
В нашей прошлой статье про синтез речи мы дали много обещаний: убрать детские болячки, радикально ускорить синтез еще в 10 раз, добавить новые "фишечки", радикально улучшить качество.
Сейчас, вложив огромное количество работы, мы наконец готовы поделиться с сообществом своими успехами:
- Снизили размер модели в 2 раза;
- Научили наши модели делать паузы;
- Добавили один высококачественный голос (и бесконечное число случайных);
- Ускорили наши модели где-то примерно в 10 раз (!);
- Упаковали всех спикеров одного языка в одну модель;
- Наши модели теперь могут принимать на вход даже целые абзацы текста;
- Добавили функции контроля скорости и высоты речи через SSML;
- Наш синтез работает сразу в трех частотах дискретизации на выбор — 8, 24 и 48 килогерц;
- Решили детские проблемы наших моделей: нестабильность и пропуск слов, и добавили флаги для контроля ударения;
Это по-настоящему уникальное и прорывное достижение и мы не собираемся останавливаться. В ближайшее время мы добавим большое количество моделей на разных языках и напишем целый ряд публикаций на эту и смежные темы, а также продолжим делать наши модели лучше (например, еще в 2-5 раз быстрее).
Попробовать модель как обычно можно в нашем репозитории и в колабе.
Как попробовать
Для самых нетерпеливых — вот основные примеры звучания:
Update — баг с резким прерыванием речи на паузе уже пофиксили
Как обычно, все инструкции можно найти:
Вот самый минималистичный пример вызова модели:
import torch device = torch.device('cpu') torch.set_num_threads(4) speaker = 'xenia' # 'aidar', 'baya', 'kseniya', 'xenia', 'random' sample_rate = 48000 # 8000, 24000, 48000 model, example_text = torch.hub.load(repo_or_dir='snakers4/silero-models', model='silero_tts', language='ru', speaker='ru_v3') model.to(device) audio = model.apply_tts(text=example_text, speaker=speaker, sample_rate=sample_rate)
Спикеров и принимаемые символы для каждой модели можно посмотреть в свойствах модели model.speakers и model.symbols.
import os import torch device = torch.device('cpu') torch.set_num_threads(4) local_file = 'model.pt' speaker = 'xenia' # 'aidar', 'baya', 'kseniya', 'xenia', 'random' sample_rate = 48000 # 8000, 24000, 48000 if not os.path.isfile(local_file): torch.hub.download_url_to_file('https://models.silero.ai/models/tts/ru/ru_v3.pt', local_file) model = torch.package.PackageImporter(local_file).load_pickle("tts_models", "model") model.to(device) audio = model.apply_tts(text=example_text, speaker=speaker, sample_rate=sample_rate)
Как обычно, больше примеров вы можете найти по ссылкам в репозитории или в статье ниже. Все дальнешие примеры мы будем приводить без импортов для экономии места. С недавнего времени у моделей также появился своё pip-пакет, аналогичный по функционалу импорту через torch.hub.
Новые фишки и примеры аудио
Перечислим еще раз все нововведения вместе и более подробно пройдемся по каждому из них ниже с примерами:
- Снизили размер модели в 2 раза (ненарочно);
- Научили наши модели делать паузы;
- Добавили один высококачественный голос (и бесконечное число случайных);
- Ускорили наши модели где-то примерно в 10 раз (!);
- Упаковали всех спикеров одного языка в одну модель;
- Наши модели теперь могут принимать на вход даже целые абзацы текста;
- Добавили функции контроля скорости и высоты речи через SSML;
- Наш синтез работает сразу в трех частотах дискретизации на выбор — 8, 24 или 48 килогерц;
- Решили детские проблемы наших моделей: нестабильность и пропуск слов, и добавили флаги для контроля ударения;
Ускорение моделей в 10 раз
Тут особо нечего сказать, наши модели просто стали в 10 раз быстрее.
Скорость мы измеряем в секундах сгенерированного аудио в секунду, ограничивая число потоков в PyTorch (1 ядро = 2 потока) на процессоре Intel.
Так например, скорость V3 модели для 8 kHz в 50 секунд аудио в секунду означает, что аудио длиной в 5 секунд будет сгенерировано примерно за 100 ms.
| V1 модель | V1 модель | V3 модель | V3 модель | |
|---|---|---|---|---|
| 1 поток | 4 потока | 1 поток | 4 потока | |
| 8 kHz | 1.9 | 4.2 | 15 — 25 | 30 — 60 |
| 16 kHz | 1.4 | 3.1 | - | - |
| 24 kHz | - | - | 10 | 15 — 20 |
| 48 kHz | - | - | 5 | 10 |
Так как на CPU задержка и скорость напрямую зависят от длины генерируемого аудио, новые цифры указаны в виде интервалов. Скорость выходит на плато примерно на длительности аудио в 5 секунд. Задержка, понятно, линейно зависит от длины генерируемого аудио.
Тут интересно также посмотреть на задержку — её легко посчитать в уме, просто поделив нужную длину аудио на скорость. По ряду технических причин, наши модели теперь не принимают списки текстов и не работают с батчами.
В ближайшем будущем мы уже планируем (и самое главное — знаем как) ускорить модель еще в 2-5 раз. Также вышло снизить размер модели в 2 раза, но мы особо этим не занимались целенаправленно. Пока есть определенные проблемы с квантизацией и конвертацией в ONNX, но в теории минимальный возможный размер модели находится в районе 5-10 мегабайт. Вы всегда можете помочь нам профинансировать соответствующие исследования.
Пробуем разные высококачественные голоса
Тут также важно обратить внимание, что теперь все спикеры на одном языке будут жить внутри одной модели.
В этот раз мы готовы представить 4 высококачественных голоса, послушать можно по ссылке:
Для добавления нового голоса xenia нам потребовалось записать всего лишь 2 часа аудио, и это не предел.
... speaker = 'xenia' # 'aidar', 'baya', 'kseniya', 'xenia', 'random' ... audio = model.apply_tts(text=example_text, speaker=speaker, sample_rate=sample_rate)
Синтезируем аудио разного качества
Мы можем синтезировать аудио с частотой дискретизации на выбор: 8, 24 или 48 килогерц. Предсказуемо, скорость работы моделей линейно меняется в зависимости от этого параметра.
... sample_rate = 48000 # 8000, 24000, 48000 ... audio = model.apply_tts(text=example_text, speaker=speaker, sample_rate=sample_rate)
Небольшая ремарка — качество модели для 8 килогерц сейчас не максимально возможное, мы это поправим при ускорении моделей.
Управляем речью и генерируем целые абзацы текста с помощью SSML
Раньше у моделей возникали проблемы при работе с текстами длиннее 140 символов — сейчас это ограничение снято. Также для удобства мы добавили поддержку самых важных SSML тегов:
| Тег | Пример тега | Возможные значения | Комментарий |
|---|---|---|---|
| Пауза | <break time="2000ms"/> |
5s, 500ms |
Целое число секунд или миллисекунд |
| Скорость речи | <prosody rate="x-fast"> … </prosody> |
x-slow, slow, medium, fast, x-fast |
rate и pitch можно комбинировать |
| Высота речи | <prosody pitch="x-high"> … </prosody> |
x-low, low, medium, high, x-high, robot |
rate и pitch можно комбинировать |
| Предложение | <s> … </s> |
- | Эквивалентен точке |
| Абзац | <p> … </p> |
- | Эквивалентен длинной паузе |
Более подробную документацию по тегам можно найти тут.
Основные теги на примерах:
Update — баг с резким прерыванием речи на паузе уже пофиксили
ssml_sample = """ <speak> <p> Когда я просыпаюсь, <prosody rate="x-slow">я говорю довольно медленно</prosody>. Потом я начинаю говорить своим обычным голосом, <prosody pitch="x-high"> а могу говорить тоном выше </prosody>, или <prosody pitch="x-low">наоборот, ниже</prosody>. Потом, если повезет – <prosody rate="fast">я могу говорить и довольно быстро.</prosody> А еще я умею делать паузы любой длины, например две секунды <break time="2000ms"/>. <p> Также я умею делать паузы между параграфами. </p> <p> <s>И также я умею делать паузы между предложениями</s> <s>Вот например как сейчас</s> </p> </p> </speak> """ sample_rate = 48000 speaker = 'xenia' audio = model.apply_tts(ssml_text=ssml_sample, speaker=speaker, sample_rate=sample_rate)
Управляем ударением
Мы добавили возможность авторасстановки ударений ещё в прошлой версии, но в новом релизе стало доступно явно управлять флагами ударения и простановки буквы ё:
put_accent— флаг автоматической простановки ударения;put_yo— флаг автоматической простановки буквыё;
Вручную ударение, как и раньше, можно проставлять с помощью символа +.
Вот примеры — нет ударения вовсе, автоматическое ударение, автоматическое ударение + пара правок:
ssml_sample = """ <speak> В недрах тундры выдры в гетрах тырят в ведрах ядра к+едров! Выдрав с выдры в тундре гетры, вытру выдрой ядра к+едра. Вытру гетрой выдре морду, +ядра - в в+ёдра, выдру в тундру. </speak> """ sample_rate = 48000 speaker = 'aidar' audio = model.apply_tts(ssml_text=ssml_sample, speaker=speaker, sample_rate=sample_rate, put_accent=True, put_yo=True) display(Audio(audio, rate=sample_rate))
Единственная загвоздка состоит в том, что мы смогли добиться точности только в 80% в простановке ударения на омографах, и поэтому новая версия модели не вошла в этот релиз. Наша цель — точность на уровне 90-95%. Также в следующей версии мы увеличим словарь словоформ до 4 миллионов штук.
Дополнительные прикольные возможности
Среди дополнительных фишечек есть:
- Возможность говорить "как робот" (с помощью тега
prosodyсpitch="robot"); - Возможность генерации и сохранения бесконечного количества "случайных" спикеров;
- Возможность клонировать интонацию некой "модельной" фразы (в непубличной версии модели);
sample_rate = 48000 speaker = 'random' audio = model.apply_tts(ssml_text=ssml_sample, speaker=speaker, sample_rate=sample_rate) model.save_random_voice('test_voice.pt') audio = model.apply_tts(ssml_text=ssml_sample, speaker=speaker, voice_path='test_voice.pt')
Также можно послушать как работает перенос интонаций на известных и неизвестных спикерах:
Понятно, что можно сделать генеральную модель, которая бы хорошо работала на всем, но мы пока не ставили такой задачи.
Типичные проблемы публичных решений и индустрии
Часто после какой-то очередной пиар акции очередного инвестиционного стартапа, мне пишут люди, мол смотрите какие классные вещи люди делают.
На практике оказывается, что кто-то просто скопировал код самой модной статьи, прикрутил к нему CLI и теперь люди могут по-настоящему делать качественные, быстрые и демократичные модели!
В реальности такие решения долго тренируются, спроектированы на работу на карточках по типу RTX 3090 — A100 — V100 (то есть, имеющих более 16 GB VRAM) и уступают уже существующим решениям.
Вот недавно мы сравнивали новую модную модель VITS:
- В статье авторы пишут про инференс только на картах по типу V100;
- На практике на инфересе нужно более 16 GB VRAM для фраз нетривиальной длины (я не понимал зачем на инференсе такие карты до этого теста);
- Скорость уступает более простым решениям;
Самое печальное, что зачастую такие статьи написаны таким образом, чтобы нельзя было понять, какие элементы моделей на самом деле "тащат". Отчасти поэтому новые релизы занимают столько времени.
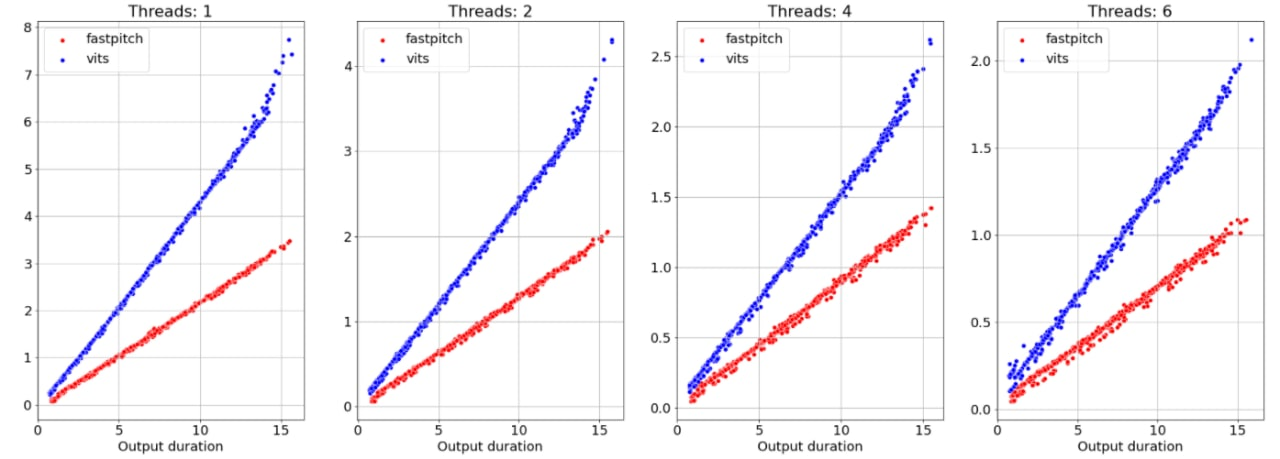
| Max VRAM, MB | |
|---|---|
| VITS | 16,301 |
| Fast Pitch | 3,215 |
Мы не преследуем идеологию перепродажи чужих наработок и воздуха инвесторам и поэтому мы делаем максимально простые, быстрые и максимально публичные компактные решения.
Дальнейшие планы
Мы не будем останавливаться на достигнутом, паниковать и следовать токсичным и самоуничижительным трендам.
Мы гордимся нашей командой и тем, что мы сделали по-настоящему уникальный продукт.
Мы верим, что только так мы все вместе можем бороться с игом корпораций, особенно иностранных.
Именно по синтезу, дальше мы планируем:
- Ускорить наш синтез еще в 2-5 раз;
- Прикрутить квантизацию и ONNX и тем самым возможно ускорить синтез еще в 2-4 раза;
- Добавить возможность использовать фонемы напрямую для синтеза для произношения сложных слов и аббревиатур;
- Довести до конца работу по автоматической простановке ударения в предложениях с омографами и достичь точности в 90-95% на омографах;
- Обновить модели для имеющихся у нас языков СНГ (если вы хотите записать какие-то новые — добро пожаловать), включая украинский;
- Обновить модели для английского и основных европейских языков (мы пока не решили каких именно);
- Сделать модель для индийских языков;
- И есть еще пара секретных фановых мини проектов, о которых я не буду вам рассказывать =);
- Нам и так потребовалась буквально пара часов для добавления нового высококачественного голоса и мы уже можем генерировать бесконечные случайные голоса. Возможно мы снизим штатное количество аудио для добавления нового высококачественного голоса до нескольких минут вместе с возможностью использования фонем;

