
Привет!
Я Жека Никитин, Head of AI в компании Celsus. Больше трех лет мы занимаемся разработкой системы для выявления патологий на медицинских снимках.
Несмотря на то, что медицинским ИИ давно уже никого не удивишь, актуальной и структурированной информации о подводных камнях ML-разработки в этой области не так уж много. В статье я собрал самые «тяжелые» из этих камней — такие как сбор данных, разметка, взаимодействие с врачами и падение метрик при встрече модели с реальностью.
Ориентировался я в первую очередь на ML-разработчиков и DS-менеджеров, но пост может быть интересен и всем любопытствующим, кто хочет разобраться со спецификой CV в медицине.
Собираем данные для обучения
Итак, предположим, вы решили основать ИИ-стартап по детекции рака молочной железы (между прочим, самый распространенный вид онкологии среди женщин) и собираетесь создать систему, которая будет с высокой точностью выявлять на маммографических исследованиях признаки патологии, страховать врача от ошибок, сокращать время на постановку диагноза… Светлая миссия, правда?

Вы собрали команду талантливых программистов, ML-инженеров и аналитиков, купили дорогое оборудование, арендовали офис и продумали маркетинговую стратегию. Кажется, все готово для того, чтобы начать менять мир к лучшему! Увы, все не так просто, ведь вы забыли о самом главном — о данных. Без них нельзя натренировать нейронную сеть или другую модель машинного обучения.
Тут-то и кроется одно из главных препятствий — количество и качество доступных датасетов. К сожалению, в сфере диагностической медицины все еще ничтожно мало качественных, верифицированных, полных наборов данных, а еще меньше из них — публично доступны для исследователей и ИИ-компаний.
Рассмотрим ситуацию на все том же примере детекции рака молочной железы. Более или менее качественные публичные датасеты можно пересчитать по пальцам одной руки: DDSM (порядка 2600 кейсов), InBreast (115), MIAS (161). Есть еще OPTIMAM и BCDR с достаточно сложной и запутанной процедурой получения доступа.
И даже если вы смогли собрать достаточное количество публичных данных, вас будет ждать следующая преграда: практически все эти датасеты разрешено использовать лишь в некоммерческих целях. Кроме того, разметка в них может быть абсолютно разная — и не факт, что подходящая под вашу задачу. В общем, без сбора собственных датасетов и их разметки получится сделать разве что MVP, но никак не качественный продукт, готовый к эксплуатации в боевых условиях.
Итак, вы разослали запросы в медицинские учреждения, подняли все свои связи и контакты и получили в руки разношерстную коллекцию различных снимков. Не радуйтесь раньше времени, вы в самом начале пути! Ведь несмотря на наличие единого стандарта хранения медицинских изображений DICOM (Digital Imaging and Communications in Medicine), в реальной жизни все не так радужно. К примеру, информация о стороне (Left/Right) и проекции (CC/MLO) снимка молочной железы могут в разных источниках данных храниться в абсолютно разных полях. Решение тут единственное — собирать данные из максимального числа источников и пытаться учесть в логике работы сервиса все возможные варианты.
Что разметишь, то и пожнешь
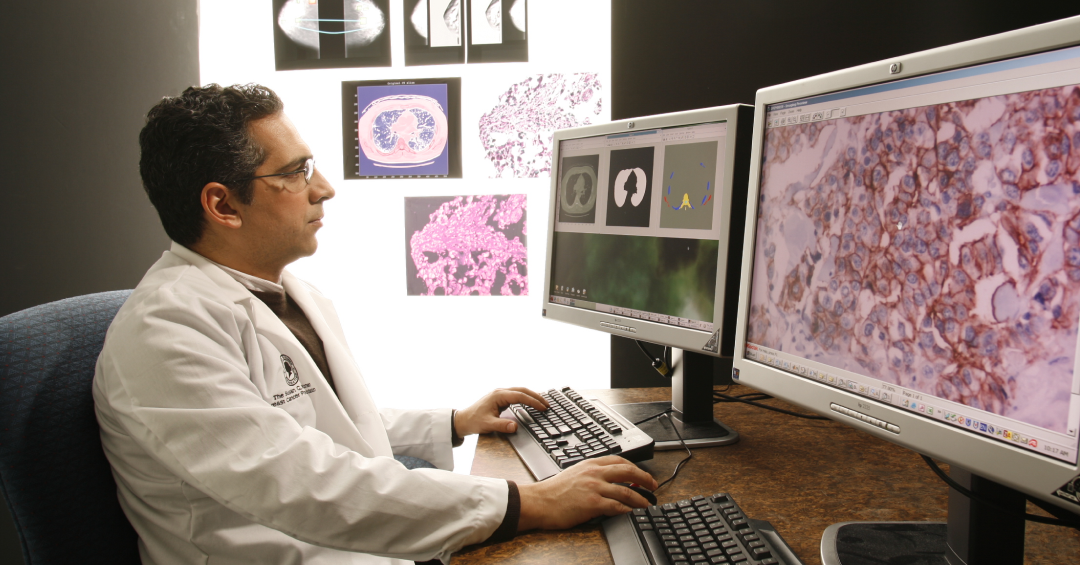
Мы наконец-то подобрались к самому интересному — процессу разметки данных. Что же делает его таким особенным и незабываемым в сфере медицины? Во-первых, сам процесс разметки намного сложнее и дольше, чем в большинстве индустрий. Рентгеновские снимки невозможно загрузить в Яндекс.Толоку и за копейки получить размеченный датасет. Здесь требуется кропотливая работа медицинских специалистов, причем каждый снимок желательно отдавать для разметки нескольким врачам — а это дорого и долго.
Дальше хуже: специалисты часто расходятся во мнениях и дают на выходе абсолютно разную разметку одних и тех же снимков. Врачи имеют разную квалификацию, образование, уровень «подозрительности». Кто-то размечает все объекты на снимке аккуратно по контуру, а кто-то — широкими рамками. Наконец, кто-то из них полон сил и энтузиазма, в то время как другой размечает снимки на маленьком экране ноутбука после двадцатичасовой смены. Все эти расхождения натурально «сводят с ума» нейронные сети, и качественную модель вы в таких условиях не получите.
Не улучшает ситуацию и то, что большинство ошибок и расхождений приходится как раз на самые сложные кейсы, наиболее ценные для обучения нейронок. Например, исследования показывают, что большинство ошибок врачи совершают при постановке диагноза на маммограммах с повышенной плотностью тканей молочных желез, поэтому неудивительно, что и для ИИ-систем они представляют наибольшую сложность.

Что же делать? Конечно же, в первую очередь нужно выстраивать качественную систему взаимодействия с врачами. Писать подробные правила разметки, с примерами и визуализациями, предоставлять специалистам качественный софт и оборудование, прописывать логику объединения незначительных конфликтов в разметке и обращаться за дополнительным мнением в случае более серьезных конфликтов.
Как вы понимаете, все это увеличивает затраты на разметку. Но если вы не готовы их на себя брать, лучше в сферу медицины не лезть.
Конечно, если подходить к процессу с умом, то затраты можно и нужно сокращать — например, с помощью активного обучения. В этом случае ML-система сама подсказывает врачам, какие снимки нужно доразметить для того, чтобы максимально улучшить качество распознавания патологий. Существуют разные способы оценки уверенности модели в своих предсказаниях — Learning Loss, Discriminative Active Learning, MC Dropout, энтропия предсказанных вероятностей, confidence branch и многие другие. Какой из них лучше использовать, покажут только эксперименты на ваших моделях и датасетах.
Наконец, можно вовсе отказаться от разметки врачей и полагаться только на конечные, подтвержденные исходы — например, смерть или выздоровление пациента. Возможно, это лучший подход (хотя и здесь есть куча нюансов), вот только начать работать он может в лучшем случае лет через десять-пятнадцать, когда повсеместно будут внедрены полноценные PACS (picture archiving and communication systems) и медицинские информационные системы (МИС) и когда будет накоплено достаточное количество данных. Но даже в этом случае чистоту и качество этих данных вам никто не гарантирует.
Хорошей модели — хороший препроцессинг
Ура! Модель обучена, показывает отличные результаты и готова к запуску в пилотном режиме. Заключены договоры о сотрудничестве с несколькими медицинскими организациями, система установлена и настроена, врачам проведена демонстрация и показаны возможности системы.
И вот первый день работы системы закончен, вы с замиранием сердца открываете дашборд с метриками… И видите такую картину: куча запросов в систему, при этом ноль обнаруженных системой объектов и, конечно, негативная реакция от врачей. Как же так? Ведь система отлично показала себя на внутренних тестах!
При дальнейшем анализе выясняется, что в этом медицинском учреждении стоит какой-то незнакомый для вас рентгеновский аппарат со своими настройками, и снимки в результате внешне выглядят абсолютно по-другому. Нейронная сеть не обучалась на таких снимках, поэтому неудивительно, что на них она «проваливается» и ничего не детектирует. В мире машинного обучения такие случаи обычно называют Out-of-Distribution Data (данные не из исходного распределения). Модели обычно показывают значительно худшие результаты на таких данных, и это является одной из главных проблем машинного обучения.
Наглядный пример: наша команда протестировала публичную модель от исследователей из Нью-Йоркского университета, обученную на миллионе снимков. Авторы статьи утверждают, что модель продемонстрировала высокое качество детектирования онкологии на маммограммах, а конкретно они говорят о показателе точности ROC-AUC в районе 0.88-0.89. На наших данных эта же модель демонстрирует значительно худшие результаты — от 0.65 до 0.70 в зависимости от датасета.
Самое простое решение этой проблемы на поверхности — нужно собирать все возможные виды снимков, со всех аппаратов, со всеми настройками, размечать их и обучать на них систему. Минусы? Опять же, долго и дорого. В некоторых случаях можно обойтись и без разметки — на помощь вам придет обучение без учителя (unsupervised learning). В нейронку определенным подаются неразмеченные снимки, и модель «привыкает» к их признакам, что позволяет ей успешно детектировать объекты на подобных изображениях в будущем. Это можно делать, например, с помощью псевдоразметки неразмеченных снимков или различных вспомогательных задач.
Однако и это не панацея. К тому же, такой способ требует от вас сбора всех существующих в мире типов снимков, что в принципе представляется невыполнимой задачей. И лучшим решением здесь будет использование универсального препроцессинга.
Препроцессинг — алгоритм обработки входных данных перед их подачей в нейронную сеть. В эту процедуру могут входить автоматические изменения контрастности и яркости, различные статистические нормализации и удаления лишних частей изображения (артефактов).
Например, нашей команде после множества экспериментов удалось создать универсальный препроцессинг для рентгеновских изображений молочной железы, который приводит практически любые входные изображения к единообразному виду, что позволяет нейронной сети корректно их обрабатывать

Но даже имея универсальный препроцессинг, не стоит забывать о проверках качества входных данных. К примеру во флюорографических датасетах нам часто попадались тестовые снимки, на которых присутствовали сумки, бутылки и другие объекты. Если система присвоит какую-либо вероятность наличия патологии на таком снимке, это явно не увеличит доверие медицинского сообщества к вашей модели. Чтобы избежать подобных проблем, ИИ-системы должны также сигнализировать о своей уверенности в корректном предсказании и в валидности входных данных.

Разное оборудование — это не единственная проблема, связанная со способностью ИИ-систем к генерализации, обобщению и работе с новыми данными. Очень важным параметром являются демографические характеристики датасета. К примеру, если в вашей обучающей выборке преобладают русские люди старше 60, никто не гарантирует корректную работу модели на молодых азиатах. Нужно обязательно следить за схожестью статистических показателей обучающей выборки и реальной популяции, для которой будет использоваться система.
При выявленных несоответствиях обязательно нужно провести тестирование, а скорее всего, и дообучение или файн-тюнинг модели. Обязательно нужно проводить постоянный мониторинг и регулярную ревизию работы системы. В реальном мире может произойти миллион вещей: заменили рентгеновский аппарат, пришел новый лаборант, который иначе выполняет исследования, в город внезапно нахлынули толпы мигрантов из другой страны. Все это может привести к деградации качества вашей ИИ-системы.
Однако, как вы сами могли догадаться, обучение — это еще не все. Систему нужно как минимум оценить, и стандартные метрики могут быть неприменимы в сфере медицины. Это вызывает сложности и в оценке конкурирующих ИИ-сервисов. Но это тема для второй части материала — как всегда, основанного на нашем личном опыте.

