
В прошлый раз я рассказал об этапах выполнения запросов. Прежде чем переходить к тому, как работают различные узлы плана (способы доступа к данным и методы соединения), надо разобраться с той основой, на которую опирается стоимостной оптимизатор — со статистикой.
Как обычно, я буду приводить примеры из демобазы. В этой статье будет довольно много планов выполнения, но про их составные части я буду рассказывать только в следующих статьях. Здесь же нас в первую очередь будут интересовать оценки количества строк (кардинальности), то есть числа, указанные в верхней строке плана в позиции rows.
Базовая статистика
Базовая статистика уровня отношения хранится в системном каталоге в таблице pg_class. К ней относятся:
число строк в отношении (
reltuples);размер отношения в страницах (
relpages);количество страниц, отмеченных в карте видимости (
relallvisible).
SELECT reltuples, relpages, relallvisible FROM pg_class WHERE relname = 'flights';
reltuples | relpages | relallvisible −−−−−−−−−−−+−−−−−−−−−−+−−−−−−−−−−−−−−− 214867 | 2624 | 2624 (1 row)
Значение reltuples используется в качестве оценки кардинальности, когда запрос не содержит никаких условий на таблицу:
EXPLAIN SELECT * FROM flights;
QUERY PLAN −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− Seq Scan on flights (cost=0.00..4772.67 rows=214867 width=63) (1 row)
Статистика собирается при анализе, ручном или автоматическом. Но, ввиду особой важности, базовая статистика рассчитывается также при выполнении некоторых операций (VACUUM FULL и CLUSTER, CREATE INDEX и REINDEX), и уточняется при очистке.
Для анализа случайно выбираются 300 × default_statistics_target строк (при значении параметра по умолчанию 100 получается 30000). Поскольку размер выборки, достаточной для построения статистики заданной точности, слабо зависит от объема анализируемых данных, размер таблицы не учитывается.
Строки выбираются из такого же количества (300 × default_statistics_target) случайных страниц. Конечно, для небольшой таблицы количество прочитанных страниц и выбранных для анализа строк может оказаться меньше.
Поскольку в достаточно больших таблицах статистика собирается не по всем строкам, оценки могут немного расходиться с реальностью. Это нормально: статистика в любом случае не может все время быть точной, если данные изменяются. Для выбора адекватного плана обычно достаточно попадания в порядок.
Создадим копию таблицы flights с отключенной автоочисткой, чтобы управлять временем выполнения анализа:
CREATE TABLE flights_copy(LIKE flights) WITH (autovacuum_enabled = false);
Для новой таблицы еще нет никакой статистики:
SELECT reltuples, relpages, relallvisible FROM pg_class WHERE relname = 'flights_copy';
reltuples | relpages | relallvisible −−−−−−−−−−−+−−−−−−−−−−+−−−−−−−−−−−−−−− −1 | 0 | 0 (1 row)
Значение reltuples = −1 (появившееся в версии PostgreSQL 14) позволяет отличить таблицу, для которой статистика ни разу не собиралась, от действительно пустой таблицы без строк.
Но с большой вероятностью в таблицу будут добавлены какие-то строки сразу после создания. Поэтому, находясь в неведении, планировщик считает, что таблица занимает 10 страниц:
EXPLAIN SELECT * FROM flights_copy;
QUERY PLAN −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− Seq Scan on flights_copy (cost=0.00..14.10 rows=410 width=170) (1 row)
Количество строк (rows) рассчитывается исходя из размера одной строки; он отображается в плане запроса как width. Обычно для оценки используется среднее значение, вычисляемое при анализе, но в данном случае, поскольку статистика отсутствует, размер строки вычисляется приблизительно с учетом типов данных столбцов.
Теперь скопируем данные из таблицы flights и выполним анализ:
INSERT INTO flights_copy SELECT * FROM flights;
INSERT 0 214867
ANALYZE flights_copy;
Сейчас статистика совпадает с реальным количеством строк (размер таблицы таков, что статистика собирается по полным данным):
SELECT reltuples, relpages, relallvisible FROM pg_class WHERE relname = 'flights_copy';
reltuples | relpages | relallvisible −−−−−−−−−−−+−−−−−−−−−−+−−−−−−−−−−−−−−− 214867 | 2624 | 0 (1 row)
Значение relallvisible обновляется при очистке:
VACUUM flights_copy; SELECT relallvisible FROM pg_class WHERE relname = 'flights_copy';
relallvisible −−−−−−−−−−−−−−− 2624 (1 row)
Оно используется при оценке стоимости сканирования только индекса.
Теперь удвоим количество строк, не собирая статистику, и проверим оценку кардинальности в плане запроса:
INSERT INTO flights_copy SELECT * FROM flights; SELECT count(*) FROM flights_copy;
count −−−−−−−− 429734 (1 row)
EXPLAIN SELECT * FROM flights_copy;
QUERY PLAN −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−���−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− Seq Scan on flights_copy (cost=0.00..9545.34 rows=429734 width=63) (1 row)
Оценка оказалась точна, несмотря на устаревшие сведения в pg_class:
SELECT reltuples, relpages FROM pg_class WHERE relname = 'flights_copy';
reltuples | relpages −−−−−−−−−−−+−−−−−−−−−− 214867 | 2624 (1 row)
Дело в том, что планировщик повышает точность оценки, масштабируя значение reltuples в соответствии с отклонением реального размера файла данных от значения relpages. Поскольку размер файла вырос в два раза по сравнению с relpages, количество строк корректируется в предположении, что плотность данных не изменилась:
SELECT reltuples * (pg_relation_size('flights_copy') / 8192) / relpages FROM pg_class WHERE relname = 'flights_copy';
?column? −−−−−−−−−− 429734 (1 row)
Конечно, такая корректировка работает не всегда (например, если удалить часть строк, то оценка не изменится), но в ряде случаев позволяет «продержаться» до прихода анализа при крупных изменениях.
Неопределенные значения
Неопределенные значения, порицаемые теоретиками (см., например, http://citforum.ru/database/articles/evergreen_nulls/), играют тем не менее важную роль в реляционных базах данных как удобный способ представления того факта, что значение не существует или не известно.
Но особое значение требует и особого к себе отношения. Помимо теоретических неувязок возникает множество сугубо практических сложностей, с которыми приходится считаться. Обычная булева логика превращается в трехзначную, а конструкция NOT IN ведет себя неожиданно. Непонятно, должны ли неопределенные значения считаться меньше обычных значений или больше (отсюда специальные предложения NULLS FIRST и NULLS LAST для сортировки). Не так уж очевидно, должны ли неопределенные значения учитываться в агрегатных функциях. Поскольку, строго говоря, неопределенные значения вовсе не являются значениями, то для их учета планировщику необходима дополнительная информация.
Помимо самой простой, базовой статистики на уровне отношений, при анализе собирается статистика для каждого столбца отношения. Она хранится в таблице системного каталога pg_statistic, но значительно проще пользоваться представлением pg_stats, которое показывает информацию в более удобном виде.
Доля неопределенных значений относится к такой статистике уровня столбца; вычисленное при анализе значение показывает атрибут null_frac. Например, поскольку часть рейсов еще не отправились, время вылета для них не определено:
EXPLAIN SELECT * FROM flights WHERE actual_departure IS NULL;
QUERY PLAN −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− Seq Scan on flights (cost=0.00..4772.67 rows=16036 width=63) Filter: (actual_departure IS NULL) (2 rows)
Оценка оптимизатора получена как общее число строк, умноженное на долю NULL:
SELECT round(reltuples * s.null_frac) AS rows FROM pg_class JOIN pg_stats s ON s.tablename = relname WHERE s.tablename = 'flights' AND s.attname = 'actual_departure';
rows −−−−−−− 16036 (1 row)
Точное значение — 16348.
Уникальные значения
Поле n_distinct представления pg_stats показывает количество уникальных значений в столбце.
Если значение n_distinct отрицательно, то модуль этого числа показывает не количество, а долю уникальных значений. Например, −1 означает, что все значения в столбце уникальны. Анализатор использует доли, когда вычисленное при анализе количество уникальных значений превышает 10 % от общего количества строк; в этом случае пропорция скорее всего сохранится при дальнейшем изменении данных.
Если количество уникальных значений вычисляется неверно (из-за ограниченности выборки, по которой проводится анализ), это количество можно явно указать для столбца командой
ALTER TABLE ... ALTER COLUMN ... SET (n_distinct = ...);
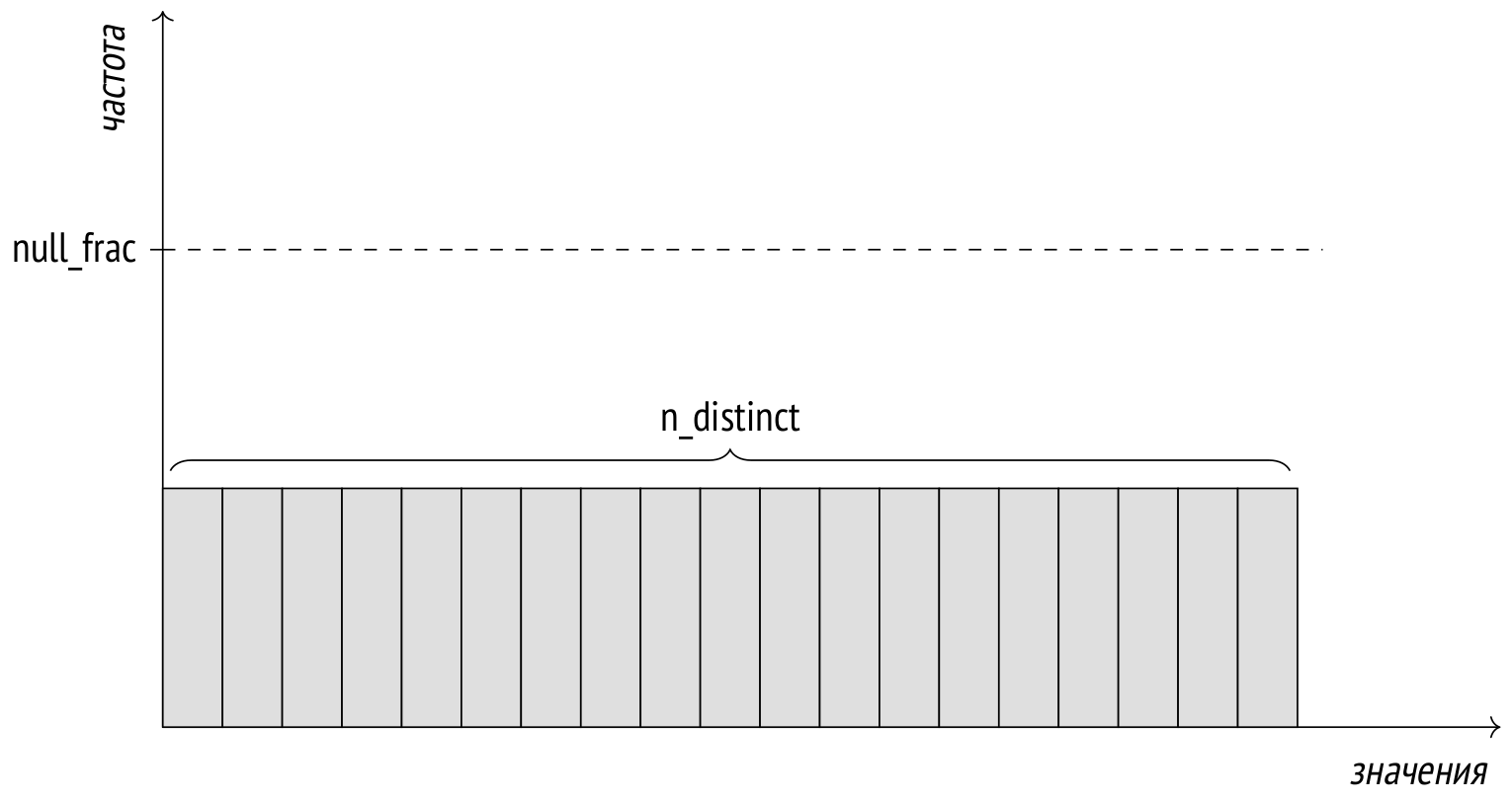
Количество уникальных значений используется во всех случаях, которые предполагают равномерное распределение данных. Например, при оценке кардинальности условия «столбец = выражение», когда значение выражения неизвестно на этапе планирования, считается, что выражение может принимать любое из возможных значений столбца с равной вероятностью:
EXPLAIN SELECT * FROM flights WHERE departure_airport = ( SELECT airport_code FROM airports WHERE city = 'Санкт-Петербург' );
QUERY PLAN −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− Seq Scan on flights (cost=30.56..5340.40 rows=2066 width=63) Filter: (departure_airport = $0) InitPlan 1 (returns $0) −> Seq Scan on airports_data ml (cost=0.00..30.56 rows=1 wi... Filter: ((city −>> lang()) = 'Санкт−Петербург'::text) (5 rows)
Здесь узел плана InitPlan выполняется один раз, и вычисленное значение используется в основном плане (на месте $0).
SELECT round(reltuples / s.n_distinct) AS rows FROM pg_class JOIN pg_stats s ON s.tablename = relname WHERE s.tablename = 'flights' AND s.attname = 'departure_airport';
rows −−−−−− 2066 (1 row)
Если бы все данные были всегда распределены равномерно, этой информации (дополненной еще минимальным и максимальным значениями) было бы достаточно. Но при неравномерном распределении, которое на практике встречается гораздо чаще, такая оценка не будет точна:
SELECT min(cnt), round(avg(cnt)) avg, max(cnt) FROM ( SELECT departure_airport, count(*) cnt FROM flights GROUP BY departure_airport ) t;
min | avg | max −−−−−+−−−−−−+−−−−−−− 113 | 2066 | 20875 (1 row)
Наиболее частые значения
Для уточнения оценки при неравномерном распределении собирается статистика по наиболее часто встречающимся значениям (most common values, MCV) и частоте их появления. Представление pg_stats показывает два этих массива в столбцах most_common_vals и most_common_freqs.
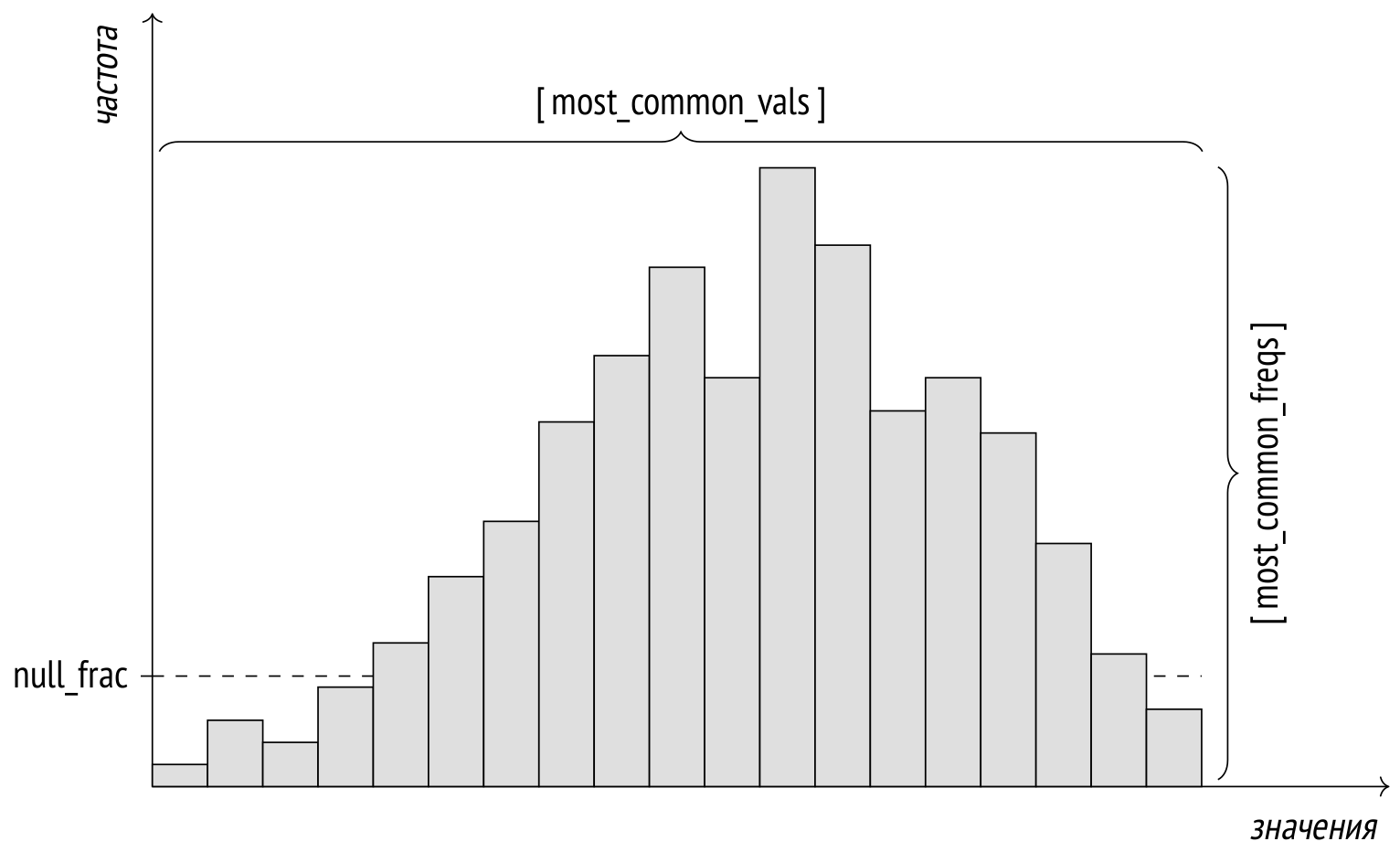
Вот пример такой статистики по частоте использования различных типов самолетов:
SELECT most_common_vals AS mcv, left(most_common_freqs::text,60) || '...' AS mcf FROM pg_stats WHERE tablename = 'flights' AND attname = 'aircraft_code' \ gx
−[ RECORD 1 ]−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− mcv | {CN1,CR2,SU9,321,763,733,319,773} mcf | {0.2783,0.27473333,0.25816667,0.059233334,0.038533334,0.0370...
Для оценки селективности условия «столбец = значение» достаточно найти значение в массиве most_common_vals и взять частоту из элемента массива most_common_freqs с тем же номером:
EXPLAIN SELECT * FROM flights WHERE aircraft_code = '733';
QUERY PLAN −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− Seq Scan on flights (cost=0.00..5309.84 rows=7957 width=63) Filter: (aircraft_code = '733'::bpchar) (2 rows)
SELECT round(reltuples * s.most_common_freqs[ array_position((s.most_common_vals::text::text[]),'733') ]) FROM pg_class JOIN pg_stats s ON s.tablename = relname WHERE s.tablename = 'flights' AND s.attname = 'aircraft_code';
round −−−−−−− 7957 (1 row)
Такая оценка, очевидно, будет близка к точному значению 8263.
Список частых значений используется и для оценки селективности условий с неравенствами. Например, для условия вида «столбец < значение» надо найти в most_common_vals все значения, меньшие искомого, и просуммировать частоты из most_common_freqs.
Статистика частых значений отлично работает, когда количество различных значений не очень велико. Максимальный размер массивов определяется тем же параметром default_statistics_target, который ограничивает размер случайной выборки строк для анализа.
В некоторых случаях может иметь смысл увеличить значение параметра по умолчанию, чтобы расширить список частых значений и повысить точность оценок. Это можно сделать на уровне отдельного столбца командой
ALTER TABLE ... ALTER COLUMN ... SET STATISTICS ...;
При этом увеличится и размер выборки, но только для указанной таблицы.
Поскольку в массиве частых значений сохраняются сами значения, массив может занимать довольно много места. Чтобы не увеличивать чрезмерно pg_statistic и не нагружать планировщик бесполезной работой, из анализа и статистики исключаются значения, размер которых превышает 1 Кбайт. К тому же такие большие значения, скорее всего, уникальны и поэтому все равно не должны попасть в most_common_vals.
Гистограмма
Когда число различных значений слишком велико, чтобы записать их в массив, на помощь приходит гистограмма. Гистограмма состоит из нескольких корзин, в которые помещаются значения. Количество корзин ограничено все тем же параметром default_statistics_target.
Ширина корзин выбирается так, чтобы в каждую попало примерно одинаковое количество значений (на рисунке это выражается в одинаковой площади прямоугольников). При этом учитываются только те значения, которые не попали в список наиболее частых.
При таком построении достаточно хранить только массив крайних значений каждой корзины — поле histogram_bounds представления pg_stats. Суммарная частота значений одной (любой) корзины равна 1 / число корзин.
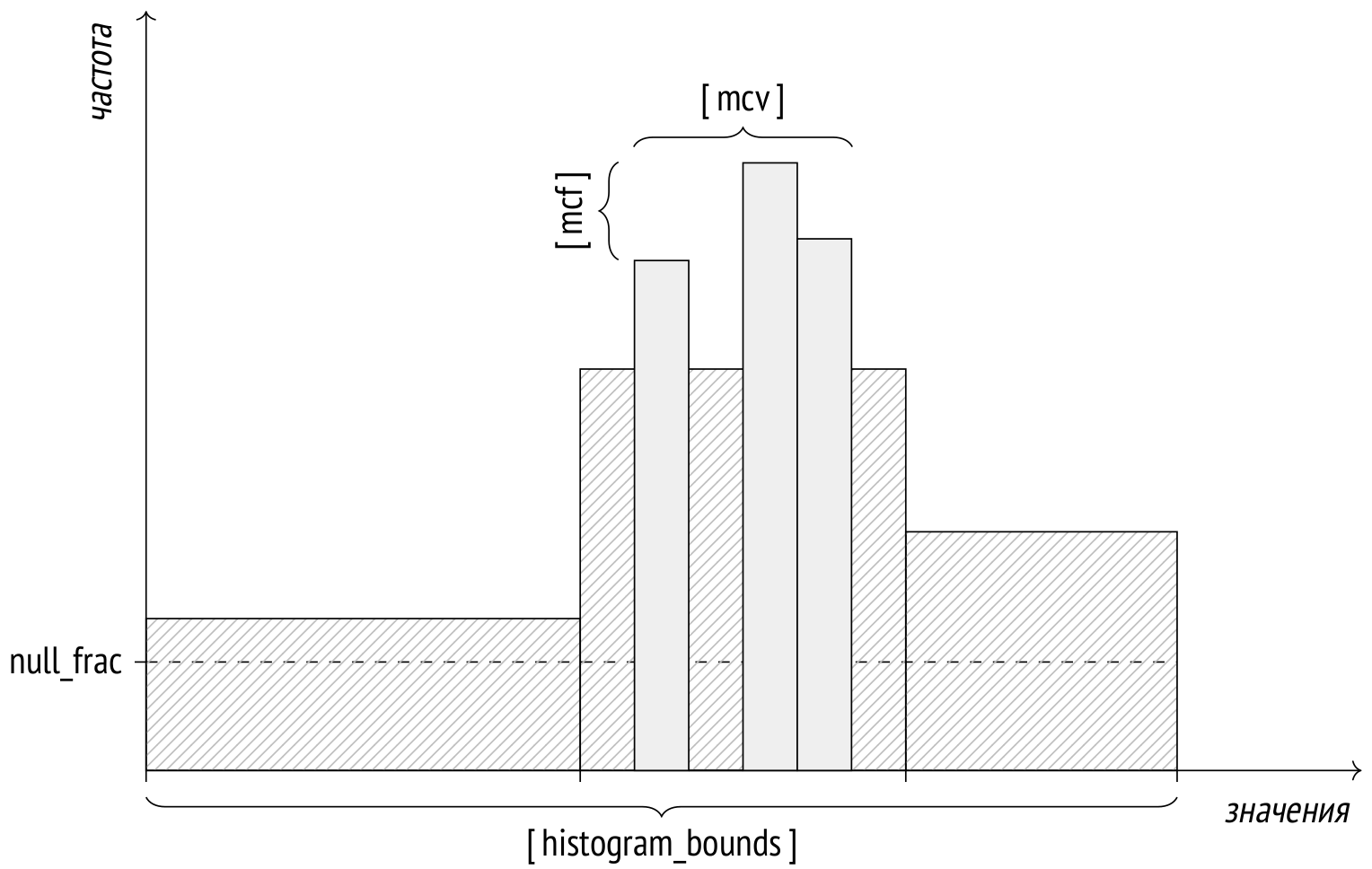
Гистограмма хранится как массив значений, ограничивающих корзины:
SELECT left(histogram_bounds::text,60) || '...' AS histogram_bounds FROM pg_stats s WHERE s.tablename = 'boarding_passes' AND s.attname = 'seat_no';
histogram_bounds −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− {10B,10D,10D,10F,11B,11C,11H,12H,13B,14B,14H,15H,16D,16D,16H... (1 row)
Гистограмма используется, в частности, для оценки селективности операций «больше» или «меньше» вместе со списком наиболее частых значений.
Рассмотрим пример — количество посадочных талонов, выданных на дальние ряды:
EXPLAIN SELECT * FROM boarding_passes WHERE seat_no > '30C';
QUERY PLAN −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− Seq Scan on boarding_passes (cost=0.00..157353.30 rows=2943394 ... Filter: ((seat_no)::text > '30C'::text) (2 rows)
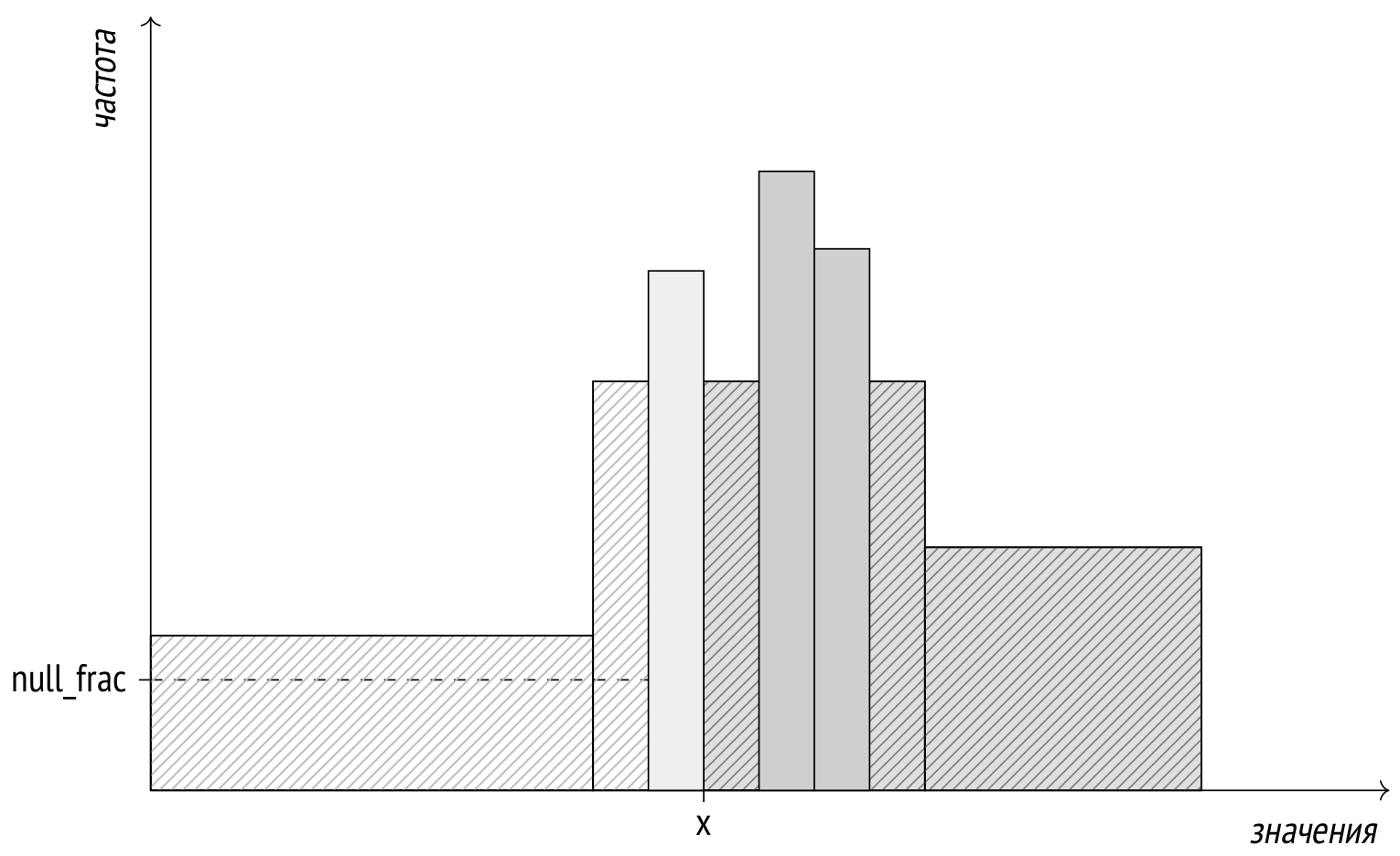
Номер места специально выбран так, что он лежит точно на границе корзин гистограммы.
Оценка селективности такого условия будет равна N / число корзин, где N — количество корзин, значения в которых удовлетворяют условию (то есть находящихся справа от значения). При этом необходимо учесть, что гистограмма не покрывает значения из списка наиболее частых и неопределенные значения.
Сначала найдем долю наиболее частых значения, удовлетворяющих условию:
SELECT sum(s.most_common_freqs[ array_position((s.most_common_vals::text::text[]),v) ]) FROM pg_stats s, unnest(s.most_common_vals::text::text[]) v WHERE s.tablename = 'boarding_passes' AND s.attname = 'seat_no' AND v > '30C';
sum −−−−−−−− 0.2127 (1 row)
Общая доля наиболее частых значений (не учитываемая гистограммой) составляет:
SELECT sum(s.most_common_freqs[ array_position((s.most_common_vals::text::text[]),v) ]) FROM pg_stats s, unnest(s.most_common_vals::text::text[]) v WHERE s.tablename = 'boarding_passes' AND s.attname = 'seat_no';
sum −−−−−−−− 0.6762 (1 row)
Неопределенных значений в столбце seat_no нет:
SELECT s.null_frac FROM pg_stats s WHERE s.tablename = 'boarding_passes' AND s.attname = 'seat_no';
null_frac −−−−−−−−−−− 0 (1 row)
Поскольку интервал занимает ровное количество корзин гистограммы (из 100 возможных), получаем следующую оценку:
SELECT round( reltuples * ( 0.2127 -- вклад частых значений + (1 - 0.6762 - 0) * (49 / 100.0) -- вклад гистограммы )) FROM pg_class WHERE relname = 'boarding_passes';
round −−−−−−−−− 2943394 (1 row)
Точное значение составляет 2986429.
В общем случае, когда значение лежит не на границе, с помощью линейной интерполяции учитывается доля корзины, в которой находится значение.
Увеличение параметра default_statistics_target может улучшить оценку, однако, как показывает пример, в сочетании со списком наиболее частых значений гистограмма обычно дает хороший результат даже при большом количестве уникальных значений в столбце:
SELECT n_distinct FROM pg_stats WHERE tablename = 'boarding_passes' AND attname = 'seat_no';
n_distinct −−−−−−−−−−−− 461 (1 row)
Увеличение точности оценки имеет смысл только в том случае, когда оно приводит к построению более качественного плана. Бездумное увеличение параметра может замедлить выполнение анализа и работу планировщика, ничего не улучшив с точки зрения оптимизации.
С другой стороны, уменьшение параметра (вплоть до нуля) — наоборот, может ускорить анализ и планирование. Но может и привести к плохим планам, так что такая «экономия» обычно неоправданна.
Статистика для нескалярных типов данных
Для нескалярных типов данных может собираться статистика по распределению не только самих значений, но и элементов, из которых состоят значения. Это позволяет более точно планировать запросы с участием столбцов не в первой нормальной форме.
Два массива
most_common_elemsиmost_common_elem_freqsпоказывают список наиболее частых элементов и их частоты.Статистика собирается и используется при оценке селективности для массивов и типа данных
tsvector.Массив
elem_count_histogramпоказывает гистограмму количества уникальных элементов в значении.Статистика собирается и используется при оценке селективности только для массивов.
Для диапазонных типов собираются гистограммы распределения нижних и верхних границ диапазонов и длины диапазона, которые используются для оценки селективности различных операций с этими типами. В представлении
pg_statsэти гистограммы не отображаются.Та же статистика используется и для многодиапазонных типов, появившихся в версии PostgreSQL 14.
Средний размер поля
Поле avg_width представления pg_stats показывает средний размер значений в данном столбце. Конечно, размер значений таких типов данных, как integer или char(3), всегда одинаков, но средний размер значений типов с переменной длиной, таких как text, может сильно отличаться от столбца к столбцу:
SELECT attname, avg_width FROM pg_stats WHERE (tablename, attname) IN ( VALUES ('tickets', 'passenger_name'), ('ticket_flights','fare_conditions') );
attname | avg_width −−−−−−−−−−−−−−−−−+−−−−−−−−−−− fare_conditions | 8 passenger_name | 16 (2 rows)
Эта статистика используется для оценки объема памяти, необходимой для таких операций, как сортировка или хеширование.
Корреляция
Поле correlation представления pg_stats показывает корреляцию между физическим расположением данных на диске и логическим порядком в смысле операций «больше» и «меньше». Если значения хранятся строго по возрастанию, корреляция будет близка к единице; если по убыванию — к минус единице. Чем более хаотично расположены данные на диске, тем ближе значение к нулю.
SELECT attname, correlation FROM pg_stats WHERE tablename = 'airports_data' ORDER BY abs(correlation) DESC;
attname | correlation −−−−−−−−−−−−−−+−−−−−−−−−−−−− coordinates | airport_code | −0.21120238 city | −0.1970127 airport_name | −0.18223621 timezone | 0.17961165 (5 rows)
Для столбца coordinates эта статистика не собирается, поскольку для типа данных point не определены операции сравнения, такие как «больше» и «меньше».
Корреляция используется для оценки стоимости индексного сканирования.
Статистика по выражению
Обычно статистика по столбцу может использоваться, только если в сравнении слева или справа от оператора фигурирует сам столбец, а не выражение. Например, планировщик не знает, как изменится статистика после вычисления функции от столбца, и поэтому для условия «вызов-функции = константа» всегда использует фиксированную оценку в 0,5 %:
EXPLAIN SELECT * FROM flights WHERE extract( month FROM scheduled_departure AT TIME ZONE 'Europe/Moscow' ) = 1;
QUERY PLAN −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− Seq Scan on flights (cost=0.00..6384.17 rows=1074 width=63) Filter: (EXTRACT(month FROM (scheduled_departure AT TIME ZONE ... (2 rows)
SELECT round(reltuples * 0.005) FROM pg_class WHERE relname = 'flights';
round −−−−−−− 1074 (1 row)
Планировщик не знает семантику даже стандартных функций, хотя нам из общих соображений понятно, что рейсов, совершенных в январе, будет примерно 1/12 от общего количества:
SELECT count(*) AS total, count(*) FILTER (WHERE extract( month FROM scheduled_departure AT TIME ZONE 'Europe/Moscow' ) = 1) AS january FROM flights;
total | january −−−−−−−−+−−−−−−−−− 214867 | 16831 (1 row)
Исправить ситуацию можно, собрав статистику не по столбцу таблицы, а по выражению.
Расширенная статистика по выражению
Первый вариант — использовать расширенную статистику по выражению. Такая возможность появилась в версии PostgreSQL 14. Расширенная статистика не собирается автоматически; необходимо вручную создать объект базы данных командой CREATE STATISTICS:
CREATE STATISTICS flights_expr ON (extract( month FROM scheduled_departure AT TIME ZONE 'Europe/Moscow' )) FROM flights;
После сбора статистики оценка исправляется:
ANALYZE flights; EXPLAIN SELECT * FROM flights WHERE extract( month FROM scheduled_departure AT TIME ZONE 'Europe/Moscow' ) = 1;
QUERY PLAN −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− Seq Scan on flights (cost=0.00..6384.17 rows=16222 width=63) Filter: (EXTRACT(month FROM (scheduled_departure AT TIME ZONE ... (2 rows)
Чтобы статистика использовалась, выражение в условии запроса должно быть записано в том же виде, что и в команде создания статистики.
Информация о расширенной статистике сохраняется в таблице системного каталога pg_statistic_ext. Собранная статистика (начиная с версии PostgreSQL 12) сохраняется в отдельной таблице pg_statistic_ext_data. Смысл такого разделения — в возможности ограничения доступа пользователей к чувствительной информации.
Несколько представлений показывают собранную информацию, доступную для пользователя, в более удобном виде. Расширенную статистику по выражению можно посмотреть следующим образом:
SELECT left(expr,50) || '...' AS expr, null_frac, avg_width, n_distinct, most_common_vals AS mcv, left(most_common_freqs::text,50) || '...' AS mcf, correlation FROM pg_stats_ext_exprs WHERE statistics_name = 'flights_expr' \gx
-[ RECORD 1 ]−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− expr | EXTRACT(month FROM (scheduled_departure AT TIME ZO... null_frac | 0 avg_width | 8 n_distinct | 12 mcv | {8,9,3,5,12,4,10,7,11,1,6,2} mcf | {0.12526667,0.11016667,0.07903333,0.07903333,0.078.. correlation | 0.095407926
Размер собираемой расширенной статистики можно изменить отдельно, задав с помощью команды ALTER STATISTICS, например:
ALTER STATISTICS flights_expr SET STATISTICS 42;
Статистика для индекса по выражению
Второй способ — воспользоваться тем, что при создании индекса по выражению для него собирается отдельная статистика, как для таблицы. Это удобно, если индекс действительно нужен.
DROP STATISTICS flights_expr; CREATE INDEX ON flights(extract( month FROM scheduled_departure AT TIME ZONE 'Europe/Moscow' )); => ANALYZE flights; EXPLAIN SELECT * FROM flights WHERE extract( month FROM scheduled_departure AT TIME ZONE 'Europe/Moscow' ) = 1;
QUERY PLAN −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− Bitmap Heap Scan on flights (cost=318.42..3235.96 rows=16774 wi... Recheck Cond: (EXTRACT(month FROM (scheduled_departure AT TIME... −> Bitmap Index Scan on flights_extract_idx (cost=0.00..314.2... Index Cond: (EXTRACT(month FROM (scheduled_departure AT TI... (4 rows)
Статистика для индексов по выражению хранится так же, как статистика по таблице. Например, количество уникальных значений:
SELECT n_distinct FROM pg_stats WHERE tablename = 'flights_extract_idx';
n_distinct −−−−−−−−−−−− 12 (1 row)
Изменить точность статистики в случае индекса можно (начиная с версии PostgreSQL 11) командой ALTER INDEX. Для этого сначала может потребоваться узнать, как называется столбец, соответствующий выражению. Например:
SELECT attname FROM pg_attribute WHERE attrelid = 'flights_extract_idx'::regclass;
attname −−−−−−−−− extract (1 row)
ALTER INDEX flights_extract_idx ALTER COLUMN extract SET STATISTICS 42;
Многовариантная статистика
Начиная с 10-й версии можно собирать многовариантную статистику, охватывающую не один, а несколько столбцов таблицы. Для этого необходимо вручную создать соответствующую расширенную статистику.
Реализовано три вида многовариантной статистики.
Функциональные зависимости между столбцами
Если значения в одном столбце определяются (полностью или частично) значениями другого столбца, и в запросе указаны условия на оба таких столбца, оценка кардинальности окажется заниженной.
Рассмотрим запрос с двумя условиями:
SELECT count(*) FROM flights WHERE flight_no = 'PG0007' AND departure_airport = 'VKO';
count −−−−−−− 396 (1 row)
Оценка оказывается сильно заниженной — всего 26 строк:
EXPLAIN SELECT * FROM flights WHERE flight_no = 'PG0007' AND departure_airport = 'VKO';
QUERY PLAN −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− Bitmap Heap Scan on flights (cost=12.03..1238.70 rows=26 width=63) Recheck Cond: (flight_no = 'PG0007'::bpchar) Filter: (departure_airport = 'VKO'::bpchar) −> Bitmap Index Scan on flights_flight_no_scheduled_departure_key (cost=0.00..12.02 rows=480 width=0) Index Cond: (flight_no = 'PG0007'::bpchar) (6 rows)
Это известная проблема коррелированных предикатов. Планировщик полагается на то, что предикаты независимы и вычисляет общую селективность как произведение селективностей условий, объединенных логическим «и». Это хорошо видно в приведенном плане: оценка в узле Bitmap Index Scan, полученная по условию на столбец flight_no, существенно уменьшается после фильтрации по условию на столбец departure_airport в узле Bitmap Heap Scan.
Однако мы понимаем, что номер рейса однозначно определяет аэропорты: фактически, второе условие избыточно (конечно, если аэропорт указан правильно). В таких случаях расширенная статистика по функциональным зависимостям может улучшить оценку.
Создадим расширенную статистику по функциональной зависимости между двумя столбцами:
CREATE STATISTICS flights_dep(dependencies) ON flight_no, departure_airport FROM flights;
При очередном анализе таблицы желаемая статистика будет собрана и оценка улучшится:
ANALYZE flights; EXPLAIN SELECT * FROM flights WHERE flight_no = 'PG0007' AND departure_airport = 'VKO';
QUERY PLAN −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− Bitmap Heap Scan on flights (cost=10.56..816.91 rows=276 width=63) Recheck Cond: (flight_no = 'PG0007'::bpchar) Filter: (departure_airport = 'VKO'::bpchar) −> Bitmap Index Scan on flights_flight_no_scheduled_departure_key (cost=0.00..10.49 rows=276 width=0) Index Cond: (flight_no = 'PG0007'::bpchar) (6 rows)
В системном каталоге собранную статистику можно посмотреть следующим образом:
SELECT dependencies FROM pg_stats_ext WHERE statistics_name = 'flights_dep';
dependencies −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− {"2 => 5": 1.000000, "5 => 2": 0.010567} (1 row)
Числа 2 и 5 — номера столбцов таблицы из pg_attribute. Значения определяют степень функциональной зависимости: от 0 (зависимости нет) до 1 (значения в первом столбце полностью определяют значения в другом).
Многовариантное число различных значений
Информация о количестве уникальных комбинаций значений из нескольких столбцов позволяет улучшить оценку кардинальности группировки по нескольким столбцам.
Например, количество возможных пар аэропортов отправления и прибытия оценивается планировщиком как квадрат количества аэропортов, но реальное значение сильно меньше, поскольку далеко не каждая пара аэропортов соединена прямым рейсом:
SELECT count(*) FROM ( SELECT DISTINCT departure_airport, arrival_airport FROM flights ) t;
count −−−−−−− 618 (1 row)
EXPLAIN SELECT DISTINCT departure_airport, arrival_airport FROM flights;
QUERY PLAN −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− HashAggregate (cost=5847.01..5955.16 rows=10816 width=8) Group Key: departure_airport, arrival_airport −> Seq Scan on flights (cost=0.00..4772.67 rows=214867 width=8) (3 rows)
Создадим и соберем расширенную статистику по числу разных значений:
CREATE STATISTICS flights_nd(ndistinct) ON departure_airport, arrival_airport FROM flights; ANALYZE flights; EXPLAIN SELECT DISTINCT departure_airport, arrival_airport FROM flights;
QUERY PLAN −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− HashAggregate (cost=5847.01..5853.19 rows=618 width=8) Group Key: departure_airport, arrival_airport −> Seq Scan on flights (cost=0.00..4772.67 rows=214867 width=8) (3 rows)
Собранная статистика в системном каталоге:
SELECT n_distinct FROM pg_stats_ext WHERE statistics_name = 'flights_nd';
n_distinct −−−−−−−−−−−−−−− {"5, 6": 618} (1 row)
Многовариантные списки частых значений
При неравномерном распределении значений одного только знания функциональной зависимости может быть недостаточно, поскольку оценка существенно зависит от конкретной пары значений. Например, планировщик ошибается, оценивая количество рейсов из Шереметьево, выполняемых Боингом 737:
SELECT count(*) FROM flights WHERE departure_airport = 'SVO' AND aircraft_code = '733'
count −−−−−−− 2037 (1 row)
EXPLAIN SELECT * FROM flights WHERE departure_airport = 'SVO' AND aircraft_code = '733';
QUERY PLAN −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− Seq Scan on flights (cost=0.00..5847.00 rows=733 width=63) Filter: ((departure_airport = 'SVO'::bpchar) AND (aircraft_cod... (2 rows)
В таком случае оценку можно уточнить, собирая статистику по многовариантным спискам частых значений:
CREATE STATISTICS flights_mcv(mcv) ON departure_airport, aircraft_code FROM flights; ANALYZE flights; EXPLAIN SELECT * FROM flights WHERE departure_airport = 'SVO' AND aircraft_code = '733';
QUERY PLAN −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− Seq Scan on flights (cost=0.00..5847.00 rows=2077 width=63) Filter: ((departure_airport = 'SVO'::bpchar) AND (aircraft_cod... (2 rows)
Теперь при оценке планировщик пользуется частотой, сохраненной в системном каталоге:
SELECT values, frequency FROM pg_statistic_ext stx JOIN pg_statistic_ext_data stxd ON stx.oid = stxd.stxoid, pg_mcv_list_items(stxdmcv) m WHERE stxname = 'flights_mcv' AND values = '{SVO,773}';
values | frequency −−−−−−−−−−−+−−−−−−−−−−−−−−−−−−−−−− {SVO,773} | 0.005733333333333333 (1 row)
В многовариантном списке, как и в обычном списке частых значений, сохраняется default_statistics_target значений (если параметр задан на уровне столбцов, то используется наибольшее значение).
Как и для расширенной статистики по выражению, при необходимости можно изменить размер списка (начиная с версии PostgreSQL 13) с помощью команды
ALTER STATISTICS ... SET STATISTICS ...;
Во всех примерах я использовал только два столбца, но многовариантную статистику можно создавать и по большему количеству.
В одном объекте можно комбинировать статистику разных типов, указывая их через запятую (а если не указать тип, для заданных столбцов будут собираться сразу все возможные статистики).
А в версии PostgreSQL 14 в многовариантной статистике, как и в статистике по выражению, можно использовать произвольные выражения, а не только имена столбцов.
