Статья является переводом поста "Introduction to Knowledge Modeling" с сайта makhfi.com сделанным с молчаливого согласия автора (запрос по-честному отправлен на почту Pejman Makhfi 30.11.2021).
1. Вступление
Получение ценной практической информации из данных была задачей наших компьютеров в течение последних пятидесяти лет в эпоху, которую метко назвали «веком информации». Тем не менее, в 21 веке в центре внимания будет уход от компьютера как простого поставщика базовой информации. Компьютеры ближайшего будущего будут использоваться для извлечения знаний из информации.
Быстрое развитие технологий, увеличение объема и сложности информации, а также широкий и легкий доступ к ней выдвигают новые требования к компьютерам. Основное внимание в текущем веке человечество уделяет использованию технологий для интеллектуальной деятельности - или того, что можно назвать развивающейся «эпохой знаний»
Технологии «эпохи знаний» переносят наше внимание с индивидуальных, изолированных информационных систем и хранилищ на расширенный обмен и совместное использование информации с целью расширения объема и глубины знаний, доступных отдельным лицам и видам деятельности.
Объем мирового рынка домашних интеллектуальных компьютерных устройств в 2020 году составил 801,5 млн штук
Но что такое интеллект? Концепция интеллекта основана на четырех фундаментальных принципах, которые включают: данные, информацию, знания и мудрость (также известные как интеллект).

Базовый уровень - это данные - меры и символы окружающего нас мира. Данные представлены в виде внешних сигналов и улавливаются различными сенсорными устройствами. Упрощенно, думайте о данных как о необработанных сигналах, фактах и числах - например, звуковых сигналах в азбуке Морзе:… ---…
Второй уровень абстракции - это информация, которая создается путем придания значения данным. Другими словами, данные становятся информацией, когда они становятся актуальными для нашего процесса принятия решений. Например, звуковой сигнал азбукой Морзе означает «SOS».
Знание - третий уровень - это субъективная интерпретация Информации в попытке распознать приложения и подходы, которые необходимо использовать в сознании воспринимающего. Таким образом, Знание трудно представить как абсолютное определение в человеческих терминах. Он придает информации цель и компетентность, что приводит к потенциальным действиям.
Наконец, мудрость воплощает в себе осознанность, проницательность, моральные суждения и принципы для создания новых знаний и улучшения существующих Знаний.
Более двух тысячелетий интеллектуалы, философы и ученые пытались концептуализировать осознание, информацию, знания и интеллект в различных формах, формах и ситуациях. Несомненно, было приложено много усилий и разработано множество приложений, которые пытались собирать и использовать Знания в различных формах с использованием различных методов.
Однако быстрый рост объема доступной информации в сочетании с гибкостью доступа к этой информации выдвинул необходимость объединения усилий для ускорения использования информации в рамках общей структуры.
По мере того, как доступные технологии опережают наши ожидания, а уровень сложности повышается, эта ситуация увеличивает потребность в эффективном синтезе и эффективном распространении знаний. Со временем знания постепенно перейдут в сферу общественного достояния, где они станут «информацией», и в то же время будут создаваться новые знания.
Цель данной статьи - представить нейтральную с точки зрения реализации методологию использования и обмена знаниями в рамках более широкого и практического подхода, когда мы вступаем в «Век знаний».
2. Что такое моделирование знаний?
Если вы думаете, что информация ценна, тогда вы должны увидеть знания в действии!
“Сбор и моделирование знаний (KCM), или, вкратце, моделирование знаний - это междисциплинарный подход к сбору и моделированию знаний в формате многократного использования с целью сохранения, улучшения, совместного использования, замены, агрегирования и повторного применения. В компьютерном мире это используется для имитации интеллекта.”
Инновации, прогресс и процветание во многом зависят от принятия «правильных решений».
Хорошая новость в том, что принимать правильные решения нетрудно. Для рационального агента нет способа принимать неправильные решения, учитывая «все» факты и «четкую» цель. Единственная причина для принятия неправильных решений - пренебрежение фактами или неверное толкование цели.
Вот почему моделирование знаний является таким важным элементом когнитивной дисциплины и предпосылкой для достижения истинного искусственного интеллекта.
Выходя за рамки систем мышления на основе знаний (KBR) и рассуждений на основе прецедентов (CBR), моделирование знаний предлагает переход от локальных проприетарных решений к созданию и распространению встроенных моделей знаний в более крупные вычислительные решения с целью генерирования «прикладных знаний».
«Прикладные знания» очень важны для погружения в «Век знаний». «Прикладные знания» вносят свой вклад в множество видов интеллектуальной деятельности, от постоянного совершенствования до автоматизированного принятия решений или решения проблем, и, следовательно, увеличивают «интеллектуальный капитал» для будущих поколений человечества.
Фундаментальная цель KCM - объединить методологии и технологии в рамках нейтральной реализации в качестве практического решения для максимального использования знаний. Основное различие между работой с информацией и знаниями заключается в том, что - в дополнение к фактам - Модель знаний включает в себя постановку и имеет способность поддерживать интуицию, а также субъективность экспертов и/или пользователей.
В повседневных ситуациях люди принимают самые разные решения, чтобы действовать. В свою очередь, эти решения варьируются в зависимости от предпочтений, целей и привычек. В следующем примере, Рисунок 1 - Ситуационные эффекты, показано, как пол и возраст играют роль в процессе принятия решений.
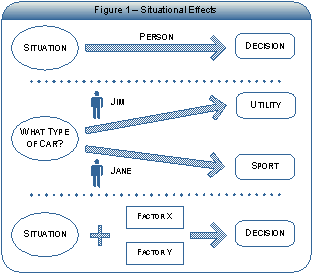
Таким образом, многие модели, такие как пример Джима и Джейн, могут быть выполнены только после назначения профиля. Профиль определяется как индивидуальная интерпретация входов модели.
KCM включает количественное и качественное использование информации и обрабатывает материальные и нематериальные атрибуты, которые способствуют конечному результату, например, решение Джима купить спортивный автомобиль. Сочетание количественных и качественных методов позволяет KCM включать субъективность, которая является основным отличием информации от знаний.
Каждая модель может иметь в качестве входа данные, информацию или выход других моделей. Таким образом, модели могут быть объединены в цепочку, вложены или агрегированы. Для единообразия в этой статье все входные данные модели рассматриваются как «информация». Таким образом, выходные данные модели будут называться информацией, когда они используются в качестве входных данных для другой модели.
Среди преимуществ модели знаний - возможность постоянного мониторинга и улучшения. Кроме того, модели знаний помогают нам извлекать уроки из прошлых решений, оценивать текущую деятельность и, что не менее важно, сохранять знания в предметной области. KCM экономит время и накладные расходы, а также снижает количество ошибок из-за недоработок.
Модели знаний очень ценны и часто переживают конкретную реализацию и/или проект. Соответственно, задача KCM состоит в том, что этот процесс должен быть разработан не только как абстрактная идея, но и как реализуемый процесс с возможностью агрегирования и распространения прикладных знаний с целью создания интеллектуального капитала для будущих поколений человечества.
3. Приложения
Существует бесчисленное множество возможных применений для KCM, так же как и бесчисленное количество интеллектуальной деятельности, выполняемой человечеством по всему миру.
В конечном итоге модели знаний будут использоваться для любой сложной задачи, включая «проектирование» и «планирование». Однако сегодня наиболее важным применением KCM являются приложения, называемые «интеллектуальными или умными приложениями». Есть приложения и инструменты, явно задействующие знания, как переиспользуемые избранные компоненты, охватывающие следующие области:
Мониторинг и Обнаружение
В этих приложениях модель знаний предоставляют возможности для мониторинга и обнаружения вредоносных действий, нарушения, закономерности или тенденцию и может вызвать действия, как результат. Действия могут охватывать множество сценариев, от уведомлений по электронной почте и SMS до автоматической обработки обращений (см. Раздел автоматизации ниже).
Думайте о сетевых вторжениях или системах обнаружения мошенничества с кредитными картами как о очевидных приложениях в этой категории. Однако, помимо приложений, которые используют мониторинг и обнаружение в качестве основного использования, эту функциональность можно добавить ко многим другим типам приложений, чтобы обеспечить совокупные преимущества помимо основной цели.
Подумайте о традиционной CRM-системе, которую можно дополнить моделью знаний для отслеживания тенденций в формировании потоков, доходов или обращений в службу поддержки; или систему бухгалтерского учета или управления персоналом, которая может быть расширена для обнаружения нарушений учетной политики.
Адаптация и Рекомендации
Модели знаний активно используются для профилирования и адаптации к среде, потребностям, привычкам и интересам пользователей и клиентов. Это обеспечивает более высокое качество самообслуживания и эффективную персонализацию в различных приложениях, от целевой рекламы и рекомендаций по продуктам до блогов и новостных сайтов.
Хорошими примерами такого использования являются такие компании, как NetFlix и Match.com, которые в какой-то момент решили сделать акцент на сложных моделях знаний для рекомендации. И которые с тех пор совершенствуют эти модели знаний силами специальной команды.
Формализация и автоматизация
Многие предприятия, операционные и системные процессы полностью или частично автоматизированы с использованием какого-либо программного обеспечения. В этой категории модели знаний диктуют и координируют выполнение ряда действий человека и системы в виде контролируемой последовательности в рамках методической, организованной структуры.
В качестве примера представьте себе работу с предупреждением о мошенничестве, результатом которого является последовательность требуемых регулирующими органами действий, таких как: отчетность SEC, приостановка учетной записи, уведомление клиента, расследование и т. Д.
Поддержка принятия решений
В этой категории модели знаний позволяют приложениям оказывать пользователям поддержку в принятии решений. Это может быть как простая контекстная справка, так и сложная, как прогнозирование кредитного риска в финансовых приложениях или автоматическое контурирование в объемной медицинской визуализации.
Эта категория, безусловно, самая большая и включает в себя такие области, как прогнозная аналитика, управляемое самообслуживание и системы диагностики.
Внутри каждой категории могут быть созданы самые разные приложения. Например, модель KCM может использоваться для инвестиционной деятельности, такой как оценка, определение степени рисков или внедрение передовой методологии в рабочий процесс комплексной проверки. Важность такой модели можно измерить по ее вкладу в «ожидаемую стоимость» инвестиционной сделки.
Уже существует множество приложений, которые прямо или косвенно используют модель KCM. Среди них инструменты разработки, такие как Analytica и Protégé, базы знаний, такие как Xaraya и KnowledgeStorm, а также модели рассуждений или аналитики, такие как MetaStock или Apoptosis, а также многие стратегические игры. Примечательно, что важным аспектом моделирования знаний является учет субъективности пользователей, который отсутствует во многих текущих решениях.
Моделирование знаний - не идеальное решение для каждой ситуации. Но есть много приложений, которые могут выиграть от KCM, например, в следующих ситуациях:
Количество или сложность параметров, задействованных в деятельности, затрудняет работу без риска упущения или без вычислительных средств.
Процесс принятия решений настолько важен, а ставки настолько высоки, что нельзя допускать ошибок. Другими словами, когда цена ошибки или ценность уверенности настолько высоки, что оправдывают усилия.
Оптимизация и/или постоянное улучшение повторяющихся действий.
Сохранять и развивать собственные усилия экспертов в данной области.
Сохранение и упаковка знаний о предметной области для передачи, совместного использования или продажи.
Облегчить принятие решений менее квалифицированными работниками.
Для автоматизации задач и/или бизнес-процессов.
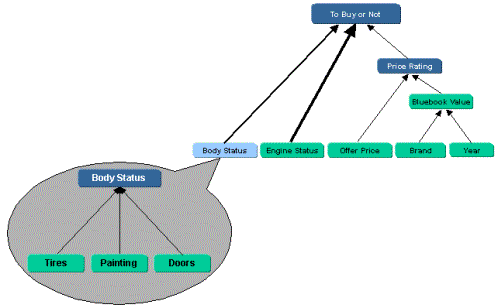
В приведенном ниже примере, Рисунок 2 - Упрощенный режим принятия решения, показана упрощенная модель принятия решения для «покупки подержанного автомобиля». В этом примере в процессе принятия решений используются как количественные, так и качественные элементы.

4. Типы моделей
На самом высоком уровне модели знаний можно разделить на следующие семь групп:
4.1 Диагностические модели
Этот тип модели используется для диагностики проблем путем классификации и определения проблем с целью определения первопричины или возможной причины.
Семантика: Жалоба » Возможная (-ые) причина (-ы)
Пример: у меня есть эти симптомы. В чем проблема?
4.2 Исследовательские модели
Этот тип модели разработан для создания возможных вариантов для конкретного случая. Варианты могут быть сгенерированы с использованием генетических алгоритмов или моделирования Монте-Карло, или извлечены из базы знаний и/или хранилища кейсов.
Семантика: Описание проблемы » Возможные альтернативы
Пример: Хорошо, я знаю проблему. Какие у меня варианты решения?
4.3 Селективные модели
Этот тип модели используется в основном для процесса принятия решений с целью оценки или выбора различных вариантов. Конечно, всегда есть как минимум две альтернативы; в противном случае нет необходимости принимать какое-либо решение.
Селективная модель различает кардинальные и порядковые результаты. С одной стороны, когда используется кардинальная модель, величина различий результатов является значимой величиной. С другой стороны, порядковые модели отражают только ранжирование, а не силу результата. Селективные модели могут использоваться для рационального выбора в условиях неопределенности или оценки и выбора альтернатив. Такой процесс отбора обычно должен учитывать и иметь дело с «конфликтующими целями».
Семантика: альтернативы » наилучший вариант
Пример: теперь я знаю варианты. Какой для меня лучше?
4.4 Аналитические модели
Аналитические модели в основном используются для анализа предварительно выбранных вариантов. Этот тип модели имеет возможность оценивать пригодность, риск или любые другие желаемые атрибуты пригодности. Во многих приложениях аналитическая модель является составной частью выборочной модели.
Семантика: Вариант » Фитнес
Пример: Я выбрал свой вариант. Насколько он хорош и подходит для моей цели?
4.5 Инструктивные модели
Инструктивные (или предписывающие) модели обеспечивают руководство в двунаправленном или интерактивном процессе. Среди примеров - множество решений по поддержке, доступных на рынке.
Семантика: Постановка проблемы » инструкции по решению
Пример: как я могу этого добиться?
4.6 Конструктивные модели
Конструктивная модель способна сама создать или сконструировать решение, а не выдавать инструкции по его достижению. Некоторые из недавно получивших популярность конструктивных моделей используются для генерации программных кодов для различных целей, от компьютерных вирусов до интерактивных мультимедиа файлов на таких веб-сайтах, как MySpace.com.
Семантика: Постановка проблемы » проект решения
Пример: Мне нужен <…> с этими спецификациями <…>.
4.7 Гибридные модели
Во многих случаях более сложные модели строятся путем вложения или объединения нескольких моделей вместе. Хотя это не всегда возможно, но - в идеале - каждая модель должна разрабатываться и реализовываться как независимый компонент. Это позволит упростить обслуживание и расширение в будущем. Сложное приложение полного цикла может включать и использовать все вышеперечисленные модели:
Диагностическая модель » Исследовательская модель » Селективная модель » Аналитическая модель » Конструктивная модель
5. Варианты технологий
В качестве наилучшего практического подхода модели знаний должны оставаться нейтральными к реализации и предоставлять экспертам KCM возможность гибкого выбора подходящей технологии для каждой конкретной реализации.
В целом технологические решения можно разделить на системы, основанные на кейсах, и системы, основанные на знаниях. Подход, основанный на конкретных случаях, фокусируется на решении новых проблем путем адаптации ранее найденных решений к аналогичным проблемам и сосредоточен на сборе знаний из историй болезни. Чтобы решить текущую проблему: проблема сопоставляется с аналогичными историческими случаями и корректируется в соответствии с конкретными атрибутами нового случая. Таким образом, они не требуют явного получения знаний от экспертов.
С другой стороны, экспертные или основанные на знаниях системы (KBS) ориентированы на прямое получение знаний от экспертов.
Существует множество методов и технологий, которые можно использовать в моделировании знаний, в том числе некоторые практики с перекрывающимися функциями. Ниже выделены наиболее часто используемые методы.
5.1 Дерево решений и AHP
Дерево решений - это граф вариантов и их возможных последствий, используемых для создания плана для достижения общей цели. Этот подход предоставляет дизайнерам структурированную модель для получения и моделирования знаний, подходящих для конкретного приложения.
Тесно связанный с деревом решений, AHP (процесс анализа иерархий), разработанный доктором Томасом Саати, представляет собой мощный подход к моделированию знаний, включающий как качественный, так и количественный анализ.
5.2 Байесовские сети и ANP
Системы, основанные на влиянии, такие как байесовская сеть (сеть убеждений) или ANP (аналитический сетевой процесс), обеспечивают интуитивно понятный способ определения и воплощения важных элементов, таких как решения, неопределенности и цели, в попытке лучше понять, как каждый влияет на другой.
5.3 Искусственная нейронная сеть
Искусственная нейронная сеть (ИНС) - это нелинейная математическая или логическая модель для обработки информации. В большинстве случаев ИНС - это адаптивная система, которая меняет свою структуру в зависимости от внешней или внутренней информации, проходящей через сеть. Она также решает проблемы, адаптируя ранее успешные решения к аналогичным проблемам.
5.4 Генетические и эволюционные алгоритмы
Вдохновленные биологической эволюцией, включая наследование, мутации, естественный отбор и рекомбинацию (или кроссовер), генетические и эволюционные алгоритмы используются для поиска неточных решений, которые включают оптимизацию и поиск проблем в исследовательских моделях (см. Типы моделей) .
5.5 Экспертные системы
Экспертные системы являются прародителями сбора и повторного использования знаний экспертов и обычно состоят из набора правил, которые анализируют информацию о конкретном случае. Экспертные системы также предоставляют анализ проблемы (ею). В зависимости от конструкции этот тип системы будет давать результат, например, рекомендовать пользователю порядок действий для внесения необходимых исправлений.
5.6 Статистические модели
Статистические модели - это математические модели, разработанные с использованием эмпирических данных. В эту группу входят 1) простая и/или множественная линейная регрессия, 2) дисперсионно-ковариационный анализ и 3) смешанные модели.
5.7 Механизмы правил
Другим эффективным инструментом моделирования знаний является Механизм правил, который классифицируется как Механизм правил вывода и Реактивные механизмы правил.
Механизм правил вывода используется для ответа на сложные вопросы, чтобы вывести возможные ответы. Например, ипотечная компания спросит: «Можно ли дать этому клиенту ссуду на покупку дома?»
Реактивные механизмы правил используются для обнаружения и реагирования на интересные паттерны происходящих событий и реагирования на них.
5.8 Системы рабочего процесса
Система рабочего процесса управляет операционным аспектом рабочей процедуры, анализируя:
как структурированы задачи,
кто их выполняет,
каков их относительный порядок,
как они синхронизируются,
как информация поступает в поддерживать задачи, и
как задачи отслеживаются.
Проблемы рабочего процесса можно моделировать и анализировать с помощью формализаций на основе графов, таких как сети Петри. (см. Измерение процесса управления знаниями)
5.9 Прочие
Другие технологии, которые можно использовать в моделировании знаний, включают традиционный подход к программированию и различные системы управления знаниями. В некоторых приложениях KCM можно использовать даже простые сценарии в Excel.
6. Процесс разработки
В процессе реализации моделирования знаний на протяжении всего проекта участвуют четыре основных заинтересованных лица, включая 1) поставщика знаний, 2) инженера и/или аналитика, 3) разработчика системы знаний и 4) пользователя знаний.
Многие проекты моделирования знаний объединяют ряд последовательных моделей, которые могут быть почти идентичными по конструкции, включать в себя разные значения решений или радикально отличаться друг от друга. Таким образом, специалисты KCM должны соответствующим образом спланировать, спроектировать и смоделировать решение.
В качестве общего принципа необходимо учитывать следующие правила:
Процесс разработки является повторяющимся и требует тщательного контроля.
Модели знаний часто перерастают конкретную реализацию - сначала сосредоточьтесь на концептуальной структуре и оставьте детали программирования для дальнейшего рассмотрения.
Будет большой спрос на расширяемость и текущее обслуживание.
Ошибки в базе знаний или модели могут вызвать серьезные проблемы для проекта.
Сосредоточьтесь на расширяемости, возможности повторного использования, функциональной совместимости, модульности и ремонтопригодности.
В идеале модели KCM должны максимально повторять человеческий разум и мыслительный процесс.
Ожиданиями нужно тщательно управлять. KCM - чрезвычайно мощный инструмент - он не решает частные проблемы.
Очень важно задавать правильные вопросы, понимать соответствующие классификации и консолидировать встроенные элементы.
Процесс разработки моделирования знаний состоит из следующих семи этапов:
Этап 1 Постановка цели и планирование
Этап 2 Выявление и анализ знаний
Этап 3 Выбор источника и/или доверенное лицо и агрегирование
Этап 4 Установка веса и профилирование
Этап 5 Создание прототипа и проверка выполнимости
Этап 6 Дизайн реализации
Этап 7 Мониторинг и обслуживание
6.1 Постановка целей и планирование
Этап постановки целей и планирования заключается в определении целей и требований проекта. Только четкое описание приведет к успешному проекту моделирования знаний. Убедитесь, что вы в достаточной степени управляете ожиданиями во время сегмента анализа требований.
Диагностируйте предпосылки » Установите цели и определите требования.
Что должно быть достигнуто? Каковы требования пользователя к вводу и выводу? Обобщайте как можно больше, сохраняя при этом компромиссы обобщения под контролем. Убедитесь, что уровень обобщения приемлем для Пользователя.
На этом этапе проекта модель знаний следует рассматривать как «черный ящик». Следует принять решение относительно ожидаемых входов и выходов модели (также называемых прямым входом/выходом). В зависимости от пользователя тип модели (включая требуемые для нее интерфейсы) может сильно различаться. Некоторые модели знаний используются только программно, в то время как для работы других может потребоваться вмешательство человека.

Модель знаний должна учитывать не только интерпретацию информации, но и последствия каждого пути решения и соответствующую чувствительность к риску. Эксперту KCM, возможно, придется управлять неопределенностью и качеством входных данных (или информации). Во многих случаях уровень уверенности представлен как вероятность в свете их возможных последствий.
Кроме того, примите во внимание тот факт, что Выходные данные модели могут привести к различным действиям, и последствия таких действий будут определять значение Выходных данных. В свою очередь, значение Выходных данных зависит от решаемой проблемы, а Выходные данные могут представлять другое значение в отдельном приложении. Первый вопрос, который нужно задать: «Как результат может повлиять на решение или действие?
6.2 Извлечение и декомпозиция знаний
Этап выявления и декомпозиции знаний фокусируется на извлечении знаний от экспертов, включая требования к входным данным высокого уровня и методы обработки в рамках структурированного и формализованного профиля. На базовом уровне Фаза 2 представляет независимое от реализации описание знаний, задействованных в данной задаче.
Выявление предметных знаний и несоответствие терминологии представляют собой проблему на этапе выявления и анализа знаний. Правильный вопрос (вопросы) - ключевой элемент решения этой проблемы.
В большинстве случаев, в дополнение к прямым входам, модели KCM требуют вспомогательных входов для получения результатов. В соответствии с целями, изложенными в Фазе 1, эксперты предметной области должны выбрать и определить необходимые вспомогательные входные данные для Модели. Эта вспомогательная информация должна использоваться при обработке модели для получения ожидаемых результатов.
Однако в идеальной ситуации модели KCM должны разрабатываться для работы независимо от вспомогательных входных данных или неопределенности. Чтобы компенсировать эту неполную способность к обработке, выходные данные модели могут включать вероятность, достоверность или уровень риска.
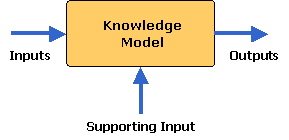
Этот этап будет включать интервью с экспертами в предметной области и другими заинтересованными сторонами для определения вспомогательных входных данных, необходимых для получения выходных данных и подхода к обработке. . Вспомогательные входы обычно включают материальные и нематериальные факторы и/или силы, влияющие на выходы.
В процессе собеседования следует учитывать разбивку входных данных для создания подмоделей с целью повышения удобства использования, точности и управляемости. Этот подход, называемый моделированием сверху вниз, часто дает наилучшие результаты в процессе собеседования.
Следующая диаграмма иллюстрирует разбивку одного из элементов решения в отдельной модели.

В следующем примере один из элементов оценки вынесен во внешнюю подмодель, которую можно использовать независимо. Такой подход позволяет пользователям контролировать, оценивать и, в конечном итоге, заменять подкомпоненты по отдельности, при желании вручную выбирая эквивалентные модели у других экспертов.
Советы по выявлению и декомпозиции знаний:
Сосредоточьтесь на наиболее влиятельных входах верхнего уровня и начните с них.
Начните с минимального количества параметров и постепенно разбивайте их на каждой итерации.
Даже входные данные с неизвестными и/или неопределенными значениями должны быть включены в модель.
Обратите внимание, что некоторые входные данные неизвестны и означают «мы не знаем, что мы их не знаем». Некоторые альтернативы реализации учитывают этот факт и включают в модель несколько ненаблюдаемых входов.
Сведите количество входов к минимуму; однако выбор правильных входов имеет решающее значение. Эти входные данные могут быть связаны нелинейно и иметь очень низкую корреляцию. Избегайте использования входов с высокой корреляцией.
Наиболее важным элементом на этапе выявления и декомпозиции знаний является правильное и полное определение входов и выходов. Деревья решений и диаграммы влияния могут оказаться полезными на этом этапе. Диаграмма влияния - это простое визуальное представление проблемы, предлагающее интуитивно понятный способ идентифицировать и отображать важные элементы, включая решения, неопределенности и цели, а также то, как они влияют друг на друга. Приложения Mind Mapping представляют собой еще один хороший инструмент для сбора информации в структурированном формате. Среди этих приложений FreeMind - один из лучших доступных вариантов.
6.3 Выбор и агрегация источника/прокси
На этом этапе каждый вход должен быть связан с источником и/или прокси. Прокси-источник может быть использован, если прямой источник невозможно идентифицировать. Основная цель этого этапа - сохранить модульность и простоту.
Имейте в виду, что некоторые входные данные могут потребовать личного суждения эксперта о неопределенности, в то время как другие входные данные могут быть получены программным способом из независимых источников.
Обратите особое внимание на компромиссы при работе с неопределенностью или качеством источников. В зависимости от источника, компромиссы могут быть решены одним из трех способов:
Обеспечение подачи входных данных, которые будут удовлетворять определенному уровню требований
Модель будет обрабатывать вспомогательные входные данные внутренне, предполагая определенную вероятность
Реализация модели сглаживает входные данные и классифицирует перед использованием.
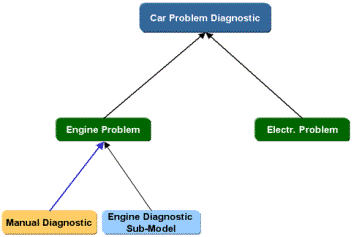
Входные данные должны быть проанализированы и, если возможно, консолидированы, поскольку некоторые входные данные могут использоваться в нескольких подмоделях. Кроме того, на этапе 3 может быть реализовано агрегирование нескольких моделей. Конкретные приложения могут получить выгоду от агрегирования параллельных моделей, как показано на диаграмме ниже. В этом примере и ручная, и полуавтоматическая подмодель диагностики объединены в основную модель. Такое агрегирование может обеспечить еще один уровень проверки для критически важных приложений.
6.4 Установка и профилирование весов
Чтобы зафиксировать субъективное мнение эксперта, модели KCM должны быть дополнены мерами важности или весами входных данных в рамках фазы настройки веса и профилирования. Эта ситуация позволит проводить калибровки в будущем без каких-либо изменений интерфейса модели (т.е. ввода/вывода). Чтобы создать превосходную модель для пользователей, исследователи также должны понимать и представлять цели пользователя. Таким образом, модели KCM должны поддерживать пользовательскую настройку для подгонки моделей к субъективности эксперта и пользователя, называемую «профилированием».
Как правило, приложения KCM можно персонализировать следующими способами:
Фиксированная модель, персонализированные веса
Одна и та же модель используется с разными весами.
Фиксированные веса, персонализированная модель (путем динамического выбора подмоделей)
Модель и ее веса фиксированы, но подмодели выбираются на основе предпочтений пользователя.
Динамический режим с индивидуальными весами и моделью
И модель, и ее веса настраиваются под пользователя.
Хотя первоначальная установка веса выполняется в процессе внедрения, модели должны поддерживать «изменение профиля». Это относится к корректировке весов во время выполнения в соответствии с предпочтениями пользователя.
Например, одна и та же аналитическая модель, предназначенная для оценки риска транзакции, может выполняться двумя разными профилями экспертов, чтобы использовать разные оценочные мнения.
Процесс получения и присвоения уровня важности входов называется «выявлением предпочтений», чтобы получить хорошее и полезное описание предпочтений и/или целей. В общем, трудно выявить предпочтения и цели из-за «нечеткого мышления» человеческого разума. Во многих случаях экспертам удобнее делать качественные заявления о предпочтениях, например: «Мне это нравится больше, чем это». Этот тип ранжирования (также известный как выявление сравнительных предпочтений) является очень полезным первым шагом для выбора весов внутри входных данных. В некоторых приложениях статистический анализ может использоваться для предложения начальных весов перед проверкой экспертом.
6.5 Прототипирование и проверка выполнимости
На этапе создания прототипа и технико-экономического обоснования проводится проверка концепции предложенной модели. Цель этого этапа - моделировать, связывать вместе и тестировать на ограниченном количестве примеров, связанных с модулями входов и планов, чтобы подтвердить решение поставленной задачи. Результат такой проверки осуществимости может привести к повторению предыдущей фазы.
Во многих случаях простая электронная таблица или дерево решений могут обеспечить достаточную поддержку для анализа осуществимости высокого уровня. Более глубокий анализ может быть проведен на каждом уровне подмодели.
Затем точность сравнивается с разницей между наблюдениями из известных случаев и выходными данными модели. Отклонения могут быть представлены в стандартных статистических формах, таких как среднеквадратичная ошибка (MSE). Уровень допустимой ошибки определяется с помощью анализа чувствительности.
Недостающие входные данные, безусловно, являются наиболее важными факторами, способствующими таким отклонениям. Таким образом, первым шагом к исправлению неэффективной модели является включение измененного выбора входных данных. Неосознанно эксперты иногда используют другие свободно доступные исходные данные из среды или исключительные ситуации, связанные с конкретными случаями, которые трудно выявить, если их прямо не спросить в процессе собеседования. Поэтому очень важно проверять все расхождения с ожидаемыми результатами с экспертами в предметной области.
Другими частыми причинами отклонений являются неправильные настройки веса и низкое качество вводимых оператором количественных данных.
Чтобы избежать одновременного возникновения нескольких точек отказа, каждый потенциальный источник проблемы в идеале должен рассматриваться изолированно. Использование одинаковой настройки веса поможет устранить одну точку отказа.
Кроме того, следует провести независимый тест профилирования для проверки модели с использованием разных профилей от разных экспертов.
6.6 Проектирование и реализация
На этапе проектирования и реализации модели KCM проектируются и передаются разработчикам для реализации. Правильный выбор дизайна и технологии - залог успешного проекта.
В какой-то момент модели должны будут иметь дело как с количественным, так и с качественным использованием входной информации в свете их значимости и цены приобретения. Поэтому при проектировании модели должны приниматься не только технические, но и экономические решения. Компромисс между точностью модели, производительностью и стоимостью эксплуатации будет определять требования к конструкции.
Лучший способ правильно справиться с этой ситуацией - выбрать правильное использование режима обработки ввода. Модели могут быть разработаны с параллельной или последовательной обработкой входных данных или их комбинацией. Параллельная обработка входных данных обеспечивает максимальную производительность, однако требует, чтобы все входные данные были представлены одновременно. Поскольку получение некоторых входов является чрезвычайно дорогостоящим, либо трудоемким, параллельная обработка входных данных не всегда возможна. В качестве альтернативы, последовательная обработка входных данных может устранить необходимость в некоторых входных данных, если это не применимо к представленному случаю, что позволяет сэкономить время и/или деньги.
Выбор правильной модели обработки в соответствии со значимостью и ценой приобретения для каждого входа приведет к оптимальному дизайну. Однако такая ситуация может быть невозможна, потому что некоторые входные данные требуют определенного режима обработки. На следующей диаграмме модель использует как параллельную, так и последовательную обработку входных данных, чтобы устранить ненужные потребности во входных данных.

Например, в модели выбора инвестиций норма прибыли (ROI) может использоваться изначально как самодостаточный фильтрующий элемент для исключения альтернатив с ожидаемой ROI ниже определенного порога. Но он также используется на более позднем этапе вместе с Риском в процессе выбора. Хотя и ROI, и риск сами по себе могут использоваться в процессе исключения, ни один из них не может использоваться в качестве автономных индикаторов в процессе выбора.
Поэтапный сбор входных данных может быть расширен до уровня приложения. В свою очередь, сбор данных может происходить в синхронизированном или асинхронном режиме. Например, система рабочего процесса может управлять процессом сбора данных в асинхронном режиме и публиковать результаты или уведомлять пользователей, когда выходы доступны. Когда нет требований к работе в реальном времени, более сложные приложения могут выиграть от такого асинхронного подхода в пользу экономии затрат и балансировки нагрузки.
На этом этапе необходимо принять решение о том, как поступать с отсутствующими входами. В то время как прямые входы обычно являются обязательными, вспомогательные входы должны разрабатываться как необязательные. Очевидно, что при определенных обстоятельствах это может быть невозможно.
Этого можно достичь, используя:
Значение по умолчанию
. Модель может использовать одно или несколько значений по умолчанию, которые будут использоваться для отсутствующих входных данных. Такие значения по умолчанию можно рассчитать как среднее статистическое значение.
Внимание: использование среднего значения может быть полезным во многих приложениях. Однако в некоторых случаях этот подход часто приводит к нежелательному эффекту компенсации. Как сказал Марк Твен: «Если человек ставит одну ногу в ведро со льдом, а другую - в ведро с кипящей водой, он в среднем чувствует себя очень комфортно».
Аппроксимация
Модель может быть разработана для аппроксимации значения отсутствующих входных данных на основе внутренних правил или других представленных входных данных.
Внутренний переключатель.
Модель-обертка может включать несколько моделей и внутренне переключаться на модель, разработанную без какой-либо зависимости от отсутствующих входных данных.
Как правило, модель будет включать четыре отдельных уровня, как показано ниже. Первый уровень будет управлять преобразованием данных. Во многих случаях входные данные необходимо преобразовать до начала фактической обработки. Модуль преобразования выполнит такую предварительную обработку.
Второй уровень - проверка входных данных в соответствии с требованиями модели. Несмотря на то, что проверка может выполняться на уровне приложения, в качестве передового подхода настоятельно рекомендуется наличие внутренней проверки данных модели. Затем может начаться фактическая обработка, третий уровень.

Наконец, полученные данные могут потребовать постобработки для возврата пользователю или приложению-оболочке.
6.7 Мониторинг и техническое обслуживание
Мониторинг и обслуживание - это непрерывный процесс на протяжении всей жизни моделей знаний. Уровень и сложность человеческих знаний постоянно растут, того же ожидают от модели знаний. Без поддержки и регулярного улучшения разработанные модели устаревают по мере изменения моделируемых знаний.
Иногда непрерывная калибровка может быть запроектирована и выполнена в автоматическом режиме, как это делается в системах неконтролируемого обучения, таких как ART-ANN (адаптивные нейронные сети) или кибернетические системы управления. Однако регулярный мониторинг и улучшения должны планироваться в контролируемой среде.
7. Заявление об ограничении ответственности
Этот документ не содержит советов по инвестициям, на него нельзя полагаться как на таковой, а также он не заменяет советы по инвестициям. Заявления и мнения, выраженные здесь, принадлежат исключительно автору и не предназначены для использования в качестве профессионального совета. Пользователь может полагаться на это на свой страх и риск, без обращения к автору и его ассоциациям.
8. Автор
Педжман Махфи - ветеран технологий Кремниевой долины, серийный предприниматель и бизнес-ангел в сфере высоких технологий. Педжман обладает более чем пятнадцатилетним прогрессивным опытом в предоставлении консультационных услуг и передового опыта предпринимателям, инвесторам в технологии и перспективным стартапам.
Широко известный как лидер в области автоматизации бизнес-процессов и моделирования знаний, Педжман имеет обширный опыт работы в программной и финансовой отраслях и был ключевым архитектором нескольких отмеченных наградами лидеров отрасли, таких как FinancialCircuit и Savvion.
Сегодня Педжман является директором по венчурному развитию в Singularity Institute, управляющим директором частной группы бизнес-ангелов и членом группы венчурного наставничества, где он оказывает помощь и руководит несколькими стартапами, включая Novamente и Perseptio.
Его опыт включает руководящую должность в TEN, ведущем технологическом инкубаторе Кремниевой долины, в котором работает более пятидесяти стартапов. Педжман руководил исследованиями и разработками TEN, а также консультировал клиентов по вопросам и тенденциям, влияющим на ранние и новые растущие компании. С момента своего создания TEN помог запустить более шестидесяти стартапов, включая eBay, iPrint, Xros, Vertical Networks, Right Works и Intruvert Networks.
Г-н Махфи имеет степень бакалавра/магистра компьютерных наук в Дортмундском университете в Германии и имеет международную лицензию проектного менеджера (PMP), а также сертифицированный черный пояс бережливого производства и шести сигм (SSBB) в области постоянного улучшения бизнеса. Он является автором множества патентов и стандартов и является активным участником таких организаций, как «Общество нейронных сетей IEEE», «Американская ассоциация искусственного интеллекта» и «Американское общество качества».
Г-н Махфи является автором множества статей, в том числе Heptalysis - The Venture Assessment Framework.
9. Авторские права
Авторские права на этот документ принадлежат автору, но с разрешения автора он может быть свободно загружен, переведен, распечатан, скопирован, цитирован, распространен на любых подходящих носителях, при условии, что он не будет изменен каким-либо образом в тексте или намерениях. и автор должным образом указан.

