
Прочитать текстовое сообщение — быстрее, чем прослушать голосовое. Ещё по тексту удобнее искать и уточнять детали. Воспринимать числа, адреса, номера телефонов и подобную информацию тоже проще в написанном виде. С другой стороны, записать голосовое зачастую удобнее, чем напечатать сообщение — ведь это можно делать параллельно с другими занятиями, на ходу или за рулём.
Автоматическое распознавание речи помогает преодолеть этот разрыв. Технология переводит устную речь в текст, а дальше с ним можно делать что вздумается: хоть выводить расшифровку, хоть передавать в поиск, хоть преобразовывать в команды для техники. Или, как в нашем случае, помогать пользователям общаться.
Меня зовут Надя Зуева, я занимаюсь голосовыми технологиями ВКонтакте. В этой статье я расскажу, как работает наше распознавание голосовых сообщений: какие модели мы используем, на каких данных их обучаем и какие оптимизации применили для быстрой работы в проде.

Для чего нам распознавание речи
Идея автоматического распознавания речи появилась, кажется, даже раньше, чем компьютеры получили достаточное распространение. С практикой было сложнее. В 1960–1980-х, когда герои «Звездного пути» свободно разговаривали с компьютером, в реальности были только отдельные устройства, которые могли распознавать цифры или небольшой набор заранее определенных команд.
Чуть позже распознавание речи стали рассматривать ещё в одном контексте: как способ, который поможет людям с ограниченными возможностями здоровья взаимодействовать с техникой. Но по большей части это всё равно была демонстрация возможностей, а не массовое применение. И только недавно распознавание речи стало мультиязычным и действительно удобным для всех пользователей технологичных продуктов. Сейчас ASR (automatic speech recognition) заметнее всего в голосовых ассистентах, умной технике и транскрибировании видео.
Я впервые столкнулась с задачей распознавания речи летом 2018 года в Сириусе, где познакомилась с ребятами из ВКонтакте. Меня позвали в команду прикладных исследований, которой на тот момент руководил Паша Калайдин. Вместе мы начали исследовать, какие архитектуры ASR-сетей сейчас самые боевые и как их можно использовать у нас.
Уже тогда мы подумали, что круто было бы сделать автоматическое распознавание голосовых сообщений с преобразованием в текст. Как продуктовая фича это точно полезно, а для нас такая задача ещё и настоящий вызов: голосовые записывают в условиях, далёких от идеальных, в них используют много сленга и не особо заботятся о дикции. При этом распознавание нужно делать быстро: потратить 10 минут на расшифровку 10-секундного голосового — не вариант.
Сначала все эксперименты мы проводили с англоязычной речью — учились распознавать её. На тот момент в открытом доступе уже было достаточно данных для обучения на английском, а на русском — нет. Так что мы начали с доступного. Сейчас с русскоязычными датасетами дела обстоят лучше: есть Golos от Сбера и Common Voice от Mozilla.
Поскольку проект был исследовательский, не обошлось без метода проб и ошибок, к тому же я тогда была студенткой без большого опыта в промышленной разработке. Так что далеко не всё шло гладко и сразу заводилось. Тем не менее к концу 2019 года была готова первая версия модели, которую можно было пробовать в проде. В основе лежала архитектура wav2letter++ от Facebook AI Research, и мы запустили её в silent-режиме в качестве фичи для поиска по голосовым сообщениям.
Когда в конце 2019 года появились первые результаты, мы увидели, что распознавание речи может быть очень полезно для преобразования голосовых сообщений в текст. Поэтому стали инвестировать в создание этой технологии больше ресурсов. К моей работе в разные моменты подключались и коллеги по команде исследований, и ребята из других направлений. Например, Октай Татанов заводил версию акустической модели, альтернативную wav2letter++, и она долго была в продакшене. Даня Гаврилов помогал экспериментировать с языковой моделью и пунктуацией. Ваня Самсонов помогал нам с координацией разметки от тестировщиков. А Дима Юткин вместе с ребятами из команды инфраструктуры встраивал модели и отвечал за них. Сейчас мы продолжаем развивать эту технологию.
С начала 2020 года задача уже состояла не только в том, чтобы сделать точную модель, но и значительно оптимизировать производительность для многомиллионной аудитории. Также отдельным испытанием для нас стал сленг — без его расшифровки в наших голосовых было не обойтись.
Сейчас пайплайн распознавания речи состоит из трёх моделей. Первая, акустическая, отвечает за распознавание звуков. Вторая, языковая, формирует из звуков слова. А третья, пунктуационная, расставляет знаки препинания. Далее обсудим каждую из моделей, но сначала подготовим входные данные.
Препроцессинг
В задачах ASR в первую очередь необходимо перевести звук в формат, удобный для подачи в нейросеть. Эта область очень требовательна к предобработке входных данных. С одной стороны, это усложняет жизнь начинающим исследователям, с другой — даёт поле для творчества.
Сам по себе звук представляется в памяти компьютера как массив значений, показывающих колебания амплитуды по времени. Причём чем больше отсчётов в секунду мы возьмём, тем лучше будет качество записи (sample rate). Этот параметр обычно исчисляется в десятках тысяч точек в секунду (или кГц), и итоговая дорожка получается очень длинной и неудобной для работы. Поэтому перед подачей в алгоритм звук предобрабатывают: в частности, переводят в спектрограмму — зависимость интенсивности колебания звука на конкретной частоте по времени.
Подход с использованием спектрограмм считается консервативным. Есть альтернативы: например, wav2vec (по сути — аналог word2vec из мира NLP для звука). Вопреки тому, что SOTA-решения (state-of-the-art model) по ASR сейчас используют wav2vec, для нашей архитектуры такой подход не дал прироста в качестве.
Акустическая модель
После того как сырая дорожка переведена в удобное для нейросети представление, мы готовы распознавать речь: получать из звука распределение вероятностей букв по времени.

В большинстве подходов сначала составляют фонетические транскрипции (по принципу «что слышится, то и пишется»), а затем отдельной языковой моделью «причёсывают» результат — исправляют грамматические и орфографические ошибки, убирают из расшифровки лишние буквы.
В качестве простой акустической модели (например, в элайнерах) в задаче распознавания речи использовались марковские модели. Сейчас их для этого, конечно, никто не применяет — на смену пришли нейросети.
Если открыть примерно любой курс по нейронным сетям, там обязательно скажут, что в 2012 году нейросети победили классические методы в задаче классификации картинок на датасете ImageNet. В области распознавания речи такая «победа» произошла ещё в 2009-м. Спустя десятилетие, когда мы активно занялись этой задачей, существовало уже довольно много архитектур, которые дают хорошие результаты.
Например, DeepSpeech2 (SOTA 2018 года на датасете LibriSpeech). Она представляла собой комбинацию двух типов слоёв — рекуррентных и свёрточных. Рекуррентные слои позволяли генерировать продолжение фраз с оглядкой на предыдущие сгенерированные слова, а свёрточные отвечали за извлечение признаков из спектрограмм. В статье об этой архитектуре показано, что для обучения используется CTC-loss: она позволяет одинаково хорошо распознавать слова «приве-е-е-е-ет» и «привет», то есть не привязываться к длительности звуков. Кстати, эта функция потерь используется и в задачах по распознаванию рукописного текста.
Область Deep Learning очень быстро развивается: в конце 2018-го мы экспериментировали со свежей DeepSpeech, и в это же время вышла статья о ещё одной архитектуре — wav2letter++ от FAIR. Её особенность в том, что в ней используются только свёрточные слои, то есть нет авторегрессивности (с авторегрессией мы оглядываемся на прошлые сгенерированные слова и идём последовательно, а это делает нейросеть медленнее). Создатели wav2letter++ сделали упор на скорость, и вся реализация выполнена на С++. Это усложнило нашу работу: пришлось иметь дело не с приятным PyTorch, в котором любят разработчиков, а с flashlight, про который я услышала впервые. Именно с этой архитектуры мы стартовали в поиске по голосовым сообщениям.
Использование полностью свёрточной архитектуры открыло новые возможности для исследователей. Вскоре появилась архитектура Jasper, которая тоже была fully-convolutional, но также использовала идею residual connections, как в ResNet или трансформерах. Затем вышла QuartzNet от NVIDIA, основанная на Jasper, и мы использовали её.
Сейчас вышла ещё одна модель — Conformer, которая на момент написания этой статьи является SOTA-решением.
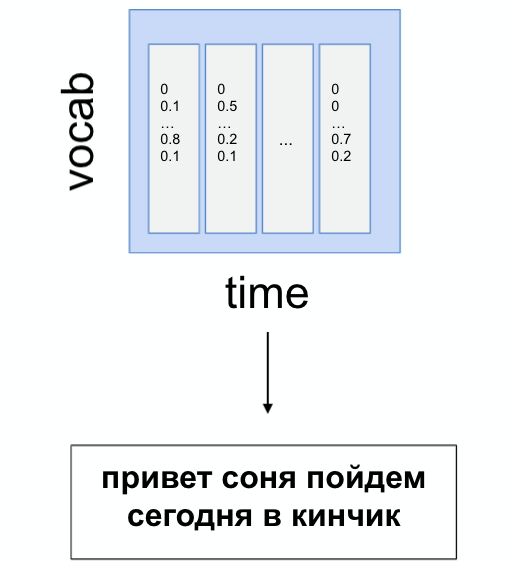
Таким образом, какую бы из этих архитектур вы ни выбрали, на вход нейросети подаётся спектрограмма, а на выходе получается матрица распределения по времени вероятностей каждой фонемы (то есть звука — в нашем случае он соотносится с русским алфавитом без буквы Ё). Такую таблицу также называют emission set.
Из выхода emission set уже можно получить ответ при помощи greedy decoder (жадного декодинга) — иначе говоря, в каждый момент выбрать наиболее вероятный звук.

Но такой подход мало что будет знать о правописании и может дать много ошибок. Здесь на помощь приходит beam search decoding с использованием перевзвешивания гипотез через языковую модель. Давайте разбираться.
Языковая модель
После того как мы получили emission set, нужно сгенерировать текст. Начинаем декодинг — процесс генерации транскрипции по emission set. Он производится не только по вероятностям, которые нам выдаёт акустическая модель, но и с учётом «мнения» языковой модели. Она может подсказать, насколько вероятно встретить в языке такую комбинацию символов или слов.
Для декодинга используем алгоритм beam search. Его идея заключается в том, что мы не просто выбираем наиболее вероятный звук в отдельный момент, а оцениваем вероятность всей цепочки с учётом уже пройденных слов, храним топ кандидатов на каждом шаге и в итоге выбираем самого вероятного.

Причём при выборе кандидатов мы присваиваем каждому вероятность с учётом ответов и акустической, и языковой моделей — формула на картинке ниже.

Окей, с beam search decoding разобрались. Теперь о том, что представляет собой языковая модель.
В качестве языковой модели мы используем n-граммы. Этот подход очень неплохо работает с точки зрения архитектуры, пока мы говорим про серверные (а не мобильные) решения. На рисунке ниже пример для n=2.

Интересно тут другое — препроцессинг данных для обучения.
В переписке люди часто используют сокращения, цифры, спецсимволы. Наша акустическая модель знает только символы русского алфавита, поэтому в данных для обучения мы должны различать ситуации, когда «1» означает «первый», а когда «один» или «единица». Сложно найти много текстов с разговорной речью, где люди пишут «верни мне триста восемьдесят шесть рублей до двадцатого декабря», а не «верни 386 руб до 20 декабря». Поэтому мы обучили вспомогательную модель нормализации.
В качестве архитектуры для неё мы взяли трансформер — модель, которая часто используется для машинного перевода. У нас в своём роде похожая задача: перевод из языка, где всё денормализовано, — в нормализованный язык, где существуют только символы русского алфавита.
На выходе языковой модели получаем последовательность слов, которые есть в языке и друг с другом «сочетаются». Прочитать и понять это гораздо легче, чем после акустической. Но для длинных сообщений результат всё ещё не очень удобный, к тому же могут быть неоднозначные трактовки.
Модель для пунктуации
После того, как мы получили читаемую последовательность слов, можем расставить знаки препинания. Это особенно полезно, когда текст длинный: с точками читать его точно будет проще.

Архитектура, которая лежит в основе нашей модели пунктуации, — энкодер из трансформера и линейный слой. Он выполняет хитрую классификацию: после очередного слова мы предсказываем, надо ли ставить точку, запятую, тире, двоеточие или же не требуется ничего.
Подход в генерации данных для обучения тут похожий: мы берём тексты с расставленными знаками препинания и искусственно «портим» эти данные, убирая пунктуацию. А затем учимся восстанавливать.
Данные для обучения
Как я говорила в начале статьи, на старте наших исследований ещё не было открытых источников русскоязычных данных для обучения систем распознавания речи. Какое-то время мы экспериментировали с английским. А потом поняли, что нам в любом случае нужны максимально разговорные записи, а не профессионально начитанные аудиокниги, как в LibriSpeech.
В итоге решили сами собрать данные для обучения. Привлекли для этого тестировщиков (VK Testers): готовили для них короткие тексты по 3–30 слов, а они их надиктовывали нам в голосовых. Тексты для озвучки генерировали сами с помощью отдельной модели, которую обучили на комментариях из публичных сообществ — так получилось распределение из того же домена, со сленгом и разговорной речью. Причём мы сразу просили записывать голосовые в разных условиях и говорить как обычно — чтобы данные для обучения были близки к тем, которые будут в реальных боевых условиях.
После получения записей было важно отсеять неподходящие. Поэтому, когда мы готовили данные от тестировщиков под обучение, использовали фильтры. Например, если запись короткого текста идёт 30 секунд (притом что в среднем человек за 1 секунду успевает произнести около трёх слов), это выглядит подозрительно.
Запуск в прод
Как известно, от моделей в статьях (и даже их реализаций силами ML-специалистов) до использования машинного обучения в продакшене лежит большой путь. Поэтому команда инфраструктуры ВКонтакте подключилась к работе над сервисом распознавания голосовых сообщений в самом начале 2020-го, когда у нас была ещё первая версия модели.
Команда инфраструктуры помогла сделать из наших ML-реализаций высоконагруженный надёжный сервис, который работает с хорошей производительностью и эффективно расходует серверные ресурсы. Подробно о том, какие проблемы и как решали наши коллеги, можно узнать из доклада Сергея Ларионенко на VK Tech Talks. Здесь кратко перечислю основное.
Мы в команде исследований работаем с файлами моделей и кодом на C++, который запускает эти модели. Но инфраструктура ВКонтакте в основном написана на Go, и коллегам из профильной команды нужно было подружить C++ с Go. Для этого использовали расширение CGO: так, чтобы верхнеуровневый код можно было писать на Go, а обращение к моделям, декодирование и прочее оставалось на C++.
Следующая задача состояла в том, чтобы обрабатывать любое аудиосообщение за несколько секунд, но укладываться в доступные мощности и эффективно использовать серверные ресурсы. Для этого распознавание голосовых работает на одних серверах с другими сервисами. Возникает проблема совместного доступа к видеокарте и CUDA-ядрам из нескольких процессов — её решаем с помощью технологии MPS от NVIDIA. MPS минимизирует влияние блокировок и простои, позволяет максимально утилизировать видеокарту без необходимости переписывать клиентское приложение.
Ещё один важный момент — группировка данных в батчи для эффективной обработки на видеокарте. Дело в том, что в батче для акустической модели все аудиофайлы должны быть одинаковой длины. Поэтому их приходится выравнивать, добавляя к более коротким дорожкам нули. А они точно так же попадают в акустическую модель и занимают ресурсы видеокарты. Получается, что из-за выравнивания короткие сообщения распознаются дольше и дороже.
Совсем избавиться от лишних нулей невозможно из-за вариативности длины записей, но можно сократить их количество. Для этого команда инфраструктуры придумала разбивать длинные аудиосообщения на отрезки по 23–25 секунд, сортировать все дорожки и группировать близкие по длине в небольшие батчи, которые уже в свою очередь отправляются на видеокарты. Разбивка делается с помощью VAD-алгоритма из WebRTC — он позволяет определять паузы и отправлять на распознавание в акустическую модель целые слова, а не их обрывки. Продолжительность в 23–25 секунд вывели экспериментально — с более короткими отрезками проседали метрики качества распознавания, а более длинным чаще требовалось выравнивание.
Подход с разбивкой длинных записей, кроме оптимизации производительности, позволяет нам переводить в текст аудио практически любой длины. А также открывает поле для экспериментов с ASR для других продуктовых задач.
Метрики
Чтобы отслеживать улучшения в нашем решении и сравнивать его с другими, нужно определиться с метриками.
Первая метрика, которая приходит в голову, — смотреть число попаданий по буквам или словам. Но в таком подходе метрика получится не слишком адекватной: если пропустить одну букву, то всё, что идёт дальше и распознано верно, будет считаться неправильным.

Есть модифицированный вариант этой наивной метрики. Он вычисляет минимальную длину цепочки из операций удаления, вставки и замены символов — той, которую необходимо пройти, чтобы получить из одной строки другую. Такая метрика называется character error rate (CER) и вычисляется по формуле:

где S — число замен (substitutions), D — число удалений (deletions), I — необходимых вставок (insertions), N — символов в исходной строке.
Если смотрим на замены не по символам, а по словам, то такая метрика называется word error rate (WER). WER вычисляется так же, как и CER, но N равно числу слов.
На датасете common voice WER нашей модели составил 9,5. Такая разница, вероятно, связана с тем, что мы оставляем небольшой вес у языковой модели, чтобы уметь распознавать сленг и слова, которые редко используются.
Текущее решение целиком
В июне 2020-го мы запустили в прод распознавание голосовых длительностью до 30 секунд (в них укладывается 90% всех таких сообщений). Потом оптимизировали работу сервиса, сделали умное распиливание дорожки — с ноября 2020-го распознаём двухминутные сообщения (это 99% от всех голосовых), с весны 2021-го любые сообщения до 60 минут и совсем недавно добавили расстановку больших букв. При этом инфраструктура готова для будущих проектов и позволяет обрабатывать и многочасовые аудиофайлы.
Конечно, с момента запуска год назад многое поменялось: мы обновили архитектуру акустической модели и языковую модель, добавили шумоподавление.
Сейчас весь пайплайн для аудиосообщений выглядит так:
Получаем на вход аудиодорожку, предобрабатываем её.
Если длина дорожки больше 25 секунд, то распиливаем её при помощи VAD на фрагменты по 23–25 секунд — так, чтобы слово случайно не разделилось на части.
Далее все фрагменты подаются в акустическую модель (основанную на QuarzNet) и языковую (использующую n-граммы).
Затем все кусочки склеиваются и попадают в модель пунктуации/капитализации с нашей собственной архитектурой. Причём перед этим этапом мы также разбиваем слишком длинные тексты, но на этот раз по 400 слов.
Склеиваем и отдаём пользователю текстовую расшифровку, которую он может быстро прочитать когда и где угодно — и сэкономить время.

Всё это вместе образует уникальный сервис: он не просто может распознавать разговорную речь, сленг, мат и новые слова в шумных условиях, но и делает это быстро и эффективно. Перцентили по времени полной обработки сообщений (не учитывая загрузку и отправку клиенту):
95 перцентиль — 1,5 секунды;
99 перцентиль — 1,9 секунды;
99,9 перцентиль — 2,5 секунды.
Количество отправленных ВКонтакте аудиосообщений за год выросло на 24%. 33 млн человек ежемесячно слушают и надиктовывают голосовые. Для нас это значит, что речевые технологии востребованы нашими пользователями и стоит вкладываться в разработку новых решений.
Сейчас наша небольшая команда продолжает эксперименты с архитектурой, пробуя себя вне сленгового домена. А ещё мы примеряем свой опыт и модели к смежным задачам: например, для voice conversion и автоматической генерации субтитров.
Возможности и перспективы ASR очень разнообразны. При этом чтобы оценить перспективы его внедрения в свой продукт, не обязательно иметь большой штат учёных. Можно для начала попробовать нафайнтюнить open-source решения под свои задачи, а уже потом браться за собственные исследования и создавать новые технологии.
