Всем доброго времени суток. Сегодня хочу рассказать максимум о регулярных выражениях: что они из себя представляют, как их писать, для чего нужны и т.д.
Информации о регулярках много, они разбросаны по разным сайтам и я решил собрать всё, касательно регулярок, в одну статью. Ну что-ж, приступим поскорее к делу :)
Содержание
Что такое регулярка и с чем ее едят?
Где писать регулярки?
Самые простые регулярки
Квантификаторы
Специальные символы квантификаторов
Специальные символы
Lookahead и lookbehind (опережающая и ретроспективная проверки)
Регулярные выражения в разных языках программирования
Заключение
Что такое регулярка и с чем ее едят?
Если по простому, регулярка- это некий шаблон, по которому фильтруется текст. Мы можем написать нужный нам шаблон (регулярку) и таким образом искать в тексте необходимые нам символы, слова и т.д. Также их используют, например, при заполнении поля E-mail на различных сайтах, т.е. создают шаблон по типу: someEmail@gmail.com. Это я взял как пример, не более. Теперь, разобравшись, что это, приступим к изучению. Обещаю, скучно не будет)
Где писать регулярки?
Регулярки мы можем писать как на специальных сайтах, так и используя какой-либо язык программирования. Синтаксис (правила написания регулярок) не привязан к какому-то отдельному языку программирования. Поэтому, изучив регулярные выражения, вы сможете пользоваться ими где захотите. Сначала, в рамках изучения, воспользуемся отличным сайтом, а как писать регулярные выражения в различных языках программирования, рассмотрим чуточку позже.
Сразу дам ссылку на сайт, чтобы вы могли уже писать вместе со мной https://www.regextester.com/
Коротко о том, как пользоваться сайтом. Сверху, в графе Regular Expression вы пишете само регулярное выражение, а под ним, в графе Test String вы пишете строку, которую вы хотите фильтровать. Если были найдены соответствия между регулярным выражением и текстом, в тексте эти соответствия будут помечены синим цветом, вы их сразу увидите, даже не сомневайтесь.
Самые простые регулярки
Перед тем, как писать регулярку, возьмем некоторый текст, чтобы мы не фильтровали пустоту. Допустим, у нас будет строка some text. И допустим мы хотим найти слово text. Для этого в саму регулярку мы должны написать просто слово text и он найдет его.

Вот и всё, надеюсь вы поняли регулярные выражения, спасибо за внимание...
Шутка конечно, это далеко не всё. Например, мы можем написать одну букву t, и он найдет все буквы t в тексте.
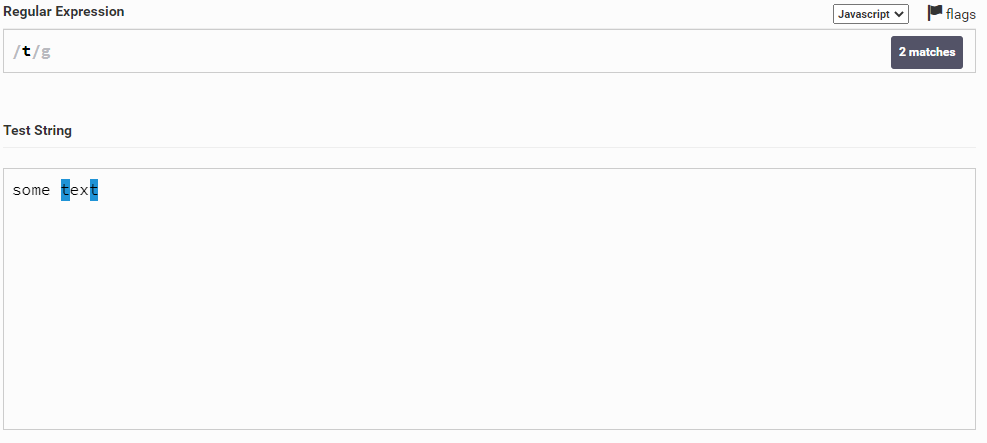
Таким образом вы можете просто указывать какие-то символы, но нам не всегда даются конкретные символы, а нужно написать какой-то шаблон. Сейчас этим и займемся.
Квантификаторы
Понимаю, звучит страшно, но на деле все просто. Сейчас разберемся.
С помощью квантификаторов мы можем указывать сколько раз должен повторяться тот или иной символ (ну или группа символов). Ниже приведу список квантификаторов с пояснением, а дальше попрактикуемся с ними.
{n} - символ повторяется ровно n раз
{m,n} - символ повторяется в диапазоне от m до n раз
{m,} - символ повторяется минимум m раз (от m и более)
Теперь посмотрим на примерах. Допустим у нас есть строка s ss sss ssss. И мы хотим выбрать слово, где буква s повторяется ровно 3 раза. Для этого мы можем написать так: s{3} - то есть пишем символ s, тем самым говоря, что хотим выбрать именно его, и рядом пишем {3}, говоря, что он должен повторяться ровно 3 раза. В результате будет найдено слово sss

Почему же он взял еще ssss? Он взял не совсем его, а лишь его часть, так как в нем тоже есть 3 буквы s подряд. Дело в том, что регулярка не будет учитывать, отдельное это слово или нет. Пробелы тоже идут как символы! Поэтому будет выбран любой фрагмент, которому соответствует 3 идущие подряд буквы s
Едем дальше, допустим мы хотим выбрать фрагмент, где символ s будет от одного до трех раз. Для этого мы можем написать s{1,3} - опять же указываем s и пишем {1,3}, говоря, что нам нужно, чтобы этот символ повторялся от одного до трех раз.

Интересный момент получается, он выбрал все. Почему же? Ответ: та же ситуация, что и в прошлый раз. Он увидел ssss, взял 3 идущие подряд s вместе и еще одну s, которая рядом, ведь она тоже соответствует регулярку (а ведь мы помним, что мы указали диапазон от одного до трех раз)
Ну и напоследок, давайте напишем шаблон, где символ s будет повторяться минимум три раза. Для этого напишем следующее: s{3,} ({3,} обозначает, что символ s будет повторяться от трех раз и до бесконечности).

Специальные символы квантификаторов
Есть уже готовые квантификаторы, которые обозначаются спец. символами. Вот они:
? ({0,1}) - символ повторяется 0 или 1 раз
* ({0,}) - символ повторяется от 0 раз и более
+ ({1,}) - символ повторяется от 1 и более раз
Давайте разбираться. Начнем со знака вопроса. Допустим у нас есть строка colour color и мы хотим найти либо colour, либо color. Мы можем написать так: colou?r.
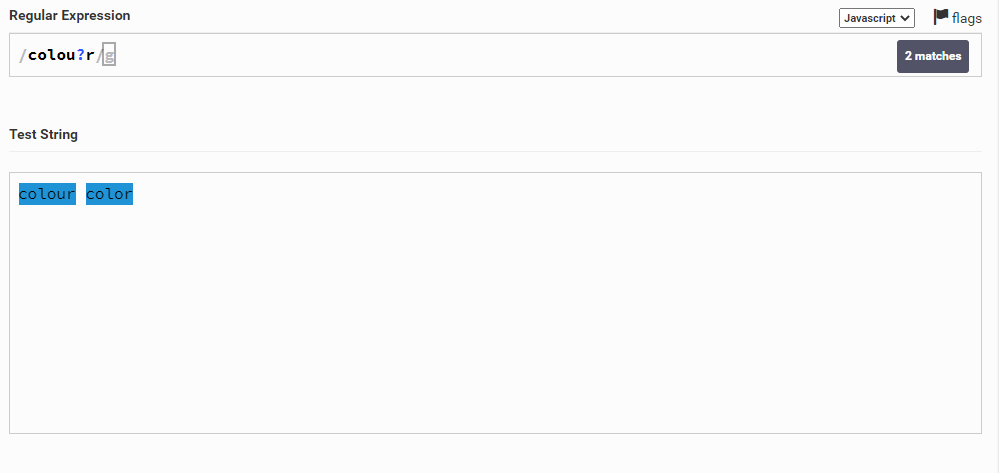
Что произошло? Мы указали, что идет последовательность символов colo, потом написали u? (тоже самое, что и u{0,1}). Это значит, что символ u повторяется 0 или 1 раз (то есть либо его нет вовсе (он не повторяется, то есть повторяется 0 раз), либо он есть, но только один (повторяется один раз)). Ну а потом указали, что после должен идти символ r. Поэтому colour соответствует, так как буква u повторяется 1 раз, а color - так как u вообще отсутствует (повторяется 0 раз). Видите, все просто :)
Давайте изменим строку и напишем что-то по типу colouuuuur color. И допустим мы хотим указать, что u должен либо не быть, либо быть сколько угодно раз. Для этого мы можем написать colou*r.

То есть либо u у нас нет, либо повторяется много раз.
Символ + работает почти также, за исключением того, что символ должен повторяться минимум 1 раз. То есть в данном случае слово color не будет соответствовать, так как там u не присутствует (то есть повторяется 0 раз, а у нас символ должен повторяться минимум 1 раз)

Специальные символы
Теперь поговорим о специальных символах, которые используются в регулярках. Тут все очень просто, так что можете сильно не переживать. Скрины прикреплять буду здесь не везде (тогда статья разрастется до безумных размеров). Так что заранее прошу меня понять и простить и попробовать сами.
. - одиночный символ
[] - набор символов, например [A-Z] обозначает все символы от A до Z
^ - начало строки
$ - конец строки
\ - экранирование
\d - любая цифра
\D - все, кроме цифр
\s - пробелы
\S - все, кроме пробелов
\w - буква
\W - все, кроме букв
[^someSymbol] - отрицание символа, соответсвие всем символам, кроме выбранного
Поговорим об одиночном символе. Это значит, что будет выбираться любой символ, который повторяется только один раз. Например, вернемся к нашей строке Some text и выберем букву t, после которой идет любой символ. Для этого напишем t.
Выберется te, так как после t идет один любой символ (в данном случае е)

Едем дальше. Допустим, у нас есть строка Some text12345 и мы хотим выбрать все буквы (только буквы, числа нам не нужны). Для этого мы можем написать следующее [A-Z,a-z] . Что же это значит? Это значит, что мы указали, что мы хотим выбрать все символы в диапазоне от A до Z (это мы выбираем все заглавные буквы) и, затем, через запятую, мы говорим о том, что хотим выбрать все символы от a до z (здесь мы выбираем все строчные символы).

Теперь давайте возьмем слово test и выделим в нем первую букву t. Для этого мы можем написать ^t. То есть мы написали символ t и указали, что он должен находиться в самом начале строки. Важно поставить символ ^ перед нужным нам символом.
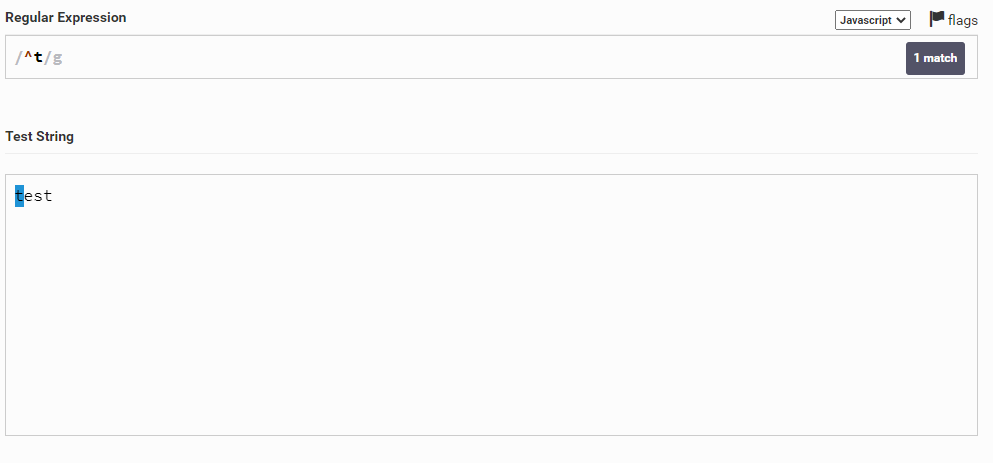
Теперь давайте сделаем наоборот и возьмем последнюю букву t. Для этого напишем t$. Важно, чтобы символ $ стоял после нужного нам символа.

Перейдем к экранированию. Звучит страшно, но на деле все проще простого. Например, в тексте some text. мы хотим выделить точку. Но ведь точка у нас уже зарезервирована как специальный символ (напоминаю, точка обозначает любой одиночный символ). И чтобы сделать так, чтобы точка на считалась как спец. символ мы можем написать \. и тем самым говоря, что точка у нас будет как обычный символ.
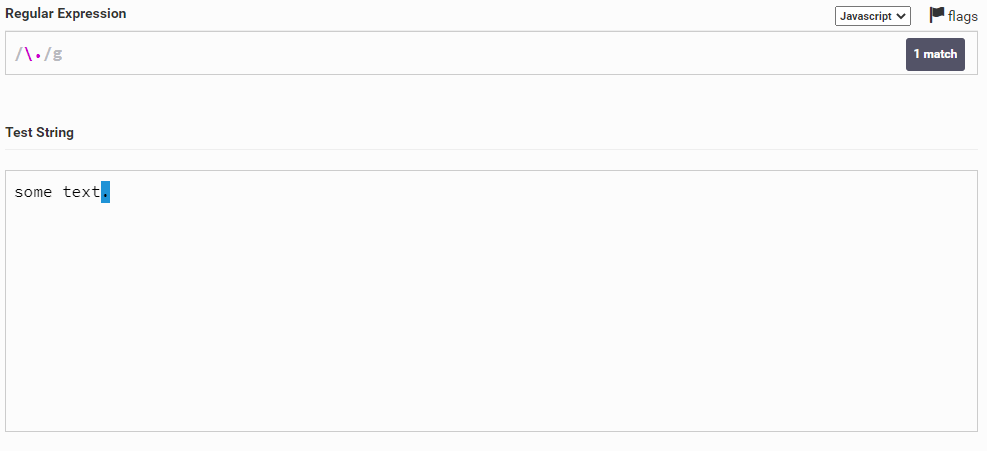
Теперь идут, простые вещи. \d у нас обозначает любую цифру. Например в тексте some text123, если написать \d у нас будут выделяться только цифры.
\D делает все наоборот: берутся все символы, кроме цифр. То есть, если написать \D будет браться все, кроме цифр (и пробелы, кстати, тоже).
\s берет все пробелы, которые есть в строке, а \S - наоборот, все, кроме пробелов.
\w берет буквы, а \W берет, все, кроме букв (в том числе и пробелы).
Теперь расскажу про еще одно применение символа ^. Его можно использовать как отрицание, тем самым исключая символ или группу символов. Например, в слове test мы хотим выбрать все, кроме буквы t и для этого мы можем написать так: [^t]

Именно в такой последовательности символ ^ будет обозначать отрицание.
Lookahead и lookbehind (опережающая и ретроспективная проверки)
Давайте разберемся, что это такое. Lookahead или же опережающая проверка позволяет выбрать символ или группу символов, если после него идет идет какой-либо символ или группа символов. Lookbehind или же ретроспективная проверка позволяет выбрать символ или группу символов, если до них идет какой-то символ или группа символов.
lookahead - опережающая проверка - X(?=Y) - найти Х, при условии, что после него идет Y
негативная опрережающая проверка - Х(?!Y)
lookbehind - ретроспективная проверка - (?<=Y)X - найти Х, при условии, что до него идет Y
негативная ретроспективная проверка - (?<!Y)Xo
Например, дана строка s sw sd st se и мы хотим выбрать букву s, после которой будет идти символ d. Для этого мы можем написать следующее: s(?=d). Таким образом мы как бы проверяем, будет ли идти после символ s символ d.
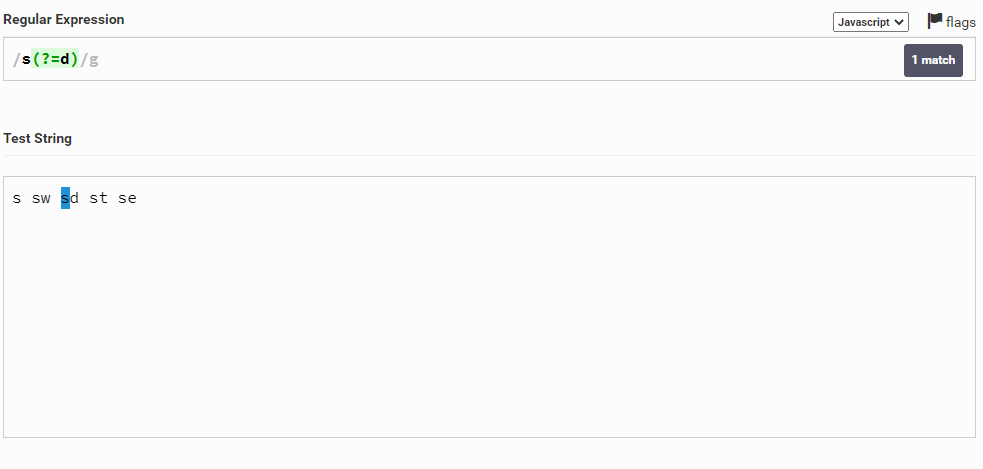
Также мы можем сделать наоборот и выбрать символ s, если после него НЕ идет символ d. Для этого вместо знака равно мы должны поставить восклицательный знак (!), т.е. написать вот так: s(?!d)

Теперь поговорим о lookbehind. Допустим, у нас есть строка s ws ds ts es и мы хотим выбрать символ s, до которого будет символ d. Для этого мы можем написать так: (?<=d)s
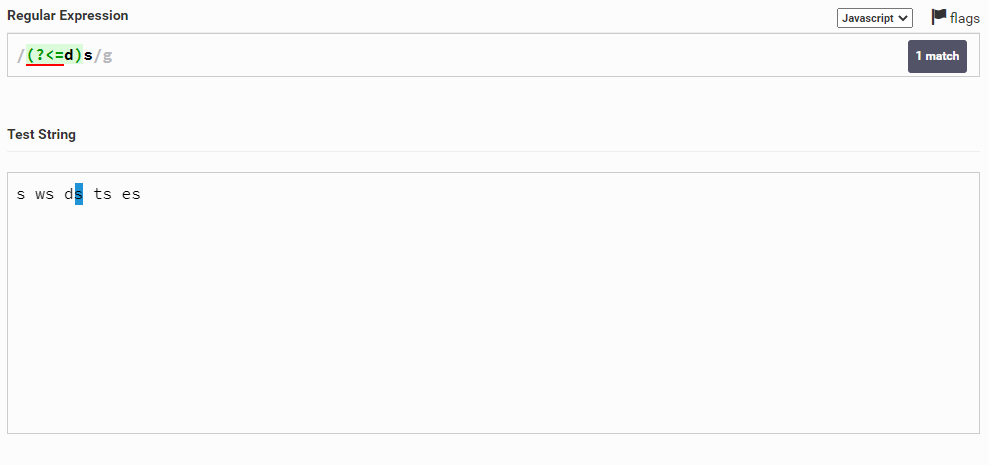
Почему же lookbehind подчеркивается красной линией? Дело в том, что lookbehind не всегда поддерживается и не везде такая регулярка будет работать. Нужно искать способ заменить этот lookbehind, но это зависит от поставленной задачи, поэтому нельзя сказать, как именно ее заменять. Будем надеяться, что в скором временем будет полная поддержка этой возможности.
Чтобы сделать наоборот, то есть выбрать все символы s, до которых НЕ будет идти символ d, нужно опять же поменять знак равно на восклицательный знак: (?<!d)s

Регулярные выражения в разных языках программирования
Здесь я приведу примеры использования регулярных выражений в различных языках программирования. Заранее говорю, я не буду заострять внимание на синтаксисе языка программирования, так как это уже не касается данной темы
C#
string str = "some text"; Regex regex = new Regex(@"t$"); MatchCollection matches = regex.Matches(str);
Здесь мы создаем строку с текстом, который хотим проверить, создаем объект класса Regex и в конструктор пишем нашу регулярку (как я и говорил, я не буду заострять внимание на том, что такое объект класса и конструктор). Потом создаем объект класса MatchCollection и от объекта regex вызываем метод Matches и в параметры передаем нашу строку. В результате все сопоставления будут добавляться в коллекцию matches.
Java
Pattern pattern = Pattern.compile("some text", Pattern.CASE_INSENSITIVE); Matcher matcher = pattern.matcher("t$");
Здесь похожая ситуация. Создаем объект класса Pattern и записываем нашу строку. CASE_INSENSITIVE означает, что он не привязан к регистру (то есть нет разницы между заглавными и строчными символами). Создаем объект класса Matcher и пишем туда регулярку.
JavaScript
var regex = /d(b+)d/g; var matches = regex.exec("cdbbdbsbz");
Здесь тоже все просто. Вы создаете объект regex и пишете туда регулярку. И затем просто создаете объект matches, который будет являться коллекцией и вызываете метод exec и в параметры передаете строку.
Заключение
Итак, мы разобрали, что такое регулярные выражения, где они используются, как их писать и использовать в контексте языков программирования. Скажу сразу, написание регулярок приходит с опытом. Практикуйтесь, и я уверен: все у вас получится! А на этом я с вами прощаюсь. Спасибо за внимание и приятного всем дня)
P.S. Прошу строго не судить, это самая первая статья, которую я написал. Любая критика приветствуется.

