Обычный, теневой, виртуальный, инкрементальный… Как получилось, что простой программный интерфейс доступа к элементам веб-страниц обзавелся таким количеством «родственников»? Чем современные фреймворки не устраивает стандартная объектная модель документа или просто DOM? Что и как на самом деле отрисовывает браузер в процессе рендера веб-страницы?
Всем привет, это Макс Кравец из Holyweb. Помните сцену из Матрицы, в которой один из юных кандидатов в Избранные наставляет Нео: «Не пытайся согнуть ложку. Первое, что ты должен понять — ложки не существует!»? Давайте переформулирую: «Не пытайся изменить DOM...». А вот о том, что прячется под многоточием, мы сегодня и поговорим.

Фундамент. Как строится веб-страница. CRP
Придется начать с самого начала — разобраться с процессом преобразования исходного HTML в содержимое страницы, который называют Critical Rendering Path (критический путь рендеринга).
Построение дерева DOM
Получив с сервера документ, парсер браузера каждый тег превращает в узел и строит их иерархию
<html> <head> <link rel="stylesheet" href="style.css"> </head> <body> <h1>Давай построим DOM</h1> </body> </html>
В результате получается дерево узлов (node), или просто DOM-дерево, в котором вложенные элементы представлены в виде дочерних узлов с полным набор атрибутов:
html head link rel="stylesheet" href="style.css" body h1 Давай построим DOM
Исторически-лирическое отступление. Когда все только задумывалось, страницы рендерились из статики, каналы связи были неторопливыми, а пользователи — непритязательными. Документ мог грузиться довольно долго и практически не изменялся за время жизни в браузере. Для того, чтобы страница как можно скорее отвечала на действие пользователя, любое изменение DOM автоматически запускало процесс повторного рендеринга страницы.
Но ведь добавление очередного узла в DOM в процессе парсинга — это тоже изменение? Так и есть. Стоит узлу попасть в объектную модель документа — страница перерисовывается. До сих пор! На практике это означает, что документ отрисовывается по частям, браузер даже не дожидается окончания загрузки. Пользователи интернета со стажем помнят, как это выглядело. Ну а сегодня можно в инструментах разработчика поставить качество связи Slow 3G на вкладке network и насладиться загрузкой какой-либо статической страницы.
Нам как разработчикам важен сам факт — любое изменение физического DOM требует перерисовки страницы, а значит — времени и ресурсов.
Построение CSSOM-дерева
Хорошо, верстку мы получили, надо сделать ее красивой. Пробежимся по полученному ранее DOM и добавим каждому узлу соответствующие стили. Говоря языком документации — сформируем CSS object model или CSSOM.
Если в примере выше в файле style.css будет
body { font-size: 16px; } h1 { font-size: 20px; }
то соответствующее CSSOM дерево будет выглядеть следующим образом:
html head link rel="stylesheet" href="style.css" body font-size: 16px h1 font-size: 20px Давай построим DOM
Еще одно отступление. CSS недаром называют Cascading Style Sheets — каскадными таблицами стилей. Чтобы применить стиль для конкретного узла, необходимо его посчитать, разобрав полностью всю таблицу стилей документа. Следовательно — на это время процесс рендера нужно приостановить.
CSS является блокирующим ресурсом. Причем не только для верстки, но и для скриптов, которые также вынуждены дожидаться построения CSSOM для того, чтобы начать выполняться.
На практике это означает, что мы должны учитывать время, которое нужно для построения CSSOM при написании своего кода.
Хорошая новость — CSS блокирует рендер только при применении. Стили, указанные с помощью медиа-атрибута для мобильного разрешения, не являются блокирующими (и не разбираются) при рендере десктопной версии и наоборот, а стили для ландшафтной ориентации устройства не участвуют в рендере для портретной.
Плохая новость — изменение размера окна браузера или поворот мобильного из одной ориентацию в другую может вызвать срабатывание медиа-атрибута и блокировку рендера страницы для пересчета CSS. Если забыть про этот нюанс, можно потерять немало времени на поиск ошибок не в том месте.
Запуск JavaScript
Ура, добрались! JavaScript — это наша альфа и омега, именно с его помощью мы делаем веб-страницы интерактивными — такими, к каким привык современный пользователь. Но за счет чего мы это делаем? За счет изменения DOM и стилей.
Стоп, скажете вы! И будете правы — именно стоп. Когда парсер доходит до тега <script>, разбор документа блокируется до тех пор, пока скрипт не будет полностью прочитан и выполнен.
Поскольку JS требуется ссылаться на какой-либо существующий элемент, код скрипта или ссылка на JS-файл должны располагаться в документе после объявления соответствующего элемента.
Если скрипт требуется разместить в начале документа (например, код счетчика систем аналитики) — можно загрузить его асинхронно, указав атрибут async. Это позволит не блокировать рендер страницы. При этом надо понимать, что выполнение самого кода начнется только после окончательной загрузки скрипта. Если же код необходимо запустить только после того, как документ будет полностью разобран, можно использовать атрибут defer
Создание Render-дерева
А как быть со служебной информацией, например, с метаданными — их-то показывать пользователю не требуется, а в DOM они присутствуют? Давайте скроем «ненужное» и соберем для рендера дерево только из тех элементов, что должны быть видны на странице! Заодно избавимся от узлов, спрятанных CSS, например, через правило display: none.
Полученный результат так и назовем: Render-дерево. То есть совокупность DOM и CSSOM, включающая в себя только видимый контент — то, что в конечном итоге будет отображено на странице.
html body font-size: 16px h1 font-size: 20px Давай построим DOM
Генерация раскладки
Кажется, все готово? Почти! Осталось разобраться с масштабом, а точнее с размером видимой области документа (viewport). Это нужно для того, чтобы рассчитать стили, заданные в относительных величинах, таких как проценты или единицы vh и vw.
<meta name="viewport" content="width=device-width,initial-scale=1">
Код выше устанавливает ширину видимой области в соответствии с шириной устройства, что используется в большинстве случаев. Если тег явно не указан, то используется стандартное значение в 980 пикселей.
Отрисовка
Вот теперь точно все. И к этому моменту мы уже понимаем, что влияет на скорость рендера страницы — размер DOM и сложность примененных стилей.
Первый этаж. Что же такое DOM
В принципе, все вышеизложенное есть в документации. Но теперь, когда мы освежили воспоминания, проще будет разобраться с дальнейшим.
Для начала, давайте разделим DOM и HTML. Несмотря на то, что первый строится на базе второго, они вовсе не идентичны. Причин две: человеческий фактор и JavaScript.
Первое — скорее «защита от дурака». Если верстальщик ошибется или забудет закрыть какой-то тег, браузер постарается все исправить. Не из альтруизма, конечно — ему важно, чтобы модель данных оставалась корректной.
<!doctype html> <html> <h1>Давай построим DOM </html>
Верстка выше не содержит обязательные для HTML теги <head> и <body>, кроме того, мы «забыли» закрыть <h1>. Но если мы посмотрим в инструменты разработчика, то увидим что браузер все исправил.
<html> <head></head> <body> <h1>Давай построим DOM</h1> </body> </html>
html head body h1 Давай построим DOM
Второй вариант, когда DOM отличается от исходного документа, — гораздо ближе к теме современной веб-разработки. Чем занимается любой фронтенд-фреймворк? Изменяет DOM!
Так что же такое DOM? Во-первых, это программный интерфейс доступа к элементам HTML-документа. Он представляет собой валидную модель данных (исправлены ошибки), которая может быть изменена с помощью JavaScript (в современных реалиях скорее не «может быть», а просто изменена).
Еще одно исторически-лирическое отступление. Когда компьютеры были большими, а веб маленьким, мало кто мог представить, что писать код для одной страницы будут десятки людей из разных стран. Про встраивание сторонних модулей не слышали, виджетов не видели. Древние, в общем, разработчики были. И мудрые. По-своему. Сделали глобальную область видимости для всего браузера — им так было удобнее.
Плюсами такого решения мы пользуемся до сих пор, с легкостью добираясь до любого элемента html-документа вне зависимости от того, насколько глубоко он вложен. Не менее полезна и возможность задавать или править глобально стили, например, для нормализации значений по умолчанию всего документа или задания дефолтного поведения
* { box-sizing: border-box }
Но за все приходится платить. Отсутствие возможностей изоляции в DOM вынуждает «костылить» префиксы в именах классов или придумывать многоэтажные системы именования, чтобы избежать пересечений. Все это в конечном итоге увеличивает и размеры файлов, и сложность работы с ними. А значит, заставляет искать другое решение.
Что за дом без веранды? Пристроим Shadow DOM
Для того, чтобы избавиться от глобальной области видимости, есть всего два принципиальных решения: создать «документ внутри документа», или «DOM внутри DOM».
Примечание: грустную историю о болях корректного встраивания нескольких iframe на странице не пропустила самоцензура, так что сразу перейдем к варианту номер два.
Знакомьтесь: Shadow DOM — изолированное дерево со своими элементами и стилями, которые не зависят от исходного документа.
Изначально оно потребовалось самим браузерам для того, чтобы спрятать «начинку» UI-примитивов — кнопок, инпутов, селекторов и так далее. Но как только этот инструмент попал в открытый доступ, то есть стал частью спецификации, его оценили и простые веб-разработчики. Хотя бы как удобный способ создания собственных универсальных элементов.
<html> <head></head> <body> <my-component></my-component> </body> </html>
Все, что для этого нужно, — задать в верстке элемент-контейнер — произвольный тег (можно воспользоваться стандартным div, а можно задать собственное имя), найти его и прикрепить теневое дерево.
const myComponent = document.querySelector("my-component"); const shadow = myComponent.attachShadow({mode: 'open'});

Страница по-прежнему пуста, но в инспекторе мы видим, что у <my-component> появился #shadow-root. Добавим в теневое дерево верстку
const mainWindow = document.createElement("main-window"); mainWindow.innerHTML = "<p>Play</p>"; shadow.appendChild(mainWindow)
и стили
const styles = document.createElement("style"); styles.textContent = ` main-window { display: flex; width: 200px; height: 100px; background: beige; border-radius: 10px; box-shadow: 0px 6px 10px 0px black; justify-content: center; align-items: center; } `; shadow.appendChild(styles)
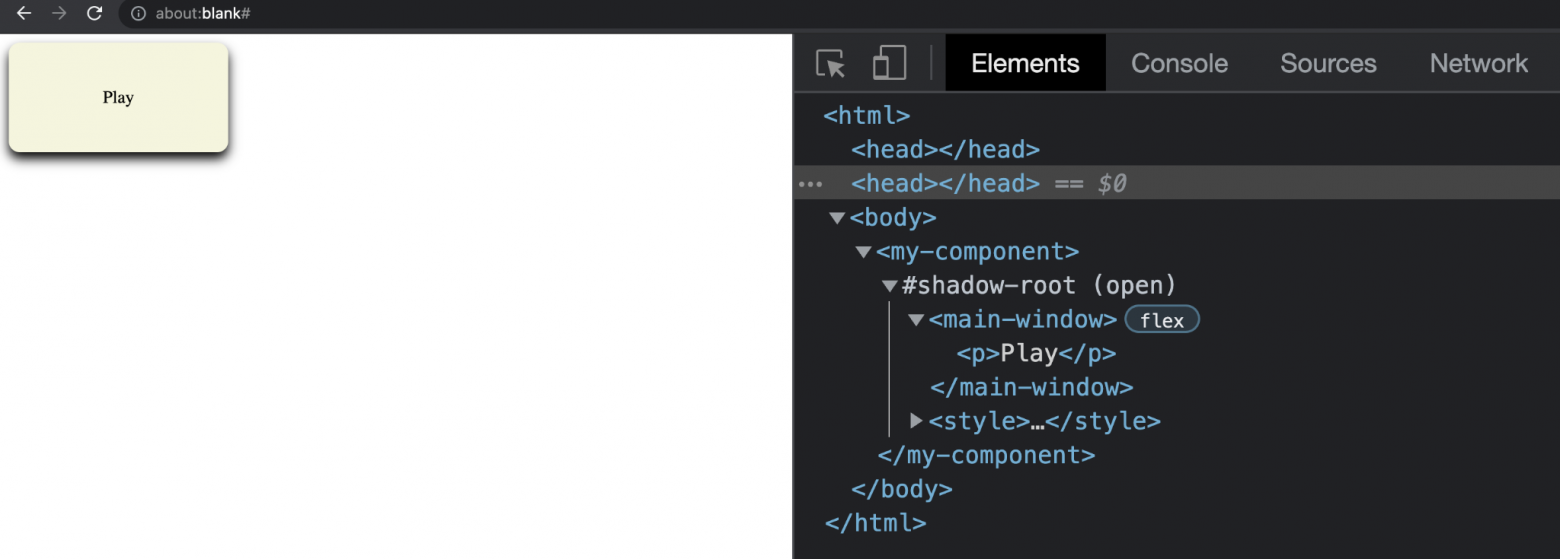
Благодаря созданию отдельного теневого дерева мы обеспечили инкапсуляцию: стили, применяемые внутри Shadow DOM, экранированы от внешней среды, а для методов DOM API создается отдельный контекст.
Что это дает? Возможность использовать одинаковые ID в разных контекстах — мы можем достучаться методами API до нужного нам элемента, но при этом он невидим снаружи для других контекстов.
Легко заметить, что теперь у любого элемента в теории может быть 2 типа поддеревьев DOM: Light tree — обычное DOM-поддерево, состоящее из HTML-потомков, и Shadow tree. Какое из них победит?
Если у элемента имеются оба поддерева, браузер по умолчанию отрисовывает только теневое. Но главная прелесть в том, что служебный тег <slot> позволяет комбинировать Light и Shadow tree. Он дает контроль над размещением непосредственных потомков сложного DOM-элемента в нужном месте и обеспечивает композицию. А следовательно — Shadow DOM можно использовать в качестве шаблона для layout-элементов.
<script> customElements.define('product-card', class extends HTMLElement { connectedCallback() { this.attachShadow({mode: 'open'}); this.shadowRoot.innerHTML = ` <div>Товар: <slot name="product"></slot> </div> <div>Цена: <slot name="price"></slot> </div> `; } }); </script> <product-card> <span slot="product">Велосипед</span> <span slot="price">12000 руб.</span> </product-card> <product-card> <span slot="product">Самокат</span> <span slot="price">2000 руб.</span> </product-card>
В этом примере браузер берет элементы из обычного DOM и отображает их в соответствующих слотах теневого дерева.
Это открывает широкие возможности для создания собственных компонентов. Но как быть, когда хочется расширить возможности стандартных элементов?
Одна из проблем, с которыми приходится сталкиваться при динамическом добавлении CSS-свойств элементу через element.style — невозможно напрямую использовать медиазапросы или определить псевдоклассы и псевдоэлементы. Shadow DOM дает доступ к элементу контейнеру через селектор ::host
let myElement = document.querySelector('div'); myElement.attachShadow({ mode: 'open', }); myElement.shadowRoot.innerHTML = ` <style> :host(:hover) { color: blue; } </style> <slot></slot> `;
Мы «подцепили» условному div-у реакцию на наведение мыши, при этом не создавали новые классы и не изменяли внешние стили.
Остается отметить, что теневых DOM на странице может быть неограниченное количество, а каждому корню теневого DOM должен соответствовать элемент в обычном DOM, который будет являться базовым хостом.
Ограничения Shadow DOM:
создается только с помощью JS, а потому не существует возможности предварительного рендера (SSR). Данное ограничение можно обойти, но это тема для другой статьи
Требует внешнего контроля жизненного цикла компонентов и их инициализации во внешней среде
Из-за использования сайтами политик безопасности, существуют серьезные ограничения на добавление стилей к элементам внутри теневого DOM. Дело в том, что CSP (Content Security Policy) запрещает парсить стили из строки. Обойти это можно отключением политики безопасности, но при разработке виджета для стороннего сайта это, пожалуй, самое плохое решение. Более универсальные решения — создание динамических стилей через element.style или добавление в Shadow DOM внешнего css-файла
создание Shadow DOM, как и любого другое действие, требует выделения дополнительных ресурсов, а потому злоупотреблять им не стоит
отсутствует поддержка в IE
Беремся за второй этаж. Зачем понадобился Virtual DOM?
На самом деле ответ прост и мы его уже знаем — физический DOM устроен так, что любое его изменение автоматически вызывает перерисовку страницы, а это не всегда нужно.
Представьте, что вам нужно выводить на странице список товаров
<!doctype html> <html lang="en"> <head></head> <body> <ul class="product"> <li class="product__item">Товар</li> </ul> </body> </html>
DOM для такой верстки:
html head lang="en" body ul class="product" li class="product__item" "Товар"
А теперь добавим в список самокат, а дефолтный товар заменим на велосипед. Для этого надо найти в DOM список, создать новый элемент, добавить в него контент, обновить контент в старом элементе списка, после чего обновить сам DOM
const productItemOne = document.getElementsByClassName("product__item")[0]; productItemOne.textContent = "Велосипед"; const productItemTwo = document.createElement("li"); productItemTwo.classList.add("product__item"); productItemTwo.textContent = "Самокат"; const product = document.getElementsByClassName("product")[0]; product.appendChild(productItemTwo);
При этом каждый раз, когда мы «дергаем» DOM API — запускается алгоритм пересчета изменений и рендера страницы.
Откровенно говоря, проще заменить старый именованный список на новый
const product = document.getElementsByClassName("product")[0]; product.innerHTML = ` <li class="product__item">Велосипед</li> <li class="product__item">Самокат</li> `;
В этом варианте мы выполнили всего одно обращение к DOM и единожды отрисовали страницу заново. А значит — выиграли в производительности.
Хочу такой же, но с перламутровыми пуговицами!
Как этого добиться? Сделать «копию» DOM, выполнить все нужные преобразования, и только когда все посчитано — обновить реальный DOM. Поздравляю, мы только что сформулировали основную идею Virtual DOM.
Давайте сформулируем и реализацию. В качестве копии — воспользуемся самым обычным JS-объектом. Для нашего примера со списком продуктов его можно представить как
const vdom = { tagName: "html", children: [ { tagName: "head" }, { tagName: "body", children: [ { tagName: "ul", attributes: { "class": "product" }, children: [ { tagName: "li", attributes: { "class": "product__item" }, textContent: "Товар" } ] } ] } ] }
Первый плюс мы уже получили — нет нужды лишний раз перерисовывать страницу. А значит, уже выиграли в производительности.
Второй плюс вытекает из самого факта того, что мы работаем с объектом. Мы избавились от необходимости постоянно обращаться к громоздкому браузерному API. Ставим еще плюсик в производительность.
Но можно ли еще как-то усовершенствовать идею? Конечно! в DOM у нас складывается весь документ целиком, и его копия — довольно большой объект. Из которого нам в нашем случае нужен всего лишь один компонент!
Давайте сделаем следующий шаг: создадим для каждого компонента свой объект и будем работать с ними, как с некими разделами Virtual DOM.
const product = { tagName: "ul", attributes: { "class": "product" }, children: [ { tagName: "li", attributes: { "class": "product__item" }, textContent: "Товар" } ] };
Мы еще на порядок упростили работу с конкретным компонентом и вновь выиграли в производительности, поскольку взаимодействуем с небольшим объектом, а не с копией всего DOM в целом.
Как работает виртуальный DOM
Вернемся к нашему примеру и проделаем те же операции. Поскольку API браузера нас больше не ограничивает, мы просто создадим новый объект
const copy = { tagName: "ul", attributes: { "class": "product" }, children: [ { tagName: "li", attributes: { "class": "product__item" }, textContent: "Велосипед" }, { tagName: "li", attributes: { "class": "product__item" }, textContent: "Самокат" } ] };
и сравним исходный product и новый copy, выделив изменения.
const diffs = [ { newNode: { /* textContent: "Велосипед" */ }, oldNode: { /* textContent: "Товар" */ }, index: /* index of element in parent's nodes */ }, { newNode: { /* textContent: "Самокат" */ }, index: { /* */ } } ]
Остается пройтись циклом по диффам, обновить старые или добавить новые элементы
const domElement = document.getElementsByClassName("product")[0]; diffs.forEach((diff) => { const newElement = document.createElement(diff.newNode.tagName); if (diff.oldNode) { domElement.replaceChild(diff.newNode, diff.index); } else { domElement.appendChild(diff.newNode); } })
Создать новый объект, посчитать его разницу с предыдущим и точечно обновить элементы — намного быстрее, чем добавить на страницу новую строку с версткой, вызвав тем самым ее полный пересчет и перерисовку.
Давайте подведем промежуточный итог. Мы сформулировали принципиальную идею отказаться от работы непосредственно с DOM, пришли к тезису что удобнее работать с отдельным объектом для каждого компонента и предусмотрели механизм, который позволяет запустить рендер страницы. Разумеется, это не production версия Virtual DOM, а только объяснение принципа его работы. В зависимости от того, какой фреймворк вы используете (и даже от его версии) — детали реализации могут отличаться.
Virtual DOM — это объектное представления JavaScript, которое позволяет взаимодействовать с элементами DOM более простым и производительным способом. Объект-представление можно изменять так часто, как это необходимо, после завершения вычислений вызывается механизм сравнения изменений. В реальный DOM вносятся только финальные изменения, что происходит намного реже, не требует большого количества обращений к API браузера и, следовательно, повышает производительность.
Для тех, кто готов достроить третий этаж
Дошедшим до этого раздела уже должно быть понятно, почему современному фронтенд-разработчику не стоит пытаться «согнуть ложку», а точнее — пытаться общаться с DOM напрямую. Для этого есть более производительный и удобный Virtual DOM, предоставляемый фреймворками.
Но постойте, браузер-то умеет работать только со своим API, а наши компоненты — только с Virtual DOM. Нужен движок, «переводчик» пожеланий компонентов в инструкции, понятные браузеру. И этот движок мы должны загрузить в браузер вместе с самими компонентами.
Как уменьшить размер бандла?
Проблема в том, что на этапе компиляции мы не знаем, какие инструкции на самом деле нужны, а какие нет, а потому приходится загружать все.
Это не так страшно, если приложение не очень большое, а ресурсов компьютера достаточно. Но когда речь заходит о мобильных устройствах, размер бандла и требуемые объемы памяти становятся критически важными параметрами.
Давайте предложим компонентам обращаться не к движку рендеринга, а непосредственно к инструкциям. Пусть каждый компонент заранее определится, какие ему нужны, тогда на этапе компиляции приложения можно будет отсеять невостребованные.
Таким образом решается задача tree-shakable — уменьшения размера сборки, которая загружается в браузер за счет удаления неиспользуемых фрагментов кода.
Поговорим о потреблении памяти
Давайте еще раз посмотрим, как Virtual DOM осуществляет рендеринг. На первом шаге мы на базе реального DOM строим виртуальное дерево, следовательно — для каждого элемента нам нужно выделить какой-то объем памяти. Когда приходит время отрисовать новое состояние, мы строим новое виртуальное дерево, а значит — для каждого элемента повторно выделяется нужный объем памяти. Далее старое и новое виртуальные деревья сравниваются, и если есть разница — изменения применяются к физическому DOM.
Получается, что на каждом этапе рендера нам требуется повторно выделять память в размере, необходимом для того, чтобы отрисовать дерево целиком.

И снова — повод задуматься. Если у нас на какой-то момент времени есть существующее актуальное состояние DOM уже отрисованное браузером, и изменяется только один элемент — зачем нам строить новое виртуальное дерево целиком? Что, если можно было бы пробежаться по старому и взять из него для построения нового те элементы, которые не изменились? Тогда нам потребуется дополнительно выделять память только в случае создания нового узла или изменения старого.
Этот алгоритм реализует небольшая (всего 2,6 КБ) библиотека под названием Incremental DOM.
Здравый вопрос — почему же тогда этот вариант до сих пор используется не всеми? Из «большой тройки» фреймворков, Incremental DOM применяется только в Angular, а React и Vue предпочитают старый добрый Virtual DOM.
Все дело в том, что Angular — единственный фреймворк большой тройки, изначально построенный на архитектуре с использованием template, когда все компоненты пишутся с использованием шаблонов. Посмотрим на пример функции renderPart() из документации библиотеки Incremental DOM
function renderPart() { elementOpen('div'); text('Hello world'); elementClose('div'); }
и мысленно подставим на место elementOpen() и elementClose() — selector компонента Angular, а на место text() — template.
function renderPart() { elementOpen('some-component'); text(` … some template html `); elementClose('some-component'); }
Для тех, кто добрался до финала
Пришло время подводить итоги и разобраться с многоточием, которое было поставлено во вступлении.
Не пытайся изменить DOM… без причины. Первое, что нужно понять: DOM существует. Но его задача — обеспечить отрисовку страницы, заранее подготовленной с помощью других инструментов. Таких, как Shadow, Virtual и Incremental DOM. И современный разработчик должен знать, в чем они схожи, чем отличаются и как выбрать наиболее подходящее решение для конкретной задачи.
Если есть чем дополнить — комментарии можно оставлять под текстом или мне в телеграм.
Другие наши статьи:

