Лет 6 назад я задавался вопросом "Как правильно организовать распределенное проектирование БД?" Тогда ответа на свой вопрос я так и не получил, но за прошедшее с тех пор время я встретился с вариантом, наиболее близко подобравшимся к моему видению "прекрасного" — это декларативная схема описания данных в Magento 2.
Мне нравится философия таких программных систем, как Magento, Odoo, WordPress, Drupal — базовый функционал, расширяемый за счёт сторонних плагинов. Она значительно отличается от философии FAANG. Философия FAANG направлена на построение уникальных высокопроизводительных решений, а философия WordPress — на адаптируемость к требованиям бизнеса. Каждый из этих подходов имеет свои плюсы и минусы, но мне ближе второй и рассматривать вопрос, вынесенный в заголовок публикации, я буду именно в рамках WordPress-подхода (WP-подхода).
Я не предлагаю решение, я просто размышляю вслух на обозначенную в заголовке тему.
Особенности WP-подхода
WP-подход подразумевает, что:
- данные приложения, как правило, находятся в единой базе данных;
- различные приложения могут использовать различные СУБД из набора доступных для соответствующей платформы (например, MariaDB/MySQL/PostgreSQL/Oracle/MSSQL/...);
- структура данных этой единой базы собирается из фрагментов, соответствующих компонентам приложения (ядра платформы и используемые плагины);
- набор плагинов может меняться за время жизни приложения;
- структура данных фрагмента (плагина) может меняться за время жизни приложения;
Таким образом, WP-подход требует наличия инструмента, который бы помогал поддерживать целостность структуры единой БД при установке/удалении/обновлении плагинов. А это значит, что формат описания структур данных должен быть лоялен к программной обработке.
Текущее положение
SQL
Стандартным форматом для описания структур данных является декларативный SQL. Это проверенный временем язык и он успешно справляется с описанием структуры данных. Тем не менее, платформы, исповедующие WP-подход, не используют SQL напрямую, а предпочитают взаимодействовать с БД через слой ORM/DBAL-инструментов.
ORM/DBAL
Инструменты типа Hibernate, Doctrine, Sequelize, Knex добавляют в приложение слой, абстрагирующий приложение от типа используемой им СУБД. Каждый инструмент предоставляет свой способ описания схемы данных и манипуляции данными, как правило на соответствующем языке программирования (Java, PHP, JS/TS). Приоритет имеют способы манипуляции данными, т.к. приложения чаще выбирают/изменяют данные в базе, чем меняют её структуру.
Исследовать схему данных, созданную такими инструментами, ещё менее удобно, чем исследовать аналогичную схему данных, созданную при помощи SQL-файлов.
Декларативный подход в Magento 2
В Magento 2 добавили ещё один слой абстрагирования при работе с данными — декларативную схему. Вместо того, чтобы описывать схему данных на PHP при помощи DBAL-инструментов платформы, разработчик описывает схему данных в XML-формате, который платформа способна разобрать и превратить в последовательность PHP-инструкций по созданию/изменению схемы.
Каждый magento-плагин содержит файл ./etc/db_schema.xml, в котором зафиксирована схема данных, используемая данным плагином. Платформа способна собрать все описания для всех плагинов приложения и скомпоновать из фрагментов единую схему данных и проверить её на непротиворечивость. Затем на основании загруженной схемы данных возможно изменение действующей схемы данных.
Минусы реализации:
- Magento 2 работает с СУБД MySQL/MariaDB и декларативная схема очень сильно привязана к этому типу БД;
- XML является форматом, очень удобным для программной обработки, но "тяжёлым" для человека;
- в единой схеме данных отсутствуют средства группировки таблиц, что существенно для баз данных с количеством таблиц в несколько сотен;
"Идеальный формат"
Отталкиваясь от декларативного описания схемы данных Magento 2, я попробую сформулировать правила, которым должен соответствовать улучшенный формат описания (в рамках моего понимания WP-подхода).
Группировка таблиц
В базах на несколько сотен таблиц зачастую применяется подход, когда имена таблиц прописываются в формате snake_case:

Расположение таблиц в группах ("папках") и вложение групп в другие группы делают навигацию по совокупности всех таблиц более удобным:
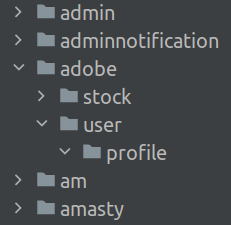
Независимость от ORM/DBAL
ORM/DBAL-инструменты дают приложению независимость от используемой СУБД. Я считаю, что "идеальный формат" должен давать независимость от ORM/DBAL-инструментов и быть ещё более абстрактным, фокусируясь на структуре данных. Технически возможно использование одной базы данных приложениями, написанными на разных ЯП и применяющих различный ORM/DBAL-инструментарий для работы с данными. Т.е., "идеальный формат" превращается в ещё один уровень абстрагирования способа описания структуры данных от способа создания:

Уменьшение вариативности
Базы данных "заточены" на оптимизацию хранения данных и обладают множеством типов для описания данных. В то же самое время JSON, который зачастую используется для передачи выбранных данных между клиентом и сервером в web-приложениях, обладает всего шестью типами данных. Если на уровне БД есть разница между CHAR, VARCHAR, TEXT, то на уровне приложения эта разница уже гораздо меньше, а для пользователя приложения они все и вовсе укладываются в один тип — текст.
Типы данных в "идеальном формате" должны быть ближе к пользователю, чем к БД.
База — для данных
Я являюсь сторонником того, что база данных должна лишь хранить данные и давать к ним доступ. Бизнес-логика (триггеры и процедуры-функции) на стороне БД — зло. Для высокопроизводительных приложений это зачастую не так, но для приложений, которые собираются из плагинов, созданных сторонними разрабами, "размазанность" бизнес-логики по слою данных и кода затрудняет их построение. Таким образом, "идеальный формат" должен описывать лишь структуру данных — таблицы, индексы и отношения (foreign keys). Некоторые относят уникальные индексы и foreign keys к бизнес-логике, но я не придерживаюсь такой точки зрения.
JSON
"Идеальный формат" для описания схемы должен быть дружелюбен к программному анализу. На данный момент я знаю три таких формата: XML, JSON, YAML. Компромиссным вариантом между удобством использования формата программой и человеком я считаю JSON — XML слишком "многословен" и тяжёл для понимания человеком, а в YAML слишком легко допустить ошибку при редактировании больших файлов с использованием техники "copy-paste".
Резюме
"Идеальный формат" для описания схемы данных в RDBMS должен:
- использовать JSON (как вариант — со взаимным преобразованием в XML/YAML);
- фокусироваться на "статике" (структуре данных и взаимоотношениях между ними) и игнорировать "динамику" (бизнес-логику);
- абстрагироваться не только от типа СУБД, но и от используемого ORM/DBAL;
Потенциальные бонусы от использования "идеального формата":
- упрощение программного анализа схемы данных (по отношению к SQL) — выстраивание последовательности удаления/создания таблиц, анализ целостности и непротиворечивости, сравнение различных схем данных (или различных версий одной схемы);
- упрощение распределённой разработки приложения за счёт формирования единой схемы данных из отдельных фрагментов (с возможной взаимозаменяемостью в приложении плагинов, близких по функционалу);
- облегчение восприятия схемы данных разработчиками за счёт дополнительного абстрагирования от ORM/DBAL (уменьшения детализации);
Я пока ещё не встретился с "идеальным форматом", но, возможно, я просто плохо его искал. Коллеги имеют возможность ткнуть в него пальцем в комментариях. Буду благодарен.

