 Мы в ABBYY уже давно занимаемся решением задач Natural Language Processing (NLP). Технологии обработки естественного языка лежат в основе многих NLP-решений ABBYY для поиска и извлечения данных. С их помощью мы помогли индустриальному гиганту НПО «Энергомаш» сделать поиск по документам, накопленным на предприятии почти за 100 лет, а один из крупных банков использует наши технологии, чтобы мониторить гигантский поток новостей и управлять рисками. В этом посте мы расскажем, как устроены изнутри наши NLP-технологии для извлечения информации из сплошного текста. Будем говорить не про текст в таблицах и четко структурированных бланках, как например, товарные накладные, а про многостраничные неструктурированные документы: договоры аренды, истории болезни и многое другое.
Мы в ABBYY уже давно занимаемся решением задач Natural Language Processing (NLP). Технологии обработки естественного языка лежат в основе многих NLP-решений ABBYY для поиска и извлечения данных. С их помощью мы помогли индустриальному гиганту НПО «Энергомаш» сделать поиск по документам, накопленным на предприятии почти за 100 лет, а один из крупных банков использует наши технологии, чтобы мониторить гигантский поток новостей и управлять рисками. В этом посте мы расскажем, как устроены изнутри наши NLP-технологии для извлечения информации из сплошного текста. Будем говорить не про текст в таблицах и четко структурированных бланках, как например, товарные накладные, а про многостраничные неструктурированные документы: договоры аренды, истории болезни и многое другое. Затем мы покажем, как это работает на практике. Например, как за Х минут извлечь Х сущностей из 200-страничного банковского договора. Или убедиться в верности юридического контракта, или оперативно добыть информацию о редких побочных эффектах из собрания медицинских статей. Наш опыт показывает, что компаниям необходимо получать такие данные быстро и без ошибок, так как от этого зависит благополучие и бизнеса, и людей.
В конце поста упомянем о нескольких трудностях, с которыми мы сталкивались при ведении таких проектов, и поделимся опытом, как удалось их разрешить. Ну, добро пожаловать под кат.
Так чем же мы занимаемся?
В целом, технологии обработки и анализа естественного языка позволяют многое: фильтровать спам в электронной почте, создавать системы машинного перевода, распознавать речь, разрабатывать и обучать чат-ботов. NLP-технологии ABBYY помогают банкам, промышленным и другим организациям быстро извлекать и структурировать большой объем информации из деловых документов. Крупные компании уже давно автоматизируют или, по крайней мере, стремятся уменьшить количество вручную проводимых рутинных операций. Речь – о поиске в бумажном документе даты, ФИО, суммы, ИНН, номера накладной; перепечатке данных в корпоративные информационные системы, проверке, корректно ли все заполнено.
Напомним, изначально мы умели извлекать текст из документов на основе геометрических признаков, в частности структуры и расположения строчек и полей. Таким образом до сих пор удобно обрабатывать информацию из структурированных анкет, строгих форм, опросников, заявлений, бланков переписи населения и т.д. Кстати, мы рассказывали на Хабре про такой кейс – c помощью ABBYY FlexiCapture министерство здравоохранения Бангладеш обработало заполненные жителями республики анкеты медицинской переписи.
Понятно, что значимая информация хранится не только в бланках, поэтому мы обучили наши NLP-решения «доставать» данные из документов, в которых вообще нет структуры или она крайне сложная. Наверное, многие помнят об ABBYY Compreno для анализа и понимания естественного языка. Мы развивали и совершенствовали технологию, и впоследствии она легла в основу многих наших NLP-решений. Один из кейсов применения NLP — проект с мониторингом новостей в нескольких крупных российских банках. Если кратко, то наш движок умеет выполнять работу банковского андеррайтера – человека, который из гигантского потока информации вылавливает события о контрагентах и оценивает риски. Подробнее о этом здесь.
Ниже речь пойдет о другом аспекте – извлечении информации из таких неструктурированных документов, как договоры, истории болезни, новости из разных источников.

Как устроены наши NLP-технологии
Концептуально обработка документа от момента загрузки в ABBYY FlexiCapture до извлечения нужных полей выглядит так:

Допустим, необходимо извлечь дату и место подписания, а также названия компаний-участников из 50-страничного контракта. 50-страничного, Карл! И дат там много! Как найти страницу, нужную клиенту? Технологии помогают это сделать в несколько этапов.
Этап сегментации
Далее происходит сегментация документа, то есть мы сужаем область для поиска информации и обрабатываем не все 50 страниц, а только, скажем, 5 сегментов по абзацу, где может быть нужная нам дата. Так алгоритмам работать гораздо проще, как и отличить искомую дату от какой-то другой.
Все этапы правее сегментации на схеме описывают работу алгоритмов NLP – подробное изучение, чтение и понимание текста. Эти процессы занимают в 10-20 раз больше времени, чем классификация и сегментация, поэтому запускать их на весь многостраничный документ не совсем правильно. Легче «натравить» их на небольшой объем текста.
Как работают NLP парсер + Bi-LSTM
С их помощью из каждого предложения в тексте извлекаются признаки (фичи). Это и есть технология ABBYY Compreno, работающая в составе FlexiCapture. Движок подробно читает текст и извлекает из него множество обобщающих признаков. Он понимает не только то, что конкретно сформулировано в этом предложении, но и смысл – то, что на самом деле имеется в виду.
Извлечение признаков – это продолжительный этап. Есть высокоуровневые признаки. Грубо говоря, они указывают на то, что в этом фрагменте что-то, похожее на имя, делает что-то, похожее на действие, с каким-то объектом из какого-то семантического класса. Затем на извлеченных высокоуровневых признаках применяется достаточно простой и классический метод ML – GBM. Это ансамбль решающих деревьев, который выдает общее решение и подсвечивает извлеченные поля. Чтобы GBM быстро обучался и качественно извлекал информацию, важно иметь достаточное количество документов для обучения. Если их немного, то качество извлечения информации может снизиться. Связано это с тем, что ядро случаев становится меньше и, соответственно, у «машинки» хуже получается обобщать – отличать единичные случаи от частотных.

Где это используют?
Приведем несколько примеров из нашей практики – реализованных проектов, пилотов или концепт-кейсов.
NLP для финансовых организаций

Заказчики часто просят нас обрабатывать инвойсы (счета-фактуры) и заказы на покупку. Некоторые данные (или поля), блоки с текстом или с адресом, можно извлечь традиционными методами, опираясь на ключевые слова. Но если нужно заглянуть внутрь текстового блока, то необходим NLP. Еще бывает, что требуется «достать» не весь блок с адресом, а только часть этого адреса: улицу, штат, город, почтовый индекс, страну. Либо нужно распарсить даты и проценты скидки, если инвойс предполагает оплату до какой-то конкретной даты. Наши технологии помогают учесть такие переменные: сколько будет стоить заказ, если оплатить его заранее или оптом, и сколько – при поздней оплате.
Еще мы помогаем юридическим отделам крупных компаний извлекать важные данные из контрактов на оказание услуг, отчетов о проделанной работе, соглашениях NDA (документов о неразглашении). Приведем в качестве примера один наш проект по работе c договорами коммерческой аренды. Они представляли собой документы из 30 страниц, данные из полей на каждой странице заказчик раньше вносил в информационную систему вручную. Как правило, для одного документа это занимало час. FlexiCapture справилась с задачей за две минуты и, по подсчетам клиента, сэкономила ему 5000 человеко-часов за год.
Или возьмем кредитные соглашения. Кредиты берут не только люди, но и крупные компании. Для этого они предоставляют банку большой пакет документов. Скажем, информацию об имеющихся коммерческих кредитах. И это не какая-то ипотека на 6 млн рублей, а ипотека на 100 млн долларов (на здания, офисы). И дальше банку нужно извлечь из такого 250-страничного документа 50-70 сущностей либо условий. Вручную это долго обрабатывалось, по подсчетам нашего заказчика – 2-3 часа на один документ. С FlexiCapture все было готово за 9 минут. Не то чтобы мгновенно, понимаем. Причина – в оформлении документов: они обычно отличаются высокой плотностью текста, и извлекать надо большое количество различных сущностей. Не секундное дело :)
Loan Applications (заявки на получение кредита) тоже часто подлежат обработке. Это предварительный документ с вопросами, который банк присылает клиенту. Чем больше сумма кредита, тем больше вопросов в такой анкете. Например, в сведениях по месту работы банк может попросить указать ее идентификатор и юридический адрес. Банки часто требуют уточнить информацию о семейном положении, наличии кредитов, долгов по коммунальным услугам, алиментам и прочих вещах, которые могут помешать выплатить кредит. Иногда вопросы в Loan Applications составлены довольно сложно, поэтому некоторые компании помогают своим заказчикам переводить с юридического языка на общедоступный, чтобы понять и по-человечески описать, что от клиента хотят.
В обработке таких заполненных документов основная сложность заключается в большом количестве полей (в нашем случае их было 105). Сотруднику банка в них легко запутаться, а технологию это сбить не может. FlexiCapture тратит на все про все 5 минут, сотрудник – до 2-3 часов. Как говорится, почувствуйте разницу.
Здравоохранение
Часть проектов ABBYY связана с извлечением информации из медицинских документов.

Например, при помощи NLP можно обрабатывать краткое содержание (Abstract) научных медицинских статей. Есть такое направление в фармакологии – Pharmacovigilance. Оно исследует побочные эффекты, которые новые лекарства могут вызвать у пациентов и которые еще нигде не описаны. Медицинские организации собирают от пациентов информацию о таких критических случаях и составляют подробные отчеты о них – Individual Case Safety Reports (ICSR). Если новая таблетка нанесла человеку вред, то производитель должен быстро сообщить об этом регулирующему органу, иначе он может попасть на крупный штраф. Чтобы избежать подобных последствий, высококвалифицированные сотрудники фармацевтических компаний в большом количестве читают ICSR. Довольно утомительное занятие.
Гораздо проще озадачить этим технологии. В рамках одного из пилотов в сфере Pharmacovigilance наши технологии извлекали из медицинских статей такие данные, как пол и возраст пациента, информацию о событии, которое с ним произошло, и название лекарства. Все, за исключением последнего, извлекалось с помощью машинного обучения. А вот для названий лекарства мы пользовались более простым методом – словарями. Суть в том, что клиент попросил извлекать из статей не все возможные лекарства, а препараты из списка с 80 наименованиями. В этом случае сопоставление со словарем сработало на отлично. Словари – это тоже часть FlexiCapture NLP. Для поиска названия лекарства используется морфология. Неважно, в какой форме или регистре написано слово, тем более в английском их не так много.
Обработку историй болезни тоже автоматизируют, потому что информации нужно перебрать много. Это и таблицы, и чеки, и описание решения страховой компании. Например, один из регуляторов в США принимает обращения пациентов по поводу страховок. Бывает, что страховая отказывается оплачивать лечение. Причины могут быть разные, но пациент имеет право разобраться и подать заявление госоргану. А регулятор должен проанализировать информацию и вынести вердикт, действительно ли отказ был обоснован?
Если таблицы легко обрабатываются с помощью FlexiLayout, то куски текста с решением страховой так не обработать. Чтобы извлечь из текста само решение и его обоснование, мы использовали NLP.
Истории болезни необходимо тщательно анализировать, когда пациента переводят из одной больницы в другую. Учитывая, что мы живем во времена коронавируса, иногда таких пациентов может поступать очень много, и сотрудникам больниц тяжело справляться со слишком большим потоком документов. Кейс, в котором мы участвовали, никак не был связан с короной, но потенциально наш опыт все равно ценный.
Недвижимость
— Один из наших потенциальных клиентов арендует много земли под строительство и под офисы. Соответственно, компания заключает много договоров аренды. Ей необходимо автоматически обрабатывать такие документы: извлекать из них даты и сроки, чтобы потом следить, не пропускают ли они платежи, когда закончится договор аренды, где договор автоматически продлевается, сколько это вообще все стоит.
— В строительных компаниях также есть такие специалисты, как portfolio analysts. Они анализируют договоры, выясняют, сколько стоит конкретная недвижимость и помогают оценить, насколько она хороша и какой доход может принести владельцу. Как банковский скоринг. В США, к слову, можно продавать или частично приобретать пакет ипотек. Это ценная бумага, она тоже может расти или падать в цене. Например, если растут цены на недвижимость, то ипотеку, которая стоила дешевле, можно рефинансировать. А если все дешевеет, то клиент старается скинуть эту бумагу.
В таком договоре есть информация, которая извлекается как при помощи NLP, так и без него. Табличные данные – при помощи FlexiLayout (это то, что мы могли делать и раньше). А все остальные поля – это параграфы, которые извлекаются сегментатором, либо поля внутри параграфов, которые извлекаются моделями извлечения.
Преимущество технологий NLP в том, что это еще один механизм, с помощью которого можно обрабатывать большее количество типов полей и документов.

— Один из наших клиентов – home owner association, условно наше СНТ. Если новый участник вступает в такое СНТ, то ему дают пакет из 9 типов документов – Deeds (это может быть договор купли-продажи). Затем данные из этих заполненных документов нужно обработать, проверить и внести в информационную систему. 8 из них – структурированные и обрабатываются FlexiLayout. Но 9-ый с подвохом. Чтобы выполнить этот проект, нашей компании было необходимо обрабатывать и неструктурированные акты.
Что мы и сделали, применив NLP. Сами документы, с одной стороны, не слишком объемные: 1-2 страницы. С другой стороны, они очень разнообразные, в плохом качестве. Несмотря на это наше решение смогло извлечь необходимую информацию. Интересен этот проект тем, что его NLP-шная часть может быть очень маленькой, но при этом критичной, потому что без нее проект просто не выполнить.
— NLP необходим и для автоматизации процесса одобрения контрактов (Contract Approval Automation). В компаниях часто заключают master agreement – рамочное (генеральное) соглашение, в котором устанавливаются общие условия для ряда будущих операций. Например, что должен выполнить клиент, в какие сроки, какие санкции за просрочки, когда нужно заплатить за услуги.
Процесс автоматического одобрения контракта выглядит так: мы извлекаем из документа определенное количество полей и условий (clause). Поля – это одно или несколько слов, а clause – это один или несколько параграфов, в которых могут быть длинные описания. Компании нужно извлекать поля, чтобы по ним индексировать документы, складывать в электронное хранилище, а затем вести по ним поиск. По clause происходит Approval – проверка, правильны ли условия. Извлеченные условия технологии сравнивают с условиями в генеральном соглашении. Если все совпадает, то рисков для компании нет, можно автоматически одобрять (провести ревью) и отправлять контракт в базу данных. Это значительно упрощает жизнь юристам: вместо того, чтобы заниматься однотипными контрактами, они могут переключиться на более важные задачи. Провести ревью контракта придется только в том случае, если система выявит в документе какие-либо несоответствия с основным.
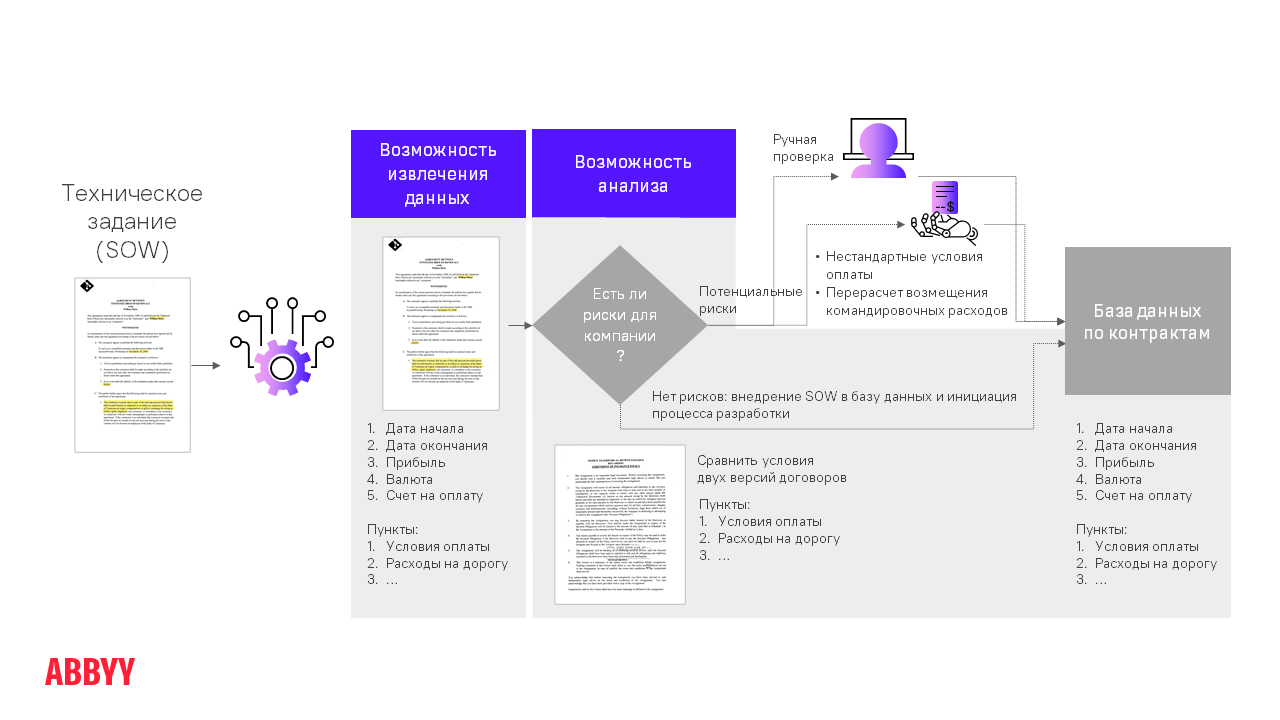
Что объединяет все NLP-проекты
В структурированных инвойсах, где мы распознаем сумму и адрес, сразу понятно, где расположены нужные поля, а сами документы занимают одну или несколько страниц. В случае с неструктурированными документами не всегда можно быстро определить, какие данные и откуда нужно извлекать — в этом главная особенность NLP-шных проектов. Кроме того, сами документы занимают не одну страницу, а 100-200. Поэтому на этапе разработки требований мы сначала просим заказчика составить список из нескольких десятков полей, которые нужно извлекать. В таких проектах необходимо участие subject matter expert – эксперта в этой области, который будет отвечать на вопросы, что и в каком случае необходимо извлекать из документа и на какие нюансы обращать внимание.
Иногда заказчик просит извлекать сразу несколько сотен полей из документа. Такой подход неконструктивен и приводит к тому, что только на обсуждение требований к проекту уходит не один месяц. Именно поэтому мы, как правило, начинаем не с сотен полей, а с 10, проясняем требования, демонстрируем, как все будет работать. В результате и нам, и заказчику понятны дальнейшие этапы проекта и milestones.
Также для любого машинного обучения, ML-проекта, включая NLP, нужна репрезентативная выборка – образцы документов заказчика, на которых будут обучать систему. Чем их больше, тем лучше.
Заключение
На этих примерах мы показали, как технологии помогают экономить главный наш ресурс — время. По-английски схема называется win-win: роботы берут на себя повторяющиеся задачи, а сотрудники освобождают руки для того, чтобы заниматься более интеллектуальными и интересными проектами. Компании, в которых рутиной заняты не специалисты, а машины, могут выстраивать взаимодействие с клиентами эффективнее, не допускать ошибок при обработке тех или иных документов и быстрее увеличивать доходность.

