Всем привет! Многие знают что такое Redis, а если вы не знаете, то официальный сайт может ввести вас в курс дела. Большинство знают Redis как кэш и иногда как очередь сообщений. Но что если немножко сойти с ума и попытаться спроектировать целое приложение, используя в качестве хранилища данных только лишь Redis? Какие задачи можно решить с использованием Redis'а?
В этой статье мы и попытаемся ответить на эти вопросы.
Не переключайтесь.
Чего не будет в этой статье?
В ней не будет подробного рассказа про каждую структуру данных Redis’а. Для этого лучше поискать отдельные статьи или почитать документацию.
Так же тут не будет продакшн реди кода, который вы могли бы использовать в своей работе.
Что будет в этой статье?
Будут использованы различные структуры данных Redis’а на примере реализации аналога дейтинг приложения.
Будут примеры кода на kotlin + spring boot.

Учимся создавать и запрашивать профили пользователей
Давайте первым шагом научимся создавать карточки с нашими пользователями: имена, лайки т.е. их профили по сути.
Для этого нам пригодится простое key value хранилище. Как это сделать?
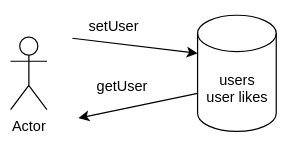
Очень просто, у редиса есть структура данных - hash. По сути своей это просто всем нам привычная hash map’а.
Достаешь по ключу. Кладешь по ключу. Все просто.
Команды к редису напрямую можно найти тут и тут. в документации даже есть интерактивное окошко чтобы прямо на сайте попробовать выполнить эти команды. А со всем списком команд можно ознакомиться вот тут.
Аналогичные ссылки работают и для всех последующих команд, которые мы будем рассматривать.
В коде же мы используем RedisTemplate и используем его практически везде. Это такая базовая вещь в экосистеме Spring'а для работы с Redis.
Единственное отличие тут от map’ы, что первым аргументом мы передаем так называемый field, т.е. наш hash с которым мы будем работать.
fun addUser(user: User) { val hashOps: HashOperations<String, String, User> = userRedisTemplate.opsForHash() hashOps.put(Constants.USERS, user.name, user) } fun getUser(userId: String): User { val userOps: HashOperations<String, String, User> = userRedisTemplate.opsForHash() return userOps.get(Constants.USERS, userId)?: throw NotFoundException("Not found user by $userId") }
Собственно выше приведен пример того, как это может выглядеть на kotlin с использованием библиотеки Spring’а.
На протяжении всей статьи будут использоваться аналогичные куски кода из github.
Обновляем лайки пользователей с использованием Redis листов
Отлично, теперь у нас есть пользователи с информация про лайки.
Теперь нужно найти способ как правильно обновлять эти лайки. Мы предполагаем что события могут происходить очень часто. И поэтому давайте используем асинхронную схему обновления через некую очередь. А информацию из очереди мы будем вычитывать по расписанию.

У редиса есть листы. И вот этот набор команд. Redis lists можно использовать и как очередь fifo, и как стек lifo.
В Spring’е работаем все по той же схеме, достаем необходимые operations, в этот раз нам нужны ListOperations из RedisTemplate.
Чтобы записать в list, нам нужно записать вправо, поскольку тут мы имитируем fifo очередь справа налево.
fun putUserLike(userFrom: String, userTo: String, like: Boolean) { val userLike = UserLike(userFrom, userTo, like) val listOps: ListOperations<String, UserLike> = userLikeRedisTemplate.opsForList() listOps.rightPush(Constants.USER_LIKES, userLike) }
И теперь по расписанию будем запускать нашу job'у и выполнять в ней уже необходимую нам логику.
По сути своей мы просто перекладываем информацию из одного типа данных редиса в другой. Этого нам достаточно для наглядного примера.
fun processUserLikes() { val userLikes = getUserLikesLast(USERS_BATCH_LIMIT).filter{ it.isLike} userLikes.forEach{updateUserLike(it)} }
Обновление нашего юзера максимально простое, привет HashOperations из предыдущего раздела.
private fun updateUserLike(userLike: UserLike) { val userOps: HashOperations<String, String, User> = userLikeRedisTemplate.opsForHash() val fromUser = userOps.get(Constants.USERS, userLike.fromUserId)?: throw UserNotFoundException(userLike.fromUserId) fromUser.fromLikes.add(userLike) val toUser = userOps.get(Constants.USERS, userLike.toUserId)?: throw UserNotFoundException(userLike.toUserId) toUser.fromLikes.add(userLike) userOps.putAll(Constants.USERS, mapOf(userLike.fromUserId to fromUser, userLike.toUserId to toUser)) }
Достаем значения из списка мы соответсвенно слева и мы хотим достать не одно значение, а сразу несколько и для этого используем метод range. И тут есть важный момент. С помощью range мы лишь получим данные из списка, но не удалим их.
Поэтому после получения наших данных нужно отдельной командой удалить их используя уже операцию trim(кажется тут уже могут возникнуть вопросы).
private fun getUserLikesLast(number: Long): List<UserLike> { val listOps: ListOperations<String, UserLike> = userLikeRedisTemplate.opsForList() return (listOps.range(Constants.USER_LIKES, 0, number)?:mutableListOf()).filterIsInstance(UserLike::class.java) .also{ listOps.trim(Constants.USER_LIKES, number, -1) } }
А вопросы, которые могут тут возникнуть это:
А как доставать данные из списка в несколько потоков?
И как гарантировать, что данные не потеряются в случае ошибки?
Такой возможности нет из коробки. Нужно получать данные из списка в одном потоке, а все возникающие нюансы обрабатывать самостоятельно.
Отправляем пуши пользователям с использованием pub/sub
Движемся, не останавливаемся!
У нас уже есть профили пользователей, и мы разобрались как обрабатывать поток лайков от этих самых пользователей.
Но что делать, если в случае взаимного лайка мы хотим сразу отправить push уведомление пользователю?
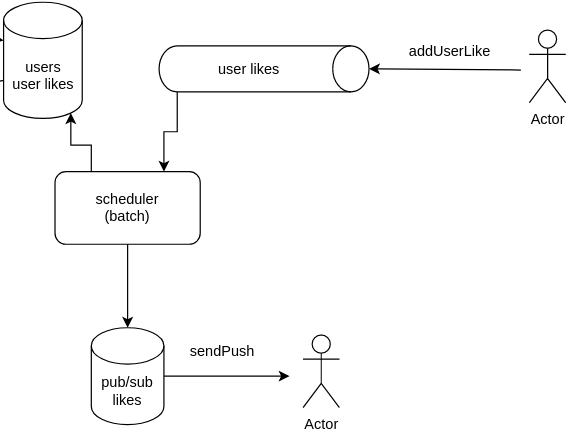
У нас уже есть асинхронный процесс обработки лайков, так давайте туда и встроим отправку push уведомлений. Отправлять мы их будем конечно по web socket’ам, и можно прям сразу как достали наш лайк, отправить его по вебсокету.
Но допустим, что мы хотим выполнить над ним некую долго-работающую логику или просто передать работу с вебсокетами одному компоненту, то как нам обойти новые ограничения?
Мы возьмем и вновь переложим наши данные из одного типа данных Redis'а (list) в другой тип данных Redis'а (pub/sub).
fun processUserLikes() { val userLikes = getUserLikesLast(USERS_BATCH_LIMIT).filter{ it.isLike} pushLikesToUsers(userLikes) userLikes.forEach{updateUserLike(it)} } private fun pushLikesToUsers(userLikes: List<UserLike>) { GlobalScope.launch(Dispatchers.IO){ userLikes.forEach { pushProducer.publish(it) } } }
@Component class PushProducer(val redisTemplate: RedisTemplate<String, String>, val pushTopic: ChannelTopic, val objectMapper: ObjectMapper) { fun publish(userLike: UserLike) { redisTemplate.convertAndSend(pushTopic.topic, objectMapper.writeValueAsString(userLike)) } }
Привязка слушателя к топику располагается в конфигурации.
Таким образом мы можем вынести нашего подписчика в отдельный сервис.
@Component class PushListener(val objectMapper: ObjectMapper): MessageListener { private val log = KotlinLogging.logger {} override fun onMessage(userLikeMessage: Message, pattern: ByteArray?) { // websocket functionality would be here log.info("Received: ${objectMapper.readValue(userLikeMessage.body, UserLike::class.java)}") } }
Находим ближайших пользователей через geo операции
С лайками разобрались, но, что за тиндер без возможности находить ближайших пользователей к заданной точке.
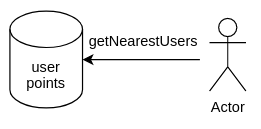
GeoOperations - наше решение. Мы будем хранить key value пары, id пользователя и его координаты.
А использовать мы будем метод radius передавая id пользователя, относительно которого будем искать, и соответственно сам радиус поиска.
Redis возвращает результат включая user id, которое мы передали
fun getNearUserIds(userId: String, distance: Double = 1000.0): List<String> { val geoOps: GeoOperations<String, String> = stringRedisTemplate.opsForGeo() return geoOps.radius(USER_GEO_POINT, userId, Distance(distance, RedisGeoCommands.DistanceUnit.KILOMETERS)) ?.content?.map{ it.content.name}?.filter{ it!= userId}?:listOf() }
Обновляем расположение пользователей через streams
Почти все, что необходимо реализовали, но у нас снова ситуация как с лайками пользователей, только теоретически вызовов метода изменения координат пользователя может происходить на много чаще.
Поэтому нам снова нужна очередь, но хорошо бы иметь что-то более масштабируемое.
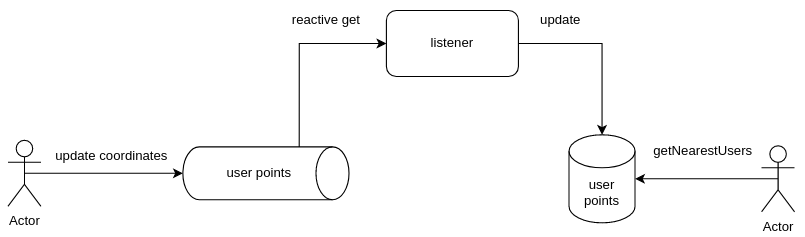
Redis streams могут помочь в решении этой проблемы.
Вероятно многие знают про то, что такое Kafka и что есть Kafka streams, но это совершенно разные вещи. А вот сама концепция Kafka это как раз очень похоже на Redis streams. Это так же write ahead log структура данных, у которой есть consumer group и offset.
Это уже более сложная структура данных, но она позволяет в отличии от lists отрабатывать данные параллельно и используя реактивный подход.
Для подробностей стоит обратиться к документации.
В Spring для работы со структурами данных Redis'а есть ReactiveRedisTemplate и RedisTemplate. Чтобы записать значение нам более удобно было бы использовать RedisTemplate, а для чтения уже ReactiveRedisTemplate. Если речь про streams. Но в таком случаи ничего работать не будет.
Если кто-то в курсе про то из-за чего это так работает, из-за Spring или Redis, то напишите в комментариях.
fun publishUserPoint(userPoint: UserPoint) { val userPointRecord = ObjectRecord.create(USER_GEO_STREAM_NAME, userPoint) reactiveRedisTemplate .opsForStream<String, Any>() .add(userPointRecord) .subscribe{println("Send RecordId: $it")} }
А наш метод слушателя будет выглядеть следующим образом:
@Service class UserPointsConsumer( private val userGeoService: UserGeoService ): StreamListener<String, ObjectRecord<String, UserPoint>> { override fun onMessage(record: ObjectRecord<String, UserPoint>) { userGeoService.addUserPoint(record.value) } }
Тут мы просто перемещаем наши данные уже в структуру данных для geo поиска.
Считаем уникальные сеансы с использованием HyperLogLog
Ну и напоследок давайте представим, что нам нужно посчитать сколько пользователей зашли в приложение за день.
Причем условимся, что пользователей у нас может быть оооочень много. Поэтому простой вариант через hash map нам не подходит из-за того, что будет потреблять много памяти. Как мы это можем сделать используя меньше ресурсов?
Тут на сцену выходит такая вероятностная структура данных как hyper log log. Интересующиеся могут почитать подробнее про нее уже самостоятельно в википедии. Ключевая ее особенность в том, что эта структура данных позволяет нам решать нашу задачу с использованием значительно меньшего количества памяти, чем вариант с hash map.
fun uniqueActivitiesPerDay(): Long { val hyperLogLogOps: HyperLogLogOperations<String, String> = stringRedisTemplate.opsForHyperLogLog() return hyperLogLogOps.size(Constants.TODAY_ACTIVITIES) } fun userOpenApp(userId: String): Long { val hyperLogLogOps: HyperLogLogOperations<String, String> = stringRedisTemplate.opsForHyperLogLog() return hyperLogLogOps.add(Constants.TODAY_ACTIVITIES, userId) }

Заключение
В данной статье мы рассмотрели различные структуры данных Redis’а. Включая geo операции и hyper log log, о которых мало кто знает. Использовали их для решения реальных задач.
Спроектировали по сути целый Tinder, можно и в FAANG после такого :-) Попутно подсветили основные нюансы и проблемы, с которыми можно столкнуться при работе с Redis.
Redis очень функциональное хранилище данных и возможно, если в вашей инфраструктуре он уже есть, то стоит посмотреть, какие ещё свои задачи вы можете решать используя уже то, что у вас и так есть без лишних усложнений.
P.S.:
Все примеры кода можно найти на github.
Пишите в комментарии, если что-то не достаточно точно описано.
Так же пишите как вам вообще подобный формат описания того как использовать ту или иную технологию.
И подписывайтесь в твиттере ? @de____ro

