
Хабр, привет! Меня зовут Сергей – я тимлид в одной из продуктовых команд в «Юле». Сегодня мы поговорим о нашей работе с интеграциями. В этой статье я хочу поделиться опытом и рассказать о паттернах и подходах, которые мы используем при написании.
О чём мы будем говорить:
базовая архитектура клиентов и немного кода;
проблемы, связанные с интеграциями (как пример: тайм-ауты, доставки данных);
асинхронные подходы.
Архитектура интеграций
Для начала давайте попробуем решить какую-нибудь простую задачу: представьте продакт-менеджера, который приходит и говорит: «Серёжа, есть бизнес-партнёры, к ним нужно сходить, получить данные и отдать их мобильной разработке, а там они уже всё сделают». Вроде бы всё просто, давайте попробуем написать код:

Что здесь происходит?
Мы создаём любой клиент;
Отправляем данные;
Формируем запрос к нашим бизнес-партнёрам;
Получаем данные, отдаём их клиенту.
Результат
Задача решена, наш продакт-менеджер доволен. Посмотрим с другой стороны: думаю, что каждый из вас увидит в этом примере проблемы: копипаст, отсутствие конфигурации, валидации и другие. Давайте попробуем разобрать некоторые из них и предложить решение.
Конфигурация
Если рассматривать на примере нашего проекта, который имеет свойство постоянно развиваться вместе с партнёрами, то создаются новые endpoint и вносятся правки в уже существующие, а версии API могут версионировать. При подходе, который мы увидели в контроллере, это добавляет нам очень много работы.
Решение
Создать какую-нибудь абстракцию и зависеть от некого конфига. Сам конфиг может заполняться, например, в админке или конфиг-файлах.
Транспортный протокол
У нас в «Юле» изначально все интеграции между микросервисами писались на Rest. В какой-то момент мы поняли, что хотим перейти на GRPC, потому что это:
а) быстрее;
б) помогает создавать документацию и генерировать код.
Если у нас уже есть абстракция, то логично в неё положить этот транспортный протокол. Как только мы захотим что-то поменять, мы просто изменим с HTTPS на тот же самый GRPC или на любой другой, который нам нужен. А если у нас уже есть класс, то логично поместить какие-то методы, связанные с отправкой данных, с подписью запросов, с отправкой нового дефолтного заголовка и так далее.
Логирование и базовые метрики
Это одна из важных составляющих любой интеграции, особенно если происходит какой-то инцидент: было бы грустно не иметь никакой информации, но и копипастить при каждой отправке запрос-ответ тоже не хочется.
Решение
Сделать логирование в абстракции, где происходит отправка сообщения.
Request & Response. Проблема валидации и документации
Тут можно провести параллель с объектами Request/Response в ответах наших endpoint. Мы описываем их так, чтобы поля соответствовали выдаваемому объекту, в Symfony описываем валидацию в док.блоках. Если документация указана в PDF-файле, мы можем описать саму документацию там же, и теперь каждый разработчик уже может зайти в этот объект и посмотреть, что здесь действительно находится.

Результат
На текущий момент у нас есть Client, он зависит от конфигурации, транспортного протокола, работает с конкретными объектами request/response, валидация скрыта в самих объектах, логирование есть.
Кеширование и дублирование
У нас есть интеграция, мы используем абстрактный метод по разным участкам нашей системы в 10-20 местах, в какой-то момент мы понимаем, что хотим закешировать данный метод.Как поступить? Идти и искать все вхождения, во внешнем коде зависеть ещё и от кэша, пытаться закешировать, обязательно где-то допустить «очепятку» и «ловить баги».
Другой случай. Мы работаем с бизнес-партнёром, запрашиваем у него данные, в какой-то момент бизнес-партнёр говорит, что нужно идти в другой API, то есть теперь мы пишем ещё один клиент и переписываем весь код, где используется этот метод. Для всех бед у нас существует ещё один слой абстракции. Мы его назвали фасадом или верхнеуровневым SDK – туда поместили всю логику, которую видели в контроллере, кэширование и валидацию.
Бонусом получили следующее:
Из внешнего кода можем отправлять в контракт этого фасада те данные, с которыми удобно работать внешнему коду.
Сразу стало понятно, куда записывать бизнес-метрики.
В фасаде каждый публичный метод несёт за собой бизнес-ценность.
В итоге мы получаем подобную схему:
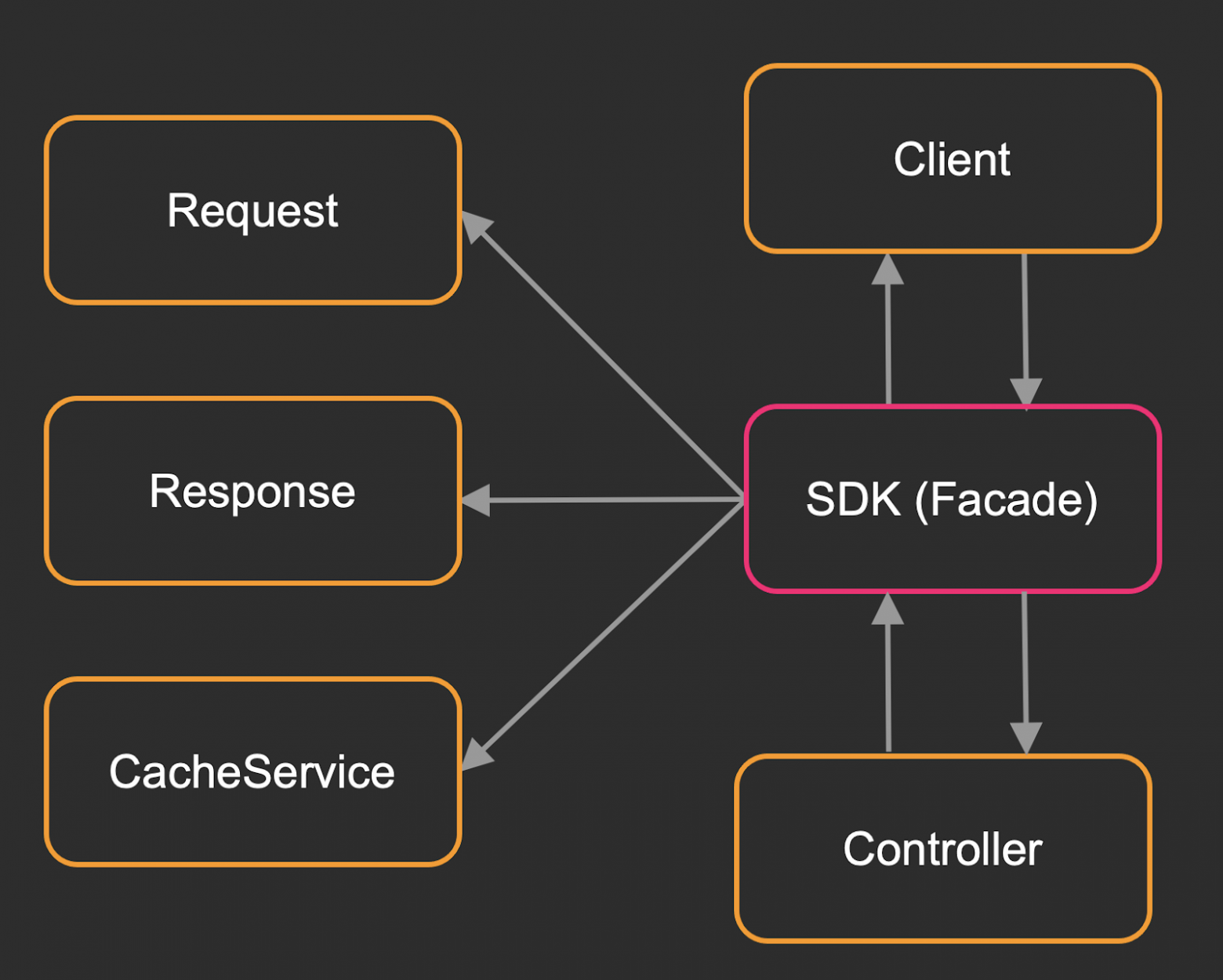
У нас есть внешний код – в данном случае это контроллер. Он всегда общается только с SDK, который уже формирует request/response и использует для клиента всякие кеш-сервисы. И это далеко не всё, каждый случай может быть разным. Если наш запрос собирается очень сложно и для процесса нужно задействовать разные участки системы, то, например, можно добавить какой-нибудь сборщик, но он не затронет внешний код и всё будет происходить внутри фасада – рефакторинг минимальный. Код получается гибким к изменениям и тестируемым. Аналогичный подход мы используем, когда хотим выделить код из монолита в микросервис.
Переносим всю работу с требуемым участком системы в SDK.
Понимаем, какие методы должны быть у данного микросервиса.
Пишем тот самый микросервис.
Описываем клиент. Но всё-таки это не два класса. Если у нас есть Swagger, Protobuf-файл или любая другая автодокументация, то слои client, request, response можно генерировать. В интернете есть множество инструментов, которые могут это делать, а нам остаётся всего лишь описать бизнес-логику.
Тайм-аут: как бороться?
Давайте попробуем понять, где это всё может сломаться. Одна из самых популярных ошибок – это тайм-аут. Сервер может не отвечать, сеть моргать, а мы не можем получить данные. Кажется, ну тайм-аут, в чём проблема? Эти тайм-ауты могут повлиять и на наш основной проект. Влияние тайм-аутов:
У нас есть достаточно много RPS, все они идут в наше приложение. Идут в NGINX – NGINX передаёт всё это логике – она идёт к бизнес-партнёрам – получает данные – пытается получить данные – получает тайм-аут – падает. Мы хотим отдать ответ на нашу ручку или ошибку, либо какие-то дефолтные значения, не столь важно. Важно, что вот этот самый запрос обработки идёт достаточно долго. Предположим, 1 сек. Далее, при большом количестве RPS может случиться вот какая ситуация: к нам приходит ещё один запрос или ещё один поток данных параллельно, попадает в NGINX, и вот тут мы сталкиваемся с проблемами. Пойдём от самого банального. У нас в php-fpm могут просто закончиться подключения. Что произойдет в этом случае? Если у нас достаточно большой RPS, и оно всё идёт и идёт, то много запросов встанет в очередь. В какой-то момент она может просто не дойти до обрабатываемой логики и умереть раньше.
Другой случай:
У нас есть эти запросы и много RPS. Каждый параллельный запрос аллоцирует память, использует какое-то количество процессора. С каждым параллельным запросом у нас всё хуже и хуже работает, потому что остаётся всё меньше ресурсов. Появляется та самая дельта, на которую запрос работает чуть медленнее, чем если бы работал один.

Понятное дело, что если у нас достаточно большой RPS, то дельта просто будет расти. В какой-то момент мы получим ошибку (504). Как с этим бороться? Мы вывели для себя критерии:
Мы хотели, чтобы это работало автоматически.
Чтобы задело как можно меньше наших пользователей.
Сообщало об инцидентах, когда происходит та самая ситуация.
Circuit breaker и его состояния
По сути, это размыкатель электрической сети. У него есть три состояния:
Open – цепь разомкнута, то есть состояние, когда в сервис ходить не нужно.
Close – цепь замкнута и всё хорошо.
Half-open – состояние, когда мы в интересующий нас сервис «тыкаем палочкой» и узнаём, жив он или нет.

Давайте попробуем воспроизвести базовую работу классического случая circuit breaker. Вот он находится в состоянии close. У нас что-то идёт не так, все запросы начинают тайм-аутить. Мы переходим в состояние open. В состоянии open мы проводим определённое время, переходим в состояние half-open. В half-open мы смотрим, что и как работает, и если сервис нормализовался, то возвращаемся обратно в close. Если работа не нормализовалась, то возвращаемся в open и опять ждём.
Задача. Предположим, что у нас 70 % трафика обрабатывается успешно, а 30 % трафика сваливается в тайм-аут. Что в этом случае произойдёт?
Рассуждения. Так как у нас 30 % фейлов, мы достаточно быстро скатимся из close в open и будем ждать 2-3 минуты, потом перейдём в состояние half-open и будем чекать, что там и как, так как у нас 70% отвечает успешно, то с большой долей вероятности мы перейдём обратно в close. Процесс будет повторяться по кругу.
Выводы. Несложно догадаться, что почти всё время, в котором проведёт наша система – это состояние open. Мы не идём за данными, но при этом могли снизить нагрузку до 60-70% трафика и обработать хотя бы часть клиентов, поэтому для таких случаев мы сделали базовое состояние – half-open. Когда у нас что-то идёт не так, мы переходим в half-open и там уже по стратегии смотрим, можно идти этому запросу или нельзя. И если там уже совсем всё плохо, только тогда переключаемся в open.

Как это выглядит в коде
У нас просто есть какой-то сервис, который осуществляет базовую работу и базовый интерфейс для circuit breaker. В этот сервис мы можем сконфигурировать какие-то стратегии, каждая стратегия использует хранилище для того, чтобы запоминать, в каком состоянии мы сейчас находимся.
Стратегии
Count strategy. Это та самая базовая схема circuit breaker. У нас она используется, когда при малом или неравномерном количестве RPS нам нужно закрыть ту самую сеть. Работает примерно так. SDK проверяет, можно ли ходить в сервис, если можно, то передаёт данные клиенту, который в свою очередь отправит запрос на сервис. Если всё хорошо – увеличиваем счётчик успешных запросов, если нет – счётчик фейлов. Eсли у нас в этот шаг заполнился threshold, то мы переключаем состояние на open. В следующий раз говорим, что сервис недоступен. Если мы хотим подняться, то эта схема поднимается сверху- вниз из состояния half-open и дальше по кругу.
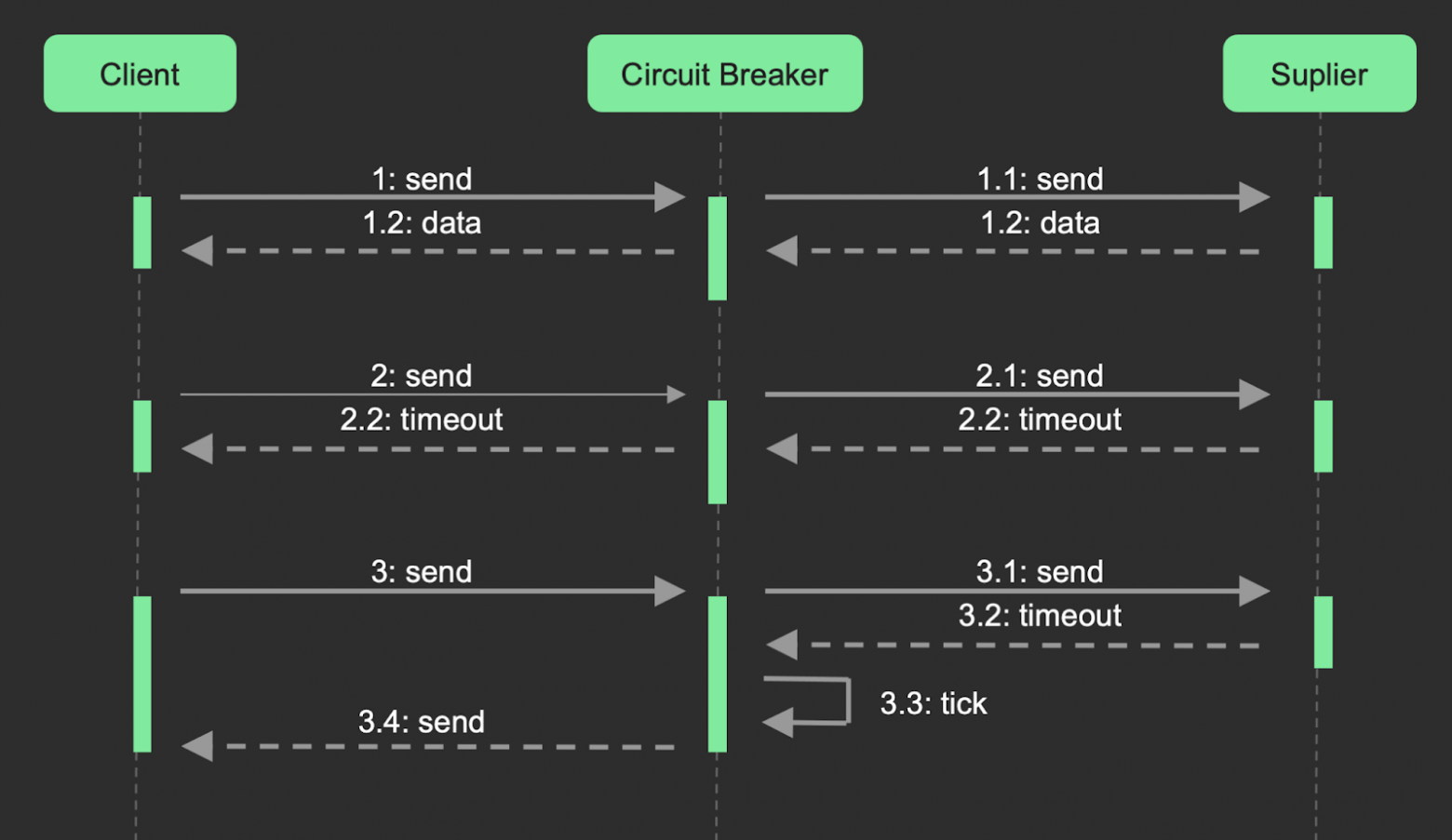
Percent Strategy. Это второй случай circuit breaker, где состояние half-open является базовым, используется при интеграции с партнёром при больших количествах RPS и применяется там, где нужно управлять трафиком. Мы идём к партнёрам, получаем какие-то данные и в любом случае запоминаем, был он успешным или нет. На этом этапе мы знаем общее количество запросов и фейлов. Мы можем нормализовать эту величину и получить тот самый процент. По этому проценту мы уже составляем некую стратегию о том, что если у нас 70% происходит с фейлом, то передавать нужно только 60% трафика. Если что-то пойдёт совсем не так, то уже переход в open. Схема поднимается наоборот: снизу-вверх, то есть мы из open переходим в half-open, точно так же рулим по стратегии и выясняем, можно идти с запросом или нет. Если всё хорошо, то поднимаемся на самый верх.
Retry-pattern
Бывают такие случаи, когда мы обязаны доставить данные. У нас есть платёжная система и система заказов – пользователь оплачивает определённый товар, мы получаем деньги, как только мы убеждаемся, что деньги находятся у нас – мы должны сообщить об этом системе заказов, система заказов должна перевести наш заказ в следующий статус, чтобы пользователи могли передать свой товар и следовать бизнес-сценарию. Мы отправляем данные, а система говорит, что не может это сделать – состояние тайм-аут. У нас всё хорошо, ведь есть circuit breaker – он работает, платёжная система чувствует себя прекрасно, но данные нужно доставить.
Решение
Давайте разберём алгоритм. Мы создаём request, коннектимся с сервером, проверяем успешность ответа. Если ответ успешный, то наша работа выполнена. Если неуспешный, то ждём какое-то время и повторяем все действия заново. Схема очень лёгкая.

Лайфхаки
Количество времени, которое мы ждём, не должно быть слишком коротким. Если мы запросили данные и сервер ответил нам тайм-аутом, а мы запросим то же самое через 50 мс – скорее всего, получим такую же ошибку.
Сервер, которому мы пытаемся доставить данные или с которого хотим их получить – может больше никогда в своей жизни не отвечать, он просто закончил свою работу и больше либо нет такого сервиса, либо партнёра. В таком случае, у нашей бедной платёжной системы накопится много задач, и она будет гонять всё это бесконечно по кругу – это будет забирать ресурс и выполнять не то, что действительно нужно, поэтому важно ограничиться количеством попыток.
Давайте предположим, что у нас есть 10 000 задач, и они все «сфейлились» примерно в одно и то же время, каждая сделала пометку о неуспешности, и нам нужно отправить их заново. Сервис не смог нам ответить, потому что для него 10 000 – это слишком много. Мы начинаем этим DDoS’ить себя же.
Поэтому f(x) – должно быть рандомизированным значением, сдвинутым в ту или иную сторону и увеличивать время с каждой новой попыткой, чтобы сгладить нагрузку.
Асинхронные подходы
Пример. Это та же самая платёжная система и система заказов, нам всё также нужно уведомить систему заказов о том, что мы получили деньги. Давайте усложним пример: добавим микросервис чеков, тарифов и ещё какой-нибудь микросервис. По прошлому подходу, нам нужно платёжной системе отправить данные о том, что деньги уже у нас, а ещё системе заказов, чекам, тарифам и множеству других.
Итог
Платёжная система занимается тем, что отправляет эти данные, а если ещё и они будут «фейлиться» то это всё нужно «ретраить» – это неудобно, ведь мы тратим лишние ресурсы и пишем много кода для поддержки такой системы. Поэтому, для таких случаев мы используем такой инструмент как Kafka, который выступает в роли шины данных. По сути, можно перевести всё это дело по-другому: платёжная система получает какие-то деньги и пушит событие в Kafka. Все остальные подписываются на Kafka, на какие-то конкретные топики – мы видим, что произошло обновление и реагируем на это в соответствии со своей бизнес-логикой – это круто.
У нас уменьшается связность – мы не пишем код, мы не знаем, что за системы подписались на это. Платёжная система начинает работать только тем, чем она должна работать – не используйте синхронные интеграции там, где можно использовать асинхронные, ведь это удобнее.

