
Всем привет! В этом посте мы расскажем про синтез голосов Сбера, Афины и Джой — виртуальных ассистентов семейства Салют. О том, как мы в SberDevices обучали модели, чтобы сделать синтез живым и специфичным для каждого персонажа, а также с какими проблемами столкнулись и как их решали.
Согласно нашей «библии ассистентов», Сбер — энергичный гик, Афина — взрослая и деловая, а Джой — дружелюбная и веселая. Они отличаются не только уникальными характерами, обращением на «ты»/«вы» и предпочтениями в шутках. Мы попытались сделать так, чтобы их личности отражались и в голосах, которыми они разговаривают.
Персонажей озвучили телеведущая Анастасия Чернобровина (Афина) и актёры дубляжа Даниил Щебланов и Татьяна Ермилова (Сбер и Джой). Виртуальных ассистентов можно услышать в приложениях Сбер Салют, СберБанк Онлайн, нашем колл-центре по номеру 900, а также в устройствах SberBox и SberPortal. Всё, что вы услышите, — это синтез речи, реализованный с помощью нейросетей. Он работает на связке Tacotron 2 и LPCNet.
Но, чтобы было понятно, что, зачем и почему, — немного теории и истории.
1. Теория

Звук — это волна, распространяющаяся в упругой среде — воздухе. Человеческое ухо воспринимает её примерно так: волна, прошедшая через ушную раковину, колеблет барабанную перепонку среднего уха, с которой связаны органы молоточек и наковальня. Они передают колебания во внутреннее ухо с улиточкой и нервами.

Источник изображения.
Похожим образом работают цифровые устройства для записи звука: обычно в микрофонах есть мембрана, которая колеблется от звуковых волн. Отклонения мембраны от первоначального положения записываются микрофоном несколько тысяч раз в секунду (обычно от 8000 до 48000, чаще всего 24000). Получается дискретизованный аудиосигнал, так называемое time domain-представление звука. Синтезировать звук в таком виде — значит авторегрессионно, шаг за шагом, предсказывать 24 тысячи чисел в секунду. Единственный успешный (и революционный) проект, работающий в time domain, — WaveNet от DeepMind, но добиться realtime-синтеза в нём можно только ухищрениями в ущерб качеству.
В задачах speech processing лучше пользоваться time-frequency-представлением звука с помощью спектрограмм (short time Fourier transform, STFT). Математически это временная последовательность модулей преобразования Фурье от коротких (10-20 мс) отрезков звука, внутри которых сигнал можно считать стационарным, то есть его спектральные характеристики почти не меняются за это время. Причины того, почему такой подход работает, тоже можно найти в биологии речевого тракта.

Источник изображения.
Человек разговаривает с помощью голосовых связок и других органов речи. Воздух выдыхается из легких, колеблет мембраны голосовых связок, получается периодический сигнал. Затем он резонирует, проходит через несколько фильтров (горло, нёбо, язык, зубы, губы), обрастает дополнительными гармониками (модулируется) и выходит изо рта в таком виде, в каком мы его слышим. Голосовые связки — это не главный орган речи человека. Например, они никак не участвуют при произнесении глухих согласных — с, п, к, … . На спектрограмме они выглядят как высокочастотные равномерно раскрашенные области, а вокализованные звуки (все гласные и звонкие согласные) — как несколько ярких полос, с наибольшей амплитудой в низкочастотной области (в нижней части спектрограммы). Самая первая (нижняя) полоса называется fundamental frequency (частота основного тона, F0) — это и есть частота колебаний голосовых связок. Следующие гармоники (полосы F1, F2, ...) могут иметь бóльшую амплитуду, но кратны F0.

На мел-спектрограммах каждый столбец на ней представляет собой rFFT от короткого фрагмента аудио. По оси X отложено время, по Y — номер мел-фильтра. Мел-шкала — это такой способ снизить разрешение спектрограмм по частоте с 2000 до 128 (или даже 80) без особенной потери информации. Он основан на психоакустике: восприятие человеком высоты и громкости звука логарифмическое. То есть нам кажется, что звук стал выше на какую-то величину, когда в действительности высота звука выросла в какое-то количество раз. Более подробно про процессинг мел-спектрограмм можно почитать тут.
Несмотря на то, что голосовые связки работают не всегда, они являются очень важной частью речевого тракта человека. Мы управляем их натяжением, что для слушателя звучит как проявление интонаций. Попробуйте шепотом, когда связки не включаются, сказать что-нибудь эмоционально — это будет намного сложнее, чем обычным голосом. Так что, если мы хотим делать интонационно богатый синтез речи, то необходимо каким-то образом контролировать F0.
2. История
Синтезировать речь — значит озвучить заданный текст человеческим голосом. Исторически первый качественный способ решить эту задачу — так называемый concatenative text-to-speech (иногда его называют unit selection). Как текст состоит из букв, так и звук здесь рассматривается как склейка коротких фрагментов аудио — фонем. В русском языке около 47 звуков, но современные concatenative-системы синтеза требуют огромных речевых корпусов (около нескольких гигабайт, это сотни тысяч аудио длиной от нескольких десятков миллисекунд). Это связано с тем, что звучание конкретной фонемы зависит от многих факторов, особенно от её соседей. Синтезированная речь получается монотонной, а артефактов на стыках фрагментов всё равно не удаётся избежать.
Более перспективным выглядит параметрический синтез речи. Это целый класс методов, которые могут быть совсем не похожими друг на друга. Их объединяет то, что синтез происходит в два этапа: сначала одна модель предсказывает параметры речи, а затем вторая по этим параметрам синтезирует нужный звук. Обе модели не обязаны быть нейросетями. Долгое время использовались скрытые марковские модели (HMM) и преобразование Griffin-Lim.
О Griffin-Lim преобразовании
Преобразование Фурье в общем случае комплекснозначное, но для звука физический смысл имеют только вещественные амплитуды, а не фазы (тут комплексные числа представляют в экспоненциальном виде), которые обычно отбрасывают. Поэтому задача восстановления звука из спектрограммы не решается обычным обратным преобразованием Фурье, и приходится делать это приближённо. Например, с помощью алгоритма Гриффина-Лима. Он итеративно применяется к вещественной спектрограмме, чтобы восстановить фазы для обратного преобразования Фурье.
До эпохи нейросетей такой подход проигрывал concatenative-синтезу со всеми его недостатками — так ужасно он звучал. Что-то похожее вы уже слышали — в фантастических фильмах роботы звучат очень механически, железно, и точно также долгое время звучал параметрический синтез. Возможно, тогда появились стереотипы, что синтезированная речь может звучать только так.
В 2017 году Google представил архитектуру нейросети Tacotron, а через полгода — Tacotron 2. Это далеко не первый параметрический синтез с помощью нейросетей, но впервые удалось добиться качества, сравнимого с естественной человеческой речью. Авторы предложили авторегрессионно генерировать по тексту столбцы на мел-спектрограмме. Обучающая выборка — это десятки тысяч пар из текстов и соответствующих им аудиодорожек.
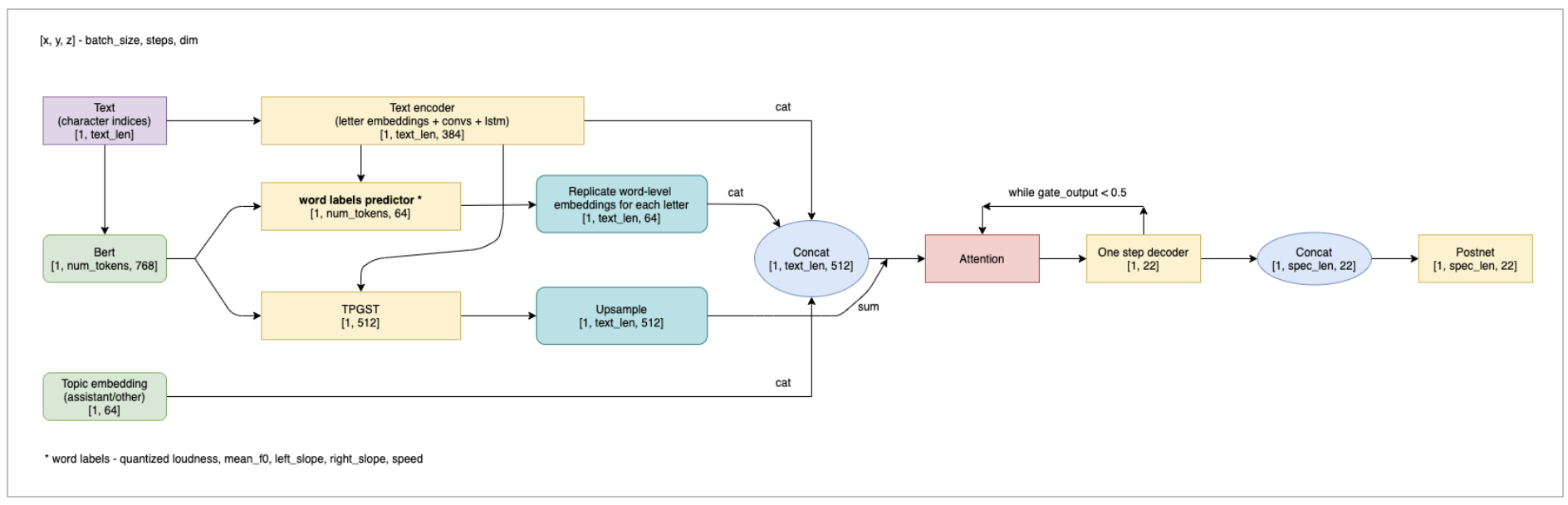
Модель состоит из нескольких модулей. Сначала эмбеддинги букв проходят через энкодер, состоящий из нескольких сверточных слоев и bidirectional LSTM. Так получаются 512-мерные представления букв с учётом контекста. Затем включается авторегрессионный декодер. На каждом его шаге в предсказании участвуют предыдущий сгенерированный столбец на спектрограмме (прошедший через prenet, играющий роль bottleneck) и текст. Attention-механизм смотрит на все буквы в предложении, но показывает декодеру, какую из них мы сейчас синтезируем.
Последняя часть такотрона — Postnet. Она немного сглаживает предсказания и улучшает конечное качество. Сам модуль состоит всего из пяти 1d-сверток по времени.

Затем, когда спектрограмма сгенерировалась целиком, её нужно перевести из time-frequency domain обратно во временное представление. Это делается с помощью отдельной модели — вокодера. Авторы оригинального Tacotron-2 использовали WaveNet, но с тех пор появились более быстрые архитектуры, работающие почти так же качественно. Мы используем LPCNet.
Пример работы первой версии Tacotron. Интонации приятные, но звук звучит железно из-за Griffin-Lim вокодера.
Тот же текст, озвученный Tacotron-2 с вокодером WaveNet. Распознать, что это говорит робот, почти невозможно.
3. Из коробки всё работает плохо
Опыт использование такотрона показывает, что он хорош только в тепличных условиях. Недостатки оригинальной архитектуры проявляются в корнер-кейсах, когда синтез делает явные ошибки. Наиболее частые из них — это неправильно расставленные паузы и ошибки в интонациях. Последнее особенно заметно в вопросительных предложениях: иногда нужной интонации вообще нет, или неправильно выделено вопросительное слово (интонационное ударение на слово называется эмфазой). На слух это звучит неестественно, сразу становится понятно, что говорит робот, а не человек.
Обе проблемы возникают из-за того, что такотрон ничего не знает о смысле слов, которые озвучивает. Причём, даже если он и выучит что-то о языке из обучающей выборки, то что делать со словами, которых он не видел?
GST — попытка хоть каким-то образом контролировать интонацию в такотроне. В статье описано, как их модель обучалась на корпусе из детских книжек, где автор озвучила персонажей разными голосами, а на инференсе хотелось указать персонажа и сгенерировать аудио его голосом. Модуль GST работает так: на обучении спектрограмма всего аудио проходит через bottleneck (несколько свёрточных слоев и один GRU, затем multihead attention на обучаемых токенах), выучивая стиль всего аудио. Под стилем понимается то, как был произнесен текст. Style embedding кодируется 128-мерным вектором, который используется дальше декодером. C одной стороны это позволяет делать перенос стиля, хотя на практике это работает не всегда качественно. А с другой — помогает такотрону лучше выучиться, ведь capacity модели не будет тратиться на предсказание громкости, скорости и тембра каждого слова — за это отвечает стилевой вектор.

Задача style transfer
Перенос стиля — задача style transfer. В ней мы хотим скопировать стиль речи (тембр, скорость, громкость и т.д.) от имеющегося референсного аудио и озвучить заданный текст с этим стилем.
На инференсе нам доступны несколько стратегий: скопировать стиль от референсного аудио, сэмплировать случайный стиль из распределения или попробовать предсказать стилевой вектор по тексту. Последнюю идею авторы предложили в отдельной статье (TP-GST). В ней предлагается предсказывать style embedding по выходу текстового энкодера такотрона.
4. Улучшаем такотрон
Очень хочется использовать в синтезе какую-нибудь языковую модель. Например, самую известную из них — BERT от Google. Мы используем его сразу в нескольких местах: для расстановки пауз, в модуле TP-GST и для предсказания формы контура F0 каждого слова.
О нашем BERT мы уже писали — это текстовый энкодер, обученный на очень большом корпусе русского языка. Модель для каждого слова в предложении (в более строгом смысле — не слова, а bpe-токена) возвращает 768-мерный вектор, кодирующий его смысл с учётом контекста. В наших экспериментах общее качество синтеза растёт, если в предсказании TP-GST использовать не только выход энкодера такотрона, но и эмбеддинг предложения от BERT. А можно ли по таким данным предсказать, в каких местах предложения синтезу стоит сделать паузу?
Оказывается, точность расстановки пауз при генерации речи можно повысить, если предсказывать их с помощью отдельной модели. Для этого нужно обучить такотрон на текстах, в которых в нужных местах стоит специальный символ — пауза. На тех же данных мы обучаем паузную сетку предсказывать, после каких слов нужно поставить этот символ. Простая модель из нескольких слоев над эмбеддингами от BERT прекрасно справляется с такой задачей.
В первом аудио паузы предсказываются текст-энкодером такотрона, во втором — синтез звучит с автоматической расстановкой пауз с помощью отдельной модели. Причём она иногда ошибается: в третьем примере есть пропущенная пауза.
Похожим образом мы контролируем интонации в синтезе. В естественной речи экспрессия выражается в повышении-понижении высоты звука, громкости, скорости (это на уровне слов) и восходящей-нисходящей интонацией всего предложения. Эти характеристики легко формализовать числами — существуют простые алгоритмы для их подсчёта.
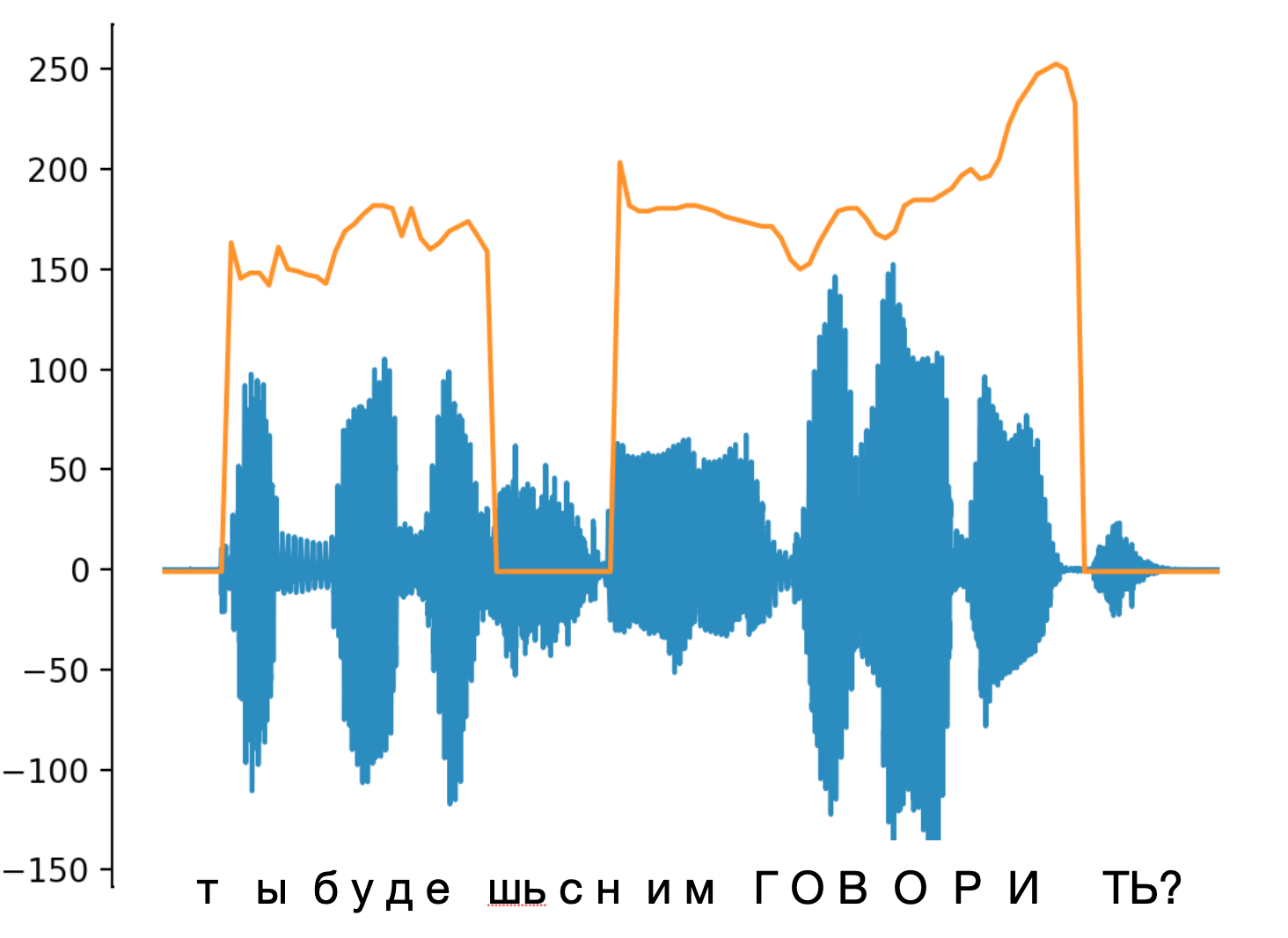
На картинке буквы примерно соотнесены с вейвформой (синий цвет), оранжевым нарисован контур F0, а капсом выделено слово с эмфазой. Чаще всего оно характеризуется растущим или просто высоким F0, и это слышно ушами.
В нашем такотроне используются квантизованные признаки, посчитанные для слов, вместо настоящих (непрерывных) значений. Под квантизацией имеется ввиду, что всё множество значений признака разбивается на несколько бинов, и для конкретного слова смотрится, в какие бины попали его фичи. Это играет роль бутылочного горлышка при обучении такотрона, мешая ему переобучиться, а также упрощает их предсказание.
Благодаря квантизации можно контролировать эмфазу: либо вручную задавать вопросительное слово, либо предсказывать его автоматически.
На инференсе набор меток для каждого слова предсказывает отдельная модель. Её дизайн похож на паузную сетку — используются эмбеддинги от BERT и несколько простых слоёв. Это работает неплохо, но квантизация открывает ещё одну приятную возможность — контролировать интонации вручную, несмотря на предсказания модели. Автор текстов для синтеза может вручную указывать, какое слово произнести громче или быстрее, но есть более интересный юзкейс. В русском языке существует не так много интонационных паттернов в вопросительных предложениях. Например, почти всегда есть вопросительное слово, которое мы выделяем особенной восходящей интонацией. Этого легко добиться, назначив нужным словам метки, отвечающие за восходящий контур F0 (наклон контура, наряду с самим значением фундаментальной частоты, — очень информативная фича). Интересно, что простые rule-based-алгоритмы справляются с автоматическим поиском таких слов в вопросительных предложениях лучше нейросетей, которые работают в остальных случаях.
В вопросительных предложениях правильные интонации особенно важны. Обычный такотрон часто ошибается, и общее качество синтеза сильно вырастет, если управлять интонацией с помощью простой модели, использующей знания о русском языке.
Обычно корпусы обучающих текстов собираются из разных источников. У нас были например, новости, анекдоты, редакторские реплики ассистентов и книги. Мы просили наших дикторов прочитать каждое предложение выразительно и максимально естественно. Но сухие выдержки из новостей и «Всем салют!» разумно читать с совершенно разным настроением. Так мы получили довольно разнообразную выборку, а синтез говорил с неестественно усредненной интонацией. Чтобы решить эту проблему, каждое предложение в обучении мы пометили one-hot-меткой, из какого источника оно взято, и добавили дополнительный вектор (topic embedding) к энкодеру. Это позволило такотрону более качественно обучиться, а нам — выбирать более подходящий стиль голоса для разных текстов.
О влиянии текста на качество синтеза. Оба примера озвучены одной и той же моделью, но во втором используется метка assistant. При обучении в этот topic попали тексты ассистента (их писали редакторы), а в other — остальные (новости, книги, ...).

Все эти модули можно собрать в одну модель. Мы назвали ее q-Tacotron. Каждый из модулей по отдельности улучшает качество, что видно по росту метрик качества. К сожалению, их никак не измерить автоматически, приходится привлекать сервисы crowdsourcing.
5. Меряем качество
В статьях про синтез речи в качестве основной метрики обычно используется MOS — mean opinion score. Респондентам предлагается оценить качество аудио по шкале от 1 до 5. Затем их голоса усредняются, и получается число, обычно около 3.8-4.5. Метрика показывает общее впечатление от синтеза. У нее есть несколько недостатков, поэтому мы разработали другие метрики оценки качества.
Сравнивая 2 похожие модели, по MOS сложно увидеть статистически значимую разницу: результаты получаются одинаковыми в пределах погрешности. Для этих целей разумнее использовать side-by-side тест, или SBS. Он похож на упрощенный до 2 моделей тест MUSHRA. Здесь респондентам даётся выбрать более понравившееся из двух аудио, где один и тот же текст озвучен двумя системами синтеза. Тут становится понятно преимущество этой метрики по сравнению с MOS: если обе модели хорошие, но одна всегда чуть лучше другой, то в SBS будет 100/0, а MOS будут похожими величинами.
Также MOS не говорит ничего конкретного об ошибках модели. Они могут быть нескольких типов: ошибки в произношении (читает мягко модель вместо модэль), в расстановке пауз, в интонациях, а также артефакты аудио (посторонний шум, нечётко выговоренные слова). Помимо SBS с бейзлайном мы меряем также PSER — pronunciation sentence error rate. Эта метрика показывает процент аудио, в которых синтез допускает ошибки. У наших дикторов это число обычно около 5-10% — то есть всего 90-95% предложений человек говорит правильно. Ошибки возникают в основном в корнер-кейсах: мы специально стараемся делать наши тестовые сеты сложными, чтобы видеть узкие места. Оригинальный Tacotron 2 с TP-GST ошибался на нём в более чем 50% предложений. У нашего q-Tacotron — 14% ошибок.
Пример синтеза, когда модель не делает ошибок.
Одним из признаков хорошего синтеза является такой уровень качества, когда на слух невозможно распознать, перед нами искусственная речь или речь живого человека. Для этого мы используем четвёртую метрику — robotness. Для её измерения мы в пропорции 50/50 смешиваем реальные записи от диктора и синтез, и просим респондентов угадать, какое аудио откуда. Затем для искусственных аудио считаем разницу между голосами за синтез и за человека. Если у нас получился идеальный синтез, который говорит неотличимо от человека, то мы должны получить 50/50, то есть метрика robotness будет 0%. Значение метрики в 50% соответствует 25% синтезированным аудио, которые респонденты посчитали произнесёнными человеком. Not great, not terrible.
Примеры синтеза голоса Татьяны Ермиловой (Джой), которые респонденты посчитали произнесёнными человеком (распределение голосов: 3 – за синтез, 7 – за человека).
 с прошлой архитектурой (актуальный на момент измерений production, prod), в которой квантизация каждой фичи была заменена на кластеризацию по всем фичам. She — синтез голоса персонажа Сбер — в озвучке Даниила Щебланова.")

Одно из аудио в тестовом сете, на котором заметно, как сильно выросло качество синтеза.
6. Заключение
У нас получился крутой синтез речи. Это видно по метрикам: по PSER мы по чуть-чуть подбираемся к пределу — человеческим 90-95%. А значение MOS 4.59 сравнимо с 4.526, которое авторы из DeepMind сообщили для оригинального Tacotron 2. В то же время разница между метрикой robotness и идеальным значением 0% пока остаётся большой. То есть синтез разговаривает приятно, но всего 25% синтезированных фраз звучат неотличимо от человека. Помимо очевидных случаев с характерными для синтеза ошибками, на эту метрику влияет общее качество аудио. Оно напрямую зависит от вокодера, который используется для озвучивания предсказанных такотроном спектрограмм. В нашем стеке используется LPCNet, он позволил нашему синтезу работать всего на 2 ядрах CPU в потоковом режиме. Но об этом вокодере мы расскажем в отдельном посте, там много всего интересного.
На самом деле работа над нашим синтезом только начинается. Каждую из метрик можно и дальше оптимизировать, делая синтез ещё лучше. Для этого мы продолжаем записывать дикторов и проводим research в области синтеза речи, NLP и около. Приходите к нам решать интересные задачи :)


{kind=link}
{kind=link}
{kind=link}