C интересом прочитал статью о впечатляющих показателях процессора Эльбрус на алгоритме шифрования Кузнечик. В этой же статье приведена ссылка на проект с реализацией указанного алгоритма. Вот мне и захотелось посмотреть, как пойдет реализация этого алгоритма шифрования на сигнальном процессоре К1967ВН44(28) , с которым мне часто приходится работать.
Шаг за шагом
DSP серии К1967ВНхх имеют собственную среду разработки CM-LYNX , компилятор С и С++ на базе Clang. Этого набора достаточно чтобы попробовать сделать оценку производительности процессора на указанной выше реализации алгоритма . В архиве проекта два файла: в одном 8-битная версия алгоритма, а в другом 128-битная версия, т.е. вариант для процессоров поддерживающих операции со 128-разрядными числами.
Для полноты эксперимента, начинаю с 8-битной версии. После компиляции и запуска на отладочной плате К1967ВН44, при максимально возможном уровне оптимизации –О2, получаю результат
Self-test OK!
kuz_encrypt_block(): 54.804 kB/s (n=200kB,t=3.649s)
kuz_decrypt_block(): 52.435 kB/s (n=200kB,t=3.814s)
Программа информирует , что тест самопроверки прошел успешно , а затем производит замер скорости шифрования-дешифрования. По умолчанию, в инструментальном софте для платы К1967ВН44 используется определение частоты процессора 250 МГц. Для этой частоты и произведены вычисления.
Чтобы понять, что это за уровень скорости 54.804 kB/s, приведу аналогичный показатель последовательной обработки для процессора Эльбрус(8СВ) - 150 мегабайт в секунду на одном ядре. До Эльбруса нужно еще ускориться где-то в 3 000 раз.
Хотя 8-битовый вариант и не был для меня особо интересен, но я все же попробовал его немного улучшить. Для функции uint8_t kuz_mul_gf256(uint8_t x, uint8_t y) я сделал подстановку, создав заранее вычисленный массив результатов размером 64К байт. С новым вариантом получен результат
kuz_encrypt_block(): 161.728 kB/s (n=400kB,t=2.473s)
kuz_decrypt_block(): 185.177 kB/s (n=400kB,t=2.160s)
Замена оказала хорошее влияние на производительность. Ускорение более чем в 3 раза, но нужно еще в 1000 раз.
Перехожу к 128-разрядному варианту алгоритма. ВН44 имеет возможность в одном такте выполнять загрузку либо сохранение 128-разрядного операнда (даже двух), выполнять логические и арифметические операции над числами меньшей разрядности, упакованными в 128-разрядные вектора.
Создаю новый проект и копирую в него 128-разрядную версию алгоритма шифрования. Исходный проект отлаживался на архитектуре х86, поэтому я заменяю тип данных __m128i , просто добавив в проект переопределение
#define __m128i __builtin_quad
Все замечательно компилируется. Запускаю проект на исполнение, вначале без оптимизации, а затем с оптимизацией О2 , и получаю результат
kuz_encrypt_block(): 1027.337 kB/s (n=3200kB,t=3.115s)
kuz_decrypt_block(): 999.474 kB/s (n=3200kB,t=3.202s)
Изменение подхода в реализации алгоритма дало куда большее ускорение, чем моя попытка заменить функцию таблицей. Наконец-то подобрались к величине скорости, когда считать уже можно в мегабайтах :)
Если на 8-битной реализации переход в оптимизации от –О0 к –О2 дал ускорение в 11 раз, то на 128-разрядном варианте была получена всего 30% прибавка. Объяснение данного феномена я нахожу только в том, что работа с 128-разрядными данными в компиляторе СМ-LYNX очень слабо оптимизируется. Получается, что дальнейшее ускорение невозможно без использования ассемблера.
Удобство 128-разрядной реализации Кузнечика базового проекта в том, что функции кодирования и декодирования очень просты в Си-реализации. Это позволяет очень быстро сделать их ассемблерные варианты. Добавляю в проект опцию, которая меняет вызов Си - функций на их ассемблерные эквиваленты и получаю новые результаты
kuz_encrypt_block(): 14679.652 kB/s (n=51200kB,t=3.488s)
kuz_decrypt_block(): 13535.172 kB/s (n=51200kB,t=3.783s)
Ассемблерная реализация дала ускорение в 14 раз. Учитывая, что я достаточно ответственно отнесся к ассемблерной версии, можно сказать, что это уже практически итоговый результат.
Несколько слов
об архитектуре процессора и деталях ассемблерного варианта на примере реализации процесса шифрования .
Процессор ВН44 имеет VLIW архитектуру и может выполнять в одном такте до 4-х инструкций. Обработка 128-разрядных данных в процессоре может выполняться в модулях Х и Y (смотрите рисунок ниже), которые могут работать как независимо (каждый под управлением собственных команд), так и синхронно (под управлением общих команд).
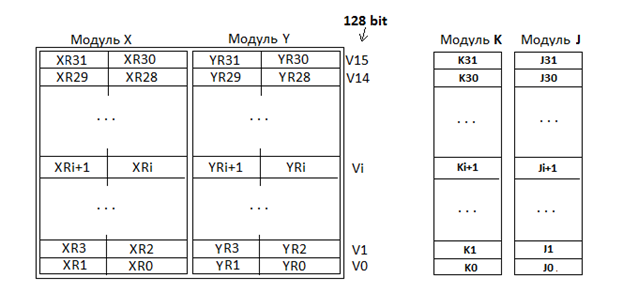
Если, например, у Эльбруса информация находится в одном большом наборе регистров, то у ВН44 каждый модуль обработки имеет индивидуальный набор регистров 32х32 бита. Для данного алгоритма модуль SIMD обработки можно рассматривать как два 64-разрядных модуля (X+Y) которые могут управляться одной общей командой. Именно спарка этих двух модулей и единая команда управления, позволяют рассматривать их как единый 128-разрядный модуль обработки.
Реализацию функции void kuz_encrypt_block(kuz_key_t *key, void *blk) на Си можно посмотреть в выше упомянутом проекте. Это всего лишь цикл, повторяющийся 9 раз, в котором выполняется операция исключающего ИЛИ для 16-ти 128-разрядных значений. Проблема только в том, что каждый новый виток цикла требует вычисления индексов этих 128-разрядных операндов на основании результата предыдущего витка. Возможно, реализация этой функции шифрования на ассемблере будет и сложна для человека не знакомого с К1967ВН44, но я все же приведу её здесь.
.global __ASM_FUN(kuz_encrypt_block_asm); // j4 = kuz_key_t *key, j5 = void *blk j6= kuz_pil_enc128 j7= offset __ASM_FUN(kuz_encrypt_block_asm): V0 = Q[j5+0]; lc0 = 9;; // get block V1 = Q[j4+=4];; // get first key YV7x6 = Q[j7+0]; k6 = j6;; XV7x6 = Q[j7+4];; // Q – 128bit load // loop is here next_velp: //+1 пузырь LV0 = V0 xor V1 ;; // L- 64-bit elements j12 = yr0; k12 = xr0;; SV3x2 = expand BV0 (IU);; // S – 16-bit elements V8 = Q[j4+=4];; // next key SV2 = lshift V2 by 2;; SV3 = lshift V3 by 2; j12 = lshiftl j12 by 24; k12 = lshiftl k12 by 24;; V5x4 = expand SV2 + SV6 (IU); j12 = lshiftr j12 by 22; k12 = lshiftr k12 by 22;; V3x2 = expand SV3 + SV7 (IU); j3:0 = YV5x4; k3:0 = XV5x4;; j11:8 = YV3x2; k11:8 = XV3x2;; V0 = Q[j12+j6]; k12 = k12+0x2000;; // 0x2000 is half=256*4*8 V1 = Q[k12+k6];; V2 = Q[j1+j6]; LV0 = V0 xor V8;; V3 = Q[k1+k6];; LV0 = V0 xor V2 ; V2 = Q[j2+j6];; LV1 = V1 xor V3 ; V3 = Q[k2+k6];; LV0 = V0 xor V2 ; V2 = Q[j3+j6];; LV1 = V1 xor V3 ; V3 = Q[k3+k6];; LV0 = V0 xor V2 ; V2 = Q[j8+j6];; LV1 = V1 xor V3 ; V3 = Q[k8+k6];; LV0 = V0 xor V2 ; V2 = Q[j9+j6];; LV1 = V1 xor V3 ; V3 = Q[k9+k6];; LV0 = V0 xor V2 ; V2 = Q[j10+j6];; LV1 = V1 xor V3 ; V3 = Q[k10+k6];; LV0 = V0 xor V2 ; V2 = Q[j11+j6];; LV1 = V1 xor V3 ; V3 = Q[k11+k6];; LV0 = V0 xor V2 ;; if nlc0e, jump next_velp; LV1 = V1 xor V3;; // repeat 9 //+1 пузырь LV0 = V0 xor V1;; cjmp(abs); Q[j5+0] = V0;; // store 128-bit and return
Если у Эльбруса широкое слово ограничивается скобками {}, то у ВН44 это ;; Регистры J и K это регистры модулей адресной арифметики. V3x2 это уже 256-разрядный регистр, как объединение двух 128-разрядных.
Одна итерация цикла занимает 28 тактов. На обработку 16 байт данных тратится (28*9) + 7 = 259 тактов. Получается, что процессор тратит на шифрование одного байта входных данных в среднем 17 тактов. Из 28 тактов цикла 16 тактов уходит на операцию XOR. Поскольку процессор в одном такте может выполнять только одну такую операцию , то как-то еще ускорить этот тип вычислений просто невозможно. Единственный вариант ускорения это поиск других операций цикла, которые могут быть выполнены одновременно с выполнением операции XOR. Однако доступной операцией в данном случае является только операция загрузки данных. Процессор может выполнять в течение одного такта и две загрузки 128-разрядных данных, но в данном случае это не позволит ускорить алгоритм из-за узкого места в единственном 128-разрядном АЛУ.
11 тактов цикла тратится на подготовку индексов операндов массива данных. В данном случае используется команда SIMD обработки и 16 байт результата сначала преобразуются в 16 значений типа short. Далее эти 16-разрядные значения сдвигаются влево на два разряда для формирования индекса квадрослова. Следующим этапом является операция сложения вектора индексов с заранее подготовленным вектором смещений. Одновременно со сложением происходит расширение индекса до 32-разрядного значения. Далее индексы пересылаются в модули адресной арифметики, где уже используются для адресации данных следующего цикла.
Что в итоге
Увы, достигнуть вершины Эльбруса пока не получилось. Но мне достигнутый результат понравился. Скорость обработки 17 тактов на байт очень хороший показатель. Алгоритм как раз задействовал лучшие возможности процессора – 128 разрядные шины обмена с памятью и 128-разрядную обработку данных в АЛУ. Также алгоритм показал и слабое место в архитектуре процессора, когда, при наличии двух конвейеров 128-разрядной обработки, определенный тип команд может присутствовать только на одном конвейере.
Подробная информация о DSP процессоре, который я использовал, приведена здесь. С исходными кодами проекта, адаптированными под К1967ВН44, можно ознакомиться здесь .

