

Термин web scraping означает извлечение информации из веб-страниц в интернете. Его ещё называют web crawling или web data extraction.
PHP широко используется в качестве серверного скриптового языка для создания динамических сайтов и веб-приложений. И на нём можно написать веб-скрейпер. Но поскольку мы не хотим изобретать колесо, можно воспользоваться готовыми open-source библиотеками для веб-скрейпинга. Кстати, мы также написали отличную статью про веб-скрейпинг с помощью Node.js и с помощью Python, почитайте. А здесь мы обсудим разные инструменты и сервисы, которые можно использовать с PHP для скрейпинга веб-страниц: Guzzle, Goutte, Simple HTML DOM, Headless-браузер Symfony Panther.
Вот что нам потребуется для работы:
- Установите последнюю версию PHP.
- Скачайте Composer и настройте его для установки разных PHP-зависимостей для библиотек веб-скрейпинга.
- Выберите редактор по вкусу.
После этого создайте директорию проекта и перейдите в неё:
mkdir php_scraper cd php_scraper
Выполните в терминале эти две команды для инициализации composer.json:
composer init — require=”php >=7.4" --no-interaction composer update
Приступим.
1. Веб-скрейпинг на PHP с использованием Guzzle, XML и XPath
Guzzle — это HTTP-клиент для PHP, позволяющий легко отправлять HTTP-запросы. Он предоставляет простой интерфейс для написания строк запросов. XML — язык разметки для представления документов в удобочитаемом для человека и компьютера формате. XPath — это язык запросов для навигации и выбора XML-узлов.
Посмотрим, как можно использовать эти инструменты для скрейпинга сайта. Начнём с установки Guzzle через Composer, выполним в терминале команду:
composer require guzzlehttp/guzzle
После установки Guzzle создадим новый PHP-файл guzzle_requests.php, в который будем добавлять код. Для примера спарсим сайт Books to Scrape, другие сайты вы сможете скрейпить действуя аналогично. Books to Scrape выглядит так:
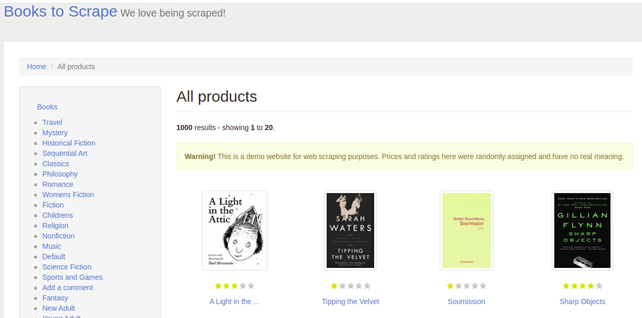
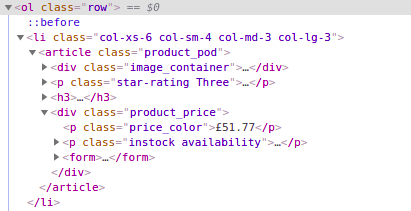
Нам нужно извлечь названия книг и отобразить их в терминале. Первым делом нужно разобраться в HTML-макете. В этом случае его можно посмотреть, кликнув правой кнопкой над списком книг и выбрав пункт Inspect. Скриншот исходного кода страницы:

Внутри элемента
<оl class=”rоw”> находится список. Следующий дочерний элемент — li. Нам нужно название книги, оно записано внутри а, внутри h3, внутри article, и наконец внутри элемента li. Чтобы инициализировать Guzzle, XML и Xpath добавьте в guzzle_requests.php такой код:<?php# scraping books to scrape: https://books.toscrape.com/ require ‘vendor/autoload.php’; $httpClient = new \GuzzleHttp\Client(); $response = $httpClient->get(‘https://books.toscrape.com/'); $htmlString = (string) $response->getBody(); //add this line to suppress any warnings libxml_use_internal_errors(true); $doc = new DOMDocument(); $doc->loadHTML($htmlString); $xpath = new DOMXPath($doc);
Этот код скачивает страницу в виде строки, затем парсит её с помощью XML и присваивает переменной
$xpath. Теперь нужно указать целевой текст внутри тега a. Добавим в файл$titles = $xpath->evaluate(‘//ol[@class="row"]//li//article//h3/a’); $extractedTitles = []; foreach ($titles as $title) { $extractedTitles[] = $title->textContent.PHP_EOL; echo $title->textContent.PHP_EOL; }
В этом коде
//ol[@class="row"] получает весь список. У каждого элемента списка есть тег a, который нас интересует для извлечения названий книг. Только тег h3 содержит a, это облегчает работу с ним. Для извлечения текстовой информации и её отображения в терминале воспользуемся циклом foreach. На этом этапе вы можете что-нибудь сделать с извлечёнными данными, например, присвоить их переменной массива, записать в файл или сохранить в БД. Вы можете выполнить файл с помощью PHP в терминале, запустив приведённую ниже команду. php guzzle_requests.php
На экране должно появиться вот что:

Работает. А что если теперь нам нужно получить стоимость книг?
Цена находится в теге
p внутри тега div. В коде страницы несколько тегов p и несколько div. Чтобы найти нужные, мы воспользуемся селекторами классов CSS, которые, к счастью, уникальны для каждого тега. Вот код получения тега цен и конкатенации его со строкой заголовка:$titles = $xpath->evaluate(‘//ol[@class=”row”]//li//article//h3/a’); $prices = $xpath->evaluate(‘//ol[@class=”row”]//li//article//div[@class=”product_price”]//p[@class=”price_color”]’); foreach ($titles as $key => $title) { echo $title->textContent . ‘ @ ‘. $prices[$key]->textContent.PHP_EOL; }
Если исполнить код в терминале, то получим:

Ваш код должен выглядеть так:
<?php # scraping books to scrape:https://books.toscrape.com/ require ‘vendor/autoload.php’; $httpClient = new \GuzzleHttp\Client(); $response = $httpClient->get(‘https://books.toscrape.com/'); $htmlString = (string) $response->getBody(); //add this line to suppress any warnings libxml_use_internal_errors(true); $doc = new DOMDocument(); $doc->loadHTML($htmlString); $xpath = new DOMXPath($doc); $titles = $xpath->evaluate(‘//ol[@class=”row”]//li//article//h3/a’); $prices = $xpath->evaluate(‘//ol[@class=”row”]//li//article//div[@class=”product_price”]//p[@class=”price_color”]’); foreach ($titles as $key => $title) { echo $title->textContent . ‘ @ ‘. $prices[$key]->textContent.PHP_EOL; }
Конечно, это лишь базовый веб-скрейпер, его можно улучшить. Перейдём к следующей библиотеке.
2. Веб-скрейпинг на PHP с использованием Goutte
Goutte — ещё один прекрасный HTTP-клиент для PHP, созданный специально для веб-скрейпинга. Его разработал автор фреймворка Symfony, он предоставляет хороший API для извлечения данных из HTML/XML-ответов сайтов. Вот некоторые компоненты клиента для упрощений скрейпинга:
- BrowserKit для симуляции поведения браузера.
- CssSelector для перевода CSS-запросов в XPath-запросы.
- DomCrawler позволяет использовать DOMDocument и XPath.
- Symfony HTTP-клиент — новый компонент от команды Symfony.
Установим Goutte через Сomposer, выполнив в терминале:
composer require fabpot/goutte
После установки создадим новый файл goutte_requests.php для кода. Ниже мы обсудим, что мы сделали с помощью библиотеки Guzzle в предыдущей главе. Извлечём с помощью Goutte названия книг с сайта Books to Scrape. Также покажем, как можно добавлять цены в переменную массива и использовать её в коде. Добавьте в файл goutte_requests.php этот код:
<?php # scraping books to scrape:https://books.toscrape.com/ require ‘vendor/autoload.php’; $httpClient = new \Goutte\Client(); $response = $httpClient->request(‘GET’, ‘https://books.toscrape.com/'); $titles = $response->evaluate(‘//ol[@class=”row”]//li//article//h3/a’); $prices = $response->evaluate(‘//ol[@class=”row”]//li//article//div[@class=”product_price”]//p[@class=”price_color”]’); // we can store the prices into an array $priceArray = []; foreach ($prices as $key => $price) { $priceArray[] = $price->textContent; } // we extract the titles and display to the terminal together with the prices foreach ($titles as $key => $title) { echo $title->textContent . ‘ @ ‘. $priceArray[$key] . PHP_EOL; }
Выполним его с помощью команды в терминале:
php goutte_requests.php
Результат:

Выше показан один из способов скрейпинга с помощью Goutte. Давайте рассмотрим способ с применением компонента CSSSelector из Goutte. CSS-селектор проще в использовании, чем XPath из предыдущего способа. Создадим ещё один PHP файл — goutte_css_requests.php. Добавим в него код:
<?php # scraping books to scrape:https://books.toscrape.com/ require ‘vendor/autoload.php’; $httpClient = new \Goutte\Client(); $response = $httpClient->request(‘GET’, ‘https://books.toscrape.com/'); // get prices into an array $prices = []; $response->filter(‘.row li article div.product_price p.price_color’)->each(function ($node) use (&$prices) { $prices[] = $node->text(); }); // echo titles and prices $priceIndex = 0; $response->filter(‘.row li article h3 a’)->each(function ($node) use ($prices, &$priceIndex) { echo $node->text() . ‘ @ ‘ . $prices[$priceIndex] .PHP_EOL; $priceIndex++; });
CSSSelector сделал код чище и удобочитаемее. Вы могли заметить, что мы использовали оператор
&, который обеспечивает передачу в цикл «each» ссылки на переменную, а не просто её значение. Если цикл меняет &$prices, то фактические значения за пределами цикла тоже меняются. Подробнее о присвоении по ссылкам можно почитать в официальной документации PHP. Выполним файл в терминале:php goutte_css_requests.php
И увидим аналогичный результат:

Наш веб-скрейпер с Goutte работает хорошо. Давайте теперь посмотрим, можно ли кликнуть на ссылку и перейти на другую страницу. На нашем демо-сайте Books to Scrape при клике на название книги загружается страница с описанием:

Посмотрим, можно ли кликнуть на ссылку в списке книг, перейти на страницу с описанием и извлечь его. Изучим код интересующей страницы:
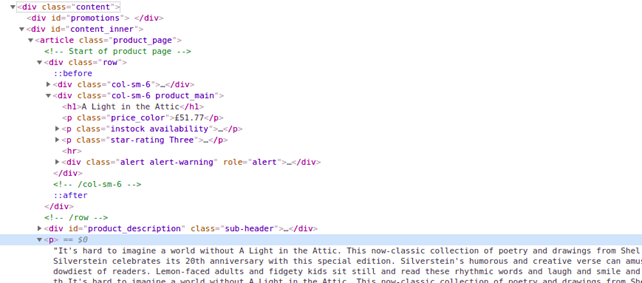
Наш целевой путь будет таким: элемент
div clаss="content", затем div id="content_inner", затем один тег article, и наконец тег p. У нас есть несколько тегов p, тег с описанием является четвёртым внутри родительского элемента div class="content". Поскольку массивы начинаются с 0, мы будем получать ноду в третьем индексе. Теперь напишем код. Сначала добавим Composer-пакет для облегчения парсинга HTML5:composer require masterminds/html5
Модифицируем файл goutte_css_requests.php:
<?php # scraping books to scrape:https://books.toscrape.com/ require ‘vendor/autoload.php’; $httpClient = new \Goutte\Client(); $response = $httpClient->request(‘GET’, ‘https://books.toscrape.com/'); // get prices into an array $prices = []; $response->filter(‘.row li article div.product_price p.price_color’) ->each(function ($node) use (&$prices) { $prices[] = $node->text(); }); // echo title, price, and description $priceIndex = 0; $response->filter(‘.row li article h3 a’) ->each(function ($node) use ($prices, &$priceIndex, $httpClient) { $title = $node->text(); $price = $prices[$priceIndex]; //getting the description $description = $httpClient->click($node->link()) ->filter(‘.content #content_inner article p’)->eq(3)->text(); // display the result echo “{$title} @ {$price} : {$description}\n\n”; $priceIndex++; });
Если исполнить его в терминале, то мы увидим название, цену и описание книги:
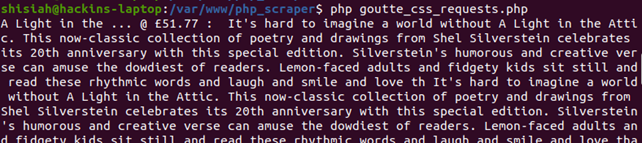
С помощью компонента Goutte CSS Selector и возможности кликать на странице вы можете легко бродить по многостраничным сайтам и извлекать сколько угодно информации.
3. Веб-скрейпинг на PHP с использованием Simple HTML DOM
Simple HTML DOM — ещё одна минималистичная библиотека веб-скрейпинга для PHP. Извлекать информацию будем с того же сайта. Прежде чем устанавливать пакет, изменим файл composer.json и добавим нижеуказанные строки сразу после блока
require:{}, чтобы избежать ошибок версионирования:“minimum-stability”: “dev”, “prefer-stable”: true
Теперь можно устанавливать библиотеку:
composer require simplehtmldom/simplehtmldom
Затем создаём новый PHP-файл — simplehtmldom_requests.php. Мы уже рассматривали макет страницы, так что сразу перейдём к коду. Добавьте в simplehtmldom_requests.php:
<?php # scraping books to scrape:https://books.toscrape.com/ require ‘vendor/autoload.php’; $httpClient = new \simplehtmldom\HtmlWeb(); $response = $httpClient->load(‘https://books.toscrape.com/'); // echo the title echo $response->find(‘title’, 0)->plaintext . PHP_EOL . PHP_EOL; // get the prices into an array $prices = []; foreach ($response->find(‘.row li article div.product_price p.price_color’) as $price) { $prices[] = $price->plaintext; } // echo titles and prices foreach ($response->find(‘.row li article h3 a’) as $key => $title) { echo “{$title->plaintext} @ {$prices[$key]} \n”; }
Если выполнить код в терминале, получим:
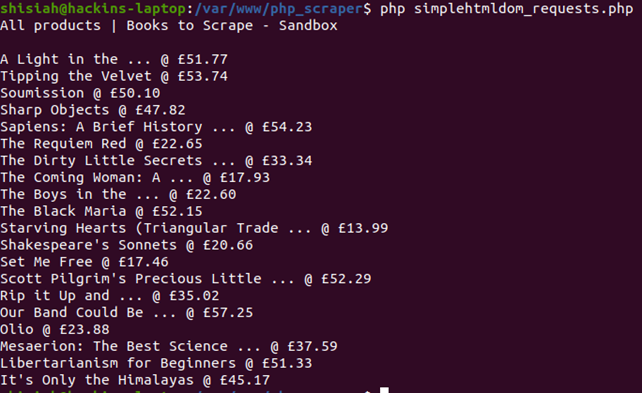
Больше способов скрейпинга с помощью Simple HTML DOM описано в официальной документации по API.
4. Веб-скрейпинг на PHP с использованием Headless-браузера Symfony Panther
Headless-браузер — это браузер без графического интерфейса. Благодаря этой особенности мы можем использовать терминал для загрузки страниц в среде, аналогичной браузеру и писать код для управления навигацией, как в предыдущих примерах. Зачем это нужно? Сегодня большинство разработчиков используют для развёртывания веб-фреймворки на JavaScript. Эти фреймворки генерируют внутри браузеров HTML-код. В других случаях для динамической загрузки содержимого применяют AJAX. В предыдущих примерах мы использовали статичные HTML-страницы, поэтому и результат скрейпинга был согласованным. А в случае с динамическими страницами, в которых HTML генерируется с помощью JavaScript и AJAX, получившееся DOM-дерево может сильно отличаться, что нарушит работу скрейпера. Решить эту проблему поможет headless-браузер.
В качестве такого браузера можно использовать PHP-библиотеку Symfony Panther. Её применяют и для скрейпинга, и для прогона тестов с использованием настоящих браузеров. Кроме того, библиотека предоставляет такие же методы, как и Goutte, поэтому можно использовать Panther вместо Goutte. Возможности Panther:
- исполняет JavaScript в веб-страницах;
- поддерживает удалённое браузерное тестирование;
- поддерживает асинхронную загрузку элементов посредством ожидания загрузки других элементов, прежде чем выполнить определённую строку кода;
- поддерживает все реализации Chrome и Firefox;
- может делать скриншоты;
- позволяет запускать пользовательский JS-код или XPath-запросы в контексте загруженной страницы.
Мы уже много скрейпили, попробуем кое-что другое. Будем загружать HTML-страницу и делать её скришот. Установим Symfony Panther:
composer require symfony/panther
Создадим новый PHP-файл panther_requests.php. Добавим в него код:
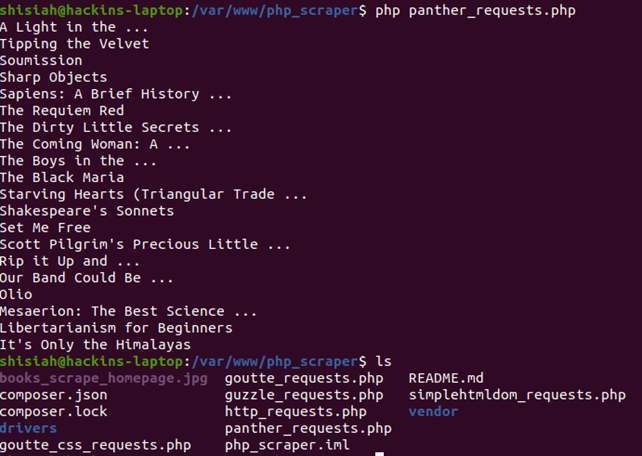
<?php # scraping books to scrape:https://books.toscrape.com/ require ‘vendor/autoload.php’; $httpClient = \Symfony\Component\Panther\Client::createChromeClient(); // for a Firefox client use the line below instead //$httpClient = \Symfony\Component\Panther\Client::createFirefoxClient(); // get response $response = $httpClient->get(‘https://books.toscrape.com/'); // take screenshot and store in current directory $response->takeScreenshot($saveAs = ‘books_scrape_homepage.jpg’); // let’s display some book titles $response->getCrawler()->filter(‘.row li article h3 a’) ->each(function ($node) { echo $node->text() . PHP_EOL; });
Чтобы запустить его в системе, нужно установить драйверы для Chrome или Firefox, в зависимости от клиента, используемого в вашем коде. К счастью, Composer может это сделать автоматически. Выполним в терминале команду установки и определения драйверов:
composer require --dev dbrekelmans/bdi && vendor/bin/bdi detect drivers
Теперь можно выполнить в терминале PHP-файл, который сделает скриншот страницы и сохранит его в текущую директорию, а потом покажет список названий книг со страницы.
Заключение
Мы рассмотрели разные open-source PHP-библиотеки, которые можно использовать для скрейпинга сайтов. С помощью этого руководства вы сможете сделать простенький скрейпер для одной-двух страниц. Хотя мы прошлись лишь по верхам, но рассмотрели большинство доступных способов использования библиотек. Теперь вы можете сделать более сложный скрейпер, способный обходить тысячи страниц. Код из статьи лежит в репозитории.
Дополнительные источники информации, которые могут быть вам полезны
