Я только что потратил более двух часов на устранение, казалось бы, простой проблемы с HTML. Когда я скопировал и вставил небольшой раздел HTML, веб-браузер отображал только что вставленный раздел не так, как оригинал. Горизонтальный интервал между некоторыми элементами был немного другим, из-за чего вся страница выглядела неправильно. Но как такое могло быть? Два раздела HTML были идентичны — новый был буквально копией старого.
Эта простая на первый взгляд проблема бросала вызов всем моим попыткам ее объяснить. Я придумал множество замечательных теорий: проблемы с моими классами CSS или с полями и отступами. Несоответствующие теги HTML. Ошибки браузера. Я попробовал три разных браузера и во всех получил одинаковые результаты.
Чувствуя себя сбитым с толку, я снова посмотрел на два раздела HTML в редакторе WordPress (текстовое представление) и подтвердил, что они полностью идентичны. Затем я попробовал встроенные в Firefox инструменты веб-разработчика для просмотра отображаемых элементов страницы и сравнил все их свойства CSS. Идентичны, но каким-то образом визуализированы по-разному. Я использовал инструменты разработчика, чтобы проверить точный HTML, полученный с моего веб-сервера, снова проверил два раздела и убедился, что они символьно идентичны. Инструмент Firefox «источник страницы» также подтвердил, что эти два раздела полностью идентичны.
К этому моменту я был готов обвинить космические лучи или магию вуду. Я обнаружил, что каждый раз, когда я копирую любой похожий раздел HTML, только что вставленный раздел будет отображаться в браузере с неправильным интервалом между элементами. Как такое могло быть? Затем я попробовал W3C Validator, который обнаружил некоторые другие проблемы с моей страницей, но ничего не могло объяснить такое поведение. И снова он подтвердил, что, несмотря на разную визуализацию в браузере, два раздела HTML идентичны.
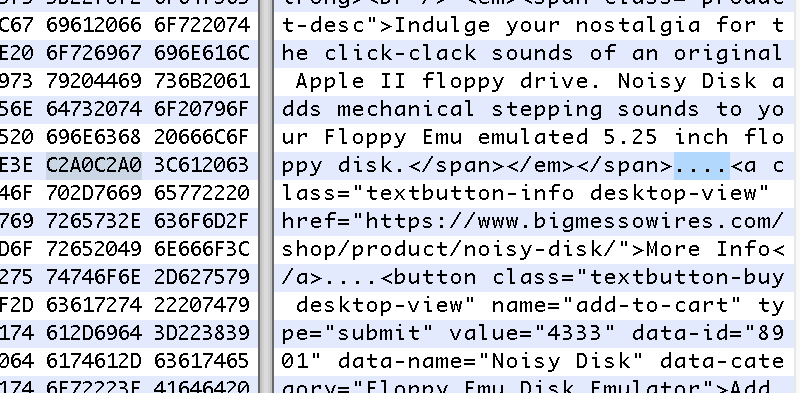
Ясно, что что-то не складывалось. Я использовал curl для загрузки веб-страницы со своего веб-сервера, просмотрел локальную копию и увидел то же поведение, что и раньше. Но когда я открыл сохраненный документ .html с помощью шестнадцатеричного редактора, я наконец получил ответ. Эти два раздела HTML не были идентичными: в одном разделе использовался другой тип пробела, чем в другом.
Что за черт.
Я обнаружил, что исходный раздел HTML содержит неразрывные пробелы. Но вместо того, чтобы кодировать их с помощью & n b s p; они были закодированы юникод-символами C2A0. Не знаю, когда и как это произошло, но виню в этом WordPress. При просмотре этого раздела в редакторе HTML WordPress пробелы C2A0 выглядели как обычные пробелы, и при копировании раздела внутри редактора неразрывные пробелы автоматически преобразовывались в нормальные пробелы с шестнадцатеричным значением 20. Таким образом, скопированная версия отображалась по-другому, хотя исходный HTML оказался таким же.
Это похоже на ремейк 0 ≠ О, только хуже. Я даже не знал, что неразрывные пробелы имеют свою кодировку в Юникоде — я подумал, что & n b s p; был единственным способом их закодировать. Я снова изменил HTML, чтобы использовать & n b s p; и теперь все работает нормально.
Я удивлен, сколько разных инструментов не смогли выявить это тонкое, но важное различие между типами пробелов в исходном HTML-коде. Редактор HTML WordPress не смог показать или правильно обработать разницу. Сбой инструментов веб-разработчика Firefox и инструментов источника страниц. Ошибка исходного представления валидатора W3C. Curl плюс шестнадцатеричный редактор был единственным способом окончательно установить достоверную информацию о точном содержании исходного кода HTML.

