
Переключение горутины с одного потока ОС на другой довольно затратно и может значительно замедлить работу приложения, если это происходит слишком часто. Однако со временем эту проблему решил планировщик Go путем обеспечения привязки горутин к потоку (scheduler affinity) в условиях конкурентной работы (concurrently). А чтобы нам лучше понять всю прелесть этой доработки, давайте вернемся назад в прошлое и посмотрим, как было до.
Первоначальная проблема
На ранних этапах существования языка Go (во времена версий 1.0 и 1.1) была проблема со снижением производительности при выполнении конкурентного кода с большим количеством потоков ОС, т.е. с высоким значением GOMAXPROCS. Посмотрим, как это выглядело, на примере вычисления простых чисел, используемого в документации:

https://play.golang.org/p/9U22NfrXeq
А вот бенчмарк вычисления первых ста тысяч простых чисел на Go 1.0.3 с несколькими значениями GOMAXPROCS:
name time/op Sieve 19.2s ± 0% Sieve-2 19.3s ± 0% Sieve-4 20.4s ± 0% Sieve-8 20.4s ± 0%
Чтобы проанализировать эти результаты, нам нужно понять, что было заложено в планировщик при разработке. В первой версии Go планировщик имел только одну глобальную очередь, в которой каждый из потоков мог отправлять и брать оттуда горутины. Вот пример приложения, работающего с максимум двумя потоками ОС (GOMAXPROCS присвоено значение два) M на схеме ниже:

Наличие только одной очереди не гарантирует, что горутина продолжит работу в том же потоке. Первый же свободный поток подберет ожидающую горутину и запустит ее. Следовательно, отсюда вытекает жонглирование горутин между потоками, и это дорого, если рассматривать это с точки зрения производительности. Вот пример с блокирующим каналом:
Горутина #7 блокируется на канале и ожидает сообщения. Как только сообщение получено, горутина становится в глобальную очередь:
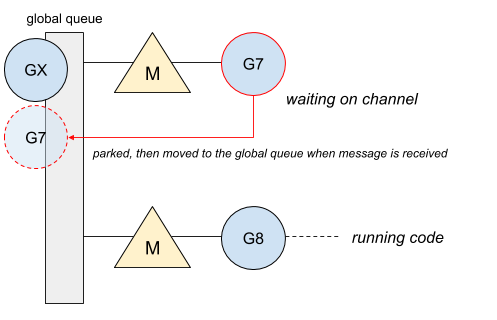
Затем канал отправляет сообщения, и горутина #X запускается в свободном потоке, в то время как горутина #8 блокируется на канале:

Горутина #7 теперь запущена в свободном потоке:
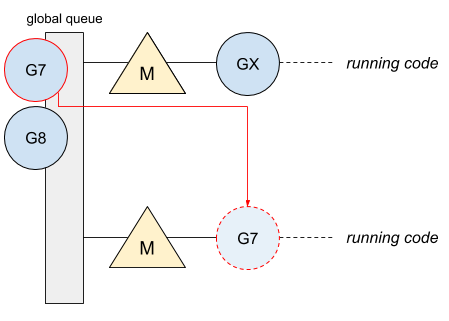
Теперь горутины работают в разных потоках. Наличие единой глобальной очереди также заставляет планировщик иметь единый глобальный мьютекс, который охватывает все операции планирования горутин. Вот, как выглядит профиль процессора, полученный с помощью pprof с GOMAXPROCS, установленным на максимум:
Total: 8679 samples 3700 42.6% 42.6% 3700 42.6% runtime.procyield 1055 12.2% 54.8% 1055 12.2% runtime.xchg 753 8.7% 63.5% 1590 18.3% runtime.chanrecv 677 7.8% 71.3% 677 7.8% dequeue 438 5.0% 76.3% 438 5.0% runtime.futex 367 4.2% 80.5% 5924 68.3% main.filter 234 2.7% 83.2% 5005 57.7% runtime.lock 230 2.7% 85.9% 3933 45.3% runtime.chansend 214 2.5% 88.4% 214 2.5% runtime.osyield 150 1.7% 90.1% 150 1.7% runtime.cas
procyield, xchg, futex и lock связаны с глобальным мьютексом планировщика Go. Мы отчетливо видим, что приложение большую часть времени находится в блокировке.
Эти проблемы не позволяют Go использовать все преимущества процессоров. Решением же этих проблем стало создание нового планировщика в Go 1.1.
Привязка к потоку в условиях конкурентной работы
В Go 1.1 был реализован новый планировщик и созданы локальные очереди горутин. Это улучшение, при условии наличия локальных горутин, позволило не допускать блокировки всего планировщика и дало возможность работать в одном потоке ОС.
Поскольку потоки могут блокироваться при системных вызовах, а количество заблокированных потоков не ограничено, Go привнес концепцию процессоров. Процессор P представляет собой работающий поток ОС, который управляет локальными очередями горутин. Вот, как теперь выглядит новая схема:

Новый бенчмарк с новым планировщиком Go 1.1.2:
name time/op Sieve 18.7s ± 0% Sieve-2 8.26s ± 0% Sieve-4 3.30s ± 0% Sieve-8 2.64s ± 0%
Go теперь действительно использует все доступные ядра процессора. Профиль процессора также изменился:
Total: 630 samples 163 25.9% 25.9% 163 25.9% runtime.xchg 113 17.9% 43.8% 610 96.8% main.filter 93 14.8% 58.6% 265 42.1% runtime.chanrecv 87 13.8% 72.4% 206 32.7% runtime.chansend 72 11.4% 83.8% 72 11.4% dequeue 19 3.0% 86.8% 19 3.0% runtime.memcopy64 17 2.7% 89.5% 225 35.7% runtime.chansend1 16 2.5% 92.1% 280 44.4% runtime.chanrecv2 12 1.9% 94.0% 141 22.4% runtime.lock 9 1.4% 95.4% 98 15.6% runqput
Как мы видим, большинство операций, связанных с блокировкой, пропали, а операции, отмеченные как chanXXXX, относятся только к каналам. Однако, не смотря на то, что планировщик улучшил привязку между горутиной и потоком, в некоторых случаях привязку можно уменьшить.
Ограничение привязки
Для того, чтобы понять какие есть ограничения привязки, мы должны иметь представление о том, что именно распределяется в локальные и глобальные очереди. Локальная очередь будет использоваться для всех операций, таких как операции блокирования каналов и вызовы select, обслуживание таймеров и блокировок, за исключением системных вызовов. Однако есть две функции, которые могут ограничить привязку между горутиной и потоком:
Кража горутин (work-stealing). Когда процессору
Pнедостает работы в своей локальной очереди, он будет красть горутины у другихP, если глобальная очередь и сетевой поллер (network poller) пусты. После чего, горутины будут работать в другом потоке.
Системные вызовы. Когда системный вызов происходит (например файловые операции, http-вызовы, операции с базами данных и т.д.), Go перемещает запущенный поток ОС в режим блокировки, позволяя новому потоку обработать локальную очередь на текущем
P.
Однако, улучшив управление приоритетностью локальной очереди, этих двух ограничений можно было бы избежать. Go 1.5 старается отдать больший приоритет горутине, которая передает данные туда-сюда по каналу, и, таким образом, оптимизирует привязку к выбранному потоку.
Упорядочивание для улучшения привязки
Как вы могли заметить ранее, горутина, передающая данные туда-сюда по каналу, является причиной частых блокировок, то есть часто происходит повторное добавление в локальную очередь. Однако, поскольку локальная очередь имеет реализацию FIFO, нет гарантии, что незаблокированные горутины будут запущены как можно скорее, если поток будет занят другой горутиной. Вот пример с горутиной, которая запускается после того, как ранее была заблокирована на каналах:

Горутина #9 возобновляет работу после блокировки на канале. Однако перед запуском ей придется подождать выполнения горутин #2, #5, и #4. В этом примере горутина #5 перехватывает поток, задерживая выполнение горутины #9 и появляется риск кражи этой горутины другим процессором. Начиная с Go 1.5, благодаря специальному свойству P, горутины, возвращающиеся из блокирующего канала, теперь будут выполняться в первую очередь:
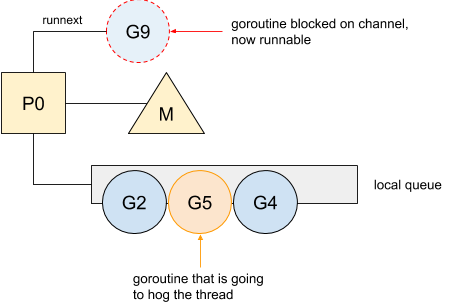
Горутина #9 теперь помечена как следующая на выполнение. Эта новая система приоритетности позволяет горутине выполнить работу, прежде чем она снова будет заблокирована на канале. Потом у других горутин будет время для выполнения их работы. Это изменение в целом положительно повлияло на стандартную библиотеку Go, улучшив производительность некоторых пакетов.
Материал подготовлен в рамках курса «Golang Developer. Professional».

