Одна из вечных тем — правильная работа с кэшем. Звучит это просто, но на деле в ней очень много подводных камней и особенностей. Ну а когда приходит нагрузка, все становится еще интересней. В кэшировании нет «серебряной пули», а есть набор отработанных техник. И остается лишь подобрать их комбинацию для вашей задачи, используя достоинства и нивелируя недостатки.
На конференции PHP Russia 2021 Павел Паршиков, backend engineer в Авито, представит доклад «Уходим в кэш в высоконагруженных системах». А в этом интервью мы поговорили о том, хорош ли PHP для растущих в плане нагрузки проектов, и какие его инструменты лучше применять.

Расскажи немного о себе. Чем ты занимаешься?
Я работаю инженером в Авито. Уже более 15 лет занимаюсь веб-разработкой, в основном проектированием бэкенда.

Когда я анализирую свое рабочее время, то понимаю, что больше половины занимают коммуникации. Для бэкенд-инженера это общение не только внутри своей команды, но и с ребятами из других групп, из отдаленных частей компании. Для этого нужно уметь задавать только важные вопросы и не тратить ценное время коллег. А в случае удаленной работы на первый план выходит умение правильно и понятно формулировать свои мысли в тексте. Так что хоть мы и программисты, большей частью мы не кодим, а думаем, коммуницируем, проектируем.
Ты занимался наукой и преподавал. Почему ушел из этих областей? Что дал тебе этот опыт?
Работать я начал еще во время обучения в университете. В то время спрос на грамотных разработчиков, даже студентов без опыта, был просто огромным. Поэтому к окончанию университета у меня уже был опыт и желание программировать дальше. Но казалось, что в науке я могу сделать больше, чем просто решить практическую задачу для дипломного проекта. Поэтому поборолся за место в аспирантуре и продолжил обучение. Особенно мотивировала возможность попробовать себя в роли преподавателя. У меня был огромный запал энергии: хотелось рассказать ребятам о том, что знаешь, чему уже научился на практике.
Во время написания диплома я заинтересовался применением различных методик принятия решений в экономике. И в конце концов направление моих исследований сместилось в сторону управления проектами и согласования интересов субподрядчиков-исполнителей работ.
Для поддержки коллективного принятия решений участники таких организаций используют распределенные интеллектуальные системы. Они чем-то похожи на микросервисы, т.к. состоят из независимых модулей, общающихся по стандартизованному протоколу. Такие модули называются программными интеллектуальными агентами, а среда для из взаимодействия — мультиагентной системой.
Они отличаются от классических программных систем в том же, в чем и микросервисная архитектура отличается от монолитной, состоящей из множества подсистем внутри общей системы.
Это интересное и перспективное научное направление. На его развитие я получил грант, исследования финансировал Фонд содействия инновациями. Но потом сил тащить сразу два направления стало не хватать. Для развития необходимо было погружаться глубже либо в науку, либо в разработку программного обеспечения. И я выбрал разработку.
Самое интересное, что я устроился в Авито по рекомендации своего студента. И вообще ребята, у которых я преподавал, успешно работают не только в крупных российских IТ-компаниях (Яндекс, Mail.ru и т.д.), но и в международных технологических гигантах, таких как Google и Apple. И успех учеников, на самом деле, тоже очень сильно мотивирует продолжать обучать, делиться знаниями, помогать ребятам добиваться большего.
Хорош ли PHP для растущих в плане нагрузки проектов?
Начну с того, что как бы ни ругали PHP, некоторые проекты в топе Рунета написаны именно на нём. В качестве языка для бэкенда высоконагруженных приложений, которые я разрабатывал раньше, тоже использовался PHP. И, при этом, они держали нагрузку в тысячи RPS, отлично масштабировались и поддерживались небольшой командой разработки.
На моей нынешней работе используются несколько языков для разработки. Основные — это PHP и Go. На PHP написан весь монолит Авито. Некоторые сервисы также написаны на PHP, например, сервисы для API мобильных приложений (mapi).
PHP точно хорош для растущих в плане рабочих рук проектов. PHP-разработчиков на рынке очень много, и это ребята самого разного уровня. Кроме того, как мы знаем, большинство веб-сайтов написано на PHP, а значит если вы хотите быстро набрать команду, то проще всего будет это сделать для проекта на PHP. Понятно, что большинство сайтов — это совсем не highload, а какие-то малонагруженные полустатические сайты или интернет-магазины, написанные на распространенных, а иногда и самописных CМS'ках. Но научить PHP-разработчика особенностям построения архитектуры под высокую нагрузку гораздо проще, чем заниматься полным переобучением. Ведь это включает в себя не только изучение нового языка, но и его философии, экосистемы, принятых архитектурных паттернов.
Относительно производительности, мы знаем, что PHP с каждой новой версией улучшает использование процессора и памяти. И по benchmark'ам имеет один из самых быстрых интерпретаторов. Дальнейший рост производительности обеспечивается полноценной поддержкой JIT компиляции. Однако PHP уже и так находится на пределе улучшений, если смотреть на производительность вычислений для интерпретируемых языков. По факту, практически все PHP-приложения заняты большую часть времени не вычислениями, а вводом-выводом: походами в сеть в другие сервисы, получением данных из кэша или базы данных и т.д. Т.е. по сути PHP приложение выступает всего лишь клеем, который связывает между собой воедино различные части архитектуры. И в такой типичной задаче для веб-приложения производительность самого языка не так важна. Гораздо важнее производительность архитектуры в целом.
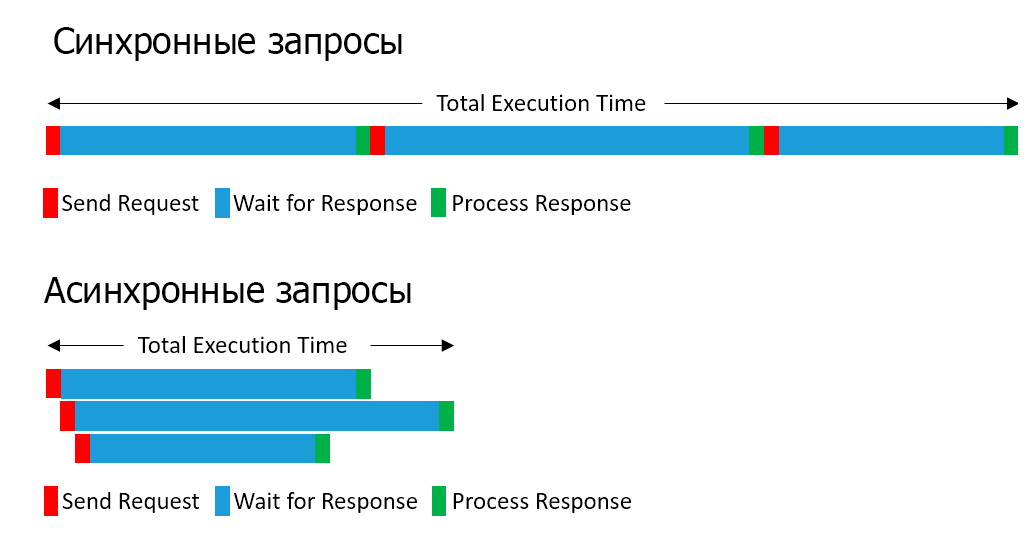
Если ваше приложение уже доросло до выделения некоторой функциональности в отдельные сервисы, стоит отметить один нюанс, существенно ограничивающий использование коробочного PHP в микросервисах. Это отсутствие асинхронности. Для обработки типичного запроса в микросервисной архитектуре нужно сходить в несколько сервисов. Например, на странице поиска это могут быть запросы в сервисы поиска, избранного, картинок, телефонов и т.д. И это слишком непозволительная роскошь — ходить во все сервисы последовательно. Особенно это опасно, когда все N сервисов начинают по чуть-чуть деградировать и тормозить. Тогда все эти задержки накапливаются и увеличивают среднюю деградацию в N раз.
И чем больше сервисов, тем, как правило, запросы в них легче поддаются распараллеливанию. Удобных конструкций для создания параллельных запросов и реализации асинхронности из коробки в PHP нет. Поэтому приходится использовать дополнительные библиотеки и фреймворки, которые реализуют в PHP различные концепции асинхронного программирования: event loop, promises, coroutines. Например, ReactPHP, AMPHP, Swoole.
Для задачи реализации асинхронных походов в несколько микросервисов по HTTP можно взять кое-что попроще. В PHP уже встроена функция curl_multi_exec(), которая умеет выполнять несколько запросов по HTTP параллельно. Я также использую библиотеку Guzzle, которая является удобной оберткой над этой функцией.
В экосистеме PHP большое разнообразие фреймворков. И можно выбрать любой, по душе и по строгости к качеству кода. Зачастую highload-проекты используют свои собственные фреймворки, т.к. стандартные решения часто слишком универсальные и достаточно тяжелые. При этом некоторые модули стандартных фреймворков очень удобны и распространены в сообществе, поэтому часто используются отдельно от него. Например, прекрасный компонент DependencyInjection от Symfony.
Быстродействие особенно важно для микросервисов, которые должны быстро взаимодействовать через API. И слишком дорого на каждый запрос поднимать все окружение фреймворка, парсить конфигурации, загружать множество файлов и создавать экземпляры классов. Проблему можно решить, если сократить объем этого окружения, перейти к микрофреймворку и оптимизировать загружаемые библиотеки. Кроме того, в PHP7.4 появился preloading для однократной предзагрузки скриптов. А еще можно воспользоваться инструментом RoadRunner, который позволяет сохранять состояние скрипта после выполнения запроса.
Если говорить о самом языке, то PHP позволяет удобно описывать бизнес-логику и строить хорошие бизнес-модели. Ведь это полноценный ООП язык со всеми необходимыми штуками, вроде наследования, полиморфизма и т.д. И это гораздо удобнее, чем, например, прототипное наследование в Javascript. Поэтому PHP отлично ложится на такие контексты как, например, автоматизация различных процессов в бэкофисе. PHP позволяет очень быстро прототипировать, и, что важно для бизнеса, снижает time to market в погоне за конкурентами.
Есть ли знания, которые приобретаются только в работе с нагруженными системами? О чем стоит думать? Что можно докрутить потом, а что — делать сразу?
В первую очередь подчеркнул бы, что для highload-проектов выбранная архитектура важнее, чем код и применяемые технологические решения. Не зря на собеседованиях в другие крупные компании обычно одна из секций — архитектурная. Для того, чтобы новая технология попала в техрадар, она должна пройти защиту, учесть рекомендации и получить одобрение. Кэши, про которые я собираюсь рассказать на PHP Russia, — супер важная часть архитектуры высоконагруженного сервиса. Правильно приготовленные, они могут существенно повысить запас прочности системы.
Вы должны заранее продумывать архитектуру и варианты масштабирования системы таким образом, чтобы рост нагрузки не потребовал полного переписывания проекта. Речь идет не только о масштабировании архитектуры системы, но и архитектуре кодовой базы. Во всех случаях ключевым принципом, которого стоит придерживаться, начиная с этапа построения архитектуры и заканчивая непосредственно разработкой, является принцип слабого зацепления (loose coupling). Такую систему в будущем становится гораздо проще «расцепить» на отдельные независимые части.
В монолитном приложении с единой кодовой базой, даже придерживаясь принципов SOLID, сложно поддерживать независимость модулей. Самый надежный вариант снизить зацепление — с самого начала применять внедрение зависимостей (DI). Это позволяет легко отцепить зависимости от клиента и, при необходимости, вынести их в отдельный модуль, библиотеку или даже сервис. В этом случае вы упрощаете для себя модульное тестирование, так как четко определены границы модулей и явно формализованы их контракты. Проще всего сразу использовать контейнер внедрения зависимостей (DIC), который упрощает конфигурирование и инстанцирование зависимостей.
В этом плане микросервисный подход имеет явные преимущества, ведь он воплощает принципы loose coupling в архитектуре, так сказать, by design. Уже на стадии проектирования микросервиса мы четко очерчиваем границы его ответственности и описываем его API. Фактически, микросервисы только и связаны через этот API. Написание юнит- и функциональных тестов, мокирование зависимостей доставляют абсолютное удовольствие.
На самом деле, сам PHP тоже оказывает помощь в масштабировании приложений, так как он — stateless по умолчанию. Хотя его модель — «умереть» после обработки запроса — явно проигрывает другим языкам по накладным расходам, проблема с масштабированием веб-сервера на PHP отсутствует. У вас нет никаких общих состояний между запросами, а чаще всего нет и данных в общей памяти. Запросы не просто слабо связаны, они вообще изолированы друг от друга. А значит неважно на каком сервере запросы обрабатываются, один это сервер или множество.
Важно отметить, что при этом не стоит сразу усложнять архитектуру системы и добавлять в нее компоненты, которые не устраняют проблемы, а только усложняют разработку и поддержку. Например, если у вас небольшая команда, объем кодовой базы незначительный, бизнес-логика проста и в ней сложно выделить отдельные области, нет смысла использовать микросервисную архитектуру, даже если нагрузки высокие. Монолитное приложение в таком случае будет гораздо удобней в разработке и поддержке, обеспечит более низкий time to market.
Как говорят, если вы думаете, нужно ли вам шардирование, скорее всего оно вам не нужно. И если вам реально потребуются архитектура и решения для highload, вы будете об этом знать наверняка. В развитии системы нужно двигаться аналогично развитию в продукте, начать с MVP-решения, а потом его итеративно улучшать, гибко планируя доработки. И любой элемент в архитектуре highload-приложения — это всегда способ решить какую-то проблему: улучшить процессы разработки, расширить bottleneck, снять нагрузку с части системы.
Все приложения под highload, как правило, очень специфичны и имеют особенную архитектуру. Эта архитектура определяется профилем нагрузки, поведением пользователей, предметной областью и еще много чем. Сейчас в отрасли сформировались наиболее популярные подходы к контейнеризации приложений, хранению данных, кэшированию. Но эти отдельные технологии и методики можно комбинировать разными способами и получать системы с различными свойствами. Архитектура приложения — это результат множества компромиссов между стоимостью, масштабируемостью, производительностью и гибкостью. И как раз на компромиссах при выборе решения по кэшированию данных я собираюсь сделать акцент в своем докладе.
В системах, работающих под высокой нагрузкой, начинают проявляться и играть важную роль такие нюансы, которые в обычных условиях просто незаметны. Поэтому от программиста требуется не только писать качественный код, но и понимать, как он работает «под капотом», какие оптимизации могут применяться интерпретатором. А значит надо понимать принципы работы интерпретатора PHP, детали работы с памятью, особенности реализации различных структур данных. Например, как переменные представляются в виде структуры zval, какие подчиненные структуры выделяются для различных типов данных и как «под капотом» работает присваивание по значению и по ссылке. Эти знания обязательно пригодятся, когда вы начнете искать узкие места в коде приложения с помощью профайлера. Иногда приходится погружаться очень глубоко и изучать опкоды, которые сгенерировал интерпретатор.
Для ненагруженных приложений зачастую слишком дорого тратить время разработчика на то, чтобы оптимизировать код. Затраченное время никогда не окупится. Гораздо проще взять сервер помощнее или горизонтально масштабировать систему. В случае высокой нагрузки незначительная оптимизация в ядре фреймворка, через который проходят сотни тысяч запросов в минуту, может уменьшить время выполнения каждого на несколько миллисекунд или сократить потребление памяти. И в итоге это приведет к высвобождению нескольких серверов, каждый из которых стоит несколько тысяч долларов. Оптимизация системы в данном случае имеет конкретную стоимость, и для бизнеса она ниже, чем покупка нового железа.
Рост нагрузки, как правило, приводит к росту архитектуры системы. И в этот момент важно не потерять понимание того, что с системой вообще происходит. И если происходит что-то нехорошее, то почему. Поэтому заранее нужно продумать системный подход к observability системы и детали реализации каждого из его трех столпов: логирование, метрики, трейсинг. В случае микросервисной архитектуры без настроенных «радаров» и продуманной системы алертинга жить невозможно. Ведь если в сложной взаимозависимой системе сервисов начнутся проблемы у одного из них, это автоматически приведет к каскадным проблемам у всех зависимых сервисов.

В итоге даже проблемы в одном сервисе в течении нескольких минут могут привести к убыткам, которые измеряются миллионами рублей.
Сейчас в крупных компаниях даже выделяют отдельно роль инженера по SRE, отвечающего за надежную работу системы. Эту позицию может занять опытный разработчик из команды. Часто эту роль выполняют инженеры-программисты параллельно с основной работой.
О чём собираешься рассказать на PHP Russia?
Кэширование — это такая штука, про которую, вроде бы, все и так знают. Что тут вообще можно изобрести? В PSR'овских рекомендациях интерфейс для Simple Cache насчитывает всего несколько стандартных функций, таких как get, set, delete и т.д.
Но на самом деле если копнуть глубже, выясняется, что кэш — это сложнейшая распределенная система, и даже не все ее части доступны для управления. А те кэши, которыми мы можем управлять, разбросаны по всей сети. Фактически, веб-разработчик любого профиля что-то кэширует: в браузере, на прокси, на серверах и т.д. Конечно, большинство рычагов для управления этой махиной находятся на сервере и в руках бэкенд-разработчиков. Но даже если сосредоточиться на серверном кэшировании, все его виды и техники даже при обзорном рассмотрении никак не поместятся в один доклад. Поэтому я выбрал небольшой кусочек этой огромной кэш-истории, которая ближе всего PHP-разработчикам — кэширование данных в оперативной памяти.
Кэширование в вебе очень многолико. На сервере под кэшированием обычно подразумевают размещение данных в оперативной памяти. Но туда невозможно положить всё, что хотелось бы. Потому готовые к использованию данные можно разместить и в других местах, и даже в одном хранилище, вместе с исходными данными. И это тоже в некоторой степени — кэш. Да, скорость доступа невелика, однако данные уже предвычислены. Так, например, распространено кэширование обработанных картинок (превью) прямо на диске, или размещение аналитических данных вместе с исходными в одной БД, в кэширующих таблицах.
Весь мой доклад будет пронизан мыслью о том, что существует множество техник и приемов для решения каждой из проблем. И их так много только потому, что для каждого кейса необходимо индивидуально подбирать технику, взвешивая ее достоинства и недостатки. Достоинства одной техники могут отлично сработать в одном кейсе, и при этом быть незаметны за ее недостатками в другом. Кэширование работает не всегда. Highload-системы тем и интересны, что стандартных кейсов не бывает, и каждый случай нужно рассматривать отдельно: работает кэширование или нет, какую выбрать политику вытеснения, как поддерживать консистентность и т.д. И тут, как говорил Шерлок Холмс, в вашем арсенале должно быть как можно больше полезных инструментов, которые в идеальном порядке и всегда под рукой.
В докладе я сознательно не акцентирую внимание на каких-то конкретных реализациях распределенных систем для кэширования в памяти, вроде Redis или Memcached. Хотя они, конечно, наиболее распространены и имеют наибольшие комьюнити. Я работал с системами, которые держали тысячи RPS запросов к бекенду, при этом использовали библиотеку Memcache для PHP, у которой из операций с данными есть только get/set/delete/increment/add. И эти операции покрывали 99% всех потребностей по управлению данными в оперативной разделяемой памяти. А более сложные операции с данными можно выполнить через комбинацию простых. Однако здесь возникают различные проблемы атомарности. О том, как с ним работать, я тоже собираюсь рассказать в своем докладе.
Одна из частей доклада будет посвящена вопросу масштабируемости кэширующих систем. Вне зависимости от нагрузки на систему, с масштабированием вы столкнетесь в том случае, если ваши данные просто перестанут помещаться в память одного сервера. Задача распределения данных по кэш-серверам чем-то напоминает шардирование базы данных. Однако между ключами отсутствуют явные связи, поэтому выбираются самые простые функции шардирования, которые часто уже реализованы в клиентских библиотеках. Но вы увидите — все настолько просто, что управлять распределением данных по алгоритму консистентного хэширования можно прямо из своего PHP-кода!
Для highload-систем разделение данных по узлам полезно еще и для масштабирования нагрузки. Из коробки размазывание нагрузки по серверам будет отлично работать для большинства ключей. Но особенное внимание нужно обратить на горячие ключи. Иногда они настолько горячие, что нагрузку на них не вытягивает один кэш-сервер. В докладе я покажу несколько приемов, которые мы используем для того, чтобы горячий ключ не стал глобальным мьютексом для всей системы, сериализующим запросы.
На уровне PHP кода необходимо предусмотреть размазывание нагрузки не только по узлам, но и во времени. На конференции разберем несколько типичных подходов к прогреву кэша и поддержанию его в горячем состоянии.
Правду говорят, что инвалидация кэша — одна из сложнейших проблем программирования?
Скорее, инвалидация — это одна из самых интересных проблем программирования. Кэширование просто напичкано такими интересно-сложными архитектурными проблемами.
Многие разработчики, сталкиваясь с высокими нагрузками и ростом response time, обращаются к кэшированию, как панацее от всех проблем. И действительно, это же так удобно и просто — сохранить копию данных в оперативную память и, за счет этого, снизить время чтения и убрать нагрузку с основного персистентного хранилища. Например, просто кладем в кэш уже заранее сгенерированную ленту для главной страницы сайта или блок с рекомендациями. Теперь время их чтения определяется скоростью оперативной памяти, что просто прекрасно.
Но вдруг в службу поддержки от пользователей начинают поступать жалобы: поменял пост — ничего не изменилось в ленте, нажал лайк — счетчик не обновился в блоке, оплатил выделение объявления цветом — оно отображается как обычное. И тут мы начинаем понимать, что не все так просто. Что делать со значением в кэше, если исходные данные изменились? А ведь наверняка от одного элемента исходных данных зависит множество производных значений в кэше: ленты, блоки, счетчики. Как реализовать консистентность каждой закэшированной копии данных и при этом не получить оверхед, превышающий все преимущества кэширования?
Возможно, эта проблема была названа сложной, потому что она пронизывает все уровни архитектуры вычислительных систем — начиная с аппаратного обеспечения (кэш процессора) и заканчивая прикладным программным обеспечением (кэш браузера). Проблема стоит особенно остро в распределенных веб-системах, где кэши расположены во всей цепочке: у клиента, в сети и на сервере. На сервере нам нужно понимать всю сеть зависимостей между данными в кэшах и исходных хранилищах. Когда мы начинаем размещать данные за пределами сервера, управлять ими становится в разы сложнее. Здесь вступают в игру политики управления кэширования через заголовки и коды состояний HTTP. В итоге получаем сложнейшую распределенную архитектуру, в которой решение задачи согласованности кэшей зачастую нетривиально, а в процессе инвалидации легко упустить какой-нибудь краевой кейс.
Часто можно пожертвовать строгой консистентностью данных. Ведь процесс инвалидации имеет свою стоимость, с точки зрения производительности и использования ресурсов. Многие наши приложения — это совсем не банковские системы, а потому если закэшированный блок будет не консистентен с лентой постов, которая находится рядом с ним, этого могут не заметить.

Но существуют кейсы, не допускающие даже временной неконсистентности данных. И в моем докладе я разберу, какую логику стоит разместить в PHP-коде, чтобы своевременно провести инвалидацию всей копий в кэшах. В простейших случаях, когда между элементами отсутствуют зависимости, можно выбрать стратегию явной инвалидации по конкретному ключу. Если же зависимости присутствуют, нужно отразить их в кэше, чтобы затем сразу выполнять инвалидацию группы элементов. Существуют даже приемы, позволяющие автоматически производить это в кэше, хитро построив ключ!
В задаче инвалидации кэша огромное поле для творчества. И когда строгая консистентность приводит к проблемам производительности или излишнему усложнению архитектуры, можно просто «замаскировать» проблему для пользователя прямо на фронтэнде. Например, по нажатию лайка для поста имитировать на фронтэнде изменение счетчика с рейтингом, маскируя неконсистентность значений в кэше.
Уверен, что после моего доклада слушатели, столкнувшись со сложной проблемой инвалидации, будут иметь «за пазухой» все необходимые инструменты для ее простого решения.
PHP Russia 2021 пройдет 28 июня в Москва, Radisson Slavyanskaya. Но уже сегодня можно ознакомиться с расписанием и присмотреть доклады, которые вы точно не захотите пропустить.
А еще вы можете выбрать формат участия: онлайн или офлайн. Не забудьте купить билеты уже сегодня!

