Итак, мы разобрались с генерацией данных и мне осталось рассказать об инструменте для получения детальной статистики по базе данных, которую 85% разработчиков считает самым узким местом в системе. И о том, как с помощью анализа статистики ускорить эту самую систему, но не попасть в ловушку.

Влияние данных на результат тестирования
Это технический пункт, здесь нет примеров кода, но есть статистика за долгое время моей работы. Если вы сгенерировали данные хорошо, то у вас не будет ошибок, вызываемых некорректными тестовыми данными. Когда в системе появляются ошибки в логах, например в app.log, ElasticSearch, GrayLog, вы можете быть уверены, что ошибка не из-за тестовых данных. Это ошибка системы. С помощью корректно сгенерированных тестовых данных я находил ошибки после конвертации, миграции и накатки версий. Например, должны быть поля, а они пропали, значит механизм конвертации их сломал. А если ваши данные некорректно сгенерированы, такие ошибки не отловить.
Плюс 40% новых дефектов производительности
Если у вас корректные данные, вы можете найти новые важные дефекты. Вот результаты моего анализа дефектов:
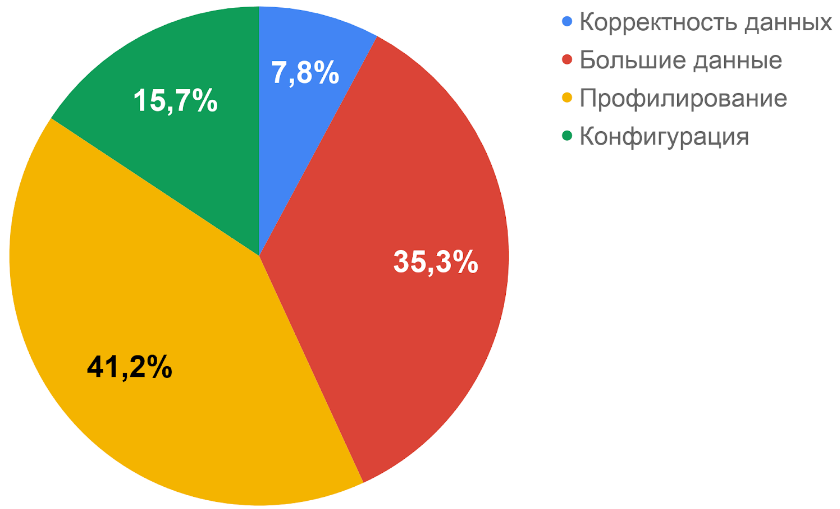
Часть из них ошибки потери или повреждения данных, которые составляют до 7% всех ошибок нагруженной системы. Например, при генерации данных я создал миллион записей с email *@ok.ru. Система делает SELECT, UPDATE, возможно, блокируется, перезапускается или отправляет эти данные по протоколам HTTP, JMS. А потом я проверяю, сколько данных получилось.
SELECT count() FROM public.таблица1 Group BY name; SELECT count() FROM public.таблица2 Group BY title;
За счет того, что количество данных на входе было круглым, я всегда могу сказать, что по ключу должно быть миллион записей. А если вижу, что записей меньше или больше, значит что-то пошло не так: они задвоились, удалились или повредились.
Такие ошибки важны в финансовых системах. Если где-то потерялась транзакция, это не совсем задача нагрузочного тестирования, но на корректных данных, на больших объемах, которые вы генерируете под нагрузку, вы такие ошибки найдёте.
С помощью большого количества данных можно находить медленные запросы, а это до 35% всех ошибок нагруженной системы. Алгоритм здесь более простой. Вы создаете много записей.
SELECT load_fill_database_test1( 1, 1000000); SELECT load_fill_database_test2(1000001, 2000000);
Система работает и собирает статистику сама о себе. Вы смотрите на мониторинг. В Postgres это таблица pg_stat_statements.
SELECT query, calls, total_time, mean_time FROM pg_stat_statements ORDER BY total_time DESC
Изучаете планы запросов, выполняете EXPLAIN ANALYZE. Добавляете индексы. Переписываете запросы, смотрите, что EXPLAIN ANALYZE показывает лучшие планы запросов. Оформляете дефекты, и ваша система ускоряется.
Анализ статистики по запросам PostgreSQL
Рассмотрим, как сохранять статистику из системной таблицы PostgreSQL pg_stat_statements в InfluxDB, как ее визуализировать, и какие у этого есть минусы.
Я выбираю InfluxDB потому, что с ней работают все инструменты нагрузки. Для неё есть Telegraf, который позволяет добавлять в InfluxDB самую разную статистику по 100 видам систем.
Многие критикуют InfluxDB потому, что у него по умолчанию создается политика хранения данных Retention policy с именем autogen. Она предполагает, что метрики вечно хранятся на InfluxDB. Из-за этого, если вы регулярно собираете данные по мониторингу, БД становится очень большой и перестает работать, а вам приходится останавливать её и удалять данные.
Чтобы решить эту проблему надо исправить Retention policy по умолчанию с бесконечности, например, на неделю, а в Autogen по умолчанию оставить бесконечность. В CONTINUOUS QUERY надо дописать, чтобы данные преобразовывались и перекладывались из укороченной перспективы хранения в вечную, но уже агрегированные, очищенные и подготовленные.
В pg_stat_statements все данные хранятся накопительно, например, сколько раз выполнялся запрос. Чтобы вычислить, какое время занял этот запрос за последнюю минуту, нужно применить функцию вычитания. В InfluxDB она называется derivative. Я написал CONTINUOUS QUERY, которые как раз превращает накопительные метрики в инкрементальные. На основе сбора статистики получается Telegraf.conf.

В нем можно сделать такой SQL-запрос:
SELECT pg_user.usename, pg_stat_database.datname, left(regexp_replace(query, '\s+',' ','g'),10000) query, md5(query)::uuid::varchar(100) as query_md5, queryid, calls, total_time, mean_time, rows FROM pg_stat_statements stat JOIN pg_user ON (pg_user.usesysid = stat.userid) JOIN pg_stat_database ON (pg_stat_database.datid = stat.dbid)
Чтобы текст запроса, содержащий сложные символы и переводы строк, корректно сохранялся в InfluxDB, нужно применить регулярное выражение. В Postgres это функция regexp_replace, которая позволяет заменить все переводы строк и символы, например, на пробелы. Поэтому любой сложный многострочный запрос превращается в одну строку, которая корректно вставляется в InfluxDB.
В результатах статистики я рекомендую выбрать небольшое количество полей, например, имя пользователя, имя БД и текст запроса, ограниченный по длине, чтобы не перегрузить ваш InfluxDB.
Если вы супер-длинным (на 500 тысяч инсертов и больше 10 тысяч символов) SQL запросом восстанавливаете базу данных из бэкапа, сохранять его не надо. Он скорее всего одноразовый, поэтому сделайте операцию left и сохраните md5 хэш от текста запроса. Это пригодится в качестве идентификатора:
идентификатор запроса
количество вызовов
суммарное время вызова
среднее время вызова
количество строк
Три последних поля из pg_stat_statements (calls, total_time, rows) дадут вам всю статистику. Теперь, для удобства, остается эти данные визуализировать.
Визуализация статистики в Grafana
Мы в команде делали визуализацию в виде большого грида с текстами запросов и сводной статистикой за любой интервал:

В Grafana Queryid является кликабельным элементом. Мы можем по нему кликнуть и перейти к детальной статистике по запросу, посмотреть, какое количество вызовов этого запроса было во времени, какова доля этого запроса по сравнению со всей БД, как менялось среднее время его выполнения во время работы и увидеть текст запроса.

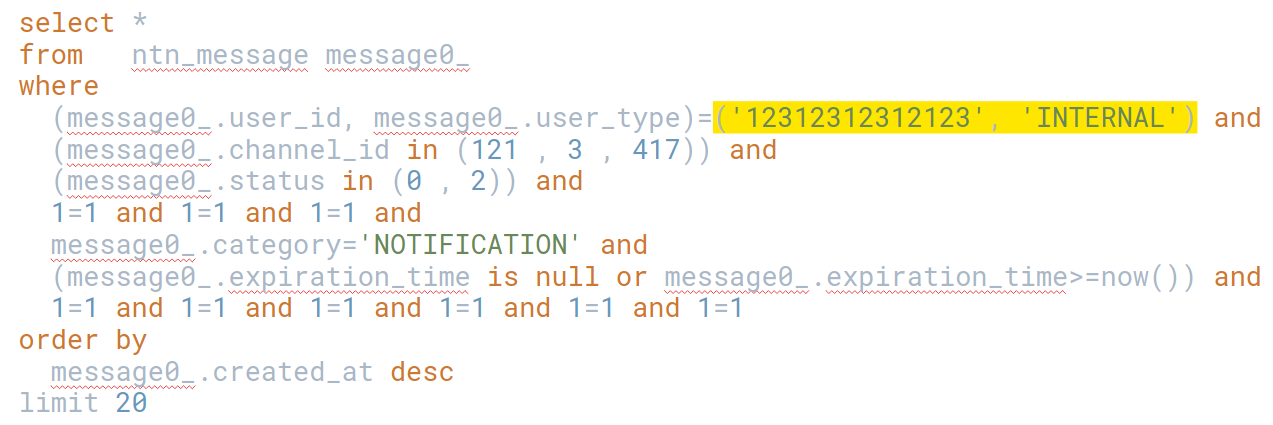
Примерно так выглядит текст запроса, взятый из pg_stat_statements:
select * from ntn_message message0_ where (message0_.user_id, message0_.user_type)=($1, $2) and (message0_.channel_id in ($3 , $4 , $5)) and (message0_.status in ($6 , $7)) and $11=$12 and $13=$14 and $15=$16 and message0_.category=$8 and (message0_.expiration_time is null or message0_.expiration_time>=$9) and $17=$18 and $19=$20 and $21=$22 and $23=$24 and $25=$26 and $27=$28 order by message0_.created_at desc limit $10
Обратите внимание, что он анонимизированный, в нем все параметры заменены на плейсхолдеры $1, $2. С таким запросом можно работать. Например, в поле категории нет индекса, и если его добавить, запрос ускорится.
Качественный сбор статистики, позволяющий выбрать все запросы по тесту и отсортировать их по длительности, помогает ускорить вашу систему. Но у этой статистики есть свои недостатки.
Недостатки статистики
Она является статистикой за счет плейсхолдеров. Но чтобы построить план запросов, нам нужны значения, то есть, запросу нужны параметры.

А если запрос генерируется Hibernate, некоторые параметры могут быть странными. Я такое не писал, но оно откуда-то появилось.

Вы построите план запроса, убедитесь, что есть проблема и нужны конкретные параметры — 1, 2, 3 и комбинации параметров:

Не бывает такого, что среди 20 параметров система всегда посылает случайные числа. Как правило, меняется только один или два параметра, а остальные остаются постоянными.
Такой запрос попадает в ТОП, и вам не нужно перебирать все параметры. Достаточно узнать часто используемые комбинации параметров и создать Partial-индексы, которые позволят сэкономить на проверках.

Часть условий, которые стабильно встречаются в выборке, вы зашиваете в индекс и получаете более короткий и меньший по размеру индекс, которому уже заранее предрассчитаны условия выборки. Это значительно ускоряет все SQL запросы. Например, если добавить индекс по полю категория, это снимет 1 проверку. А индекс с часто используемыми комбинациями снимает 6 проверок и ускоряет выборку по двум полям.
Теперь расскажу, наверное, самую хитрую часть — как сделать так, чтобы знать значения запросов, которые вызывает ваше приложение.
Логирование запросов PostgreSQL с параметрами
Чтобы узнать параметры запросов есть несколько подходов:
настроить тотальное логирование всего на PostgreSQL Server
настроить перехват трафика Wireshark
настроить логирование Hibernate
настроить логирование в JDBC-драйвере PostgreSQL
Первые два достаточно сложные. Hibernate позволяет залогировать тексты запросов. Я так тоже пробовал, но рекомендую подход с логированием в JDBC-драйвере PostgreSQL. Делается это по документации:

Добавьте в ваш connection string loggerLevel=TRACE&loggerFile=путь к файлу логов, например, /tmp/pgjdbc.log. С такими логами удобно работать:
#!/bin/sh name="ntn.query" cat */pgjdbc.log | grep "from ntn_message message0_ where (message0_.user_id, message0_.user_type)=([$]1, [$]2)" -A 2 > $name.txt cat $name.txt | grep "Bind[(]" > $name.bind.txt cat $name.txt | grep "Parse[(]" > $name.Parse.txt cat $name.Parse.txt | sort | uniq -c | sort -nr > $name.Parse.count.txt
Например, если вам надо выбрать статистику с параметрами по запросу, который у нас был в ТОП-10, и в нем условие: grep "from ntn_message message0_ where (message0_.user_id, message0_.user_type)=([$]1, [$]2)" -A 2 > $name.txt то можно сделать это с помощью grep в BASH.
Если в BASH написать $1, то BASH будет думать, что внутри двойных кавычек первый аргумент скрипта и заменит его на что-нибудь ненужное, чтобы оставить статикой. Чтобы grep воспринимал его как $1, его надо экранировать. Различные слэши, в том числе, двойные, ничего не экранируют. Обращайте на это внимание, при использовании grep.
Потом из этой статистики можно забрать все строчки, где биндятся параметры, и сами тексты запросов сгруппировать с помощью sort, uniq. Так вы получите значения всех параметров, разделенные запятой $name.bind.txt, сгруппированные тексты запросов и детальную статистику $name.Parse.c.txt.
У логирования с режимом Trace тоже есть свои минусы. Его нельзя запускать под большой нагрузкой. Поэтому, я выработал определенный порядок действий на проекте:
сначала подается нагрузка без таких параметров
собирается статистика, какой запрос топовый
запускается небольшая нагрузка, уже с логированием;
лог разбирается и анализируется файл в Excel
Например, с разбивкой по запятым. Так выявляются самые частые параметры и забиваются в Partial индексы.
Материалы
Три части статьи "Атака не клонов":
Слайды по докладу "Атака не клонов".
Видео с митапа общества анонимных тестировщиков:
Третья часть материала впоследствии стала отдельным докладом, обросла кодом:
Репозиторий с docker-контейнерами, скриптами, мониторингом, чтобы попробовать повторить материалы третьей части статьи на практике и слайды к материалу:
Итоги
При подготовке данных для микросервисов, вместо клонирования или деперсонализации, применяйте генерацию. Если вы делаете данные для тестов производительности, они не должны повторяться, пересекаться между тестами, между генераторами и даже в двух итерациях теста. При генерации с PostgreSQL удобно использовать «хранимки», если нужно генерировать файл Excel, обратите внимание на Python и Pandas.
Если вы генерируете данные через API, и у вас появился соблазн сгенерировать XML и JSON файлы в большом количестве с помощью конкатенации строк, откажитесь от этой идеи. Придите к разработчикам, возьмите у них описание классов и сериализуйте объекты в готовые JSON и XML объекты. Это даст вам большой прирост по количеству неотловленных ранее багов и уверенность в результате.
Когда у вас будет много данных, pg_stat_statements нужно периодически выгружать в InfluxDB с помощью Telegraf. Так вы получите информативную статистику по базе данных, выполнению и расходу времени каждого SQL запроса. Анализ статистики по запросам PostgreSQL позволит вам ускорить систему.
Если при анализе запроса выясняется, что уже есть индексы и добавлять, на первый взгляд, нечего. То пригодится узнать самые частые параметры запроса. И добавить Partial-индексы именно для них. Я советую залогировать тексты SQL запросов с помощью параметров подключения Postgres SQL в JDBC-драйвере к серверу БД, а анализ параметров выполнить скриптом.
Конференция об автоматизации тестирования TestDriven Conf 2022 пройдёт в Москве, 28-29 апреля 2022 года. Кроме хардкора об автоматизации и разработки в тестировании, будут и вещи, полезные в обычной работе. Расписание уже готово, а купить билет можно здесь. До повышения цены осталось 9 дней.

