
Всем привет!
В ходе обсуждения возможных сценариев применения представления смысла документа через действия нам сообщили интересную проблему, с которой сталкиваются пользователи общедоступных систем машинного перевода при работе с не англоязычными текстами. Например, фраза
«Груша мне понравилась больше, чем кислое яблоко, так как она была слаще» переводится на немецкий язык одной из самых известных он-лайн систем так
«Ich mochte die Birne lieber als den sauren Apfel, da er süßer war»
(Мне больше понравилась груша, чем кислое яблоко, так как оно было слаще):
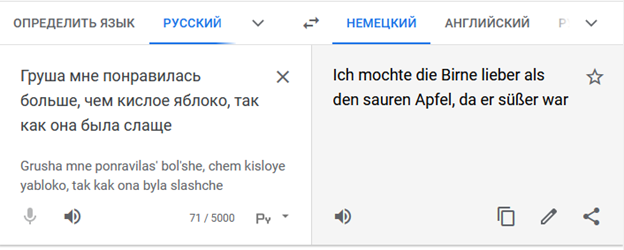
что нарушает смысл и делает яблоко вдобавок еще и сладким – «er süßer war». Разбор проблемы и потенциальное решение - далее.
Проблема
На данный момент к машинному переводу применяются статистический и нейросетевой подходы (согласно материалам на сайте yandex.ru), с помощью которых на массивах данных обучают систему – в какой ситуации какое слово или сочетание что может означать.
Одним из минусов данного подхода, является то, что огромная часть этих массивов данных содержит английский текст, в котором хоть и присутствует разделение слов по родам, но в достаточно ограниченном виде по сравнению с русским, немецким, французским или иными языками.
Учитывая, что за одним и тем же словом, выражающим понятие, в разных языках может быть закреплен разный род, то при обработке местоимений (он/er, она/sie, они/es, его/ihn и т.д.) существует риск возникновения коллизии и искажения смысла.
Из примера выше - «Яблоко», в русском языке отнесенное к среднему роду («оно»), в немецком «Apfel» относится к мужскому («er»).
Вот проиллюстрированный разбор примера из вступления, где цветом обозначены ключевые объекты предложения:

Таким образом видно, что машинный перевод на основе статистики и весов нейросетей решил присвоить параметр «сладкий» объекту «Яблоко». При этом, семантически корректным переводом была бы фраза
«Ich mochte die Birne lieber als den sauren Apfel, da sie süßer war».
Данный пример не кажется критическим – всего лишь неправильно отнесено свойство. Однако все та же проблема может повлиять на корректность исполнения договоренностей, как в следующем примере:
«В ходе совещания стороны обсудили Программу и Контракт, а также договорились его подписать до 20.01.2021»,
который машинный перевод обработал следующим образом:
«Während des Treffens diskutierten die Parteien das Programm und den Vertrag und vereinbarten auch, diese bis zum 20.01.2021 zu unterzeichnen»
(В ходе встречи стороны обсудили Программу и Контракт и договорились их до 20.01.2021 подписать),
искажая смысл в части итоговой договоренности – в результате перевода должны быть подписаны оба документа, а не только Контракт.
Да, другой известный он-лайн переводчик также допускает ошибку в данной конструкции, но уже предписывает необходимость подписать не Контракт, а Программу

Причина и возможное решение
Причиной происходящего является то, что автоматические переводчики не работают с уровнем понятий переводимого текста, а ограничиваются уровнем слов. Можно сказать, что они не понимают смысла обрабатываемого текста.
Одним из возможных вариантов решения данной проблемы видится применение подхода, обеспечивающего работу не с буквальным представлением документа или предложения, а дополнительно и с его смысловой составляющей.
Например, решение по декомпозиции текста через действия проекта RealAI построит следующую семантическую модель фразы
«Груша мне понравилась больше, чем кислое яблоко, так как она была слаще»

Отнесение местоимения "она" к объекту "Груша" будет произведено семантическим анализатором на основе поиска подходящего по роду и числу объекта из всего перечня выявленных во фразе объектов (Мне(Я), Груша и Яблоко).
В смысловой модели легко увидеть привязку местоимения «она» к существительному «груша», а вовсе не к «яблоку», что позволяет реализовать либо проверку корректности перевода (путем сравнения моделей исходного и целевого языка), либо произвести корректное формирование фразы на целевом языке.
Заключение
Безусловно, практическое внедрение построения семантической модели текста требует на данный момент решения многих задач, в частности по объему базы знаний анализатора и оптимизации производительности, однако без реализации представления в каком-либо виде смысла текста, задача качественного и точного перевода вряд ли может быть решена.
Подход RealAI по декомпозиции текста предлагает один из вариантов представления смысла. Реализованные демо-сценарии (извлечение данных из неформатированного текста, подготовка списка поручений) позволяет говорить о практической реализуемости подхода.
Если хабрапользователи сталкивались с иными проблемами, для которых необходим именно смысл обрабатываемой информации – прошу писать или комментировать для проработки тестовых сценариев.

