Всем привет, меня зовут Сергей, я занимаюсь тестированием производительности. Недавно поднялся вопрос в выборе инструмента для воспроизведения довольно интенсивной нагрузки, в основном по HTTP. Инструментов для тестирования производительности сейчас представлено довольно много, в том числе многие из них являются Open Source — проектами и доступны бесплатно. Стало интересно, какой же инструмент справится с подобной задачей лучше, сможет воспроизвести большую нагрузку затратив меньше ресурсов.
Решил поставить несколько популярных инструментов в одинаковые условия и проверить результат. Если интересно что из этого получилось, добро пожаловать под кат.
Дисклеймер
Данное тестирование не претендует на объективность, и показывает результаты только в одних конкретных условиях с конкретным подходом и только при использовании HTTP. Возможно что при изменении подхода или в результате какого-либо тюнинга результаты будут совершенно другие.
Итак, рассмотрим претендентов
Gatling (https://gatling.io/)

Open Source инструмент для тестирования производительности, написан на Scala, поэтому работает на JVM и требует установленную Java, для разработки скриптов можно использовать Scala, Java или Kotlin, но основным языком все-таки считается Scala, большинство встречающихся примеров написано именно на нем. Из коробки умеет работать с HTTP и WebSocket, но для популярных протоколов существуют не официальные плагины. Не имеет интерфейса, все скрипты пишутся при помощи кода или рекордера. Умеет строить довольно красивые краткие отчеты. Gatling не очень популярен в России, но его популярность стремительно растет в последнее время.

Apache JMeter (https://jmeter.apache.org/)

Наверно самый известный инструмент для нагрузочного тестирования. Написан на Java, для работы требуется JVM, поэтому может выполняться в любой среде где есть Java. Имеет довольно понятный интерфейс. Большую часть логики запросов можно сделать без программирования, добавляя и конфигурируя нужные блоки. Из коробки поддерживает довольно много протоколов. А так же для JMeter существует огромное количество плагинов реализующих более специфические протоколы которых нет по-умолчанию. Так же вокруг JMeter очень большое сообщество специалистов, в том числе русскоязычных.
K6 (https://k6.io/)

Подающий надежды новичок в области тестирования производительности. Распространяется бесплатно, имеет коммерческую версию, предоставляемую как сервис. Разработан на Go, скрипты пишутся на JS, из коробки умеет работать только с HTTP, но уже имеется набор плагинов для популярных протоколов. Не имеет интерфейса, все делается при помощи кода и параметров запуска.
Locust (https://locust.io/)

Open source фреймворк для тестирования производительности разработанный на Python, скрипты так же пишутся на Python. Очень прост в освоении, особенно для знакомых с Python. Имеет веб-интерфейс для запуска, конфигурирования параметров теста и просмотра результатов.
MF LoadRunner (https://www.microfocus.com/)

Единственный проприетарный инструмент в нашем тесте. Очень популярный в банковской сфере, поддерживает огромное количество протоколов, имеет удобные приложения с интерфейсами для разработки, запуска тестов и анализа результатов тестирования. В зависимости от протокола доступны разные языки написания скриптов.
Для тестирования был написан примитивный веб-сервер на языке Go, который обрабатывает единственный GET-запрос и возвращает статический ответ. Кому интересно, код ниже.
Код
package main import ( "fmt" "net/http" ) func main() { http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) { fmt.Fprintf(w, "Hello World!") }) http.ListenAndServe(":8089", nil) }
Максимальная производительность сервиса достигнутая на хост-машине находится примерно на уровне 150 000 запросов в секунду.
Все инструменты, кроме LoadRunner, запускались на виртуальной машине QEMU с ОС Ubuntu Server 20.04, версия ядра 5.4.0-92-generic, конфигурация виртуальной машины 4vCPU, 4GB RAM, само тестируемое приложение размещено на хост-машине, где и развернута виртуалка. Конфигурация хост-машины: AMD Ryzen 5 5500U, 16GB RAM. Kubuntu 21.10 версия ядра 5.13.0-27-generic.
Для увеличения количества подключений, на обоих линуксах были выполнены следующие настройки:
Увеличено максимальное число открытых файлов в /etc/security/limits.conf
* hard nofile 97816 * soft nofile 97816
и количество подключений
sysctl net.ipv4.ip_local_port_range="15000 61000" sysctl net.core.somaxconn=1024 sysctl net.ipv4.tcp_tw_reuse=1 sysctl net.core.netdev_max_backlog=2000 sysctl net.ipv4.tcp_max_syn_backlog=2048
LoadRunner запускался на аналогичной конфигурации, но в качестве ОС уже была Windows Server 2019.
Мониторинг построен на связке Telegraf, Influx, Grafana. Telegraf установлен на обоих машинах, Influx и Grafana установлены на хост-машине.
Все инструменты, кроме LoadRunner, были настроены на отправку данных в Influx, понимаю что это создает лишнюю нагрузку, но зачем нужно тестирование без мониторинга.
Результаты тестирования
Если подробности не интересны, лучше сразу перейти к таблице в конце статьи.
Gatling
Для тестирования использовалась версия 3.7.3 (последняя на момент написания статьи)
Скрипт довольно примитивный, каждый виртуальный пользователь делает запрос, каждые 2 мс., количество пользователей возрастает от 1 до 300 за 10 минут.
Код скрипта
import io.gatling.core.scenario._ import io.gatling.http.Predef._ import io.gatling.core.Predef._ import scala.concurrent.duration.DurationInt class GatlingTest extends Simulation{ val httpConf = http.baseUrl("http://192.168.122.1:8088") val rq = http("SampleRq").get("/") val scn = scenario("SampleScenario").forever( pace(2.millis). exec(rq)) setUp( scn.inject(rampConcurrentUsers(1).to(300).during(600)).protocols(httpConf) ).maxDuration(10.minutes) }
Стабильный рост нагрузки происходил примерно до 22 500 запросов в секунду, что можно считать максимальной производительностью для Gatling в данных условиях.
Важно заметить что, чем больше виртуальных пользователей, тем больше создается сетевых коннектов, которые потребляют большую часть ресурсов, при быстром выполнении запросов и минимальном количестве пользователей создается максимальная производительность.

Как можно заметить, рост количества запросов продолжался и дальше, и можно заметить пики на уровне 40 000 запросов в секунду, однако производительность на этом уровне была уже очень нестабильной, поэтому за максимум считаю 22 500 запросов в секунду.

Перед началом нестабильной работы утилизация процессора виртуалки находилась на уровне около 65%, думаю такие показания связаны со склонностью виртуалок занижать потребление процессора при измерении изнутри.

Время отклика начало расти, как только уровень нагрузки стал нестабильным.

Количество виртуальных пользователей увеличивалось равномерно

Количество соединений росло пропорционально нагрузке
JMeter
Для тестирования использовалась версия 5.4.3 (последняя на момент написания статьи) Подход к формированию скрипта здесь аналогичный, для пауз использовался Constant Throughput Timer с целевой производительностью 30 000 запросов в минуту на один поток. Количество пользователей 300, запускаются за 10 минут.
Скрипт

Стабильный рост нагрузки продолжался примерно до 28 000 запросов в секунду, Jmeter создает минимальное количество подключений, что положительно сказывается на производительности.

Количество запросов возрастало довольно стабильно, пока не закончились ресурсы CPU.

По достижению максимальной утилизации процессора, перестала расти и производительность.

Оперативная память утилизировалась довольно умеренно.

Количество подключений возрастало пропорционально нагрузке.

Время отклика начало расти, как только достигли максимальной производительности.
K6
Для тестирования использовалась версия k6 v0.36.0. Использовался примерно такой же подход к формированию скрипта пауза между итерациями 10 мс. Запуск 200 виртуальных пользователей за 10 минут.
Код скрипта
import http from 'k6/http'; import { sleep } from 'k6'; export const options = { stages: [ { duration: '600s', target: 200 }, { duration: '20s', target: 0 }, ], }; export default function () { http.get('http://192.168.122.1:8089'); sleep(0.01); }
Стабильный рост нагрузки продолжался примерно до 4 500 запросов в секунду.

В пике производительность возрастала до 8000 запросов в секунду, но на таком уровне нагрузка была очень нестабильной.

Время отклика возрастало на протяжении всего теста.

Количество виртуальных пользователей возрастало равномерно.

Утилизация CPU в начале нестабильной нагрузки была на уровне около 65%.

Оперативная память утилизировалась существенно, наблюдался значительный рост утилизации в начале нестабильной работы.
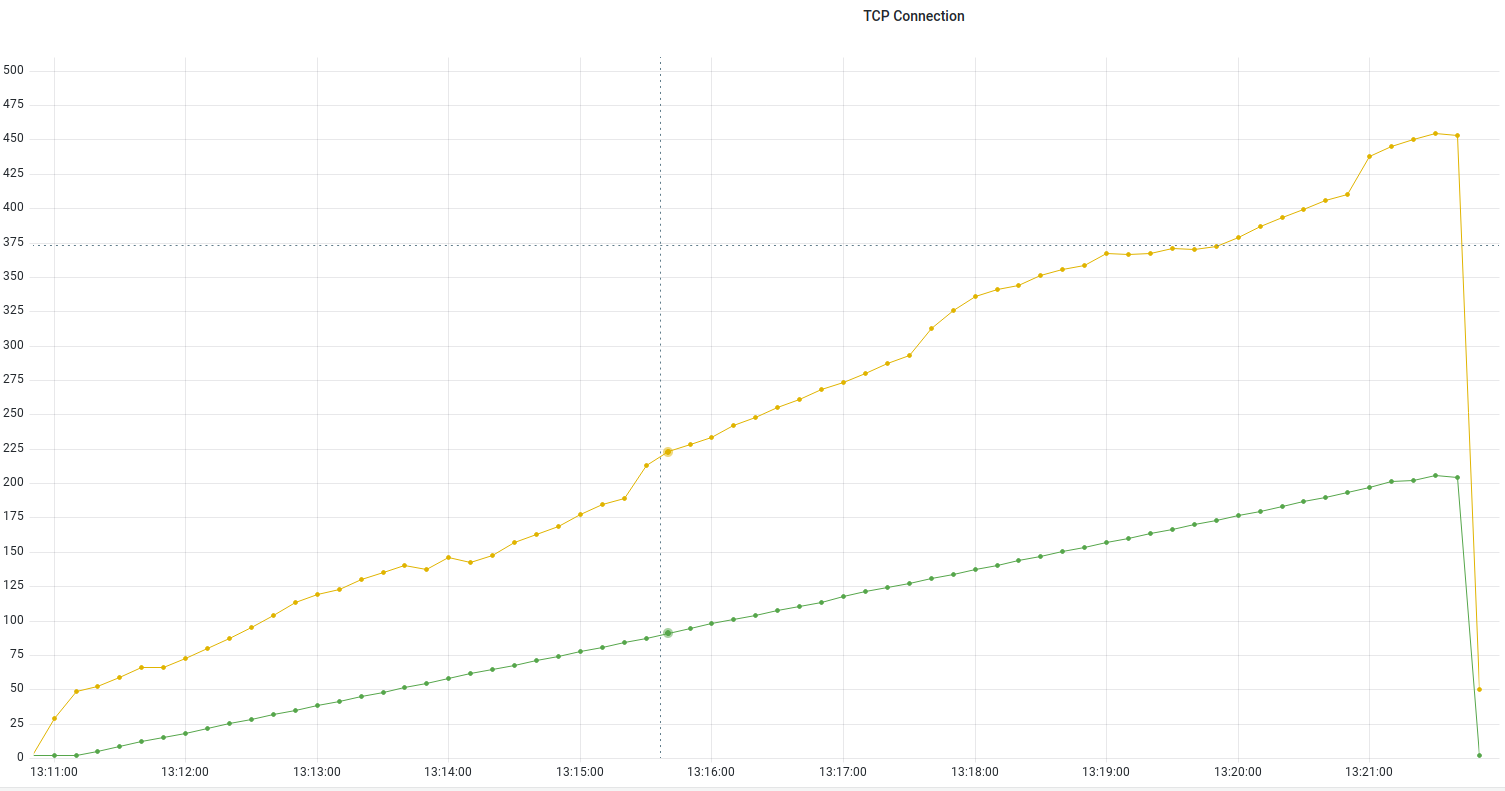
Количество коннектов росло пропорционально нагрузке
Locust
Для тестирования использовалась версия 2.5.1. В скрипте прописаны паузы в 200 мс. Между запросами, количество пользователей 200, запускаются по 1 в секунду. Для отправки результатов в Influx использовалась библиотека InfluxDBListener.
Код скрипта
from locust import between, constant, events, tag, task, HttpUser from locust_influxdb_listener import InfluxDBListener, InfluxDBSettings @events.init.add_listener def on_locust_init(environment, **_kwargs): """ Hook event that enables starting an influxdb connection """ influxDBSettings = InfluxDBSettings( influx_host = '192.168.122.1', influx_port = '8086', user = 'admin', pwd = 'admin', database = 'monitoring' ) InfluxDBListener(env=environment, influxDbSettings=influxDBSettings) class HelloWorldUser(HttpUser): @task def hello_world(self): self.client.get("/") wait_time = constant(0.2)
Стабильный рост производительности наблюдался до 835 запросов в секунду, после происходит существенны спад и производительность становится нестабильной.

При этом утилизируется только одно ядро виртуальной машины.

Так как использовалось только одно ядро, утилизация CPU была в пределах 25%.

После начала нестабильной работы время отклика начало расти.

Оперативная память утилизировалась несущественно.

MF LoadRunner
Для тестов использовалась верся 2021 build 371, тип скрипта WebHTTP, к сожалению простыми путями указать интервал запуска итераций меньше секунды в LoadRunner не представляется возможным, никакой паузы не указывалось. Запускались 50 пользователей (ограничение бесплатной версии) по одному в минуту.
Код скрипта
Action() { web_rest("GET: http://192.168.122.1", "URL=http://192.168.122.1:8089", "Method=GET", "Snapshot=t449913.inf", LAST); return 0; }
В RunTimeSettings обязательно нужно снять галочку Sumulate a new user on each iteration, иначе на каждый раз создается новое подключение и подключения быстро заканчиваются.
Стабильный рост производительности продолжался примерно до 7800 запросов в секунду, пока не закончились ресурсы CPU.

Утилизация CPU росла пропорционально нагрузке.

Оперативная память утилизировалась незначительно, небольшой рост наблюдается при достижении максимальной производительности.

Время отклика начало немного расти после достижения максимальной производительности.

Итоговая таблица
№ | Название инструмента | Полученный RPS |
1 | Gatling | 22 500 |
2 | JMeter | 28 000 |
3 | K6 | 4 500 |
4 | Locust | 835 |
5 | LoadRunner | 7 800 |
Выскажу свое впечатление по каждому инструменту по результатам тестов.
Gatling — мощный инструмент, показал высокую производительность, для новичка в НТ будет сложноват из-за подхода только через код и необходимости осваивать Scala, но специалисту с опытом определенно может пригодиться, особенно если придется тестировать веб-сокеты.
JMeter — победитель в текущем конкурсе. Хороший инструмент как для новичка, потому что легок в освоении, так и для специалиста, имеет огромный функционал из коробки, а так же возможности для расширения.
K6 — возможно еще сыроват и поэтому показал не очень хорошие результаты. Может требует какого то тюнинга, но из коробки результаты получились не очень хорошие. Если кто то заметил что я сделал с ним не так, напишите пожалуйста в комментариях.
Locust — производительность этого инструмента оказалась, мягко говоря, «слабовата». Зато он имеет очень приятный веб-интерфейс с неплохим функционалом и позволяет писать на Python. Думаю для Python-разработчиков, которым по-быстрому нужно протестировать не очень высоко нагруженный проект идеальный вариант.
LoadRunner — производительность этого ветерана банковской сферы оказалась примерно по-середине, но и нужно учитывать, что запускался он под Windows. Несомненный плюс его результатов в том что нагрузка была предсказуемой, даже после исчерпания ресурсов CPU производительность не начала скакать, а находилась примерно на одном уровне.
Как видно, каждый инструмент хорош для своих целей, поэтому не стоит воспринимать этот тест как рейтинг инструментов тестирования производительности. Возможно инструмент показавший себя плохо в данном тесте, будет лидером в других условиях.

