Парадокс pull request-ов можно объяснить так. Я только что закончил писать код, который может хорошо сказаться на опыте наших пользователей, и хочу поскорее запустить его в работу. Мне нужна ваша помощь, но вы заняты и в большей степени склонны работать над собственным кодом.
— Я только что написал решение для важной проблемы, мне нужна инспекция кода.
— А я сейчас занята решением другой важной проблемы...
Pull request-ы появились в мире открытого кода и были необходимой мерой. Нужен был какой-то способ контролировать вклад от участников проектов со всего мира. В GitHub создали соответствующее решение для тех, кто работает с открытым кодом, а вскоре Git получил широкое распространение в корпоративном мире, несмотря на то, что большая часть его пользователей работала в офисе. Впрочем, сейчас круг замкнулся, и мы стали массово уходить на удаленку. Получается, pull request-ы стали актуальны, как никогда прежде? Возможно.
Однако рост популярности pull request-ов означает, что возникает новое препятствие между нашим кодом и слиянием/релизом. Раньше сотрудники просматривали код друг друга непосредственно в кабинете – в процессе парного программирования или синхронизированной проверки. Закончили – внесли код в проект. Сейчас pull request-ы по большей части проходят процедуру одобрения асинхронно, с многократной пересылкой файлов туда-сюда. По этой причине в процессе возникают периоды простоя, которых не было раньше.
И что же плохого в этом простое? Ведь мы не сидим сложа руки, пока ждем, когда коллега просмотрит нашу работу. Отправляем pull request и беремся за что-то другое. Но, как выясняется, такие периоды простоя выбивают разработчика из колеи, и в процедуре одобрения pull request-ов эта проблема стоит особенно остро.

(спустя несколько часов)
— Есть пара вопросов по твоему коду....
Команда специалистов по data science из компании LinearB проанализировала 733 000 pull request-ов и 3,9 миллиона комментариев от 26 000 разработчиков и выяснила следующее:
Иными словами, на каждый этап работы приходится в среднем где-то два дня простоя! Моя команда страдает от такого положения дел. Это не просто действует на нервы, это создает реальные проблемы с производительностью.
Мы не можем вносить код в базу и выпускать продукт. Наша миссия – решать проблемы (часто путем написания кода, способного их решать) и передавать решения в руки пользователей как можно быстрее. Периоды простоя блокируют релизы и не позволяют нам распространять ценные возможности.
Из-за простоя разработчики теряют контекст, тратят дополнительные усилия и создают менее качественные продукты. С каждым часом, который проходит от создания нового pull request-а, для того, чтобы вернуться к этому коду, требуется всё больше и больше когнитивных усилий. Если мне пришлют вопросы и предложения по фрагменту кода спустя день или два, будет очень сложно снов�� восстановить то состояние потока, в котором я пребывал, когда его писал. Это можно сравнить с процессом работы над статьей для блога – каждый раз, когда я за нее сажусь, приходится перечитывать то, что уже написано, и только после этого можно продолжать.
Периоды простоя вредят качеству кода – когда в продакшне возникают проблемы с кодом, который я писал много дней, а то и недель назад, устранять баги становится намного сложнее.

В пятницу вечером: Отлично, закончу в понедельник.
В понедельник утром: Да что всё это значит?!
Команда срывает сроки. Лидам и так тяжело приходится с планированием спринтов, которое соответствовало бы действительности. Из-за простоя и затягивающихся циклов процессы становятся более непредсказуемыми, и сроки срываются.
Сейчас многие предлагают альтернативы pull request-ам.
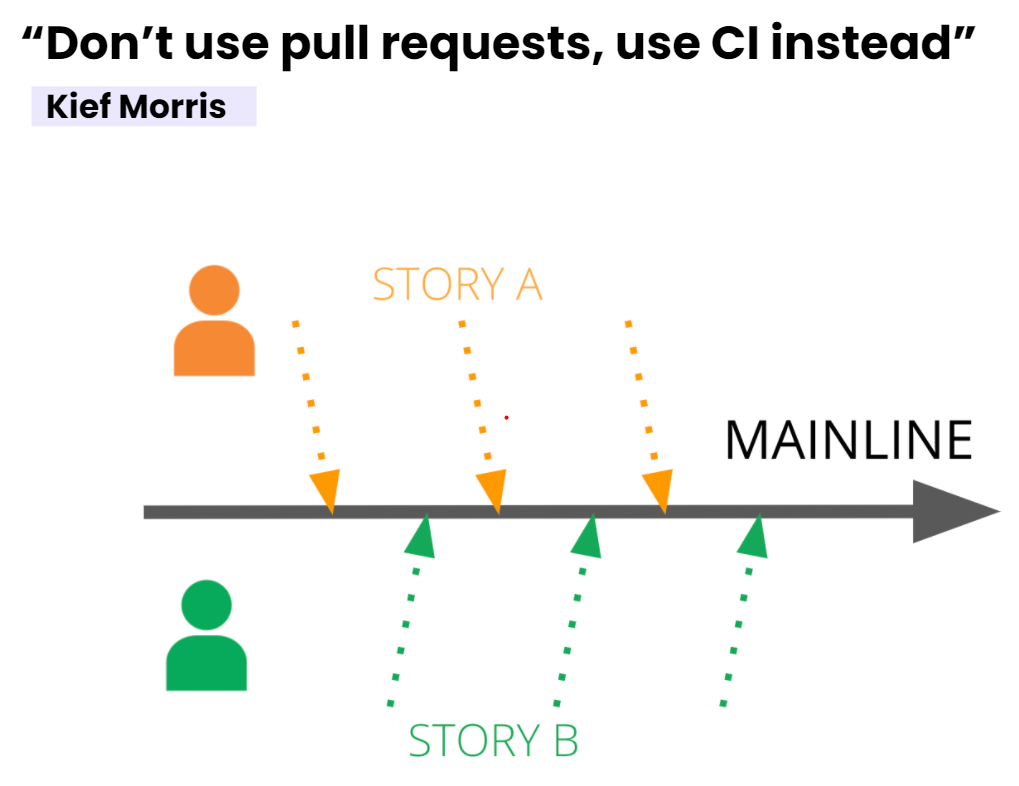
Непрерывная интеграция в истинном смысле слова. В последнее время стала популярна точка зрения, согласно которой pull request-ы и непрерывная интеграция – взаимоисключающие понятия. «Стволовой» подход к разработке позволяет разработчикам вносить код непосредственно в основную ветвь – никаких процедур инспекции и слияния. Для отдельных элитных команд такой подход, возможно, сработает, но для оставшихся 95% минусов окажется больше, чем плюсов.
Система Ship / Show / Ask, которую Руан Уилсенах определил следующим образом: «Это стратегия ветвления, которые совмещает систему pull request-ов с градацией сохранения изменений. Изменения классифицируются по трем типам: Ship – слияние с основной ветвью происходит без проверки, Show – pull request открывается для проверки, но сразу же проводится слияние с основной ветвью; Ask – перед слиянием открывается обсуждение по pull request-у».
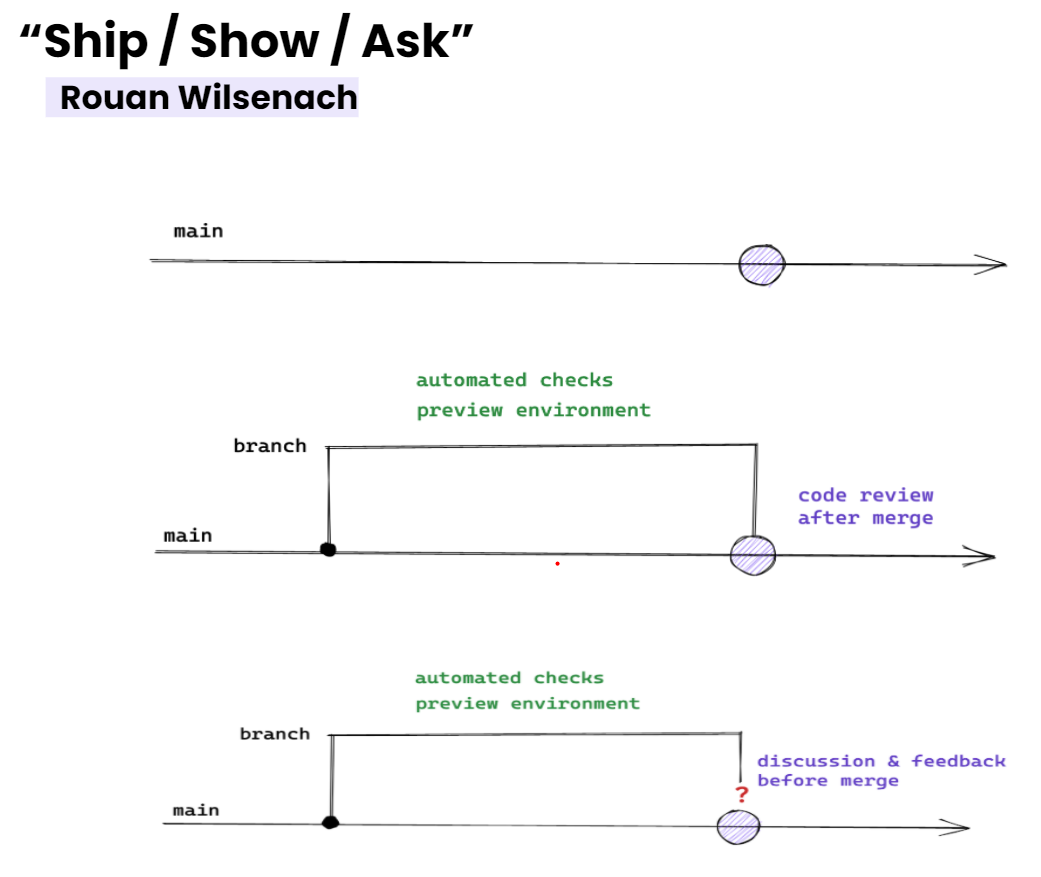
Мне очень нравится такой подход. Не все pull request-ы одинаковы. Если ставки невысоки, вполне разумно проводить слияние без инспекции или просматривать код постфактум. Проблема тут только в том, что у большей части команд, которые мне встречались, нет устоявшихся процессов, терминологии и автоматизации, которые необходимы для работы системы.
Парное программирование. Парное программирование – это замечательно, но теперь, с переходом на удаленный режим, возникают некоторые сложности с его организацией. Я знаю целый ряд команд, которые применяют совместную работу дополнительно к асинхронной проверке pull request-ов, однако лично мне еще не доводилось работать в команде, где она полностью бы их вытеснила.
Сомневаюсь, что pull request-ы себя изживут. По моему опыту, передать свою работу коллеге на проверку, прежде чем отправлять на слияние – самый простой и наименее затратный способ повышать качество кода и снижать число багов. Особенно эффективны pull request-ы против багов, связанных с поддержкой кода в будущем – автоматизированные тесты отлавливают их плохо.
Я провел опрос среди участников сообщества Dev Interrupted в Discord и обнаружил немало разработчиков, которые считают, что pull request-ы – отличный инструмент, который позволяет держать качество продукта на уровне и обмениваться знаниями. Предполагается, что за следующие десять лет количество разработчиков возрастет с двадцати миллионов до сорока. А это значит, что появится много новичков, которым не повредит, чтобы их код кто-то дополнительно просматривал.

У pull request-ов есть своя ценность, но есть и серьезный недостаток. Что же нужно поменять в процессах, чтобы не упускать ценность, но при этом сокращать время простоя и быстрее вносить код в основную ветвь? Наша команда в прошлом коду опробовала новый принцип, который дал неплохой эффект.
Долгое время мне казалось, что с этим парадоксом ничего не поделаешь. Уж так сложилось. А потом мне попалось исследование под названием «Какие pull request-ы одобряют и почему». В статье отмечалось, что pull request-ы небольшого размера чаще получают одобрение. Это хорошо соотносится с древним преданием: возьмите маленький pull request – и там будет несколько вдумчивых комментариев, возьмите большой – и там будет один комментарий: «Всё норм».
И неудивительно. Когда лично я задумываюсь, не взять ли в работу pull request от коллеги, то небольшой, который можно легко втиснуть между другими задачами, скорее возьму, а крупный – скорее отложу. И это навело меня на мысль: какая еще информация о pull request-е подвигнет меня быстро его обработать? И наоборот, какая информация замедлит этот процесс?
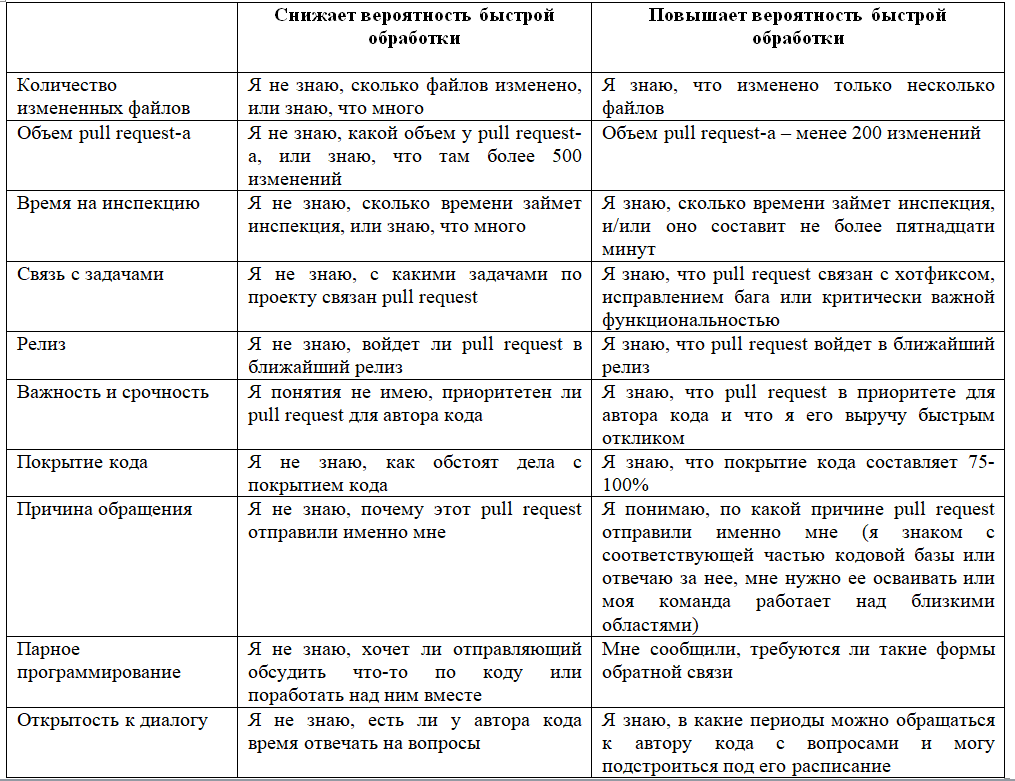
Разработчик не может считать свою работу законченной, прежде чем его код не окажется в основной ветви. А внести его туда не получится без помощи коллег. А у коллег своей работы хватает. Поэтому в команде LinearB мы стали приде��живаться такого взгляда: когда открываешь pull request, твоя задача – сделать его привлекательнее для проверяющего. Мы даем как можно больше информации, чтобы проще было вникнуть и быстро дать отклик. Мы ведь уже потратили массу времени на написание важного кода, самое меньшее, что можно сделать для себя и для коллег – не пожалеть еще пяти минут, чтобы представить свою работу в нужном контексте. Мы составили список из десяти типов сведений, которые предоставляем, чтобы проверяющему было проще. Если у вас есть какие-то еще идеи – автор будет рад их услышать.
Наша команда примерно пять месяцев использовала этот список, заточенный на то, чтобы «продать» pull request за счет дополнительного контекста. Некоторые преимущества были предсказуемы: код стал попадать в базу быстрее и процесс инспекции стал вызывать у разработчиков гораздо меньше раздражения. Но другие плюсы оказались неожиданными: например, некоторые из наших молчаливых разработчиков стали отмечать, что теперь им стало легче пройти инспекцию, потому что контекст делает процесс демократичнее и не нужно приставать к людям с просьбами помочь.
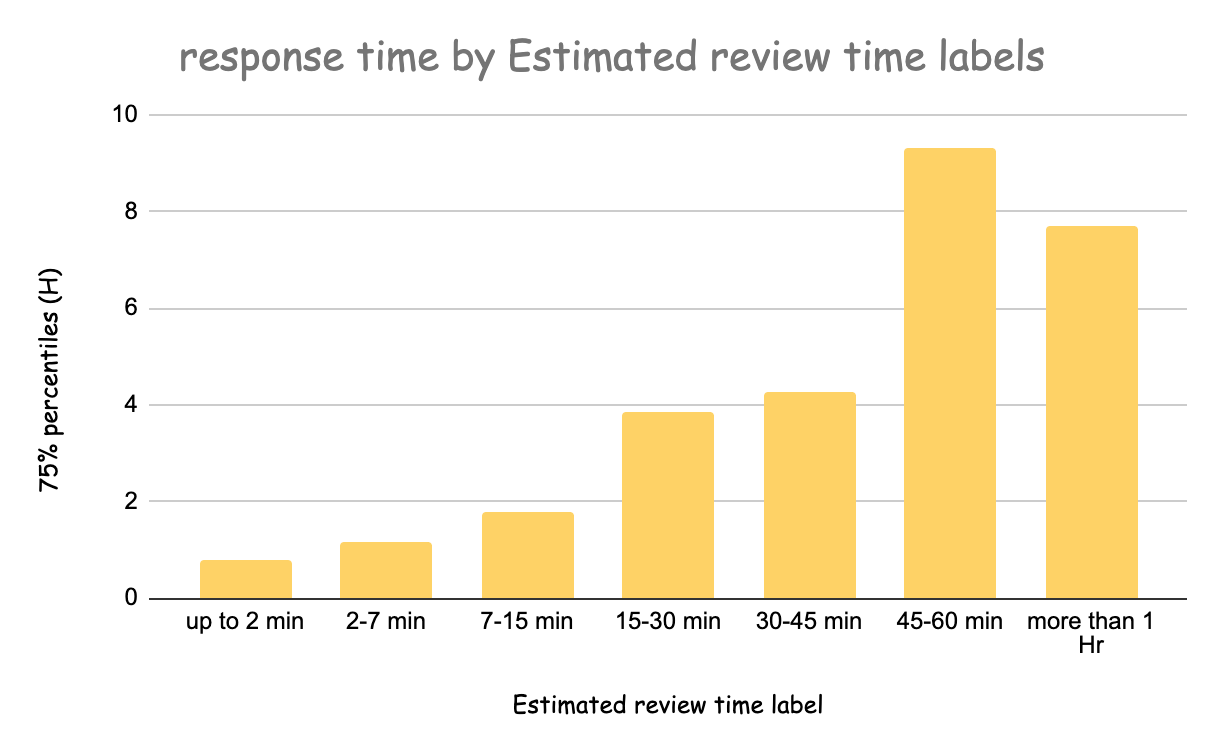
Еще один плюс – постоянное напоминание о том, что нужно дробить работу на небольшие фрагменты. Маленькие pull request-ы составляют основу разработки по Agile, но ввести их на практике все равно непросто. Мы отслеживаем сроки инспекции pull request-ов и обнаружили явные свидетельства того, что небольшие pull request-ы, которые оцениваются в небольшое время, обрабатываются гораздо быстрее, чем крупные, на которые, по оценке, нужно больше времени.
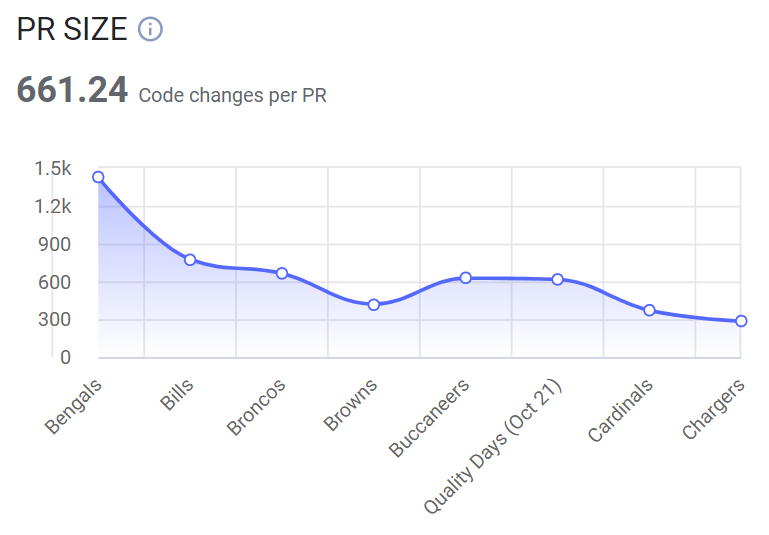
И в то же время, как можете видеть, за тот же период размер среднего pull request-а уменьшился. Совпадение? Сомневаюсь.
Сейчас, на базе того, что мы узнали о параметрах привлекательности pull request-ов, наша команда создает специальный инструмент, который помогает снабдить pull request всем необходимым, включая сведения о размере (в файлах, числе изменений и строках кода), примерное время обработки, ссылки на связанные задачи, мемы и гифки и многое другое. Если хотите его опробовать, записывайтесь к нам на бета-тестирование.
— Я только что написал решение для важной проблемы, мне нужна инспекция кода.
— А я сейчас занята решением другой важной проблемы...
Очень, очень сжатая история pull request-ов
Pull request-ы появились в мире открытого кода и были необходимой мерой. Нужен был какой-то способ контролировать вклад от участников проектов со всего мира. В GitHub создали соответствующее решение для тех, кто работает с открытым кодом, а вскоре Git получил широкое распространение в корпоративном мире, несмотря на то, что большая часть его пользователей работала в офисе. Впрочем, сейчас круг замкнулся, и мы стали массово уходить на удаленку. Получается, pull request-ы стали актуальны, как никогда прежде? Возможно.
Однако рост популярности pull request-ов означает, что возникает новое препятствие между нашим кодом и слиянием/релизом. Раньше сотрудники просматривали код друг друга непосредственно в кабинете – в процессе парного программирования или синхронизированной проверки. Закончили – внесли код в проект. Сейчас pull request-ы по большей части проходят процедуру одобрения асинхронно, с многократной пересылкой файлов туда-сюда. По этой причине в процессе возникают периоды простоя, которых не было раньше.
Как парадокс вредит разработчикам
И что же плохого в этом простое? Ведь мы не сидим сложа руки, пока ждем, когда коллега просмотрит нашу работу. Отправляем pull request и беремся за что-то другое. Но, как выясняется, такие периоды простоя выбивают разработчика из колеи, и в процедуре одобрения pull request-ов эта проблема стоит особенно остро.
(спустя несколько часов)
— Есть пара вопросов по твоему коду....
Команда специалистов по data science из компании LinearB проанализировала 733 000 pull request-ов и 3,9 миллиона комментариев от 26 000 разработчиков и выяснила следующее:
- У 50% pull request-ов 50,4% всего жизненного цикла состояло из периодов простоя.
- У 33% pull request-ов доля «пустого» времени доходила до 77,8% жизненного цикла.
- Средняя продолжительность цикла для разработчиков из выборки составляла шесть дней и пять часов.
- Средняя продолжительность инспекции для них же составляла четыре дня и семь часов.
Иными словами, на каждый этап работы приходится в среднем где-то два дня простоя! Моя команда страдает от такого положения дел. Это не просто действует на нервы, это создает реальные проблемы с производительностью.
Мы не можем вносить код в базу и выпускать продукт. Наша миссия – решать проблемы (часто путем написания кода, способного их решать) и передавать решения в руки пользователей как можно быстрее. Периоды простоя блокируют релизы и не позволяют нам распространять ценные возможности.
Из-за простоя разработчики теряют контекст, тратят дополнительные усилия и создают менее качественные продукты. С каждым часом, который проходит от создания нового pull request-а, для того, чтобы вернуться к этому коду, требуется всё больше и больше когнитивных усилий. Если мне пришлют вопросы и предложения по фрагменту кода спустя день или два, будет очень сложно снов�� восстановить то состояние потока, в котором я пребывал, когда его писал. Это можно сравнить с процессом работы над статьей для блога – каждый раз, когда я за нее сажусь, приходится перечитывать то, что уже написано, и только после этого можно продолжать.
Периоды простоя вредят качеству кода – когда в продакшне возникают проблемы с кодом, который я писал много дней, а то и недель назад, устранять баги становится намного сложнее.
В пятницу вечером: Отлично, закончу в понедельник.
В понедельник утром: Да что всё это значит?!
Команда срывает сроки. Лидам и так тяжело приходится с планированием спринтов, которое соответствовало бы действительности. Из-за простоя и затягивающихся циклов процессы становятся более непредсказуемыми, и сроки срываются.
Может, нам просто отказаться от pull request-ов?
Сейчас многие предлагают альтернативы pull request-ам.
Непрерывная интеграция в истинном смысле слова. В последнее время стала популярна точка зрения, согласно которой pull request-ы и непрерывная интеграция – взаимоисключающие понятия. «Стволовой» подход к разработке позволяет разработчикам вносить код непосредственно в основную ветвь – никаких процедур инспекции и слияния. Для отдельных элитных команд такой подход, возможно, сработает, но для оставшихся 95% минусов окажется больше, чем плюсов.
Система Ship / Show / Ask, которую Руан Уилсенах определил следующим образом: «Это стратегия ветвления, которые совмещает систему pull request-ов с градацией сохранения изменений. Изменения классифицируются по трем типам: Ship – слияние с основной ветвью происходит без проверки, Show – pull request открывается для проверки, но сразу же проводится слияние с основной ветвью; Ask – перед слиянием открывается обсуждение по pull request-у».
Мне очень нравится такой подход. Не все pull request-ы одинаковы. Если ставки невысоки, вполне разумно проводить слияние без инспекции или просматривать код постфактум. Проблема тут только в том, что у большей части команд, которые мне встречались, нет устоявшихся процессов, терминологии и автоматизации, которые необходимы для работы системы.
Парное программирование. Парное программирование – это замечательно, но теперь, с переходом на удаленный режим, возникают некоторые сложности с его организацией. Я знаю целый ряд команд, которые применяют совместную работу дополнительно к асинхронной проверке pull request-ов, однако лично мне еще не доводилось работать в команде, где она полностью бы их вытеснила.
Сомневаюсь, что pull request-ы себя изживут. По моему опыту, передать свою работу коллеге на проверку, прежде чем отправлять на слияние – самый простой и наименее затратный способ повышать качество кода и снижать число багов. Особенно эффективны pull request-ы против багов, связанных с поддержкой кода в будущем – автоматизированные тесты отлавливают их плохо.
Я провел опрос среди участников сообщества Dev Interrupted в Discord и обнаружил немало разработчиков, которые считают, что pull request-ы – отличный инструмент, который позволяет держать качество продукта на уровне и обмениваться знаниями. Предполагается, что за следующие десять лет количество разработчиков возрастет с двадцати миллионов до сорока. А это значит, что появится много новичков, которым не повредит, чтобы их код кто-то дополнительно просматривал.
Перевод
Когда я ушел из мобильной разработки в бэкенд, мне очень помог подтянуться один сениор, который на некоторые мои pull request-ы оставлял по сорок и больше комментариев. Тогда меня это немного раздражало, казалось, что он не дает мне работать самостоятельно, но теперь я ему благодарен за то, что не жалел времени меня учить.
У pull request-ов есть своя ценность, но есть и серьезный недостаток. Что же нужно поменять в процессах, чтобы не упускать ценность, но при этом сокращать время простоя и быстрее вносить код в основную ветвь? Наша команда в прошлом коду опробовала новый принцип, который дал неплохой эффект.
Долгое время мне казалось, что с этим парадоксом ничего не поделаешь. Уж так сложилось. А потом мне попалось исследование под названием «Какие pull request-ы одобряют и почему». В статье отмечалось, что pull request-ы небольшого размера чаще получают одобрение. Это хорошо соотносится с древним преданием: возьмите маленький pull request – и там будет несколько вдумчивых комментариев, возьмите большой – и там будет один комментарий: «Всё норм».
И неудивительно. Когда лично я задумываюсь, не взять ли в работу pull request от коллеги, то небольшой, который можно легко втиснуть между другими задачами, скорее возьму, а крупный – скорее отложу. И это навело меня на мысль: какая еще информация о pull request-е подвигнет меня быстро его обработать? И наоборот, какая информация замедлит этот процесс?
У каждого pull request-а есть продавец и покупатель
Разработчик не может считать свою работу законченной, прежде чем его код не окажется в основной ветви. А внести его туда не получится без помощи коллег. А у коллег своей работы хватает. Поэтому в команде LinearB мы стали приде��живаться такого взгляда: когда открываешь pull request, твоя задача – сделать его привлекательнее для проверяющего. Мы даем как можно больше информации, чтобы проще было вникнуть и быстро дать отклик. Мы ведь уже потратили массу времени на написание важного кода, самое меньшее, что можно сделать для себя и для коллег – не пожалеть еще пяти минут, чтобы представить свою работу в нужном контексте. Мы составили список из десяти типов сведений, которые предоставляем, чтобы проверяющему было проще. Если у вас есть какие-то еще идеи – автор будет рад их услышать.
Наша команда примерно пять месяцев использовала этот список, заточенный на то, чтобы «продать» pull request за счет дополнительного контекста. Некоторые преимущества были предсказуемы: код стал попадать в базу быстрее и процесс инспекции стал вызывать у разработчиков гораздо меньше раздражения. Но другие плюсы оказались неожиданными: например, некоторые из наших молчаливых разработчиков стали отмечать, что теперь им стало легче пройти инспекцию, потому что контекст делает процесс демократичнее и не нужно приставать к людям с просьбами помочь.
Еще один плюс – постоянное напоминание о том, что нужно дробить работу на небольшие фрагменты. Маленькие pull request-ы составляют основу разработки по Agile, но ввести их на практике все равно непросто. Мы отслеживаем сроки инспекции pull request-ов и обнаружили явные свидетельства того, что небольшие pull request-ы, которые оцениваются в небольшое время, обрабатываются гораздо быстрее, чем крупные, на которые, по оценке, нужно больше времени.
И в то же время, как можете видеть, за тот же период размер среднего pull request-а уменьшился. Совпадение? Сомневаюсь.
Сейчас, на базе того, что мы узнали о параметрах привлекательности pull request-ов, наша команда создает специальный инструмент, который помогает снабдить pull request всем необходимым, включая сведения о размере (в файлах, числе изменений и строках кода), примерное время обработки, ссылки на связанные задачи, мемы и гифки и многое другое. Если хотите его опробовать, записывайтесь к нам на бета-тестирование.

