
В своем первом пробном цикле статей я хочу немного обозреть некоторые особенности упомянутого выше российского DSP процессора. Про этот процессор уже были упоминания и не одно, в том числе и на Хабре, например, здесь. Поэтому не буду разбирать его общий функционал, откуда и когда он взялся, а так же чьим родственником он является. Но желание этим заняться у меня вызвало в первую очередь то, что мне самому по долгу службы пришлось столкнуться с данным товарищем и это по сути мой первый опыт работы с процессором DSP. Поэтому данный текст будет полезен в первую очередь тем кто только начинает разбираться с подобными процессорами, или же просто интересуется из общего интереса.
Большая проблема любого начинающего разработчика сталкивающегося с отечественным процессором, это в первую очередь очень малое количество примеров, с оглядкой на которые он сможет сделать первые робкие шаги, и освоившись уже топить тапкой в пол. В случае с данным процессором, разработчик предоставляет достаточно много подробной документации, также имеется образовательный сайт, на котором есть несколько примеров, и форум. Но, конечно информация там не исчерпывающая, а по ассемблеру примеров вообще не очень много. Исходя из этого было решено изучать процессор по документации и эмпирически, а свои впечатления записывать, быть может кому пригодятся. На этом лирическое вступление считаю нужно заканчивать и переходить к конструктиву.
Структура
Фирма предоставляет достаточно много документации, но что-то полезное для программирования есть только в спецификации на процессор и в руководстве по программированию.
Структура программ получается следующая:
1) Сначала подрубаем все нужные нам библиотеки и дефайним нужные нам дефайны…
2) Далее мы доходим до объявления переменных и написания уже непосредственно алгоритма функций и тела. Тут стоит обратить внимание что у нас в процессоре имеется 6 банок по 4 Мбит SRAM. При объявлении переменных или массивов переменных, необходимо начинать диалог со слов:
.SECTION /DOUBLE64 /CHAR32 .data;
.align 4;
Далее перечисляете нужные вам переменные и массивы до тех пор, пока у нас с вами не закончится банка памяти. Вспоминаем что в одной банке памяти 4Мбит из этого следует что в одну банку памяти поместится 128к 32-битных слов, при попытке впихать невпихуемое, компилятор будет ругаться. На самом деле в банки в среднем можно запихнуть до 130к 32-битных слов, как это коррелирует с вышесказанным пока не понятно. Если одной банки памяти нам оказалось мало то можно захватить вторую и т.д. Имена банок для обращения через оператор .SECTION удобно брать из файла .ldf. Помимо .data это может быть - .cdata, .bss, .ehframe и т.д.
3) Для перехода к написанию алгоритма необходимо перейти в секцию .program и далее следующим образом глобально объявить тело и имена функций
.GLOBAL _main;
При этом секции памяти можно также назначать подсекции
.SECTION /DOUBLE64 /CHAR32 .program._main;
.ALIGN_CODE 4;
Смысл этого действия состоит в том по сколько байт мы выравниваем информацию при размещении в памяти.
В примере от производителя вообще представлена какая-то такая конструкция
.SECTION /DOUBLE64 /CHAR32 .program._main;
.ALIGN_CODE 4;
.GLOBAL _main;
.TYPE _main,@function;
Причем что тело функции должно не только начинаться с метки начала, для тела которая только «_main:» а для остальных функций уже на своё усмотрение. Но и заканчиваться функция должна соответственно на метку, например, в случае с главным телом «_main.end:», с другими функциями аналогично.
Далее перейдем к не разобранному синтаксису. Уже встреченная нами и необъясненная «.align 4» выравнивание данных по адресу. Соответственно если мы хотим разместить в памяти 64битные данные, то выравнивание надо делать уже 8. Следовательно если мы поставим выравнивание больше чем надо, например, при работе с 32 битными числами поставим значение 8, то никто не пострадает, просто в банку теперь поместится не 128к слов, а 64к.
Архитектура
Архитектура процессора, как пишут в спецификации ближе к архитектуре VLIW. Так же процитируем: "Высокая производительность процессора достигается отчасти за счет возможности исполнения до четырех 32- битных команд в одном такте". В синтаксисе это реализуется следующим образом, символ «;;» знаменует конец полного такта. И если у нас последовательно идет, например, запись в регистры, принадлежащие разным группам или идет работа разных арифметических устройств, то эти операции можно разделять одинарным знаком «;». В таком случае за один такт мы успеем гораздо больше.
Регистры
Как таковых отдельных регистров РОН нет, их функцию выполняют по большей части регистры ALU. Всего 32 регистра в блоке X и столько же в блоке Y. В эти регистры мы при написании кода можем класть значения напрямую.
Отдельного внимания заслуживает механика обращения к регистрам. Если мы обращаемся к регистру из блока X, то следует обращаться XR0, аналогично с Y. В случае, когда приставка отсутствует это понимается как работа с XY т.е. с обоими блоками параллельно.
Типы арифметических операций с фиксированной точкой выбираются если обращаться к регистрам как указано выше. Для перехода к операциям с плавающей точкой, при обращении к регистру добавляется приставка «F» перед R (XFR0).
Ширина данных при проведении арифметических операций также выбирается приставками:
Разрядность | Синтаксис |
8 | XBR0 |
16 | XSR0 |
32 | XR0 |
64 | XR3:2 |
Стоит отметить, что при обращении к сдвоенному регистру меньшим номером регистра должен являться четный номер либо ноль. Стоит помнить, арифметические операции будут происходить только в рамках заявленной разрядности.
Помимо регистров ALU есть еще регистры IALU (целочисленного АЛУ). Это блоки регистров J и K. Блоки это представлены в таком же количестве по 32 шт. Так же есть и много иных регистров, но это основные две группы об остальных походу.
Арифметика
Арифметика была бы проста и понятна если бы не шаманства с опциями и приставками, которые в общем тоже не представляют серьёзной проблемы.
Фиксированная точка
Сложение двух чисел
Xr0=r8+r13;;
Xr3=r3+r4;;
Вычитание аналогично…
Умножение и деление тоже аналогично. Как видно приставки указываются только один раз.
Теперь про опции. Все их перечислять не вижу смысла, ибо проще посмотреть в документах. Но, например, если сложение оно одинаково что для фиксированной точки что для целочисленного типа, то, например, с умножением это не так и надо указывать необходимую опцию, что речь идет именно о целочисленных в данном случае опция «(i)»
Xr5=r6*r7(i);;
Аналогично когда мы хотим указать что операнды знаковые или без знаковые, операция проводится с насыщением или без и т.д…
Если мы хотим произвести умножение с накоплением, то для этого есть отдельная группа регистров MR4:0
MR1:0+= Rm * Rn 32-битное дробное умножение с накоплением;MR3:2-= Rm * Rn
Стоит отдельно отметить что в регистры J и K из регистров X и Y мы можем перекладывать значения без проблем. В обратную же сторону мы это можем делать только при помощи обращения к памяти, выглядит это следующим образом:
Xr0=[j0+0];;
К слову именно через квадратные скобки мы и обращаемся по адресу. Если мы хотим обратиться к каким-либо объявленным нами в памяти переменным, то делаем мы это следующим образом:
.SECTION /DOUBLE64 /CHAR32 .data; /* Data Section */ .align 4; .VAR cvar =90; .SECTION .program; .ALIGN_CODE 4; .GLOBAL _main; _main: [J31 + xvar]=xr8;;//кладем в переменную новое значение XR0 = [J31 + сvar];;//берем значение из переменной _main.end:
Если же мы объявили массив то нам будет удобно воспользоваться указателем
.SECTION /DOUBLE64 /CHAR32 .data; /* Data Section */ .align 4; .VAR cvar[] ={0,1,0,1,0,1,0}; .SECTION .program; .ALIGN_CODE 4; .GLOBAL _main; _main: j2=cvar;;//указатель на первый член массива xr0=[j2+0];; xr0=[j2+3];; _main.end:
Теперь деление. Ничего похожего на команду DIV в документации не присутствует. Если же мы скомпилируем вот такую программку на языке си:
int a,b,c; a=120; b=6; c=a/b;
То получим такие коды в асме:
J27 = J27 - 8 (nf);; K26 = J27;; [J27 + 15] = CJMP;; K0 = 0;; [J27 + 14] = K0;; K1 = 120;; [J27 + 13] = K1;; J0 = 6;; [J27 + 12] = J0;; J4 = [J27 + 13];; K1 = [J27 + 12];; J5 = K1;; [J27 + 10] = K0;; CALL __DIV32;; [J27 + 11] = J8;;
В регистре J8 будет лежать наш искомый результат – частное. Конечно каждый раз писать такую конструкцию неудобно, и стоит её оформить в виде функции.
// делимое передаем через K1 а делитель через j1 div32_f: [j0+=1]=cjmp;; [j0+=1]=j27;; [j0+=1]=k0;; [j0+=1]=k1;; [j0+=1]=j4;; [j0+=1]=j5;; [j0+=1]=j1;; J27 = J27 - 8 (nf);; K26 = J27;; [J27 + 15] = CJMP;; K0 = 0;; [J27 + 14] = K0;; [J27 + 13] = K1;; [J27 + 12] = J1;; J4 = [J27 + 13];; K1 = [J27 + 12];; J5 = K1;; [J27 + 10] = K0;; CALL __DIV32;; nop;nop;nop;; j0=j0-1;; j1=[j0 + 0];; j0=j0-1;; j5=[j0 + 0];; j0=j0-1;; j4=[j0 + 0];; j0=j0-1;; k1=[j0 + 0];; j0=j0-1;; k0=[j0 + 0];; j0=j0-1;; j27=[j0 + 0];; j0=j0-1;; cjmp=[j0 + 0];nop;nop;; cjmp;; div32_f.end:
Стоит отметить что деление целочисленное, следовательно результат округляется до целого, причем округление происходит просто отбрасыванием дробной части конечного результата. Также тут применен стек (точнее то что его заменяет), но об этом позже.
Арифметика с плавающей точкой
Касательно всего кроме деления те же операции, но теперь вместо, например, «xr0» пишем «xfr0».
Преобразование данных:
Для перехода из формата с плавающей точкой к целочисленному используется операция «Fix», обратно операция «float»
xr9=fix xfr3;; xfr6=float r6;;
Условные операторы
Касательно условных операторов. Есть операция сравнения «comp», которая портит флаги в статусном регистре. В зависимости от флагов, в свою очередь портятся предикаты соответствующего АЛУ. Ф уже предикаты мы можем использовать, например, в операторе «if» который в местном ассемблере тоже есть. Для понимания приведу отрывок из документации с описанием «comp» для АЛУ с фиксированной и плавающей точкой точкой X или Y. Приведу небольшую вырезку из документации.
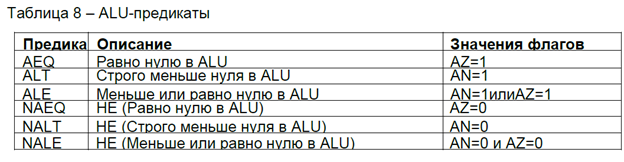
Сравнение
Синтаксис
{X|Y|XY}{S|В}COMP( Rm, Rn) {(U)} ;
{X|Y|XY}{L|S|В}COMP (Rnd, Rnd) {(U)} ;
Флаги состояния
AZ Установлен, если значения в Rm и Rn одинаковы;
AN Установлен, если значение в Rm меньше значения в Rn;
AV(AOS) Сброшен (не изменяется);
AC Сброшен.
Опции
( ) Знаковое
(U) Беззнаковое
Сравнение (плавающая арифметика)
Синтаксис
{X|Y|XY}FCOMP (Rm, Rn) ;
{X|Y|XY}FCOMP (Rmd, Rnd) ;
Флаги состояния
AZ Установлен, если Rm=Rn и ни один из Rm или Rn не NAN;
AUS Не сбрасывается;
AN Установлен, если Rm<Rn и ни один из Rm или Rn не NAN;
AV Сброшен;
AVS Не сбрасывается;
АС Сброшен;
AI Установлен, если какой-либо входной операнд есть NAN;
AIS Установлен, если какой-либо входной операнд есть NAN; иначе не сбрасывается.
В приведенном ниже коде показан пример сравнения
xcomp(r18,r17);;// if xaeq,jump mk;;// если значения одинаковы прыгаем на метку mk xr16=0;;//если значения не одинаковы xr9=0;;NOP; NOP; NOP;; jump collect;; mk: Xfr1=r1+r16;;//изменяем х на единицу call sin_func;NOP; NOP; NOP;;//переход по метке collect:
Реализация циклов
Для реализации циклов служат регистры LC1 и LC0. Представлю один из вариантов
xr5=lc1;;//назначаем количество циклов m: //тут делаем что хотели if NLC1E, jump m;NOP; NOP; NOP;;
Переход во внешнюю функцию. Стек
Для перехода в функцию есть встречающаяся почти в любом ассемблере команда «call», при этом адрес для возврата помещается в регистр «cjmp». В случае, когда мы заходим в какую-то функцию и никуда больше не прыгая, сделав все что надо возвращаемся обратно. Нам нет необходимости пользоваться стеком или чем-то что его частично заменит. Если же мы вызываем функцию, которая будет в свою очередь эксплуатировать другие вспомогательные функции то тут стоит учитывать что предыдущее значениеадреса возврата из «cjmp» может кануть в лету, если его не сохранить например просто в каком-то регистре или по адресу в памяти а в идеале в стеке, как обычно и делают, но тут с этим трудности. Дело в том что в данном процессоре отсутствует аппаратная реализация стека. Поэтому приходится как-то выкручиваться.
call lfm_func;NOP; NOP; NOP;; _main.end: lfm_func: yr3=cjmp;;//сохраняем адрес возврата в регистре алу call sin_func;NOP; NOP; NOP;; cjmp=yr3;;NOP; NOP; NOP;;//достаем адрес возврата cjmp;; lfm_func.end: sin_func: cjmp;; sin_func.end:
Выше приведен банальный пример где мы просто сохраняем адрес возврата из функции в регистре АЛУ. Этот способ мягко говоря не серьёзный и вообще делать так неприлично, ибо если мы внутри одной из вызываемых программ будем эксплуатировать данный регистр то все пропадет и дорогу назад мы забудем. Следовательно надо делать какую то структурку похожую на стек. Я предлагаю заранее создавать массив предназначенный для стека, допустим мест на 100 и один из регистров АЛУ J использовать там как указатель. Получаем соответственно что-то такое в начале каждой функции
//пушим в стек [j0+=1]=j3;; [j0+=1]=xr15;; [j0+=1]=xr10;; [j0+=1]=xr5;; [j0+=1]=xr2;; [j0+=1]=xr6;; [j0+=1]=xr3;;// [j0+=1]=cjmp;; [j0+=1]=lc0;;
И что-то такое в конце каждой функции
j0=j0-1;; lc0=[j0 + 0];; j0=j0-1;; cjmp=[j0 + 0];; j0=j0-1;; xr3=[j0 + 0];; j0=j0-1;; xr6=[j0 + 0];; j0=j0-1;; xr2=[j0 + 0];; j0=j0-1;; xr5=[j0 + 0];; j0=j0-1;; xr10=[j0 + 0];; j0=j0-1;; xr15=[j0 + 0];; j0=j0-1;; j3=[j0 + 0];;
Вывод данных из области памяти
Начать, наверное, стоит с того что производитель предоставляет множество разнообразных утилит и в том числе для работы с памятью как я подозреваю, но не очень разобрался. Потому было решено встать на путь изобретения своих велосипедов.
Представим ситуацию, когда нам нужно ввести записанный в память какой-то массив данных и визуализировать его или замерить некоторые параметры сигнала. Допустим, необходимые нам данные лежат в массиве «arr» на 8 мест. В режиме отладки нам доступна функция отображения переменных в памяти. В окошке «Variables» на нужном нам массиве щелкнем правой кнопкой мыши и выберем «View Memory».
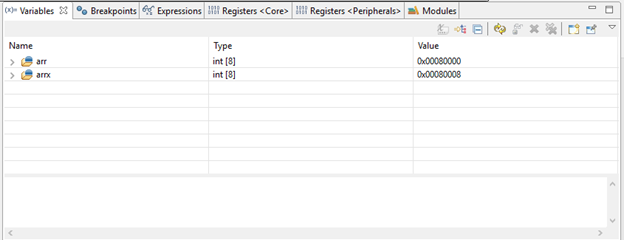
Откроется пространство ячеек памяти по соответствующим адресам. Адрес начала нашего массива будет подсвечен синим.
Чтоб экспортировать данные в файл выберем «Export».
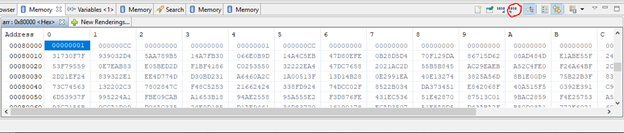
В открывшемся окне выбираем количество элементов, которые мы хотим вывести, начиная с указанного адреса и формат выведенных данных. А также адрес файла в который складируем наши значения.
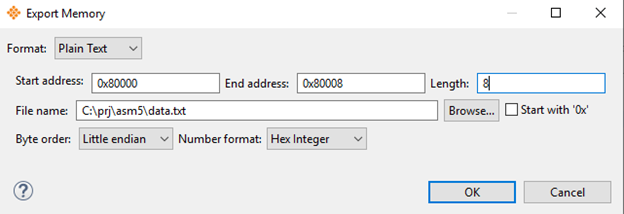
Далее возможны разные варианты событий. Мне показалось наиболее удобным хватать эти данные в последствии матлабом. На случай если кому то пригодится оставлю тут код выводящий содержимое на график.
close all; clear; T=readtable('data.txt'); F=table2array(T); f=hex2dec(F); t=1:length(f); figure; plot(t,f); grid on;
Не стоит забывать, что нам из памяти таким образом значения будут выведены только в шестнадцатеричном виде. Встроенная в Matlab функция hex2dec, к сожалению, работает только с без знаковыми целочисленными значениями. Следовательно, если вы будете выводить таким образом из памяти отрицательные, с фиксированной или с плавающей точкой значения то вы рискуете увидеть вместо графиков некоторый контент 18+.
Поэтому если возникает нужда выводить знаковые значения то надо дописать функцию которая переводит код из дополнительного кода в понятный матлабу, это связанно с тем что в матлабе мы не задаем какие то ограниченные размеры переменных ибо он у нас с динамической типизацией. Поможет вот такая функция.
function [ y ] = invert( x ) y1=dec2bin(x); for i=1:length(y1) if y1(i)=='1' y1(i)='0'; else y1(i)='1'; end; end; y=bin2dec(y1)+1; end
и соответственно основное тело изменится следующим образом
close all; clear; max=2147483647; T=readtable('data.txt'); F=table2array(T); f=hex2dec(F); for i=1:length(f) if (f(i)>max) f(i)=-invert(f(i)); end end t=1:length(f); figure; plot(t,f); grid on;
На этом дабы не перегружать статью, пожалуй закончу, и надеюсь продолжу в следующих письменах.

