Последние достижения в области обработки естественного языка (Natural Language Processing, NLP) в значительной степени основаны на успехах предварительного обучения без учителя, с помощью которого можно обучать универсальные языковые модели на большом количестве текстов без ручной разметки или меток. Было показано, что такие предобученные модели, вроде BERT и RoBERTa, запоминают удивительно большое количество общих знаний о мире, например «место рождения Франческо Бартоломео Конти», «разработчик JDK» и «владелец Border TV». Хотя способность кодировать знания особенно важна для определенных задач обработки естественного языка, таких как ответы на вопросы, поиск информации и генерация текста, эти модели запоминают знания неявно, т. е. знания о мире фиксируются абстрактным образом в весах модели, что затрудняет определение, какие знания были сохранены и где именно они хранятся в модели. Кроме того, объем памяти и, следовательно, точность модели ограничены размером нейронной сети. Чтобы получить больше знаний о мире, стандартной практикой является обучение все более крупных сетей, что, однако, может сильно замедлять и удорожать процесс.
Но что если вместо этого существовал бы метод предварительного обучения, позволяющий получить доступ к знаниям явно, например, путем ссылки на дополнительный большой внешний текстовый корпус, способный достичь точных результатов без увеличения или усложнения модели? Например, предложение, найденное во внешней коллекции документов, «Франческо Бартоломео Конти родился во Флоренции», может использоваться моделью для определения места рождения музыканта, вместо того, чтобы полагаться на непрозрачную способность модели получить доступ к знаниям, хранящимся в ее собственных параметрах. Возможность извлекать текст, содержащий явные знания, такие как этот, повысит эффективность предварительного обучения, позволяя модели хорошо работать с наукоемкими задачами без использования миллиардов параметров.
В статье «REALM: Retrieval-Augmented Language Model Pre-Training», принятой на Международной конференции по машинному обучению (ICML) 2020 года, авторы рассказали о новой парадигме предварительного обучения языковой модели, которая дополняет модель языкового представления с помощью модуля извлечения знаний, позволяя модели REALM извлекать текстовые знания о мире явно из необработанных текстовых документов вместо запоминания всех знаний в параметрах модели. Авторы также открыли исходный код REALM, чтобы продемонстрировать, как можно совместно обучать модуль извлечения и языковое представление.
Предыстория: предварительное обучение языковых моделей
Чтобы понять, как стандартные языковые модели запоминают общие знания о мире, следует сначала рассмотреть, как эти модели проходят предварительное обучение. С момента изобретения BERT задача заполнения пропуска, называемая маскированным языковым моделированием (Masked Language Modeling, MLM), широко использовалась для языковых моделей (или моделей языковых представлений). Задача состоит в заполнении недостающих слов в предложениях, где некоторые слова замаскированы. Пример этой задачи выглядит так:
I am so thirsty. I need to __ water. Я испытываю жажду. Мне нужно __ воды.
Во время предварительного обучения модель просматривает большое количество примеров и настраивает параметры так, чтобы предсказать пропущенные слова (так, в примере выше ответ drink (выпить)). Интересно, что задание «заполнить пропуск» заставляет модель запоминать определенные факты об окружающем мире. Например, чтобы заполнить пропущенное слово в следующем примере, необходимо знать место рождения Эйнштейна:
Einstein was a __-born scientist. (answer: German) Эйнштейн был учёным, родившимся в __. (ответ: Германии)
Однако, поскольку знания о мире, усвоенные моделью, хранятся в ее весах, они абстрактны, что затрудняет понимание того, какая именно информация была усвоена.
Идея: предварительное обучение языковой модели с аугментацией извлеченными знаниями
В отличие от стандартных языковых моделей, в REALM добавлен дополнительный модуль извлечения знаний, который сначала извлекает фрагмент текста из коллекции внешних документов в качестве вспомогательных знаний (в своих экспериментах авторы используют корпус текста Википедии), а затем передает вспомогательный текст наряду с исходным в языковую модель.
Ключевая интуиция REALM заключается в том, что модуль извлечения знаний должен улучшать способность модели заполнять пропущенные слова. Следовательно, больший вес должны получать те извлеченные тексты, которые предоставляют больше контекста для заполнения пропущенных слов. Если же полученная информация не помогает модели делать прогнозы, её вес следует уменьшить, освобождая место для лучшего извлеченного текста.
Но как обучить модуль извлечения знаний, учитывая, что во время предварительного обучения доступен только неразмеченный текст? Оказывается, можно использовать задачу заполнения слов для обучения модуля извлечения знаний косвенно, без какой-либо ручной разметки. Предположим, есть входной запрос вида:
We paid twenty __ at the Buckingham Palace gift shop. Мы заплатили двадцать __ в сувенирном магазине Букингемского дворца.
Заполнить пропущенное слово (ответ: pounds (фунты)) в этом предложении без извлечения знаний может быть непросто, поскольку модели необходимо иметь неявно сохраненные знания о стране, в которой расположен Букингемский дворец, и соответствующей валюте, а также установить связь между ними. Модели было бы легче заполнить пропущенное слово, если бы ей предоставили также фрагмент текста, который бы явно связывал некоторые необходимые знания, извлеченные из внешнего корпуса.
В этом примере следующее предложение получит большой вес в модуле извлечения:
Buckingham Palace is the London residence of the British monarchy. Букингемский дворец - лондонская резиденция британской монархии.
Поскольку на данном этапе необходимо добавить больше контекста к исходному предложению, полезными могут оказаться несколько вариантов извлеченных текстов, например вот такой:
The official currency of the United Kingdom is the Pound. Официальной валютой Соединенного королевства является фунт.
Весь процесс показан в следующей схеме:

Вычислительные вызовы для REALM
Большим вызовом для REALM стало масштабирование предварительного обучения, позволяющее модели извлекать знания из миллионов документов. В REALM выбор лучшего документа формулируется как поиск на основе максимума скалярного произведения (Maximum Inner Product Search, MIPS). Для выполнения поиска модели MIPS должны сначала закодировать все документы в коллекции, чтобы каждый документ имел соответствующий вектор. Вход модели кодируется как вектор запроса. В MIPS при заданном запросе извлекается документ в коллекции, имеющий максимальное значение скалярного произведения между вектором документа и вектором запроса, как показано на рисунке ниже:

В REALM используется пакет ScaNN для эффективного выполнения MIPS, что делает поиск максимального значения скалярного произведения относительно малозатратным, учитывая, что векторы документа предварительно подсчитаны. Однако, если параметры модели были обновлены во время обучения, обычно необходимо перекодировать векторы документов для всей коллекции документов. Для решения этой вычислительной проблемы авторы построили модуль извлечения таким образом, чтобы вычисления, выполняемые для каждого документа, можно было кэшировать и асинхронно обновлять. Авторы также обнаружили, что обновление векторов документов каждые 500 шагов обучения, а не каждый шаг, может обеспечить хорошую производительность и сделать обучение более управляемым.
Применение REALM к ответам на вопросы в открытой области
Авторы оценили эффективность REALM, применив модель на задаче ответов на вопросы открытой предметной области (Open-QA), одной из самых знаниеемких задач в обработке естественного языка. Цель задачи — ответить на такие вопросы, как «Какой угол у равностороннего треугольника?».
В стандартных задачах с ответами на вопросы (например, SQuAD или Natural Questions) вспомогательный документ предоставляется как часть входных данных, поэтому модели нужно только искать ответ в данном документе. В Open-QA нет заданных документов, поэтому модели должны сами искать знания — это делает Open-QA отличной задачей для проверки эффективности REALM.
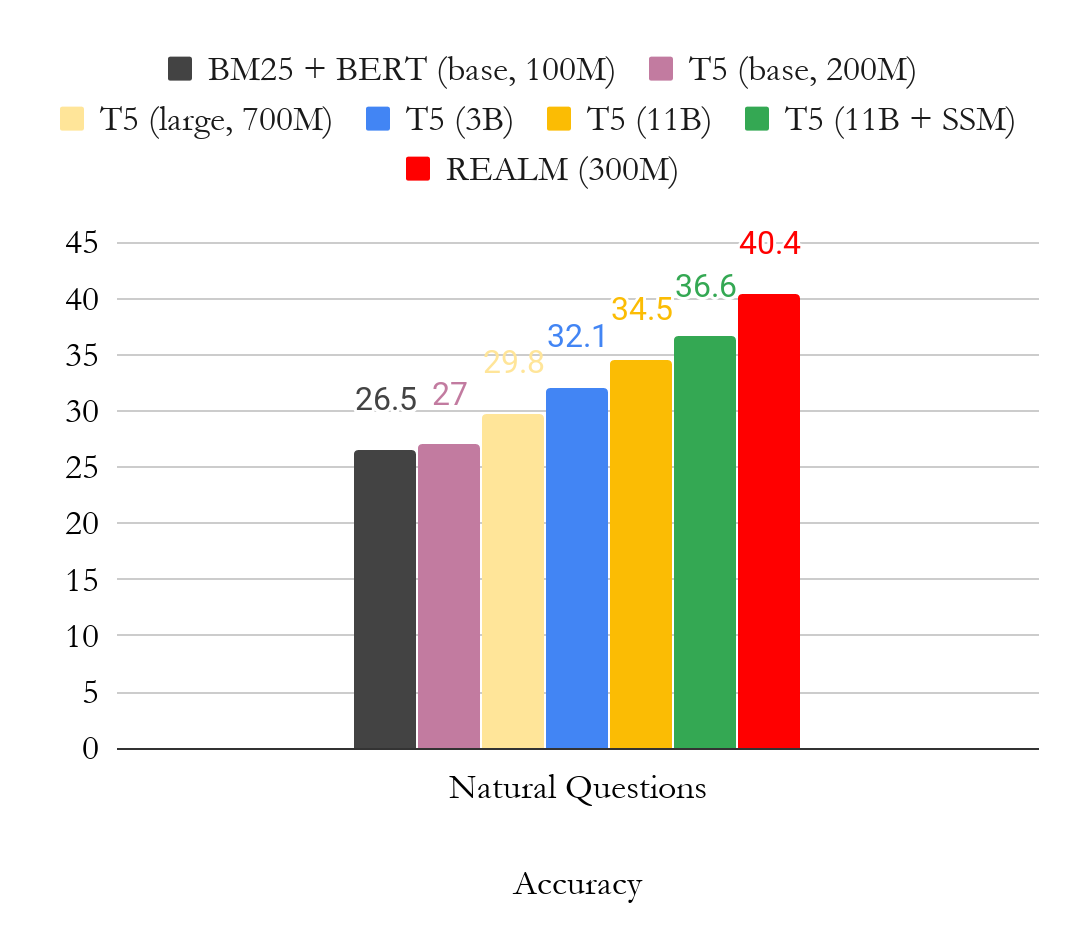
На следующем рисунке показаны результаты для Open-QA-версии Natural Questions. В основном авторы сравнивали свои результаты с T5, другим подходом, который обучает модель без дополнительных размеченных документов. Из рисунка ясно видно, что предварительное обучение REALM генерирует очень мощные модели Open-QA и даже превосходит гораздо более крупную модель T5 (11 млрд) почти на 4 пункта, используя только часть параметров (300 млн).
Заключение
Выпуск REALM помог повысить интерес к разработке моделей, аугментированных извлеченными текстами, включая недавнюю генеративную модель. Авторы с нетерпением ждут возможности расширить это направление работы несколькими способами, включая 1) применение методов, подобных REALM, к новым приложениям, требующим знаниеемких ответов и интерпретируемости выхода (помимо Open-QA), и 2) изучение преимуществ извлечения других форм знаний, таких как изображения, структуры графов знаний или даже текста на других языках. Авторы также будут рады наблюдать за работой исследовательского сообщества с открытым кодом REALM.
Авторы
- Автор оригинала – Ming-Wei Chang, Kelvin Guu
- Перевод – Смирнова Екатерина
- Редактирование и вёрстка – Шкарин Сергей

