Несмотря на масштабный переход к цифровым технологиям, часть наиболее сложных данных по-прежнему хранится в виде текста в статьях или официальных документах. В условиях изобилия публично доступной информации возникают трудности с управлением неструктурированными сырыми данными и их преобразования в понятный для машин вид. С текстом это сделать сложнее, чем с изображениями и видео. Возьмём для примера простое предложение: "They nailed it!". Люди бы поняли его как выражение одобрения, подбадривания или признания заслуг, однако традиционная модель обработки естественного языка (Natural Language Processing, NLP), скорее всего, воспримет только поверхностное понимание слова, упустив смысл. А именно, она бы ассоциировала слово "nail" с забиванием гвоздей молотком. Точные аннотации текста помогают моделям лучше понимать передаваемые им данные, что приводит к безошибочной интерпретации текста.
Что такое аннотирование текста?
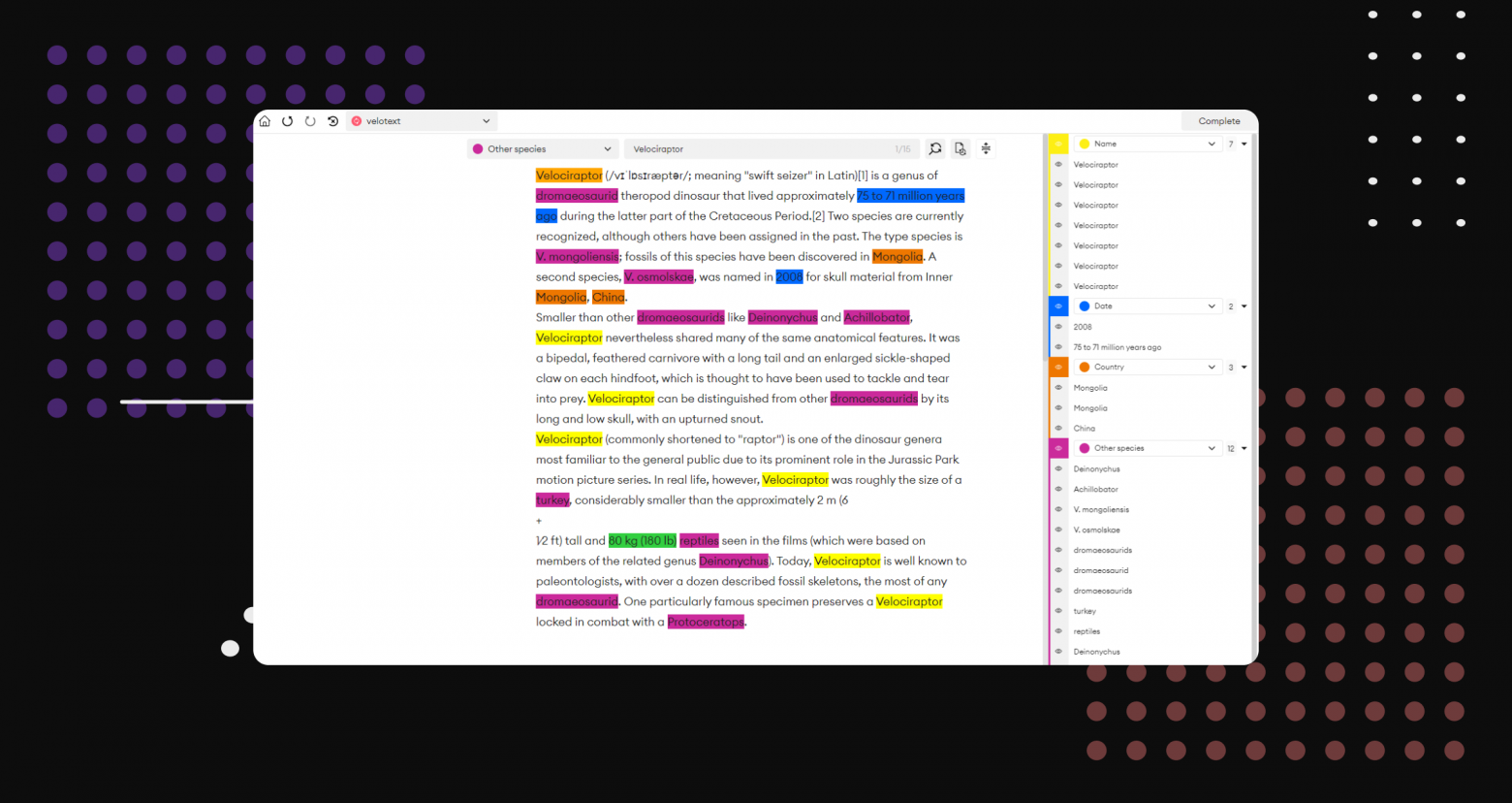
Аннотирование текста — это процесс разметки текстового документа или различных элементов его содержимого. Какими бы умными ни были машины, человеческий язык иногда бывает сложно расшифровать даже самим людям. При аннотировании текста составляющие предложений или структуры выделяются по определённым критериям для подготовки наборов данных к обучению модели, которая сможет эффективно распознавать человеческий язык, коннотацию или эмоции, стоящие за словами.
Почему это важно?
Зачем мы вообще аннотируем текст? Последние прорывы в сфере NLP выявили нарастающую потребность в текстовых данных для таких областей, как страхование, здравоохранение, банковское дело, телекоммуникации и так далее. Аннотирование текстов необходимо, поскольку оно гарантирует, что целевая считывающая система, в данном случае — модель машинного обучения (ML), сможет воспринимать предоставленную информацию и делать выводы на её основе. Ниже мы подробнее рассмотрим конкретные способы использования, а пока вам следует помнить то, что текстовые данные всё равно остаются данными, почти как изображения или видео, и они так же используются для обучения и тестирования.
Как аннотируется текст: аннотирование текстов для NLP
Список задач, которые учатся выполнять компьютеры, стабильно растёт, однако некоторые области остаются нетронутыми: NLP не является в этом исключением. Без аннотаторов-людей модели не поймут глубины, естественности и сленга, при помощи которых люди управляют и манипулируют языком. Поэтому компании постоянно пользуются помощью живых аннотаторов для обеспечения достаточного качества данных для обучения. К современным ИИ-решениям на основе NLP относятся голосовые помощники, машинные переводчики, умные чат-боты, альтернативные поисковых движки, и список систем продолжает расширяться параллельно с повышением гибкости, обеспечиваемой типами аннотирования текста.
Аннотирование текста для распознавания текста
Визуальное распознавание текста (optical character recognition, OCR) — это извлечение текстовых данных из отсканированных документов или изображений (PDF, TIFF, JPG) в понимаемые моделью данные. Системы OCR предназначены для упрощения доступности информации пользователям. Они помогают в ведении бизнеса и в рабочих процессах, экономят время и ресурсы, которые были бы необходимы для управления данными. После преобразования обработанная OCR текстовая информация может более удобно и просто использоваться компаниями. Достоинствами распознавания текста являются отсутствие необходимости ручного ввода данных, снижение ошибок, повышение продуктивности и т.д.
Подробнее об OCR и областях его применения мы поговорим в отдельной статье. А пока главный вывод будет таким: OCR вместе с NLP — две основные области, сильно зависящие от аннотирования текста.

Типы аннотирования текста
Наборы данных аннотирования текста обычно представлены в виде выделенного или подчёркнутого текста, по краям которого оставлены заметки. В этом посте мы рассмотрим следующие основные типы аннотирования текста:
Аннотирование сущностей
Аннотирование сущностей служит для разметки неструктурированных предложений важной информацией; часто оно применяется в наборах данных для обучения чат-ботов. Этот тип аннотирования можно описать как нахождение, извлечение и разметка сущностей в тексте одним из следующих способов:
Распознавание именованных сущностей (named entity recognition, NER): NER лучше всего подходит для разметки в тексте ключевой информации, будь то люди, географические точки, часто встречающиеся объекты или персонажи. NER является фундаментальной основой NLP. Google Translate, Siri и Grammarly — прекрасные примеры NLP, использующего NER для понимания текстовых данных.
Разметка частей речи: как понятно из названия, разметка частей речи помогает парсить предложения и распознавать грамматические единицы (существительные, глаголы, прилагательные, местоимения, наречия, предлоги, союзы и т.п.).
Разметка ключевых фраз: этот способ можно описать как поиск и разметку ключевых слов или фраз в текстовых данных.
Хотя аннотирование сущностей является сочетанием распознавания сущностей, частей речи и ключевых фраз, оно часто идёт рука об руку с сопоставлением сущностей, что помогает моделям в более глубокой контекстуализации сущностей.
Сопоставление сущностей
Если аннотирование сущностей помогает находить и извлекать сущности из текста, то сопоставление сущностей, часто называемое сопоставлением именованных сущностей (named entity linking, NEL) — это процесс соединения этих именованных сущностей с более крупными наборами данных. Возьмём для примера предложение "Summer loves ice cream". Задача заключается в том, чтобы определить, что Summer — это имя девушки, а не время года или любая другая сущность, которую потенциально можно назвать Summer. Сопоставление сущностей отличается от NER тем, что NER находит именованную сущность в тексте, но не указывает, что это за сущность.
Классификация текста
Задача аннотирования сущностей заключается в аннотировании конкретных слов или фраз, а задача классификации текста — в аннотировании фрагмента текста или строк одной меткой. Примерами и специализированными типами классификации текста являются классификация документов, разбиение продуктов на категории, аннотирование эмоционального настроя текста и так далее.
Классификация документов: присвоение документу одной метки может быть полезным для интуитивной сортировки больших объёмов текстового содержимого.
Разбиение продуктов на категории: процесс сортировки продуктов или сервисов на классы и категории может улучшить поисковые результаты для электронной коммерции, например, оптимизировать SEO и повысить видимость продукта на странице ранжирования.
Аннотирование эмоционального настроя
Как понятно из названия, аннотирование эмоционального настроя заключается в определении эмоций или мнений, лежащих в основе текстового блока. Даже нам, людям, иногда сложно определить значение полученного сообщения, если тексту свойственен сарказм или другие виды языковых манипуляций. Представьте, что определять его приходится машине! За кулисами этого явления находится аннотатор, внимательно анализирующий текст, выбирающий метку, лучше всего описывающую эмоцию, настрой или мнение. Затем компьютеры могут основывать свои выводы на схожих данных, чтобы различать положительные, нейтральные или отрицательные отзывы, а также другие виды текстовой информации. В свете своей применимости анализ эмоционального настроя помогает компаниям разрабатывать стратегии позиционирования своего продукта или услуги и их дальнейшего отслеживания.
Способы применения аннотирования текста
Способы применения аннотирования текста почти столь же повсеместны, как и способы применения аннотирования изображений и видео. Почти каждая область, содержащая текстовые данные, может быть аннотирована и использована для обучения модели:
Здравоохранение
Аннотирование текста меняет правила игры в здравоохранении, где оно заменяет кропотливые ручные процессы высокопроизводительными моделями. В частности, оно влияет на следующие операции:
- Автоматическое извлечение данных из отчётов о клинических испытаниях, а также классификация медицинских документов для улучшения доступа и упрощения исследований.
- Повышение результатов излечения пациентов благодаря тщательно анализируемым медицинским картам и улучшению распознавания патологических состояний.
- Выявление пациентов с медицинской страховкой, расчёт сумм потерь и другая информация страхователя для ускоренной обработки требований.

Страхование
Как и в здравоохранении, в области страхования аннотирование текста обеспечивает множество преимуществ.
- Оценка рисков и извлечение контекстуальных данных из договоров и форм.
- Распознавание сущностей, например, вовлечённых сторон и сумм потерь для ускорения обработки требований.
- Обнаружение мошеннических требований и мониторинг документов и форм для выявления сомнительных требований.
Банковское дело
Повышение персонализации, улучшение автоматизации, снижение ошибок и адекватное использование ресурсов — всё это становится возможным благодаря модели, способной выполнять следующие задачи:
- Выявление паттернов мошенничества и отмывания денег.
- Упрощение рабочих процессов благодаря извлечению данных из договоров и управлению ими.
- Извлечение кредитных ставок, рейтингов кредитоспособности или других атрибутов для мониторинга соответствия.
Телекоммуникации
Аннотированный текст автоматизирует человеческий труд в следующих областях:
- Оптимизация производительности сетей и точное прогнозирование проблем.
- Автоматизированные ответы на запросы клиентов, в том числе через чат и электронную почту.
- Подробный анализ сетевых взаимодействий.
- Понимание настроя и эмоций клиента для улучшения качества поддержки.
- Распознавание злонамеренных действий.
- Персонализированная реклама и создание продуктов на основании анализа поведения клиентов.
В заключение
Аннотирование текста продолжает оставаться желанной целью в большинстве сложных проектов аннотирования. В условиях разнообразия типов и возникающих новых способов применения аннотирование текста предоставляет моделям способность читать, осознавать и реагировать на информацию подобно человеку.
Понравилась статья? Еще больше информации на тему данных, GenAI, ML, LLM вы можете найти в моем Telegram канале
- Как проектировать и считать экономику AI-агентов для бизнеса
- Какие данные нужны для обучения GenAI моделей
- Почему бенчмарки лгут и как правильно оценить LLM для ваших бизнес-задач

