Привет! Я возглавляю направление R&D в компании «ЛАНИТ – Би Пи Эм», которая специализируется на автоматизации бизнес-процессов. Мы исследуем тренды, готовим образовательные программы для технических сотрудников, ведем собственную продуктовую разработку. Наши наработки успешно используются в нескольких компаниях-заказчиках.
Что общего между безопасным хранением паролей и защитой от искажения файлов при скачивании из интернета? Казалось бы, это совершенно про разное. На деле, оба этих алгоритма можно реализовать с помощью хеш-функции. В этой статье мы обзорно поговорим про способы идентификации данных, рассмотрим распространенные сценарии и возможные подходы к их реализации.
Прочитав эту статью, читатели узнают новые способы идентификации данных, выяснят, какие есть технологии взаимодействия с данными, с которыми они сталкиваются в повседневной жизни, познакомятся с интересными и неочевидными сценариями работы. Статья точно будет полезна джунам и системным аналитикам и может пригодиться миддл-разработчикам.
 Источник
Источник
Первый подход, который мы рассмотрим, – когда идентификатор генерируется и приписывается к объекту.
При этом важны:
Наиболее распространённые реализации:
 Как выглядит UUID (uuidtools.com)
Как выглядит UUID (uuidtools.com)
«Глобальные» идентификаторы, например, обеспечивают уникальность и за пределами генерирующей системы, но имеют достаточно большой размер (8-16 байт) и обычно не монотонны. В совокупности это может вызвать проблемы с производительностью при их использовании в индексах / запросах БД.
Подробнее можно почитать здесь:
Второй подход – вместо генерации вычислять идентификатор на основе данных объекта. Это применимо в случаях, когда идентичность всех данных объектов означает и идентичность объектов, т. е. в системе не может / не должно быть двух разных объектов с полностью одинаковыми данными. Чаще всего вычисление идентификатора делается путём хеширования (hash / digest) – «свёртывания» данных объекта, обычно в число фиксированной разрядности.
Для хеширования важны:
Популярные реализации:
Криптоустойчивые реализации:
Преимуществом хеширования является то, что после вычисления хеш может существовать и передаваться отдельно от данных, и его можно вычислить повторно. При этом для криптоустойчивых хеш-функций не получится вычислить по хешу исходные данные или подобрать другие данные с таким же хешом.
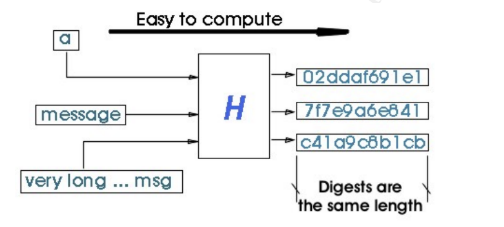 Источник. Вычисление хеша
Источник. Вычисление хеша
В распределённой архитектуре несколько систем со своими БД порождают сущности, которые реплицируются между БД. Идентификаторы сущностей должны быть уникальными в масштабах всей архитектуры.
Пример решения: использовать в качестве идентификатора UUID или Snowflake ID.
В распределённой архитектуре одни системы порождают события, другие — обрабатывают их, причём к потребителям сообщения приходят с гарантией At Least Once, т.е. могут быть дубликаты.
Пример решения: система-производитель генерирует UUID для каждого события, каждая система-потребитель индивидуально ведёт в своей БД учёт обработанных идентификаторов. Поскольку идентификаторы «глобальные», созданные в разных системах идентификаторы будут уникальными.
Имеется большой список объектов, и необходимо ускорить поиск объекта по заданным атрибутам.
Пример решения: реализуется хеш-таблица – для каждого объекта берутся его значения атрибутов поиска и для них вычисляется хеш. Хеш делится по модулю на число строк таблицы, получается номер строки в таблице. Объект помещается в первую свободную ячейку в строке. При поиске по атрибутам вычисляются хеш и номер строки. Далее поиск ведётся уже только по объектам внутри строки поочередным простым сравнением. Хеш-функции позволительно давать коллизии, нужна лишь равномерность значений, чтобы строки таблицы заполнялись одинаково.
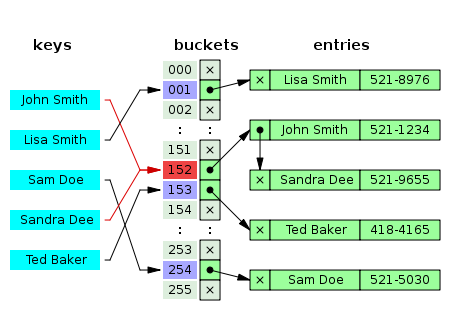 Источник. Хеш-таблица
Источник. Хеш-таблица
Детали реализации хеш-таблиц в Java:
При скачивании больших файлов возможны ошибки передачи, из-за чего содержимое будет искажено. Необходимо на клиенте проверить целостность файла.
Пример решения: публиковать хеш рядом с файлом, вычислять на клиенте хеш скачанного файла и сравнивать со скачанным хешем (контрольной суммой).
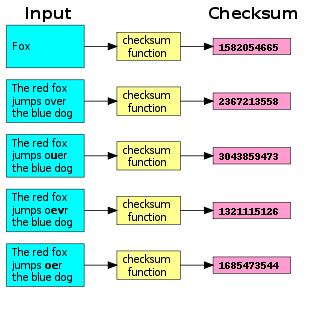 Источник. Вычисление контрольной суммы
Источник. Вычисление контрольной суммы
Для проверки паролей приложение должно хранить эталонные значения, чтобы сверять с вводом пользователей. Хранение в открытом виде небезопасно – администратор / третья сторона могут украсть пароли.
Пример решения: хранить хеш пароля и сравнивать с ним хеш ввода пользователя. Использовать криптоустойчивую хеш-функцию, чтобы невозможно было «развернуть» пароль или подобрать другой, с совпадающим хешем.
Git является распределённым и децентрализованным репозиторием, при этом необходимо уникально идентифицировать каждое изменение (commit).
Пример решения: использовать полную информацию об изменении (файлы, дата изменения, автор, идентификатор предыдущего изменения) для расчёта хеша, который будет идентификатором. Использовать криптоустойчивую хеш-функцию, чтобы исключить совпадение идентификаторов и «подлог» изменений в публичных репозиториях.
 Источник. Идентификаторы в Git
Источник. Идентификаторы в Git
Необходимо подписать документ электронной подписью, при этом алгоритм электронной подписи не может работать с большим объёмом данных или работает медленно.
Пример решения: вычислить хеш документа и наложить подпись на него. В опубликованной подписи задекларировать алгоритм хеширования наряду с алгоритмом подписи, чтобы проверяющая сторона повторила вычисление хеша и проверку подписи.
 Источник. Работа электронной подписи
Источник. Работа электронной подписи
Таким образом, как и в любой задаче, прежде чем выбрать подход к идентификации, нужно подумать, какие есть вводные и ограничения. Самый понятный и простой способ – не всегда самый правильный и эффективный.
Я надеюсь, моя статья поможет вам в решении ежедневных задач. В будущем планирую делиться и другим полезным контентом. Здесь мы перечислили наиболее распространенные сценарии и способы реализации, интересно будет увидеть и другие примеры в ваших комментариях. Поскольку это мой первый опыт написания статьи для Хабра, хочется узнать, понравился ли вам такой обзорный формат или нужно более глубокое погружение в тему.
Что общего между безопасным хранением паролей и защитой от искажения файлов при скачивании из интернета? Казалось бы, это совершенно про разное. На деле, оба этих алгоритма можно реализовать с помощью хеш-функции. В этой статье мы обзорно поговорим про способы идентификации данных, рассмотрим распространенные сценарии и возможные подходы к их реализации.
Прочитав эту статью, читатели узнают новые способы идентификации данных, выяснят, какие есть технологии взаимодействия с данными, с которыми они сталкиваются в повседневной жизни, познакомятся с интересными и неочевидными сценариями работы. Статья точно будет полезна джунам и системным аналитикам и может пригодиться миддл-разработчикам.
Какими бывают подходы к идентификации данных
Генерация идентификаторов
Первый подход, который мы рассмотрим, – когда идентификатор генерируется и приписывается к объекту.
При этом важны:
- уникальность – в рамках области применения не должно быть повторяющихся идентификаторов,
- скорость генерации – высоконагруженные системы могут быть чувствительны к таким расходам,
- монотонность / хронология значений – для отладки и тестирования удобнее иметь короткие, идущие по порядку значения, для безопасности более привлекательными выглядят «случайные» значения,
- тип и размер значений – чаще всего это либо число, либо строка.
Наиболее распространённые реализации:
- последовательность в БД (Sequence / Identity),
- «глобальный» идентификатор (UUID / Snowflake ID).
«Глобальные» идентификаторы, например, обеспечивают уникальность и за пределами генерирующей системы, но имеют достаточно большой размер (8-16 байт) и обычно не монотонны. В совокупности это может вызвать проблемы с производительностью при их использовании в индексах / запросах БД.
Подробнее можно почитать здесь:
Вычисление идентификаторов
Второй подход – вместо генерации вычислять идентификатор на основе данных объекта. Это применимо в случаях, когда идентичность всех данных объектов означает и идентичность объектов, т. е. в системе не может / не должно быть двух разных объектов с полностью одинаковыми данными. Чаще всего вычисление идентификатора делается путём хеширования (hash / digest) – «свёртывания» данных объекта, обычно в число фиксированной разрядности.
Для хеширования важны:
- отсутствие коллизий – вероятность получения одинакового хеша для объектов с разными данными должна быть низкой (насколько низкой – определяется областью применения),
- детерминированность – повторные вычисления хеша для объекта должны давать то же самое значение,
- криптостойкость – «развёртывание» хеша обратно в объект, подбор двух объектов с коллизией хеша и другие атаки должны иметь высокую вычислительную сложность.
Популярные реализации:
- FNV,
- CRC,
- MurmurHash.
Криптоустойчивые реализации:
Преимуществом хеширования является то, что после вычисления хеш может существовать и передаваться отдельно от данных, и его можно вычислить повторно. При этом для криптоустойчивых хеш-функций не получится вычислить по хешу исходные данные или подобрать другие данные с таким же хешом.
Сценарии
Репликация сущностей между БД
В распределённой архитектуре несколько систем со своими БД порождают сущности, которые реплицируются между БД. Идентификаторы сущностей должны быть уникальными в масштабах всей архитектуры.
Пример решения: использовать в качестве идентификатора UUID или Snowflake ID.
Дедупликация событий
В распределённой архитектуре одни системы порождают события, другие — обрабатывают их, причём к потребителям сообщения приходят с гарантией At Least Once, т.е. могут быть дубликаты.
Пример решения: система-производитель генерирует UUID для каждого события, каждая система-потребитель индивидуально ведёт в своей БД учёт обработанных идентификаторов. Поскольку идентификаторы «глобальные», созданные в разных системах идентификаторы будут уникальными.
Быстрый поиск объектов
Имеется большой список объектов, и необходимо ускорить поиск объекта по заданным атрибутам.
Пример решения: реализуется хеш-таблица – для каждого объекта берутся его значения атрибутов поиска и для них вычисляется хеш. Хеш делится по модулю на число строк таблицы, получается номер строки в таблице. Объект помещается в первую свободную ячейку в строке. При поиске по атрибутам вычисляются хеш и номер строки. Далее поиск ведётся уже только по объектам внутри строки поочередным простым сравнением. Хеш-функции позволительно давать коллизии, нужна лишь равномерность значений, чтобы строки таблицы заполнялись одинаково.
Детали реализации хеш-таблиц в Java:
- Откуда растут ноги у hashCode
- Best implementation for hashCode method
- Подробный разбор класса HashMap
Контроль целостности файлов
При скачивании больших файлов возможны ошибки передачи, из-за чего содержимое будет искажено. Необходимо на клиенте проверить целостность файла.
Пример решения: публиковать хеш рядом с файлом, вычислять на клиенте хеш скачанного файла и сравнивать со скачанным хешем (контрольной суммой).
Безопасное хранение паролей
Для проверки паролей приложение должно хранить эталонные значения, чтобы сверять с вводом пользователей. Хранение в открытом виде небезопасно – администратор / третья сторона могут украсть пароли.
Пример решения: хранить хеш пароля и сравнивать с ним хеш ввода пользователя. Использовать криптоустойчивую хеш-функцию, чтобы невозможно было «развернуть» пароль или подобрать другой, с совпадающим хешем.
Компактный производный идентификатор
Git является распределённым и децентрализованным репозиторием, при этом необходимо уникально идентифицировать каждое изменение (commit).
Пример решения: использовать полную информацию об изменении (файлы, дата изменения, автор, идентификатор предыдущего изменения) для расчёта хеша, который будет идентификатором. Использовать криптоустойчивую хеш-функцию, чтобы исключить совпадение идентификаторов и «подлог» изменений в публичных репозиториях.
Объект электронной подписи
Необходимо подписать документ электронной подписью, при этом алгоритм электронной подписи не может работать с большим объёмом данных или работает медленно.
Пример решения: вычислить хеш документа и наложить подпись на него. В опубликованной подписи задекларировать алгоритм хеширования наряду с алгоритмом подписи, чтобы проверяющая сторона повторила вычисление хеша и проверку подписи.
Заключение
Таким образом, как и в любой задаче, прежде чем выбрать подход к идентификации, нужно подумать, какие есть вводные и ограничения. Самый понятный и простой способ – не всегда самый правильный и эффективный.
Я надеюсь, моя статья поможет вам в решении ежедневных задач. В будущем планирую делиться и другим полезным контентом. Здесь мы перечислили наиболее распространенные сценарии и способы реализации, интересно будет увидеть и другие примеры в ваших комментариях. Поскольку это мой первый опыт написания статьи для Хабра, хочется узнать, понравился ли вам такой обзорный формат или нужно более глубокое погружение в тему.
Приходите к нам работать!

