
В этой заметке рассмотрим процесс обмена данными между двумя процессорами 1967BH028 через интерфейс LVDS с использованием каналов DMA. А также вкратце ознакомимся с особенностями организации системы вызова прерываний в этом процессоре и задействуем прерывание по завершению работы канала DMA. Данная статья является продолжением статьи https://habr.com/ru/post/582110/.
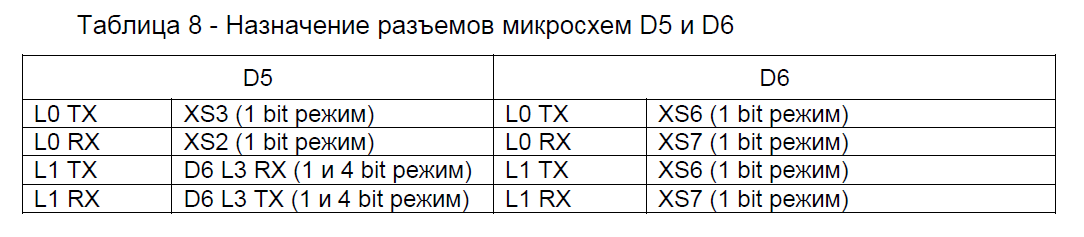
Для начала обратимся к уже известной по прошлому моему обзору табличке, описывающей к каким разъемам DVI выведен какой из LINK портов (он же LVDS порт).

И к табличке с описанием допустимых соединений для LINK портов обоих размещенных на плате процессоров.
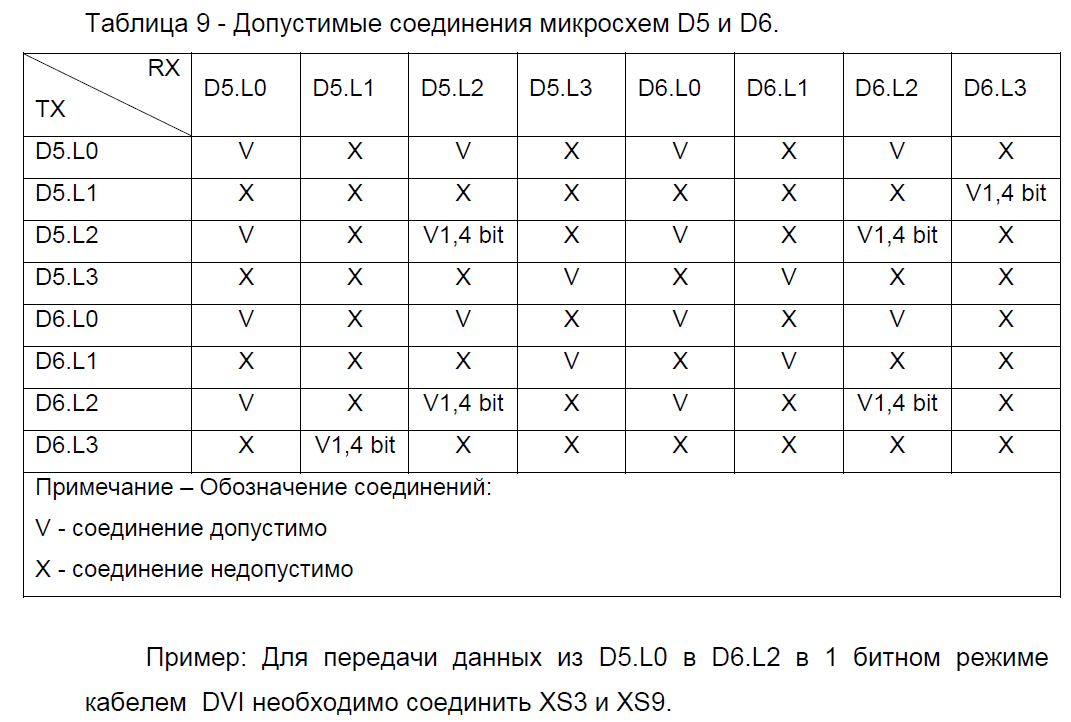
Для начала выберем между однобитным и четырех битным форматом приёма/передачи. Сразу определимся, что брать от жизни стоит все до чего дотягиваются руки и исходя из этого соображения обмен данными будем осуществлять в формате 4 бит. Следовательно, в таблице допустимых соединений у нас отпадают варианты поддерживающие только однобитную передачу. Процессором D6 будем принимать через приемник второго порта, а процессором D5 будем слать данные через передатчик также второго порта. Как видим из таблички такой вариант соединения допустим. Для реализации физического соединения этих портов соединим DVI кабелем разъемы XS4 и XS9 исходя из информации в первой приведенной табличке. Теперь можно переходить к написанию кода.
Код для передатчика будет следующим:
Для начала объявим массив который будет содержать передаваемые данные - arrt
#include <defts201.h> .SECTION /DOUBLE64 /CHAR32 .data; .ALIGN 4; .var arrt[4096];
Далее включим индикацию и заполним массив передачи данными
.SECTION .program; .ALIGN_CODE 4; .GLOBAL _main; _main: SQCTL = 0x1200;;//переход в режим супервизора j0=0x1f;; FLAGREG=j0;; //включим индикацию j0=arrt;; //заполняем массив передачи xr0=0;; lc0 = 4096;; wr_tr: [j0+=1]=xr0;; xr0=r0+1;; if nlc0e, jump wr_tr;;
После чего перейдем к настройке передатчика. Включим LINK, дадим лишнее время приемнику подготовиться и включим DMA.
//Включаем линк передатчика j0=(1<<4)+(4<<5);;//формат 4 бит LtCTL2=j0;; lc0 = 10;; dly_p1: if nlc0e, jump dly_p1;; //подождем //включаем j0=1+(1<<4)+(4<<5);; LtCTL2=j0;; lc0 = 1000;; dly_p2: if nlc0e, jump dly_p2;; // дадим приемнику время подготовиться //Настраиваем и включаем DMA передатчика xr0=arrt;; xr1=0x4000004;; //передаем 1024 4-байтных слова xr2=0;; xr3=0x40000000/*выбираем внутреннюю память*/+ (6<<19)/*выбираем номер порта линк и направление */ + (3<<25) /*ставим длину данных */ q[j31+task_T]=xr3:0;; dc6=xr3:0;;
Далее провалимся в бесконечный цикл. Буфер передачи мы сделали в 4 раза больше чем передаем данных, это пригодится нам для имитации потока данных больше приемного буфера.
Теперь приемник.
Объявляем два массива приема. Второй массив также пригодится для отработки приема данных в режиме автобуфера, но сначала отработаем однократный прием.
#include <defts201.h> .SECTION /DOUBLE64 /CHAR32 .data; .ALIGN 4; //Буфер приема из двух частей .var arrr[1024]; .var arrr1[1024];
Далее произведем для приемника операции аналогичные тем, что мы произвели для передатчика.
.SECTION .program; .ALIGN_CODE 4; .GLOBAL _main; _main: SQCTL = 0x1200;;//переход в режим супервизора j1=0x5f;; FLAGREG=j1;; //включим индикацию //чистим буферы j1=arrr;; j2=arrr1;; xr0=0;; lc0 = 1024;; wr_res: [j1+=1]=xr0;; [j2+=1]=xr0;; if nlc0e, jump wr_res;;
Включим LINK порт и затем DMA, после чего провалимся в бесконечный цикл
//Включаем линк приемника j1=(1<<4);;//формат 4 бит LRCTL2=j1;; lc0 = 10;; dly_p1: if nlc0e, jump dly_p1;nop;nop;; j1=1+(1<<4);; LRCTL2=j1;; //настраиваем и включаем DMA приемника xr0 = arrr1;; xr1=0x4000004;; xr2=0;; xr3=0x40000000/*выбираем внутреннюю память*/+(2<<19)/*выбираем номер порта линк и направление */ +(1<<24)/*разрешаем прерывание по завершению работы канала */ +(3<<25) /*ставим длину данных */ dc10=xr3:0;; _main_loop: nop;nop;nop;; nop;nop;nop;; nop;nop;nop;; nop;nop;nop;; nop;nop;nop;; nop;nop;nop;; jump _main_loop;nop;; _main.end:
Запустим и посмотрим, что получилось. Как видно в процессе отладки данные успешно загрузились.

Теперь стоит отработать вариант с непрерывным потоком данных, ведь очень часто мы не можем прогнозировать сколько конкретно данных надо еще принять и к тому же данных от внешнего источника может оказаться больше чем возможно уместить в буфер приема или же это может быть вообще непрерывный поток данных. DMA обычно имеет возможность работы в режиме автобуфера. Тут такая возможность тоже имеется если дать разрешение цепочки. Цепочка разрешается в 22 бите регистра DP входящего в группу настроечных регистров DMA. Разрешение цепочки позволяет по окончанию работы DMA взять по адресу прописанном в первых 18 битах регистра DP. Буфер приема будет у нас состоять из двух частей arrr и arrr1, которые будут по очереди обновляться. Для проверки в передатчике изменим количество передаваемых квадрослов с 1024 на 4096 заменив в его коде:
xr1=0x10000004;;
В приемнике добавим два массива для настройки цепочек.
.var task_R[4]={0,0,0,0}; .var task_R1[4]={0,0,0,0};
Соответственно в приемнике изменим процесс настройки DMA добавив разрешение цепочки и указатель настройки на следующую цепочку. Причем сделаем так чтоб цепочки чередовались. Каждая из цепочек в качестве указателя следующей цепочки содержит адрес другой цепочки. Таким образом загрузка идет то в один буфер то в другой.
//настраиваем и включаем приемник xr0 = arrr1;; xr1=0x4000004;; xr2=0;; xr3=0x40000000/*выбираем внутреннюю память*/+(2<<19)/*выбираем номер порта линк и направление */ +(3<<25) /*ставим длину данных*/ + (1<<22)/* разрешение след приема */ + (task_R/4);; //указатель на след цепочку выравненный по квадрословам q[j31+task_R1]=xr3:0;; xr0 = arrr;; xr3=0x40000000/*выбираем внутреннюю память*/+(2<<19)/*выбираем номер порта линк и направление*/ +(3<<25) /*ставим длинну данных */ + (1<<22)/* разрешение след приема */ + (task_R1/4);; //указатель на след цепочку выравненный по квадрословам q[j31+task_R]=xr3:0;; xr0 = arrr;; dc10=xr3:0;;
Проверим работу. Мы отправляли значения от 0 до 4096, каждый буфер имеет по 1024 места. И как видно из скриншотов ниже конечные значения буферов такие какими должны быть


Также, чтоб понимать, когда очередной буфер закончил заполняться чтоб перейти к его обработке мы можем воспользоваться прерыванием по завершению работы DMA.
Тут стоит сказать несколько слов о работе с прерываниями в процессоре 1967BH028.
Прерывания в данном процессоре организованы отлично от привычной многим схемы, где прерывания при сработке, отсылают в таблицу векторов прерываний расположенную в памяти с нулевого адреса, а в таблице соответственно содержатся уже переходы на обработчики соответствующих прерываний. Здесь таблицы векторов нет как таковой. Зато под каждое прерывание есть отдельный регистр, в который мы и можем положить адрес обработчика. В документации говорится
«…Обработка прерывания начинается в контроллере прерываний. Контроллер прерываний принимает запрос в регистр ILAT, далее смотрит разрешен ли полученный запрос в регистре IMASK. Если прерывание разрешено, анализируется регистр PMASK, который содержит в себе информацию о текущих обрабатываемых прерываниях. Если приоритет поступившего запроса прерывания выше приоритета обрабатываемого прерывания (либо нет обрабатываемых прерываний), контроллер формирует номер прерывания, считывает из таблицы векторов прерываний соответствующее значение адреса процедуры обслуживания прерывания и отсылает всю эту информацию в устройство управления…»
Ниже приведено описание младших регистров ILATL, IMASKL, PMASKL

Затем происходит проверка глобального разрешения прерываний. За это отвечает бит GIE регистра управления SQCTL. Если прерывания разрешены, то мы проваливаемся в обработчик.
Для разбора работы с прерываниями поставим цель генерировать прерывания по окончанию акта приема/передачи DMA. Код будет сделан на основе кода из прошлой заметки о работе LVDS порта. Там для передачи был использован DMA6, а для приема DMA10. Их регистры векторов прерываний IVDMA6, IVDMA10, и нам будет достаточно прерывания по приему.
Внесем изменения в код приемника. Разрешим прерывания глобально.
SQCTL = 0x1204;;//переход в режим супервизора + глобальное разрешение прерываний
Разрешим нужное прерывание в регистре маскирования прерываний
//Разрешим прерывание DMA10 в регистре маскирования прерываний j0=(1<<31);; imaskl=j0;;
Загрузим в IVDMA10 адрес функции обработчика, у меня она зовется «dma10_interrupt». Добавим в начало программного тела:
k0=dma10_interrupt;; ivdma10=k0;;
Далее, по логике, надо разрешить прерывание в регистре настройки DMA канала (в tcb). За это отвечает 24 разряд регистра DP

Теперь настройка этого регистра выглядит так
//настраиваем и включаем приемник xr0 = arrr1;; xr1=0x4000004;; xr2=0;; xr3=0x40000000/*выбираем внутреннюю память*/+(2<<19)/*выбираем номер порта линк и направление */ +(1<<24)/*разрешаем прерывание по завершению работы канала */ +(3<<25) /*ставим длину данных*/ + (1<<22)/* разрешение след приема */ + (task_R/4);; //указатель на след цепочку выравненный по квадрословам q[j31+task_R1]=xr3:0;; xr0 = arrr;; xr3=0x40000000/*выбираем внутреннюю память*/+(2<<19)/*выбираем номер порта линк и направление */ +(1<<24)/*разрешаем прерывание по завершению работы канала */ +(3<<25) /*ставим длину данных*/ + (1<<22)/* разрешение след приема */ + (task_R1/4);; //указатель на след цепочку выравненный по квадрословам q[j31+task_R]=xr3:0;; xr0 = arrr;; dc10=xr3:0;;
В данном случае мы обслуживаем только одно прерывание, и по сути мы можем просто в него провалиться и вернуться командой RTI. При переходе в обработчик, адрес возврата кладется в регистр RETI и это значение используется командой RTI при возврате из обработчика. Но в случае, если у нас прерываний будет несколько, могут возникнуть проблемы. При одновременном вызове нескольких прерываний сработает прерывание с большим приоритетом (согласно таблице приоритетов, в спецификации). Однако при сработке прерывания и переходе в обработчик, обработка любых прерываний до конца обработки будет запрещена, в том числе и прерываний с большим приоритетом. Так как будет поднят флаг EXE_ISR показывающий, что идет обработка. Чтобы такого не происходило стоит в начале обработчика считать значение регистра RETI например командой «j0 = RETIB;;» это вызовет копирование регистра RETI в регистр j0 и сброс флага EXE_ISR. Значение j0 надо сохранить на стеке и перед операцией выхода из прерывания записать обратно «RETIВ = j0;;». В нашем случае мы сохранять RETIB не будем так как прерывание включать планируем только одно. Также для внешней индикации отработки прерывания будем в обработчике менять светики. Обработчик в итоге выглядит вот так:
dma10_interrupt: j1=0x3f;; FLAGREG=j1;; /*код обработчика*/ RTI(np);; dma10_interrupt.end:
Теперь при приеме потока данных когда один из буферов будет заполнен произойдет вызов прерывания и мы будем знать, что можно приступать к обработке собранных в него данных. А на этом закончу, спасибо за внимание.

