
"Размышления без практики приводят к заблуждению, практика без размышления приводит к затруднению."
Мы ведём войну с индивидуальностью у шардов в кластере MongoDB. Это продолжение статьи Шардинг от которого невозможно отказаться, а это значит, что наступила пора конкретики.
Как я и обещал, здесь мы рассмотрим подробнее:
- настройку процесса выравнивания размера шардов
- расчет поправок для коррекции границ
- мониторинг распределения данных в коллекциях
ShardEqualizer
Это вполне себе рабочий инструмент. Он хоть и в бета версии, но с его помощью команда Smartcat очень даже управляет размещением 3.5Tb данных на 9ти шардах.
Написан на C# и опубликован как dotnet tool. Вот тут можно найти его последнюю версию.
Для всех операций с кластером достаточно readonly прав. Результатом любой команды будет либо отчет в консоли, либо файл со скриптами для выполнения.
По всем командам в консоли можно вывести справку с помощью ключа --help
Оправдания
Все операции над своими данными вы выполняете на свой страх и риск.
Файлы со скриптами всегда можно внимательно изучить. Там местами даже есть комментарии.
До тех пор пока вы не выполнили уточнение ключа шардирования, вы всегда можете просто удалить зоны и вернуться в исходное состояние.
Бета версия — это значит, что проработаны все happy path. Но некоторые ошибки конфигурации, крайние условия (только 1 шард) или нештатные ситуации (отвалился шард или пропала связь целиком) могут выглядеть как ошибки. Не стоит пугаться, утилита не может навредить вашим данным. Она не выполняет никаких управляющих команд.
Если вам кажется, что утилита выдает неожиданные результаты, то у вас куча возможностей. Все исходники тут, а я на связи!
Что мы ровняем
Наша исходная цель — выровнять объем данных которые размещены на дисках шардов. Но, мы не можем на него влиять напрямую. Давайте рассмотрим ключевые характеристики которыми мы можем пользоваться для выравнивания данных.
Основные команды которые нам доступны для первичной оценки размещения данных на шардах:
- db.stats() — вывод общей статистики по БД.
- db.collection.stats() — вывод статистики по конкретной коллекции.
- db.collection.getShardDistribution() — вывод распределения чанков.
В разных представлениях из вышеперечисленных команд мы можем получить следующую информацию о данных:
- size — исходный объем данных. По сути это просто объем BSON всего, что мы храним в коллекции.
- storageSize — занимаемый объем на диске. С настройками по умолчанию WiredTiger жмёт данные примерно в 2 раза.
- indexSize — размер индексов.
Теперь надо определиться, какой же из параметров нам выбрать для оптимизации.
Несжатый объем данный (size) — инвариантен, т.к. конкретный набор документов будет иметь одинаковый размер на любом шарде.
Хранимый размер и индексы будут менять размер в зависимости от условий эксплуатации. После удаления или изменения размера документов увеличивается фрагментация их размещения на диске. Индексы же вообще не уменьшаются в размере после удаления данных.
Поэтому основной параметр, который нам остаётся — это исходный объем данных.
Мы можем достаточно точно и предсказуемо выравнивать размер несжатых данных, но это не отменяет мониторинга занимаемого места на дисках. Занимаемое место будет примерно пропорционально объему несжатых данных сразу после resync. С течением времени будет увеличиваться перекос по шардам. Если он будет увеличиваться выше необходимого, то достаточно просто повторить resync.
Проектирование шардинга — это хоть и полезная, но достаточно затратная операция. Поэтому в реальной жизни разработчики скорее всего не будут с этим торопиться.
Значит, кроме шардированных коллекций у нас есть еще и нешардированные. И, скорее всего, будут даже целые нешардированные БД.
Нешардированные коллекции лежат на одном шарде. Если их не учитывать, то простое выравнивание размеров частей шардированных коллекций приведет к тому, что первичный шард будет всегда "перегружен" этими нешардированными коллекциями. Чтобы этого не происходило, мы в процессе выравнивания будем компенсировать размер нешардированных коллекций за счет смещения части данных шардированных коллекций на другие шарды.
Как мы ровняем
Итак, опросив статистику каждой коллекции в кластере, мы можем быстро получить следующий набор чисел:
- Сумма нешардированных данных на каждом шарде — это все нешардированные коллекции. Их мы не можем перемещать, но их размер участвует в выравнивании и его надо будет компенсировать.
- Распределение данных каждой шардированной коллекции по шардам — эти распределения мы можем менять.
Немного математики
Все что мы описали выглядит как задача оптимизации. А такие задачи удобно решать с помощью математического программирования. Мы выберем удобную "выпуклую" функцию ошибки — среднеквадратичное отклонение от оптимума. Это позволит нам перейти в класс задач квадратичного программирования. Их решения можно легко запрограммировать.
Опишем постановку задачи.
Пространство решений
 — общее число коллекций
— общее число коллекций
 — индекс коллекций
— индекс коллекций
 — общее число шардов
— общее число шардов
 — индекс шардов
— индекс шардов
Пространство решений — это размеры частей (partition) коллекций.
Обозначим их как  — размер части коллекции
— размер части коллекции с на шарде s
Соответственно

это вектор из всех этих чисел.
Сумма частей одной коллекции по всем шардам — это общий размер коллекции.
При перемещении данных между шардами эта сумма не меняется.
 — это общий размер коллекции
— это общий размер коллекции c.
За счет этого равенства мы можем понизить размерность пространства решений.
Выразим последнюю часть каждой коллекции через все остальные:

Число переменных уменьшилось на .
Ограничения
Каждая часть всех коллекций должна быть больше нуля и меньше размера этой коллекции

Исходя из анализа реальных данных ограничения могут быть строже. Если шард содержит только jumbo-чанки, значит текущий размер уменьшить нельзя.
Если мы не хотим размещать данные коллекции с на конкретном шарде s, то вносим дополнительное ограничение 
Целевая функция
Размер шарда s опишем формулой

где  — это объем нешардированных данных шарда
— это объем нешардированных данных шарда s.
 — общий объем данных
— общий объем данных
 — это средний размер шарда.
— это средний размер шарда.
К этому числу мы будем стараться приблизить размер каждого шарда.
 — средний размер части коллекции
— средний размер части коллекции c по шардам.
К этому числу мы будем стараться приблизить размер частей коллекции c.
Целевая функция у нас будет состоять из 2-х слагаемых:
- Первое слагаемое описывает выравнивание размера шардов — это квадрат относительного отклонения от среднего размера шарда.
- Второе слагаемое, описывает выравнивание размера частей коллекции на шардах — это квадрат относительного отклонения от среднего размера части коллекции.
Наша более приоритетная цель — выравнивание размера шардов. Второстепенная цель — выравнивание частей коллекций на шардах. Чтобы этого добиться, вес второго слагаемого понизим в 1000 раз. Коэффициент подбирал на практике, и так он дает примерно 0.1% ошибки выравнивания шардов.
Общая формула целевой функции:

Значение этой функции и надо минимизировать.
Решение
Здесь будут хорошо работать разные итерационные алгоритмы. Но для них нужно указать начальное решение, которое бы отвечало ограничениям — это наше текущее состояние.
Чтобы не программировать самому алгоритм оптимизации, я воспользовался библиотекой Accord.Math. В ней реализовано несколько алгоритмов. Я выбрал алгоритм GoldfarbIdnani. На практике на нашей задаче он оказался самым шустрым и стабильным. К сожалению, не смог найти его понятное описание.
После прогона алгоритма мы получим "идеальное" распределение данных каждой коллекции по шардам.
Двигаем границы
Итак, для каждой коллекции у нас известен желаемый размер каждой его части на шарде. Также мы знаем текущие размеры частей коллекции.
Вот пример для пяти шардов:
Текущие размеры (в Gb) — 15, 26, 9, 18, 30
Желаемые размеры — 18, 20, 20, 20, 20 (предположим что на первом шарде еще 2Gb не шардированных данных)
У нас 4 границы. Несложные расчеты дадут нам требуемые смещение границ:
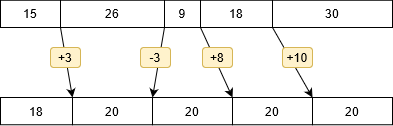
Для каждой границы мы сканируем размеры чанков последовательно в направлении смещения.
Jumbo чанки мы пропускаем.
Набираем сумму чанков, размер которых примерно соответствует требуемому смещению этой границы. И фиксируем границу с новым значением ключа шардирования на границе чанков.
Чтобы зафиксировать смещение границ в БД, нам надо удалить все старые зоны размещения данных коллекции командой sh.removeTagRange, а потом добавить новые зоны размещения данных командой sh.addTagRange.
Практика
Удобнее всего будет потренироваться на маленьких никому не нужных данных. В этом репозитории я собрал все необходимые скрипты для опытов. В docker compose мы можем быстро поднять себе минимальный шардированный кластер. А несложная консольная утилитка заполнит нам тестовую коллекцию данными с нужным распределением.
Теперь заведем директорию под конфигурацию балансировки. Установим в нее ShardEqualizer и приступим к настройке процесса сопровождения шардированного кластера. Основные этапы настройки:
- создаем конфигурацию процесса (подключение к кластеру MongoDB, теги шардов и т.д.)
- уточняем настройки выравнивания шардированных коллекций
- выполняем предварительный расчет границ зон
Сопровождение кластера это:
- контроль распределения данных
- выравнивание размеров шардов
- удаление пустых чанков
Инициализация
Выделяем директорию в которой мы будем хранить настройки шардированного кластера.
Эту директорию можно положить в систему контроля версий, для удобного сопровождения конфигурации.
Лучше выполнить локальную установку утилиты. Так, будет проще управлять версией утилиты.
dotnet new tool-manifest dotnet tool install ShardEqualizer --version 1.0.0-beta.6
Создадим конфигурацию нашего существующего кластера
dotnet ShardEqualizer config-init -h localhost
Будет создан файл configuration.xml со следующими секциями:
- подключение к кластеру
- последовательность шардов по умолчанию
- список шардированных коллекций
Имя файла конфигурации выбрано по умолчанию, но его можно переопределить опцией -с
в командной строке. Также будет создан файл commandPlan_*.js с командами создания зон. Можете оставить их или завести новые по своему усмотрению. Если будете создавать свои зоны, то внесите их в файл конфигурации:
<Defaults zones="shardA,shardB,shardC" />
Для каждой коллекции в опциональном атрибуте zones можно дополнительно указать свой набор или другой порядок зон размещения.
<Interval nameSpace="disbalance.jobs" zones="shardB,shardC" /> <Interval nameSpace="disbalance.locks" zones="shardC,shardB" />
Это нужно для того, чтобы явно разнести данные которые конфликтуют по нагрузке.
Здесь мы не пользуемся авторизацией, но если указать имя пользователя и пароль, то будет дополнительно создан подключаемый файл конфигурации выше по директории.
Предварительное разбиение
Для выделения новых границ надо запустить команду presplit:
dotnet ShardEqualizer presplit
Утилита просканирует чанки коллекций и разобьет их на равные части по числу чанков. Это будет первое приближение к выравниванию. Сейчас, когда данные фрагментированы, без полного сканирования размера чанков, лучшего разбиения не предложить.
Для существующих коллекций будет проверен порядок следования зон в конфигурации. Если он отличается, то в скрипте будет зачистка старых зон. Если не отличается, то коллекция уже дефрагментирована и будет пропущена.
Результатом работы будет скрипт с созданием зон размещения данных.
Примерно такой:
// presplit commands for disbalance.jobs sh.addTagRange( "disbalance.jobs", { "projectId" : MinKey }, { "projectId" : NumberInt(342) }, "shardA"); sh.addTagRange( "disbalance.jobs", { "projectId" : NumberInt(342) }, { "projectId" : NumberInt(683) }, "shardB"); sh.addTagRange( "disbalance.jobs", { "projectId" : NumberInt(683) }, { "projectId" : MaxKey }, "shardC"); // ---
Если указать ключ --renew-current-zones, то это приведет к повторному переразбиению всех коллекций. Это может потребоваться, например, при массовых неравномерных обновлениях данных или при добавлении нового шарда.
Мониторинг перемещения чанков
Перемещение чанков будет длительной операцией. Это приведет к дополнительной нагрузке на сервера. Если это нежелательно в прайм-тайм, то стоит настроить включение балансировщика в удобное время.
Чтобы узнать, что все чанки находятся на положенных им местах, надо выполнить команду balancer:
dotnet ShardEqualizer balancer
Здесь мы сканируем зоны размещения чанков и ищем чанки в неположенных границах.
Будет выведен примерно такой отчет:
Scan intervals ... found 11 chunks awaiting movement. disbalance.jobs: tag range 'shardB' waits for 6 chunks from 'shardA' shards tag range 'shardC' waits for 5 chunks from 'shardB' shards
Общее число недоехавших чанков и их разбивка по коллекциям.
Когда все доехало, надо подождать еще 10-20 минут. Кластер будет подчищать перемещенные данные. Ну или можно включить ожидание удаления, но это увеличит общее время перемещения чанков.
Оценка распределения
Когда чанки перемещены можно оценить распределение данных. Командой deviation можно построить разные отчеты о распределении данных
dotnet ShardEqualizer deviation -sM --format=md --layouts="default,balance"
Основные ключи:
--scale— масштаб размера; задается буквой префикса от K (килобайт) до E (экзабайт)--format— формат вывода таблиц; может быть в CSV или Markdown--layouts— состав колонок таблиц:
default— колонки по всем типам данныхbalance— сокращенный набор для быстрой оценки качества выравнивания
Вот так может выглядеть отчет отрендеренный в Markdown в YouTrack
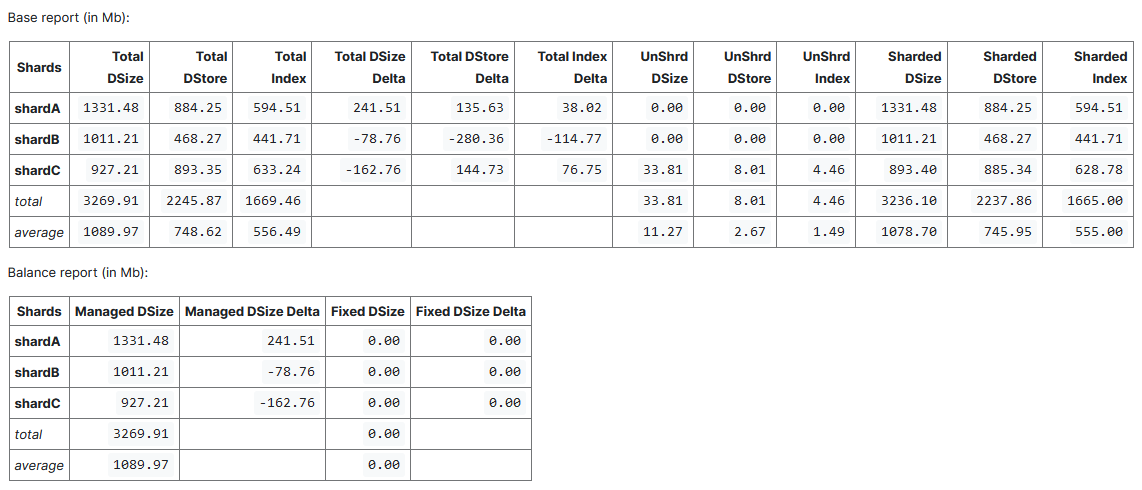
В первой колонке идут имена шардов и обозначение строк с суммой и средним значением.
Обозначения в названиях колонок:
DSize— размер данных в BSON (без сжатия)DStore— занимаемый объем на дискеIndex— размер индексовTotal— все типы коллекцийUnShrd— нешардированные коллекцииSharded— шардированные коллекцииManaged— коллекции, которые выравниваются нашей утилитой, и нешардированные коллекции.Fixed— коллекции, у которых выравнивание выключено (выставлен атрибутadjustable="false"в конфигурации) Это может быть полезно для временных часто меняющихся данных.Delta— в колонке указано отличие от среднего значения
В демонстрационной БД я для примера расположил нешардированную коллекцию на шарде shardC.
По таблице Balance report можно быстро понять, требуется ли нам коррекция.
Колонку Managed DSize Delta будем стремиться держать на около нулевых значениях. Это и есть те значения, которые мы стремимся выровнять.
Выравнивание
Если размер данных на шардах стал сильно отличаться, то мы можем запустить команду выравнивания:
dotnet ShardEqualizer equalize
В консоль будут выведены параметры перемещения границ для каждой коллекции. После этого будет запущен процесс сканирования вдоль границ коллекций. По мере окончания сканирования будет создан файл с командами на замену зон размещения данных.
Основные ключи:
--dry-run— режим "мне только спросить". Вывод отчета с оптимальным положением границ, без сканирования и генерации скриптов смещения границ.--correction-percent— выполнить частичное смещение границ на указанный процент к оптимальному решению.
Если кластер очень сильно разбалансирован, то сканирование может занять много времени. Все это время сервера будут избыточно нагружены. Поэтому лучше выполнять коррекции маленькими порциями.
Вот так будет выглядеть отчет о планируемой коррекции границ
Find solution
Found solution with max deviation of 342.79 Kb between shards
Data move plan:
disbalance.jobs
Require move: 230.93 Mb
Equalize details (in Mb)
| shard | current | target | delta | incoming | left accepted | right accepted |
| shardA | 833.42 | 766.71 | -66.71 | 0.00 | | 66.71 -> shardB |
| shardB | 864.22 | 766.71 | -97.50 | 66.71 | shardA -> 66.71 | 164.22 -> shardC |
| shardC | 569.02 | 733.24 | 164.22 | 164.22 | shardB -> 164.22 | |
Total update pressure:
[shardA] 0 b
[shardB] 66.71 Mb
[shardC] 164.22 Mb
Здесь у нас найдено решение с отклонением от среднего в 342.79 Kb.
Нам предложено переместить 66.71 Mb c shardA на shardB и 164.22 Mb c shardB на shardC.
shardA будет уменьшен на 66.71 Mb
shardB будет уменьшен на 97.50 Mb
shardC будет увеличен на 164.22 Mb
Вот такой файл с командами на смещение границ будет создан после окончания сканирования.
// Found solution with max deviation of 342.79 Kb between shards // Equalize shards from disbalance.jobs // [shardA] > 96.46 Mb > [shardB] > 193.11 Mb > [shardC] // change tags sh.removeTagRange( "disbalance.jobs", { "projectId" : MinKey }, { "projectId" : NumberInt(342) }, "shardA"); sh.removeTagRange( "disbalance.jobs", { "projectId" : NumberInt(342) }, { "projectId" : NumberInt(683) }, "shardB"); sh.removeTagRange( "disbalance.jobs", { "projectId" : NumberInt(683) }, { "projectId" : MaxKey }, "shardC"); sh.addTagRange( "disbalance.jobs", { "projectId" : MinKey }, { "projectId" : NumberInt(304) }, "shardA"); sh.addTagRange( "disbalance.jobs", { "projectId" : NumberInt(304) }, { "projectId" : NumberInt(607) }, "shardB"); sh.addTagRange( "disbalance.jobs", { "projectId" : NumberInt(607) }, { "projectId" : MaxKey }, "shardC"); // --- // Chunks to be moved: 6 // Incoming data by shard: // [shardA] 0 b // [shardB] 96.46 Mb // [shardC] 193.11 Mb
Его надо будет запустить под учетной записью с правами clusterManager. Балансировщик можно при этом не выключать, т.к. он все равно работает с некоторой задержкой и не начнет переносить чанки на момент пересоздания границ.
Ну и далее мы возвращаемся к заголовку Мониторинг перемещения чанков и попадаем в замкнутый процесс наблюдения и коррекций границ по необходимости.
Удаление пустых чанков
Причина пустых чанков — удаление больших групп документов. Если идентификатор группы не переиспользуется (например, у него тип GUID или ObjectId), то новых документов с таким идентификатором больше не будет.
Если мы не уточняли ключ шардирования, то пустые чанки — это бывшие jumbo-чанки с очень узким диапазоном ключей.
Например ровно для одного проекта:
{ min: { projectId: 228 }, max: { projectId: 229 }, }
Если уточняли, то это будут чанки у которых границы содержат одинаковое значение в первом поле.
{ min: { projectId: 3, name: "Job IG5U" }, max: { projectId: 3, name: "Job M7JPO" }, }
В обоих случаях почти невероятно, что в этот чанк попадут новые данные. Копить пустые чанки не стоит, т.к. они немного замедляют работу роутеров и сильно будут замедлять работу утилиты. К счастью, и искать пустые чанки не надо. Мы будем объединять весь диапазон шарда командой:
dotnet ShardEqualizer merge
Результат — файл со скриптами на объединение чанков.
// merge chunks on disbalance.jobs // shard: shardA db.adminCommand({ mergeChunks: "disbalance.jobs", bounds: [ { "projectId" : MinKey, "name" : MinKey }, { "projectId" : NumberInt(4), "name" : "8P9PJRVUX" } ] }); // shard: shardB db.adminCommand({ mergeChunks: "disbalance.jobs", bounds: [ { "projectId" : NumberInt(4), "name" : "8P9PJRVUX" }, { "projectId" : NumberInt(38), "name" : MinKey } ] }); // shard: shardC db.adminCommand({ mergeChunks: "disbalance.jobs", bounds: [ { "projectId" : NumberInt(76), "name" : MinKey }, { "projectId" : MaxKey, "name" : MaxKey } ] }); // --
После объединения мы получим гигантские чанки. Но не стоит беспокоиться. При обновлении или добавлении документов в них, балансировщик опять проведет разбивку. Это займет некоторое время, а для коррекции границ требуются маленькие чанки. Поэтому подчистку пустых чанков лучше делать сразу после очередного выравнивания. Чтобы к следующему дисбалансу размера шардов, чанки уже были достаточно разделены.
Напутствие
Управлять распределением данных оказалось менее страшным, чем первый раз столкнуться с разбалансировкой данных. Нам не выбрать универсальных инструментов на все случаи жизни, и здесь мы рассмотрели всего один особенный сценарий.
Если у вас есть другие интересные сценарии шардинга — обращайтесь, будет что обсудить!

