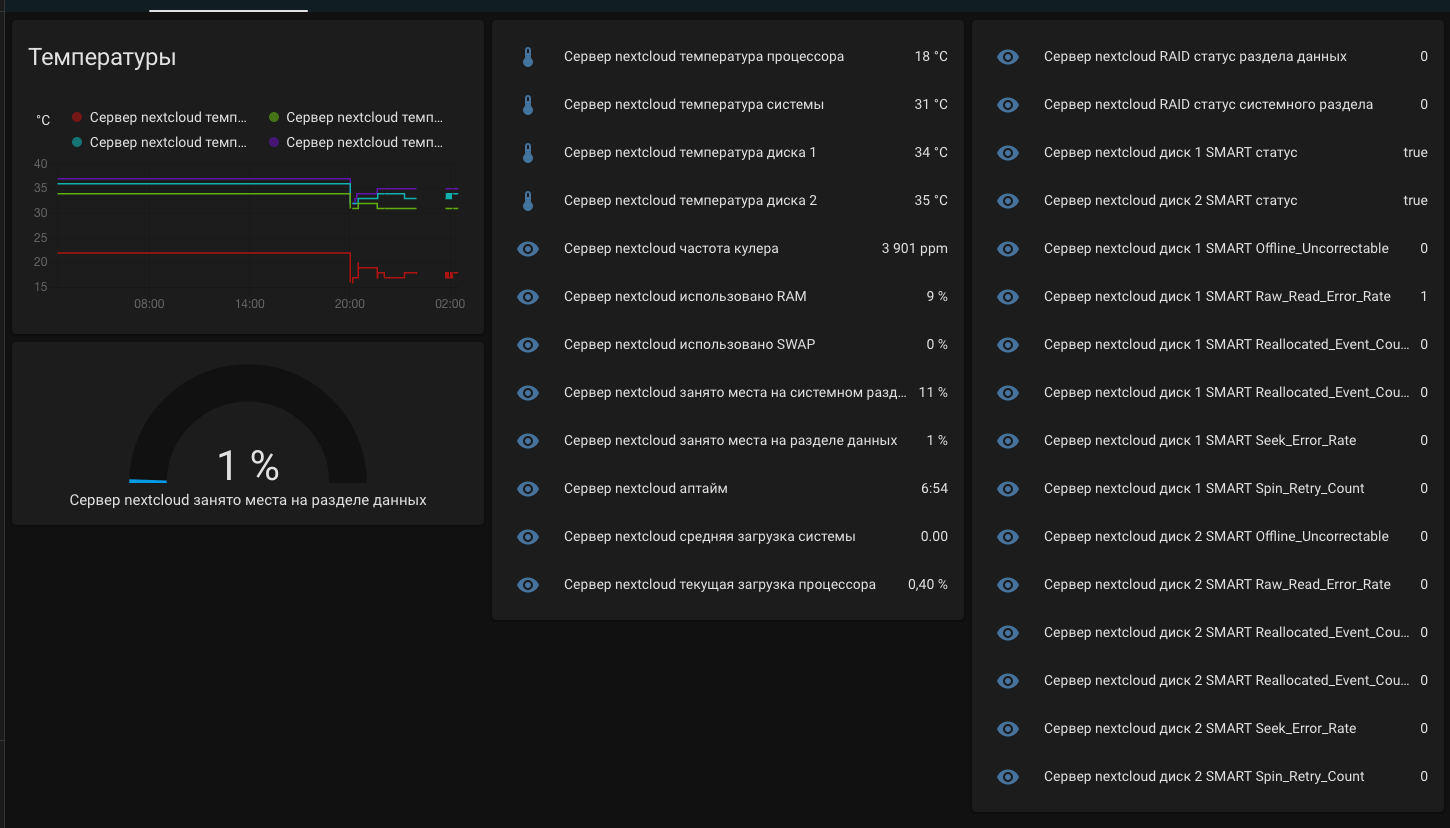
Убедившись что все работает, добавляем скрипты в крон. Системные показатели я передаю раз в полчаса, состояние дисков раз в час, а состояние smart раз в сутки.
Приведенное решение - не панацея, для других конфигураций настройку очевидно надо корректировать на месте. Кроме того, по аналогии можно интегрировать любой параметр. Получаем нужный параметр той или иной программой → приводим его к простому виду → передаем через mqtt.
В следующей статье я опишу свой вариант обратной интеграции - когда linux компьютер выступает в качестве исполнительного элемента для умного дома, то есть меняет состояние устройств, выводит сообщения, воспроизводит звуки.
Также для многих будет не очевидна необходимость контролировать состояние сервера на умном доме - имея задачей только рассылку уведомлений проще делать это непосредственно на контролируемом сервере. Хотя некоторые данные хорошо бы хранить исторически, так что смысл все же есть. Кроме того, я интересно и с пользой провел воскресный вечер.
На скриншоте видно, что обсуждаемый сервер запланирован под nextcloud. Его внутренние показатели тоже можно прекрасно добавить в HA, для этого там есть чудесный api. А у HA есть встроенная интеграция.
Upd1: В комментариях посоветовали утилиту Glances, имеющую встроенную интеграцию с Home Assistant. Из плюсов - готовый работающий вариант. Из минусов - открытый веб-интерфейс на сервере, если это имеет для вас значение.
Умеет собирать значительную часть системной информации из этой статьи
For each detected disk (or mount point) the following sensors will be created:
disk_use_percent: The used disk space in percent.
disk_use: The used disk space.
disk_free: The free disk space.
memory_use_percent: The used memory in percent.
memory_use: The used memory.
memory_free: The free memory.
swap_use_percent: The used swap space in percent.
swap_use: The used swap space.
swap_free: The free swap space.
processor_load: The load.
process_running: The number of running processes.
process_total: The total number of processes.
process_thread: The number of threads.
process_sleeping: The number of sleeping processes.
cpu_use_percent: The used CPU in percent.
sensor_temp: A temperature sensor for each device that provides temperature (depends on platform).
docker_active: The count of active Docker containers.
docker_cpu_use: The total CPU usage in percent of Docker containers.
docker_memory_use: The total memory used by Docker containers.
Upd2: Если речь идет о сервере именно для Nextcloud, то действительно есть встроенная интеграция, которая умеет собирать много информации. Кроме данных о состоянии системы nextcloud, также немного системных данных, таких как объем занятой и всего памяти, свопа, статистическую загрузку из файла /proc/loadavg.
Upd3: Установка и использование Glances
Утилита работает на python, так что он должен быть установлен.
Запускаем установку
pip install glances
или
wget -O- https://bit.ly/glances | /bin/bash
или
apt-get install glances
Все три способа равнозначны, но в последнем еще и зависимости подтянутся. При выборе второго способа рекомендую убедиться что за сокращателем ссылок по прежнему скрипт установки.
После установки запускаем веб-сервер:
glances -w
Теперь если открыть http://ip:61208/ то увидете в браузере все что собирает утилита.
Ну а теперь нужно подключить интеграцию - в HA добавляете новую интеграцию, ищете в списке Glances, в открывшемся окне вводите адрес сервера, порт (по умолчанию 61208), логин/пароль, и готово.
Скриншот
Если результат вас устраивает, то нужно настроить автозапуск веб-сервера, вот инструкция от автора программы.
Лично мне не понравилось. Во первых - утилита сама по себе добавляет немалую загрузку системе. На двухядерном атоме, который является подопытным в этой статье, это до 20% само по себе. Во вторых - лишние зависимости.
Но, если питон используется для чего то еще, зависимости это не проблема, а достаточно мощный сервер такую нагрузку даже не заметит. Кроме того утилита кроссплатформенная, и тот же подход можно использовать для мониторинга и других систем.

