
Если полноценно рассматривать Dependency Injection, то вокруг этого термина крутится множество интересных инженерных практик. Несмотря на то, что эта статья про конкретный подход к написанию кода, она будет интересна широкому кругу разработчиков. Я постарался провести глубокий анализ существующих около Dependency Injection (DI) принципов разработки и хочу поделиться исследованием с сообществом.
Для тех, кто не знаком с DI, кратко расскажу о нём в следующем разделе. Остальные могут пропустить первую часть и сразу перейти к сути. Добро пожаловать в увлекательный мир Software Engineering!

Что такое DI
В общем случае, когда мы открываем проект, в котором повсеместно используется Dependency Injection, то видим такой контроллер:
namespace Controller; class OrderInfo { private IOrders $orders; public function __construct(IOrder $orders) { $this->orders = $orders; } public function get() { $productDescription = $this->orders->getInformation(); // здесь идёт некоторый код и вызов view } }
Вы спросите меня: «Здесь есть вызов метода getInformation(), но где создаётся объект Order?». Чтобы найти ответ, достаточно посмотреть особый файл. Здесь и ниже буду использовать Symfony DI и конфигурационный файл в yml-нотации.
\Controller\OrderInfo: arguments: - \Service\Order \Service\Order: arguments: - \Model\Product \Model\Product: ~
В нём описываются все классы системы, а также связи между ними. Более того, теперь всем нашим объектам будут автоматически прокидываться необходимые сущности, и сейчас у нас нет нужды ни создавать их, ни владеть знанием об аргументах, которые обязательны для их создания. Почему так и какие плюсы с минусами мы из этого получаем, расскажу в следующих разделах. На этом краткое погружение заканчиваю и перехожу к основной сути статьи.
О чём пойдёт речь
Когда меня спрашивают про Dependency Injection, мне представляется следующая схема разных инженерных подходов и принципов разработки. В статье мы рассмотрим каждый из них по отдельности и пойдём от простого к сложному:
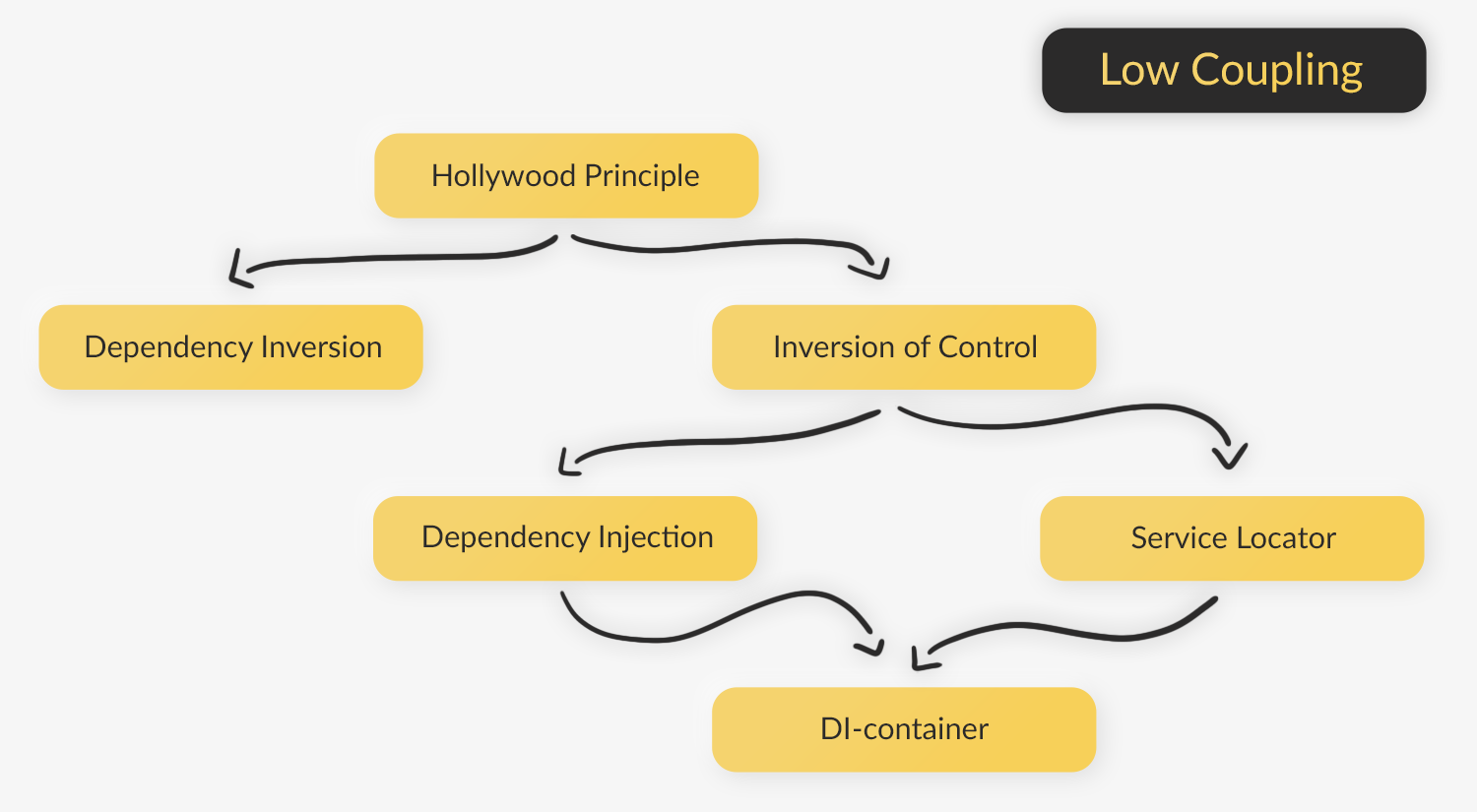
Над большим приложением обычно работает много сотрудников, поэтому в нём неизбежно происходят постоянные изменения. Постоянно внося правки в конечный продукт, важно не выстрелить себе в ногу.
Когда мы решаем крупные задачи, то стараемся разделять их на части поменьше, и тут возникает резонный вопрос: откуда взять критерии качества и то самое решение? Первая логичная идея — это воспользоваться интуицией.
Интуиция — это хорошо. За ней стоит опыт и багаж знаний, который мы накопили. Но, следуя только интуиции, мы рискуем ошибиться в принятии решения. Мы можем десять раз сделать всё верно, а на одиннадцатый совершим ошибку, потому что не опирались на понятные и осязаемые критерии.
Ошибка может быть фатальной с точки зрения проектирования или выработанной архитектуры для решения задачи. Поэтому моя цель — рассказать о разных подходах. Так, если рассмотреть понятие Dependency Injection, то существует большая путаница в терминах, которые я постараюсь выстроить в единую концепцию.
Low Coupling
На мой взгляд, одним из важных и глобальных подходов является Low Coupling или слабая связанность. Все остальные принципы, о которых пойдёт речь, по сути, его переиспользуют.
Слабая связанность, если провести аналогию с реальной жизнью, — это как птицы и двигатель самолета. Они несовместимы, потому что если птица попадёт в двигатель, ничем хорошим это не закончится. Их нужно разделять.
В разработке то же самое: разные вещи надо держать в стороне друг от друга, чтобы с ними было проще работать. Классический пример слабой связанности — это паттерн MVC, где есть три компонента, на которые делятся все программные модули:
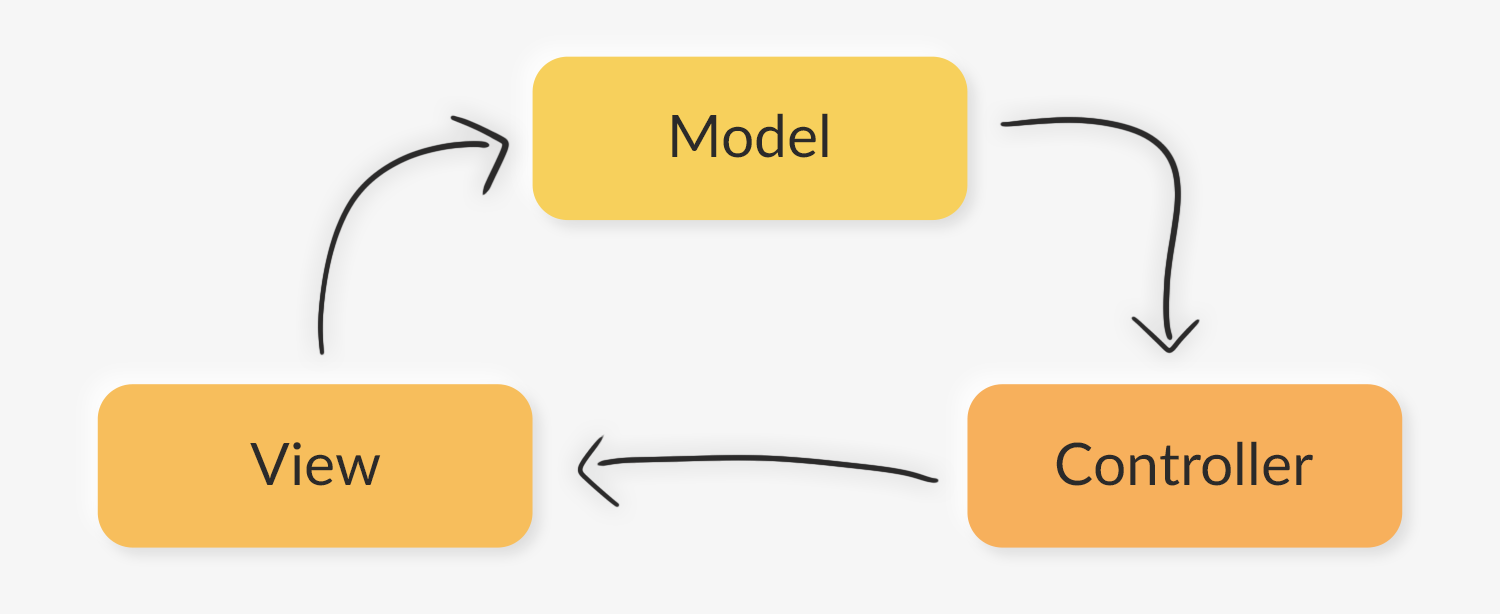
Слабая связанность здесь выражена в том, что можно выбросить один или два компонента из системы и написать новую реализацию, оставив остальные части без изменений. Чтобы это работало, связь между компонентами должна быть минимальной. Если они мало друг с другом коммуницируют или есть известный протокол общения, то разработчику легко переиспользовать уже сделанное, чтобы система продолжала работать с минимальными изменениями и потерями в будущем.
Например, мы пилим монолит на микросервисы. Если связанность между компонентами слабая, пилить будет легко. Если же всё спутано и закрепощено, то задача будет двигаться очень медленно и не так перспективно, как хотелось бы.
Шаблон Low Coupling был описан Крэгом Ларманом в книге «Применение UML 2.0 и шаблонов проектирования». В книге автор сначала задаёт вопрос с проблемой и дальше даёт ответ, как можно её решить. Для Low Coupling это вопрос о том, как уменьшить влияние вносимых изменений на другие объекты. Ответ — минимизировать степень связанности между объектами в процессе распределения обязанностей. Получается, связанность про то, что два компонента или класса имеют связь друг с другом, то есть общаются, вызывают методы, выполняют действия и так далее. Сами эти классы обладают обязанностями, то есть знанием о чём-либо и/или действием (взаимодействием).
Плохой случай, когда мы нарушаем шаблон Low Coupling, выглядит примерно так:
class Order { public function __construct(IDB $db, IDiscount $discount) { $this->db = $db; $this->discount = $discount; } public function calculate() { // ... $product = new Product(); // ... $promo = new Promo(); // ... $warehouse = new Warehouse(); // ... $email = new Notification(); // ... } }
К примеру, мы пишем интернет-магазин, и у нас есть класс «заказ». Здесь плохо то, что класс Order связан с большим количеством разных сущностей: есть и получение классов через конструктор и создание объектов внутри себя. Отвязать Order от всех этих взаимоотношений будет сложно. Система очень закрепощена, связь между компонентами тягучая и сложная.
Чтобы реализация была слабо связанной, а программные модули — легко переиспользуемыми, можно сделать следующее:
class Order { public function __construct( IProductCollection $productCollection, IDiscount $discount ) { $this->productCollection = $productCollection; $this->discount = $discount; } public function calculate() { // ... $promo = new Promo(); // ... } }
Здесь количество связей меньше за счёт того, что мы создаём дополнительные абстракции, которые переносят работу в другие прослойки. В прошлом примере мы создавали продукт, соединялись с базой данных, использовали класс для работы со скидками. А теперь всё это начинают делать другие сущности, которые в ответе дают простую коллекцию с продуктами и передают её в класс Order.
Low Coupling экономит время и усилия, уменьшая количество ошибок при модификации проекта. В тот момент, когда мы хотим что-то изменить, необходимо каждый раз вспоминать про Low Coupling и думать, сколько связей есть в классе. Достаточно просто иметь эту метрику в голове.
Таким образом, мы получили неплохой алгоритм: вспомнили шаблон, подумали о количестве связей, поняли, что всё в порядке, и идём дальше. В этом случае система действительно будет работать хорошо.
Здесь дам идеальную картинку для большей наглядности. Допустим, у нас есть два куба. Это некоторые классы, которые взаимодействуют друг с другом. Точками обозначены методы. Методы хорошо связаны друг с другом, в идеале каждый из них взаимодействует со всеми остальными. Взаимодействием может быть вызов методов других классов.
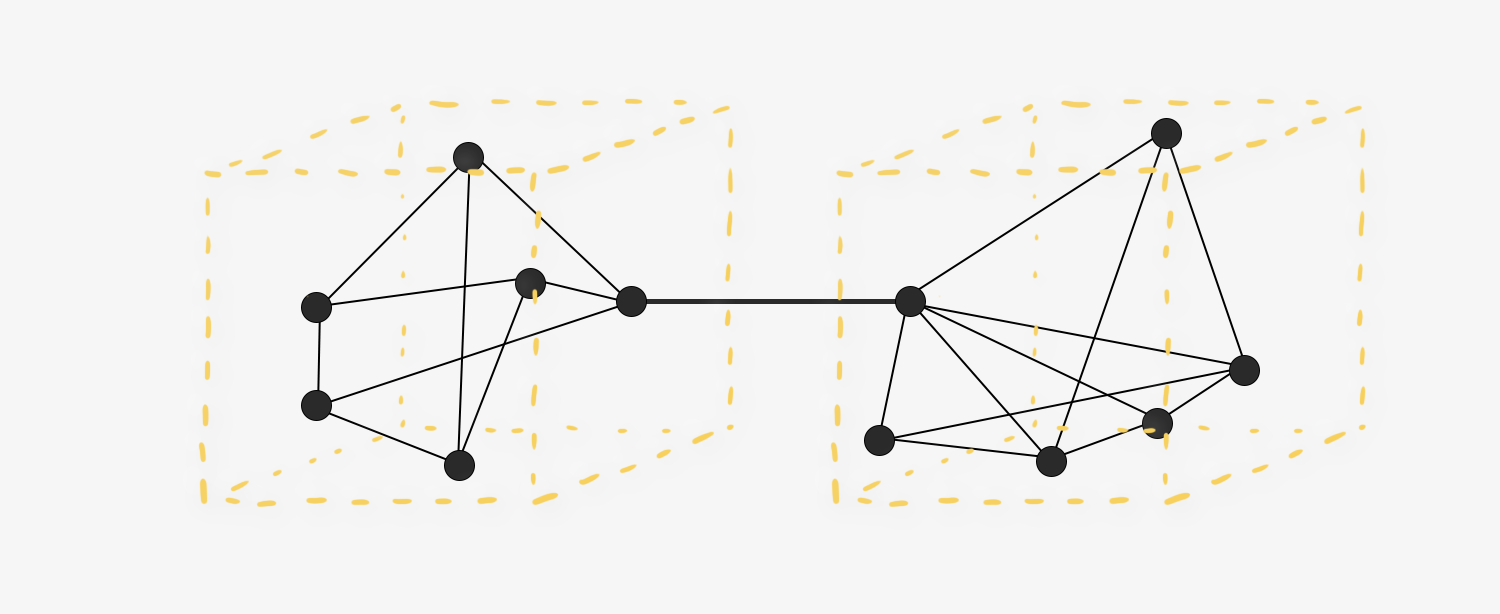
Накладывая принцип Low Coupling, мы видим, что только один метод из первого класса взаимодействует с другим классом. Это и есть слабая связанность, значит, всё сделано как надо.
В паре с Low Coupling всегда идёт High Cohesion или сильное сцепление. Оно про то, что методы должны хорошо сочетаться (контактировать) друг с другом. Не буду на этом подробно останавливаться, можно дополнительно почитать книгу Крэга Лармана.
Тандем слабой связанности и сильного сцепления занимается тем, что задаёт некоторые правила для написания устойчивого к изменениям кода. Они нужны, чтобы проекты могли жить не один месяц, а много лет, и не приходилось переписывать существующий код снова и снова. Чем меньше трудозатрат на изменения, тем больше продуктовых инициатив можно реализовывать в проекте.
Слабая связанность присуща всем подходам, про которые буду говорить дальше.
Dependency Inversion
Второй принцип, о котором хочу рассказать, — это инверсия зависимости. Не путать с Dependency Injection (внедрение зависимости).
Прежде чем рассказывать об инверсии, хочется разобраться, а что же стоит называть прямой зависимостью. Прямая зависимость — это классическая работа с программными компонентами. Например, у нас есть контроллер (Controller), который создаёт объект (Permissions), в котором происходит проверка прав доступа. В свою очередь Permissions создаёт объект алгоритма (Algorithm), в котором происходит разграничение зон ответственностей. Сами права доступа находятся в базе, поэтому в Algorithm создаётся объект ORM для получения данных о текущей роли и правах пользователя.
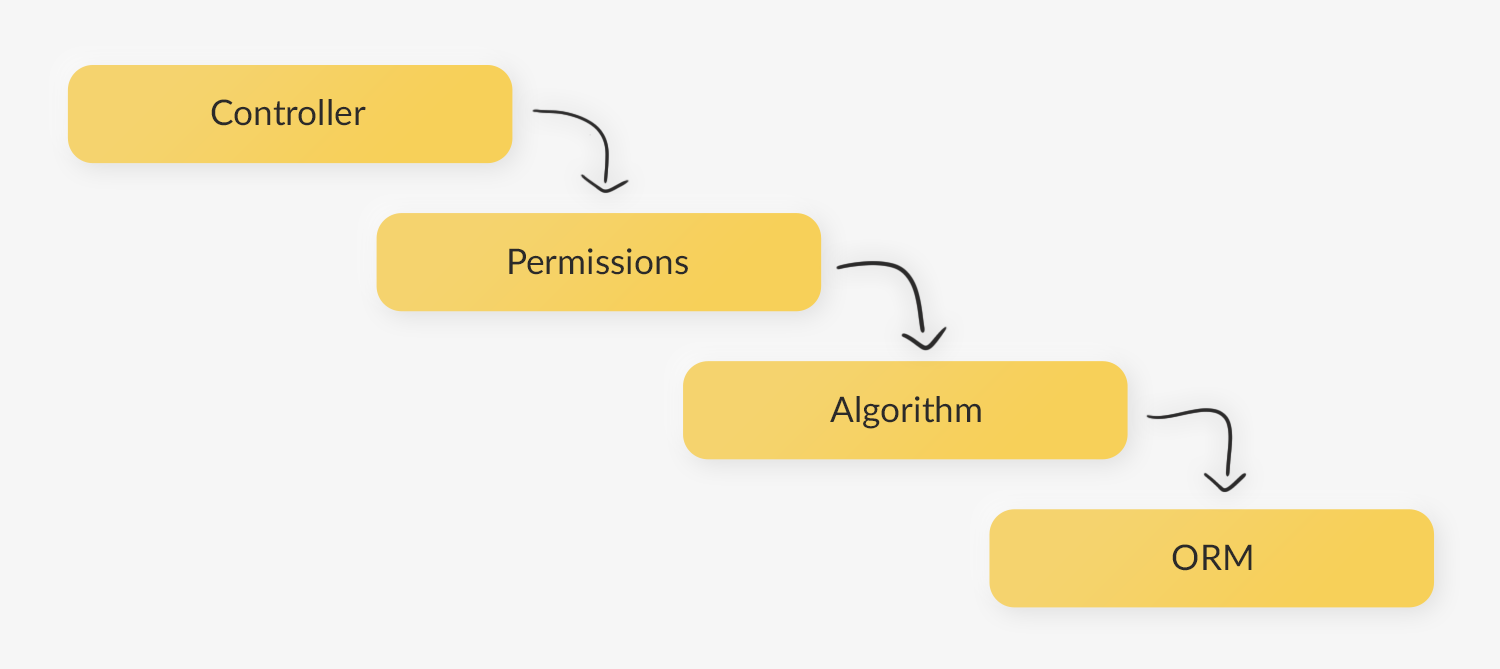
При прямой зависимости эта схема в коде выглядела бы таким образом:
// вызов из контроллера (new Permissions())->getMethod(); class Permissions { public function getMethod() { // ... $algorithm = new Algorithm(); // ... } } class Algorithm { public function getData() { // ... $orm = new ORM(); // ... } } class ORM { // реализация методов }
Проблема в том, что при прямой зависимости все классы достаточно жёстко сцеплены (связаны) друг с другом за счёт конструкции new, которая находится внутри классов. Расцепить эту связь сложно. У нас получилась явная иерархия, сверху вниз, где стек вызовов происходит по цепочке от первого элемента до конечного.
При такой схеме:
Мы не можем подменить реализацию классов, потому что все классы и их создание прописаны прямо внутри тела метода. Выкинуть один класс и заменить его другим становится не так-то просто. Нужно сделать кучу телодвижений и переписать реализации, которые уже были протестированы.
Сложно написать юнит-тесты, поскольку всё вызывается по цепочке.
Бизнес-логика легко начинает растекаться по классам. В итоге становится непонятно, какой класс и какая абстракция должна реализовать ту или иную ответственность.
Увеличивается зависимость классов друг от друга, и слабая связанность теряется.
Решить эти проблемы поможет принцип Dependency Inversion. Он был описан Робертом Мартином в книге «Гибкая разработка программ». У принципа достаточно большое определение:
Модули верхнего уровня не должны зависеть от модулей нижнего уровня, те и другие должны зависеть от абстракций. Абстракции не должны зависеть от деталей. Детали должны зависеть от абстракций.
Если мы воспользуемся данным принципом, то схема начнёт выглядеть следующим образом:
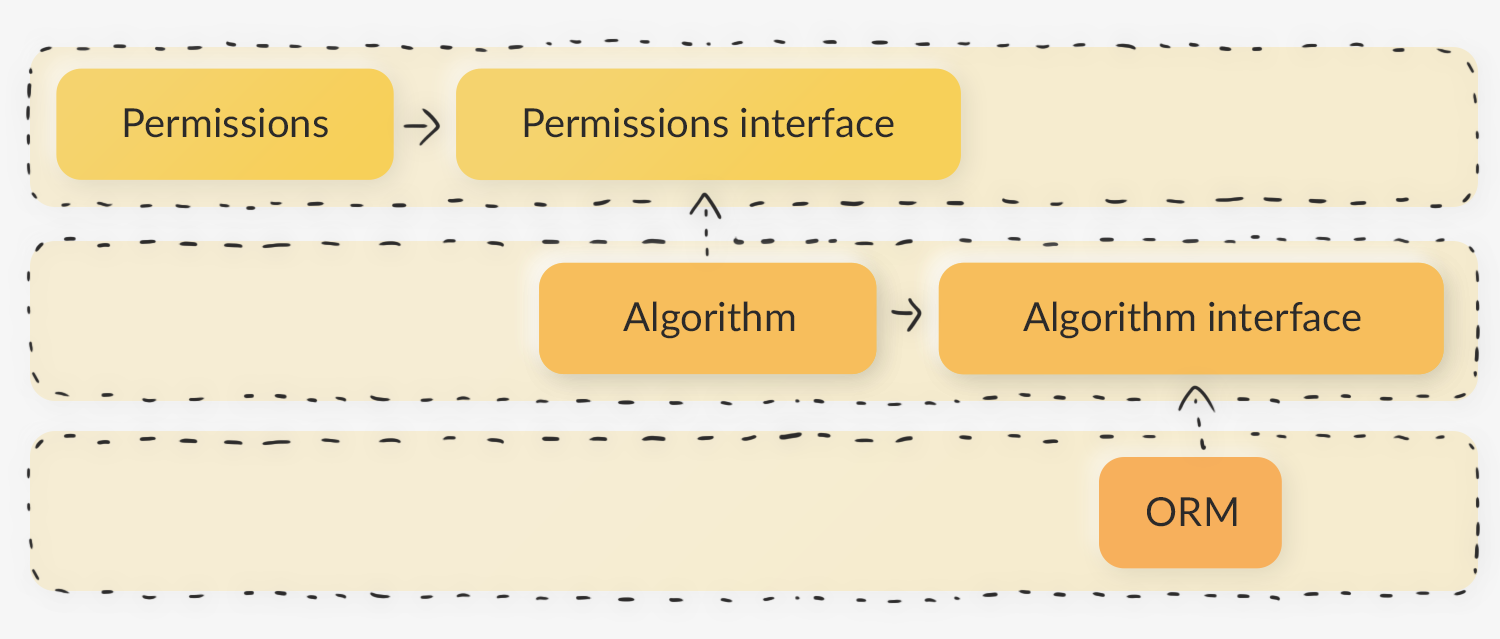
У нас есть всё те же компоненты: контроллер, модуль проверки прав доступа, сущность с алгоритмами и база данных. Но в этом случае вся схема идёт не сверху вниз, а наоборот: нижний объект вкладывается в находящийся выше и так далее. Получается слоистая система, где есть классы и интерфейсы, а на входе в каждый метод или модуль нужно прокидывать в качестве аргумента объект, который лежит ниже по стеку.
Покажу, как это выглядит в коде:
$orm = new ORM(); $algorithm = new Algorithm(); (new Algorithm())->getData($orm); (new Permissions())->getMethod($algorithm); class Permissions { public function getMethod(IRules $rules) { // ... } } class Algorithm implements IRules { public function getData(IDataResolver $dataResolver) { // ... } } class ORM implements IDataResolver { // реализация методов }
Чтобы применить инверсию, нужно вынести процесс создания объектов наверх, то есть убрать их из обозначенных классов. Возможно, это будет контроллер, возможно, некая прослойка или абстракция. Это не столь важно, главное, что они не находятся внутри стека вызова.
В новой схеме созданные объекты передаются через аргументы методов, а дальше мы работаем с ними как первоначально, когда рассматривали прямую зависимость. Нам даже не важно, какими объектами будут оперировать наши классы, самое главное, чтобы они реализовывали интерфейсы указанные в type hinting методов.
Итак. Мы инвертировали поход. Нижние слои теперь создаются первыми и прокидываются в вышележащие объекты. Мы получили весомые плюсы для структуры: теперь объекты не имеют жёсткой связанности, и Low Coupling выполняется идеально. Связей между объектами практически нет. Какой-то один-единственный уровень знает, как сцепить классы, но дальше они существуют автономно друг от друга, и подменить одну реализацию на другую будет несложно.
Если вы работали с Dependency Injection, то можете подумать, что это оно и есть. Почти, но не совсем. Между ними есть небольшая разница.
Здесь мы поговорили про Dependency Inversion, который описан в SOLID-принципах. Почитать про них можно в книгах «Гибкая разработка программ» и «Чистая архитектура». При этом автор Роберт Мартин сам говорит, что прародителем подхода был «Голливудский принцип», который, в свою очередь, использовал другой автор — Мартин Фаулер. Уже он рассказал про Dependency Injection. Эти принципы частично перекликаются, но обладают своими нюансами. Давайте сейчас рассмотрим подход, из которого родилось столько отличных концепций.
Hollywood Principle
Сам по себе Голливудский принцип звучит до банальности просто:
Не звони нам, мы сами позвоним тебе.
Голливудский принцип был описан аж в 1983 году в статье Ричарда Свита «Среда программирования Mesa» (“The Mesa Programming Environment”). Приведу аналогию для запоминания. У нас есть звезда кино и менеджеры. Если вы начинающая звезда, то не надо названивать менеджерам, чтобы стать какой-то суперкрутой звездой. Пока вы не станете известными, они не будут поднимать трубку, зато сами позвонят, когда ваша известность дорастёт до нужного уровня.
Переводя на программистский язык, Голливудский принцип говорит о следующем:
Инструмент должен организовываться так, чтобы предупреждать его, когда пользователь захочет передать какое-то событие. Вместо того, чтобы использовать модель, «запроси у пользователя команду и выполни её».
В определении надо обратить внимание на последнюю фразу. Приложение должно само выполнять команду пользователя, не дожидаясь от него действий. То есть приложение должно каким-то образом понимать, что произошло в системе. Получается, что оно фактически обладает неким разумом или интеллектом.
В итоге мы пришли к тому, что в разработке Голливудский принцип определяет поток управления программой. То есть определяет, кто управляет потоком: человек, программа либо какие-то особые подходы, о которых буду повествовать дальше.
Inversion of Control
Из Голливудского принципа вытекает следующий подход — инверсия контроля. Если переносить инверсию контроля в реальный мир, то это как если бы птицы кормили людей. То же самое будет происходить у некоторых наших программных сущностей. Эти идеи описаны в статьях Мартина Фаулера, и Inversion of Control — его термин.
Если вспомнить Bash-скрипты, то все команды в них выполнялись последовательно, от первой строчки до последней.
#!/bin/bash echo -n "Введите своё имя: " read name say_hello_func name echo -n "Введите свой вопрос: " read question get_answer_func question
В этом листинге мы сначала запрашиваем имя пользователя, далее считываем значение, введенное пользователем, и вызываем некоторую функцию. В нашем случае это некоторая библиотека, которая будет приветствовать нас.
В этом примере мы полностью контролируем ход выполнения программы. После ввода имени поток управления программы передаётся в библиотеку say_hello_func, а затем возвращается обратно, чтобы мы могли продолжить взаимодействие с пользователем.
Дальше мы просим пользователя ввести свой вопрос, где снова передаём поток управления программой следующей библиотеке, которая пытается найти ответ. Такое взаимодействие напоминает общение с Siri или Google, когда ассистент взаимодействует с нами. Всё это является классической реализацией, когда мы полностью управляем ходом выполнения программы и периодически передаём поток библиотекам.
Но существует принципиально другой вариант работы с потоком управления. Он проявляется, когда в проекте используется фреймворк. Обычно при работе с современным приложением мы идём по некому URL, за которым стоит фреймворк, обрабатывающий запрос.
Вспомните инициализацию компонентов в своём фреймворке. Это будет достаточно большой конвейер, состоящий из разных модулей. Выполняя запрос к сайту, фреймворк предзагружает библиотеки, находит нужный роутинг и отрабатывает разные правила, может быть, это поход в базу данных или проверка прав доступа. В какой-то момент мы попадаем в контроллер. Это та точка расширения, которая пишется разработчиком.
class TestController { public function pageAction() { // …код приложения… } }
В такой ситуации мы фактически не являемся руководителем потока управлением программы. Фреймворк сам говорит, как приложение должно работать, и лишь на определённых этапах разработчик пишет расширение к фреймворку и говорит: «У меня есть такие-то ручки, такие-то страницы, которые будут работать тем или иным образом». Это как раз и есть инверсия контроля, когда не мы управляем ходом выполнения программы, а кто-то нами руководит. В данном случае, руководителем процесса будет тот самый фреймворк.
Инверсия контроля — это очередная метрика того, кто управляет ходом выполнения программы: мы, библиотека или фреймворк. Если мы вызываем библиотеку, то, скорее всего, мы же и управляем потоком, потому что пошагово контролируем каждую строчку кода. Во фреймворках контроль начинается лишь тогда, когда мы доходим до контроллера, и всего того кода, который заложили в систему.
Инверсию контроля можно найти в большом количестве разных мест. Если брать книгу Банды Четырёх «Приёмы объектно-ориентированного проектирования. Паттерны проектирования», то это будут такие паттерны, как:
Factory method.
Abstract factory.
Template method.
Strategy.
Помимо этого инверсию можно найти в юнит-тестах, когда вызываются setUp() и tearDown() методы, а также в замыканиях и паттерне Service Locator.
Дальше расскажу о Service Locator, потому что он — часть библиотеки, которая работает как в Symfony DI, так и в других библиотеках, которые вы подключаете, когда хотите работать с Dependency Injection.
Service Locator
Service Locator создаёт и возвращает объекты по требованию. Это уже не абстрактный принцип, а конкретная реализация, обеспечивающая слабую связанность.
Service Locator появился задолго до Dependency Injection и в своё время неплохо справлялся со своей задачей, пока не были представлены лучшие реализации. Идея подхода заключается в следующем. У нас есть некоторое приложение, и вместо того, чтобы создавать конкретные объекты, мы абстрагируем этот процесс, смещая точку их создания в специальную отдельную сущность. Эта сущность и есть Service Locator.
class Car { public function drive() { $motor = Locator::get('motor'); // запуск цилиндрового двигателя $transmission = Locator::get('transmission'); // переключение коробки передач $wheels = Locator::get('wheels'); // вращение колёс } }
В этом примере нет конструкций new motor, new transmission, new wheels. Всё это делает Service Locator. Внутри себя он ищет нужную метку (такую как ‘motor’) и дальше создаёт объект. Данная реализация является лишь примером, паттерн можно реализовывать как угодно. Важна идея.
Плюс подхода в том, что создание классов выделено в отдельную абстракцию, а значит, нам не нужно знать, как создавать эти классы и какие аргументы передавать в конструктор. Также на такую реализацию проще написать тесты.
Service Locator был достаточно популярным, но у него есть свои минусы, из-за чего впоследствии он стал анти-паттерном. Главной проблемой стало то, что вместо зависимости от конкретного класса мы во всем приложении начинаем зависеть от Service Locator и получаем единую точку отказа. Как результат слабая связанность решалась частично. К началу 2010 года от этого подхода практически везде отказались в пользу DI, а Service Locator стал частью DI-библиотек.
Итак, Service Locator инкапсулирует процессы, связанные с получением информации об объектах по некоторому запросу.
Dependency Injection
Dependency Injection похож на кукловода, который управляет программными сущностями. Давайте разберёмся с ним и разницей между инъекцией зависимости и инверсией зависимости, о которой шла речь ранее.
Когда-то существовал вопрос, как лучше создавать классы: писать «new название класса», чтобы получить объект, или делать статическую фабрику, когда статический метод create() создаст внутри себя объект и вернёт его.
class Order { public function getTotalAmount() { $discount = (new Discount())->calculate(); // или $discount = Discount::create()->calculate(); } }
Правильный ответ — ни то, ни другое не подходит. Ни первый, ни второй способ не даёт слабую связанность. Все зависимости в них будут фактически прибиты гвоздями к объектам, и написать удачный юнит-тест или подменить реализацию будет непросто. Поэтому Dependency Injection идёт иным путём.
Dependency Injection решает следующие задачи:
Разрывает жёсткую связь между классом и его вспомогательными сервисами.
Улучшает тестируемость кода.
Уменьшает число классов, адаптирующих код, при переносе в другие приложения.
Позволяет проще переносить в другие приложения классы, находящиеся на верхних уровнях (ближе к контроллеру), а нижние (ближе к базе данных) — менять на другие реализации.
Суть Dependency Injection в том, как внедрять одни объекты в другие. Мартин Фаулер предлагает три способа, как можно это сделать, хотя в интернете можно найти ещё один. Как правило, в реальных проектах используются первые два, третий и четвёртый приведу справочно.
Constructor Injection
Первый вариант — это инъекция через конструктор. Его мы используем практически в каждом проекте, где есть DI.
$order = new Order(new Discount(), new Products()); class Order { private $discount; private $products; public function __construct(IDiscount $discount, IProduct $products) { $this->discount = $discount; $this->products = $products; } public function getTotalAmount() { $totalPrice *= $this->discount->calculate(); } }
В этом варианте через аргументы конструктора внедряются классы. Создание Discount и Products вынесено из Order. В идеале, в type hinting конструктора Order указаны интерфейсы, а не конечные классы. Хотя на практике вариант с интерфейсом чаще всего расточителен и применяется редко.
Плюсы данного подхода в том, что его легко реализовать, здесь нет никаких подводных камней. Все зависимости будут обязательны: всё, что в конструкторе объявлено, то и надо прокидывать. Но будьте аккуратны. Low Coupling говорит, что связь между классами должна быть минимальна. Поэтому если вы будете прокидывать пять и более объектов, то, наверное, что-то идёт не так, и сам по себе класс будет весьма закрепощён.
Минусы инъекции через конструктор в том, что нет возможности не внедрять классы. Все зависимости обязательные. Также нельзя добавить динамичности, когда сначала пробрасывается один набор классов, а затем другой. Да, можно сделать какие-то ухищрения через сеттер-методы, но это немного другое. Если аргументов слишком много, реализация будет выглядеть некрасиво, даже неправильно с точки зрения Low Coupling.
Setter Injection
Второй подход — внедрение через сеттер-методы — чуть менее популярен, но мы его используем, когда нужна опциональность.
$order = (new Order()) ->setDiscount(new Discount()) ->setProducts(new Products()); class Order { private $discount; private $products; public function setDiscount(IDiscount $discount) { $this->discount = $discount; return $this; } public function setProducts(IProduct $products) { $this->products = $products; return $this; } public function getTotalAmount() { $totalPrice = 0; if ($this->products !== null) { foreach ($this->products->getProducts() as $product) { $totalPrice += $product->getPrice(); } } $totalPrice *= $this->discount !== null ? $this->discount->calculate() : 1; } }
Разница между ним и внедрением через конструктор заключается лишь в том, что вместо конструктора есть сеттер-методы. Для каждой зависимости мы создаём отдельный сеттер-метод, и через них внедряем каждую сущность. Тут есть нюанс: нужно добавить проверку на случай, если сеттер-метод не был вызван. В таком случае свойство, отвечающее за сущность, будет иметь значение null.
Плюс данной реализации в том, что есть возможность выбора, внедрять класс или нет, и это можно делать динамически. В теории возможно внедрить сначала первый класс, потом дальше по ходу реализации программы пробросить какой-то другой класс, который удовлетворяет интерфейсу. Такое, в принципе, возможно, хотя и непонятно, зачем.
Минус в том, что можно забыть внедрить какую-то зависимость и в результате не получить что-то в качестве конечного результата. Второй неприятный момент — надо не забывать делать проверки на null и обрабатывать ситуации, если вдруг зависимость не была прокинута изначально. Ещё для каждой зависимости нужно прописывать свой сеттер. Код немного увеличивается в размерах, но это не столь критично.
Инъекция через конструктор и сеттер-методы — это два основных подхода у Dependency Injection. Есть ещё два дополнительных, давайте их рассмотрим.
Interface Injection
В этом варианте зависимость создаётся на основе интерфейса. Правда, каждый интерфейс должен реализовываться одним классом, иначе будет невозможно определить, который класс необходимо выбрать для внедрения.
$order = $container->get('order'); class Order { private $discount; private $products; public function __construct(IDiscount $discount, IProduct $products) { $this->discount = $discount; $this->products = $products; } public function getTotalAmount() { $totalPrice *= $this->discount->calculate(); } }
В таком случае мы можем прокинуть зависимость один к одному. Система сама может догадаться о том, что эту сущность можно прокинуть здесь, и ничего дополнительного делать не нужно. По сути, это тот же самый autoware из Symfony DI. Нам не нужно описывать процесс, мы просто говорим: «создай класс Order, найди зависимости и внедри их». Плюсы и минусы в этом варианте точно такие же, как у инъекции через конструктор.
Property Injection
Последний способ — это внедрение через публичные свойства. Пользоваться им не рекомендую, хоть Symfony DI его и поддерживает.
$order = new Order(); $order->discount = new Discount(); $order->products = new Products(); class Order { public $discount; public $products; public function getTotalAmount() { $totalPrice = 0; if ($this->products !== null) { foreach ($this->products->getProducts() as $product) { $totalPrice += $product->getPrice(); } } $totalPrice *= $this->discount !== null ? $this->discount->calculate() : 1; } }
По смыслу подход похож на сеттер-метод, только сами сеттер-методы писать не нужно, достаточно сделать свойства публичными и добавить в коде проверки на null. Здесь, в общем-то, минимальный код: определили свойства, прокинули и сделали нужные проверки.
Ещё раз повторюсь, делать так не стоит, поскольку через сеттер-методы есть возможность дописать дополнительную бизнес-логику и проверки. Это более надежный способ, чем неконтролируемое добавление данных через публичные свойства.
Разница между Dependency Inversion и Dependency Injection
Рассмотрев четыре способа внедрения зависимости, хочется добавить, что задача Dependency Injection заключается в том, чтобы предоставлять программному компоненту внешнюю зависимость. То есть мы говорим про способ, которым будут доставляться объекты в конкретный instance.
Пройдя долгий путь, мы пришли к самому интересному и готовы понять разницу между принципами. Тут хотелось бы дать сравнение, чем инверсия зависимости отличается от внедрения зависимости. Они делают похожие вещи, но немного по-разному.
Здесь важна идея, с которой подходил каждый из авторов — Роберт Мартин и Мартин Фаулер — к описанию своего принципа. В инверсии зависимости, которая описана в SOLID-принципах, говорится лишь о том, что это подход инвертирования иерархии классов. Он о том, что система переворачивается: нижние модули вкладываются в верхние, верхние — в следующие верхние и так далее. Dependency Injection рассказывает про способ, как внедрять классы друг в друга. В этом, по сути, и есть разница.
Получается, инверсия про то, как относиться к работе с кодом, а внедрение — про способы. При этом в инверсии зависимости неважно, как вы будете прокидывать зависимости — через конструктор или сеттер-методы. Если говорить о первоисточнике, то в нём достаточно было прокинуть зависимость через аргумент вызываемого метода.
Dependency Inversion | Dependency Injection |
Общий принцип инвертирования зависимости. | Конкретные способы внедрения зависимости. |
Если сравнить Service Locator и Dependency Injection, то у них различие уже более явное.
Service Locator | Dependency Injection |
Конечные классы зависят от локатора. | Зависимость внедряется на верхних уровнях. |
В Service Locator конечные классы знают про существование Service Locator и зависят от него. В Dependency Injection зависимость внедряется на верхних уровнях или в отдельной абстракции, а конечные классы ничего не знают о DI, и это очень весомый плюс.
Теперь давайте поговорим про то, во что в конечном счёте вылился Dependency Injection, и что же на самом деле мы используем в своей работе.
DI-контейнер
Как правило, когда мы скачиваем с GitHub очередную библиотеку для подключения в свой проект DI-подходов, то по инерции продолжаем называть подобные ведоровские библиотеки просто DI. Мартин Фаулер же называет их термином «DI-контейнер» или «IoC-контейнер». Почему так?
Для начала сравним, чем отличается инверсия контроля от DI-контейнера. Инверсия контроля — это общий принцип, определяющий поток в нашей программе, а DI-контейнер — это библиотека или некоторый фреймворк, который реализует концепцию Dependency Injection. Inversion of Control — это верхнеуровневая идея или подход, а не программная реализация. DI-контейнер — это уже выраженная в коде библиотека, которую можно скачать через GitHub и использовать в проекте.
Inversion of Control | DI-контейнер |
Общий принцип, определяющий поток управления в программе. | Реализует Dependency Injection в виде библиотеки или фреймворка. |
Интересная особенность: во внутренней реализации вендорских библиотек всегда используется Service Locator. Он, как правило, не торчит наружу. В Symfony DI это называется словом container. Как только вы видите слово container, то должны понимать: ага, это Service Locator, он содержит информацию обо всех классах, описанных в конфигурационном файле (в Symfony DI это может быть yml, xml, php).
Напомню, что Service Locator сейчас имеет статус анти-паттерна, поэтому если вдруг вы обращаетесь в своём коде к контейнеру напрямую, значит, вы что-то делаете не так. Внутри DI-контейнера он отлично справляется со своей задачей, но если начать работать с ним напрямую, это нарушит Low Coupling и свяжет реализации в труднорасширяемый монолит.
Давайте рассмотрим работу DI-контейнера на реальном примере. Всё начинается с того, что мы открываем в браузере некоторый URL, с которым связан контроллер. В таком контроллере мы прокидываем зависимости. В примере ниже их достаточно много. Конечно, это нарушает Low Coupling, но такова действительность: разделение класса на несколько сущностей лишь затруднит работу с классом и вместо положительного эффекта мы получим лишь минусы. Можно сказать, что текущей декомпозиции достаточно для оперирования реализацией, поэтому при использовании того или иного принципа, думайте головой. Принципы — лишь маркеры, чтобы не допустить проблем, а не табу или аксиома.
class Subscription extends Admin { private SubscriptionService $subscriptionService; private ContractService $contractService; private TariffSettings $tariffSettings; private ShopSubscriptionHistory $shopSubscriptionHistory; public function __construct( SubscriptionService $subscriptionService, ContractService $contractService, TariffSettings $tariffSettings, ShopSubscriptionHistory $shopSubscriptionHistory ) { parent::__construct(); $this->subscriptionService = $subscriptionService; $this->contractService = $contractService; $this->tariffSettings = $tariffSettings; $this->shopSubscriptionHistory = $shopSubscriptionHistory; }
Дальше идём в yml-файл, где описаны все зависимости между классами. Без этого конфигурационного файла, к сожалению, DI-контейнер не может существовать. В файле описаны все классы системы, а также требующиеся им зависимости или, другими словами, связь классов друг с другом.
Admin\Subscription: autowire: true
Дальше происходит магия. Если мы говорим про Symfony DI, то конфигурационный файл (например, в yml-формате) нужен не только для описания классов системы, но и для кодогенерации. Когда наше приложение выполняется, оно никогда не работает с yml-файлом. Вместо этого происходит обращение к Cached Container, который создаётся на основе описания yml. В Cached Container как раз описывается, как нужно создать классы с зависимостями.
/** * Gets the public 'Admin\Subscription' shared autowired service. * * @return \Admin\Subscription */ protected function getSubscriptionService() { $a = ($this->services['SubscriptionV2\\ContractService'] ?? $this->getContractServiceService()); return $this->services['Admin\\Subscription'] = new \Admin\Subscription( ($this->services['SubscriptionV2\\SubscriptionService'] ?? $this->getSubscriptionServiceService()), $a, ($this->services['SubscriptionV2\\TariffService'] ?? $this->getTariffServiceService()), ($this->services['ShopSettings\\TariffSettings'] ?? $this->getTariffSettingsService()), new \ShopSubscriptionHistory($a, ($this->privates['SubscriptionV2\\Presenter\\Contract'] ?? $this->getContract2Service())), ($this->services['SubscriptionV2\\PriceCalculator'] ?? $this->getPriceCalculatorService()) ); }
Давайте откроем сгенерированный файл, чтобы посмотреть, каким образом он создаёт и возвращает объекты в проекте. Внутри он состоит из большого числа методов, в каждом из которых формируется единственный объект, а аргументы конструктора мы получаем по цепочке из других методов Cached Container.
Благодаря такой схеме, невозможно получить циклические ссылки. Даже больше того, они будут найдены ещё на этапе кодогенерации Cached Container. Когда в нашем фреймворке будет необходимо создать объект Subscription, будет вызван метод getSubscriptionService(), а он вызовет методы, на основе которых будут созданы объекты, необходимые для конструктора Subscription.
А где здесь Service Locator, спросите вы? Ответ лежит на поверхности: свойство services это и есть Service Locator. Он инкапсулирован в DI-контейнер и хранит внутри себя созданные объекты системы. По сути, это отображение описания классов из yml-файла. Все объекты создаются один раз, на что указывает проверка с тернарным оператором null coalescing. То есть если объект ещё не создавался, будет вызван соответствующий метод, в котором он будет создан, и также он будет присвоен в массив services. При повторном обращении к классу, будет возвращён уже созданный экземпляр объекта. Такое поведение экономит память. Если же вы вдруг работаете с состоянием объекта особым образом, и вам нужен его свежий instance, то в Symfony DI используется параметр shared=false.
Плюсы DI-контейнеров заключаются в следующем. Во-первых, это универсальное решение для сбора полноценного приложения из множества компонентов. Мы можем, грубо говоря, скопировать нужные классы из одного приложения в другое. Чаще всего это некая фантастика, но в целом к этому можно немного приблизиться. Тут главное понять, что DI-контейнеры из-за своей архитектуры делают слабо связанные классы, полностью удовлетворяющие Low Coupling.
Используя их, можно легко подменить один класс другим, поскольку сборка проекта происходит на уровне YAML. Нам нужно лишь правильно прописать тот или иной класс или поменять одну зависимость на другую. Поскольку классы друг о друге не знают, то юнит-тесты или интеграционные тесты пишутся без каких-то сложностей.
Основные минусы в том, что при использовании DI нам становится сложно понять, какие зависимости прокидываются в текущие классы. Решить эту проблему можно в PhpStorm, если использовать плагин Symfony. Благодаря ему проще находить описание класса в yml-файле и, наоборот, переходить из yml в класс. Без плагина приходится многое держать в голове и делать много рутинных действий.
Также эта дополнительная библиотека-прослойка требует, чтобы её поддерживали в актуальном состоянии и следили за актуальностью всех связей. И последний момент: порог входа в проект из-за этого улучшения резко повышается.
Итого
Мы изучили все подходы, которые так или иначе связаны с Dependency Injection, поняли всю иерархию и разобрали, что означает каждый из элементов внутри неё.
Я начинал статью с роли интуиции в инженерной практике. Мы поняли, что интуиция — не совсем то, что помогает строить хорошее и грамотное приложение. Вместо неё лучше использовать проверенные подходы, которые позволяют работать с кодом гибко, удобно и правильно.
Любой подход надо использовать с головой. Если в реализации есть DI или слабая связанность, это не значит, что надо специально уменьшать количество классов. На практике мы часто приходим к тому, что зависимостей всё равно много, потому что так проще работать. Практика и теория могут иногда расходиться, и в этом нет ничего ужасного. Всё должно делаться для удобства.
Если тема показалась вам интересной или хочется погрузиться глубже в материал, то можно дополнительно почитать статьи Мартина Фаулера, в которых он описывает, что такое Inversion of Control:
И также про Dependency Injection:
