

Привет! Меня зовут Александр Кленов, и я работаю в Tarantool. В апреле вышел Tarantool 2.10 Enterprise Edition – обновленная версия платформы in-memory вычислений. В версии 2.10 появилось несколько новых функций, о которых уже немного рассказывали на Хабре.
В этой статье я хочу подробнее остановиться на одной из фичей — сжатии данных в оперативной памяти. Далее я расскажу, как ей пользоваться, что может, а чего не может данный механизм, как его применять и какие существуют особенности.
Как включить сжатие
Все просто — нужно указать в настройках поля, что его надо сжимать: compression = '<вариант>'.
Доступно два варианта сжатия:
zstd,
lz4.
Например:
local space = box.schema.space.create(space_name, { if_not_exists = true }) space:format({ {name = 'uid', type = 'string'}, {name = 'body', type = 'string', compression = 'zstd'}, })
Если это не новый, а существующий проект с данными, понадобится также вызвать фоновую миграцию:
box.schema.func.create('noop', { is_deterministic = true, body = 'function(t) return t end' }) space:upgrade{func = 'noop', format = { {name = 'uid', type = 'string'}, {name = 'body', type = 'string', compression = 'zstd'}, }}
Подробнее смотрите в документации
Каких результатов можно добиться за счет сжатия?
Итак, мы подключили фичу. Давайте посмотрим, что хорошего она может нам дать. В качестве примера возьмем реальный проект – данные крупного телеком-оператора. Это 100 тысяч различных JSON-документов общим объемом 316 МБ.
По очереди мы применим разные варианты сжатия. CPU в нашем случае = 3,6 ГГц. Для лучшего сравнения методов добавим сжатие с помощью внешней библиотеки ZLIB.
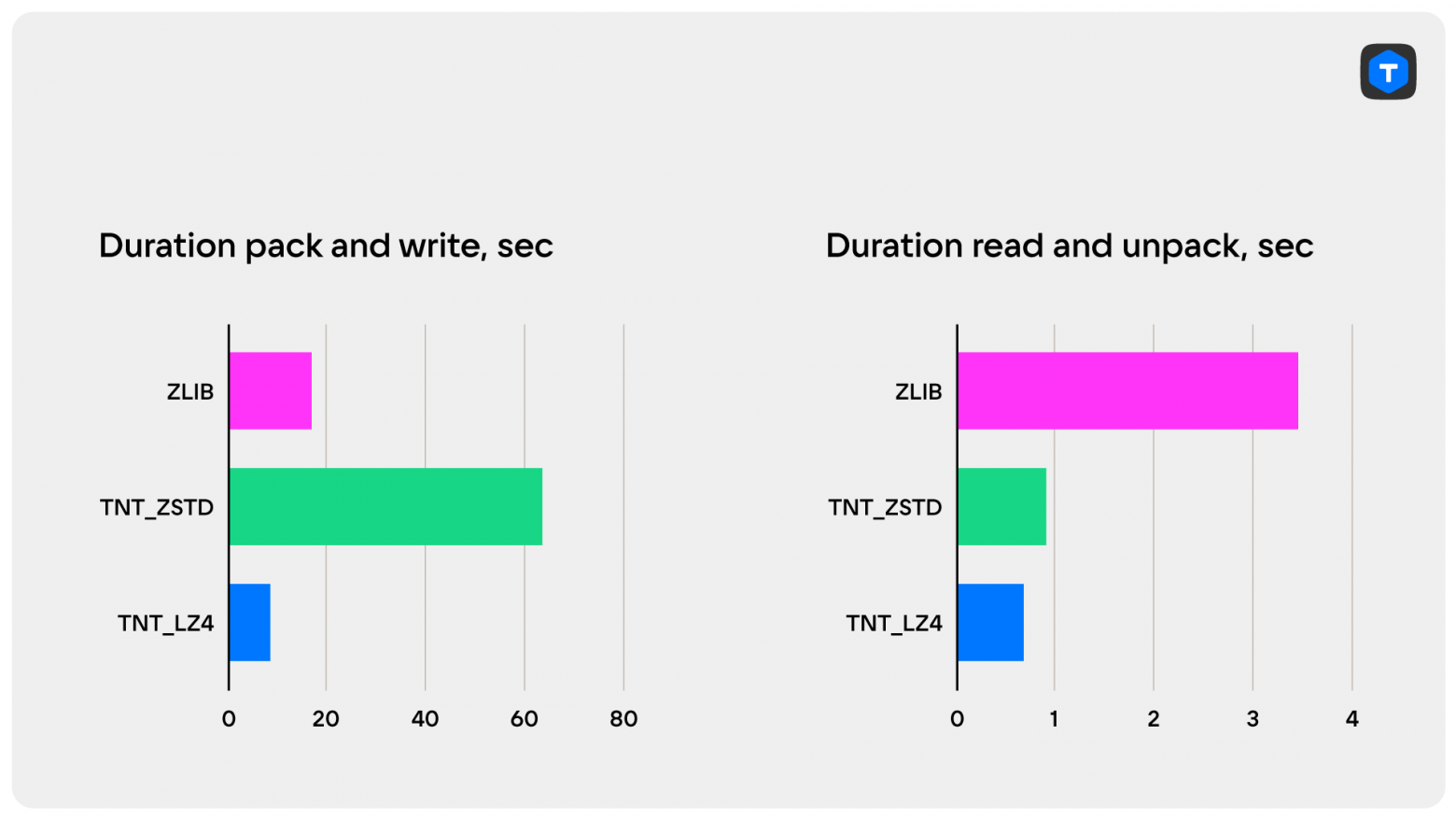
Тестирование показало следующие результаты:
Метод | Время упаковки и записи в таблицу, сек | Время чтения и распаковки, сек | Конечный размер спейса, МБ | Коэффициент сжатия | Сжатие, % |
ZSTD | 61.222 | 0.889 | 113.234 | 2.790 | 64.16 |
LZ4 | 7.701 | 0.963 | 186.499 | 1.694 | 40.97 |
ZLIB* | 16.119 | 3.528 | 121.958 | 2.590 | 61.40 |
* Внешняя библиотека ZLIB

Исходник теста можно посмотреть на Гитхабе.
Ключевой вывод – все три метода работают по-разному. ZSTD сжимает эффективно, но медленно и при этом достаточно быстро распаковывает документы. LZ4 – быстро сжимает и разжимает, но коэффициент сжатия уступает остальным методам. Сжатие с использованием ZLIB сопоставимо с результатами ZSTD и при этом не слишком медленно, однако проседает скорость разжатия.
Сжатие в кластере
В реальных продуктовых проектах экземпляры Tarantool разделены по ролям. Для нашего примера важно выделить две:
маршрутизатор (router),
хранилище (storage).
Сжатие данных в кластере – не такая линейная задача, как сжатие одного узла. Это можно организовать разными способами в зависимости от места сжатия и разжатия. У каждого способа есть свои плюсы и минусы. Рассмотрим три варианта.
Вариант первый — быстрый эффект

Сжимаем и разжимаем в хранилище. Этот вариант обеспечивает описываемая в статье функциональность. Подходит, если нужно быстро и при ничтожных изменениях проекта высвободить кучу места.
Звучит здорово, но это вызывает дополнительную нагрузку на ЦП хранилища и его замедление. Более того, каждая реплика будет повторять то же самое сжатие. Как следствие — снижение производительности кластера. Хранилище со встроенным упаковщиком дороже масштабировать. То есть вместо одного дополнительного упаковщика придется поставить рядом хранилище с упаковщиком.
Посмотреть пример, как сделать, можно здесь:
Локальная переменная enable_zlib в роутере должна иметь значение = false. В хранилище в 11-й строке нужно указать тип сжатия.
Такой вариант подойдет – если срочно нужно освободить место. То есть как временное решение. Если нагрузка позволяет – это может быть постоянным решением. Это про быстро и дешево.
Если вы хотите сохранить производительность кластера, потребуется больше усилий.
Вариант второй — максимальная производительность
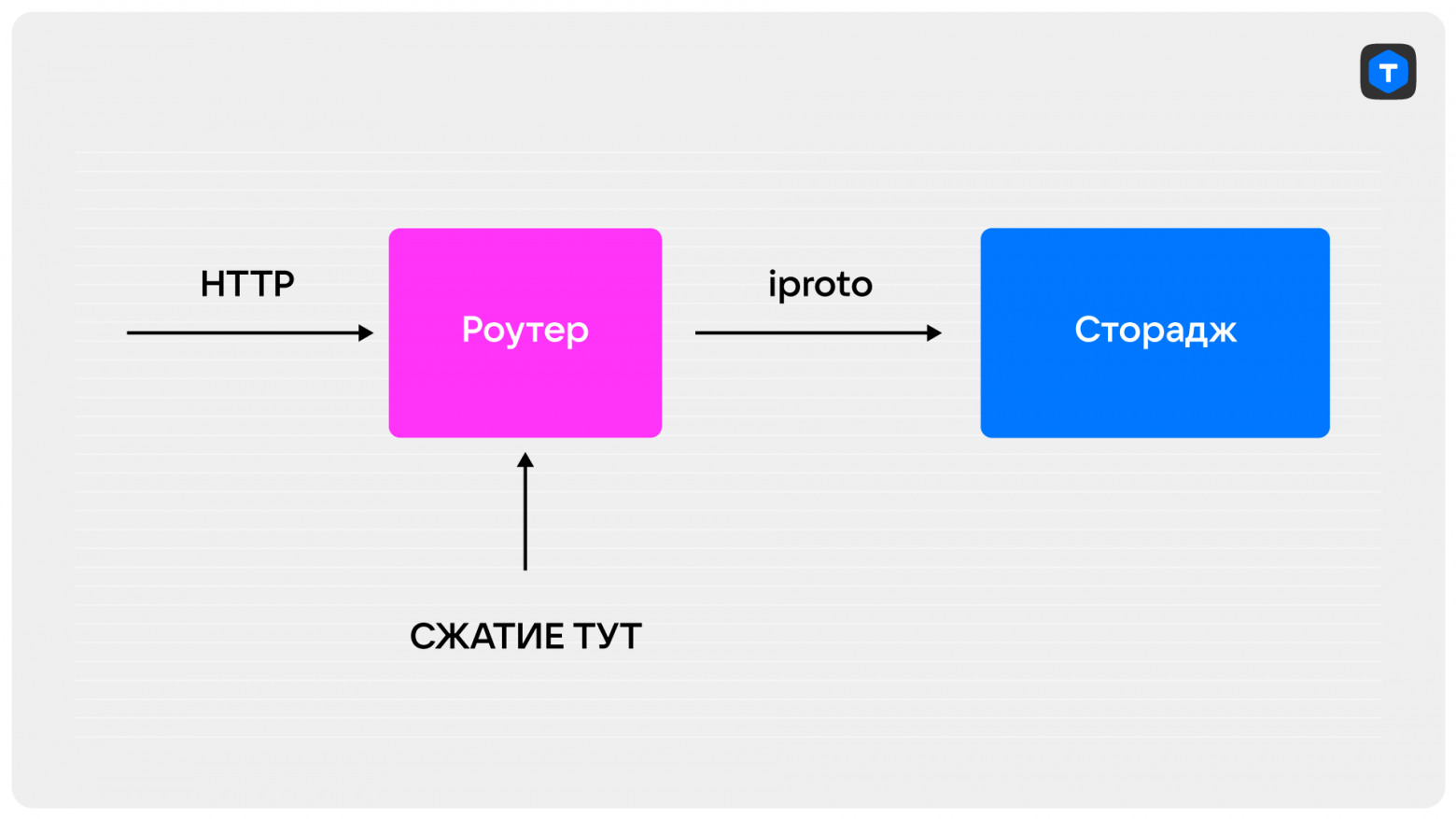
Сжимаем и разжимаем на роутере. Это дает больше производительности, но встроенное сжатие никак не поможет — придется подключать внешнюю библиотеку и реализовывать дополнительную логику работы с ней. В мастер и на реплики тогда будут попадать уже упакованные данные.
В качестве примера можно использовать пару роутер-хранилище, приведенную выше. Только переменная enable_zlib в роутере должна иметь значение = true. В хранилище тип сжатия не указываем.
Плюсы:
не нагружаем хранилище;
уменьшаем трафик между роутером и стораджем;
легче масштабируем — ставим нужное количество роутеров с упаковщиком до требуемой производительности.
Минусы:
нужно реализовать логику упаковщика на роутере;
появляется задержка на роутере на сжатие и распаковку.
Если хочется большего, то можно управлять сжатием в виде отдельной роли. Это позволит регулировать число роутеров отдельно от числа инстансов сжатия. Более гибко регулировать утилизацию ресурсов. В этом случае можно рассмотреть третий вариант.
Вариант третий — ленивое сжатие
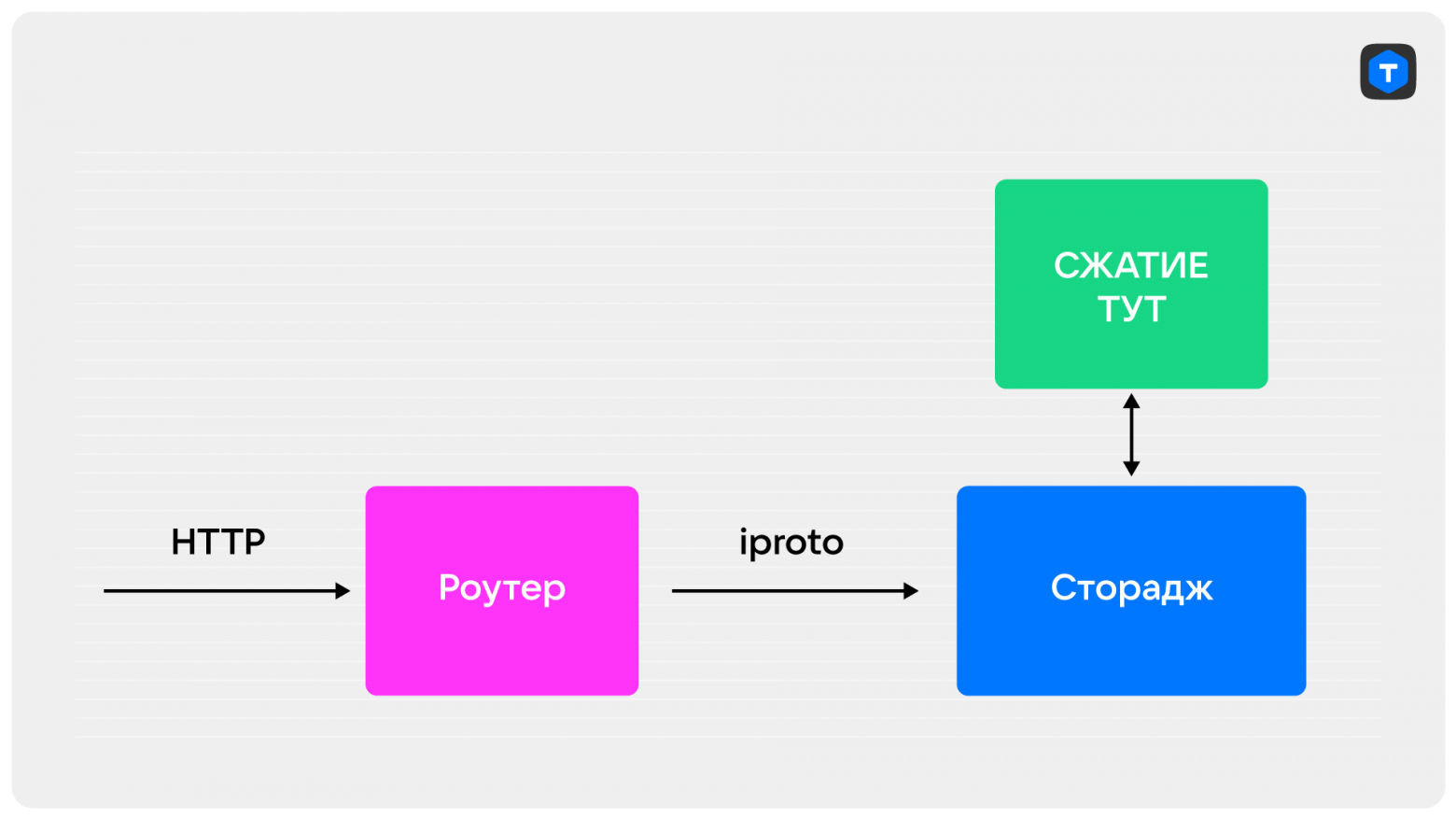
Сжимаем на отдельном экземпляре, разжимаем на роутере. То есть пишем в хранилище как есть с признаком «не упакован». Далее реализуем отдельную роль «упаковщик», которая проходит по мастер-хранилищам и упаковывает все не упакованное. Если данные поступают быстро и надо паковать быстрее — добавляем ещё экземпляры упаковщика. На реплики будут попадать уже упакованные данные.
Посмотреть пример реализации, чтобы понять идею, можно здесь.
Его можно нагрузить тем же нагрузочным тестом. Результаты он покажет как при записи без сжатия, потому что сжатие происходит не при записи, а в отдельном параллельном процессе.
Плюсы:
нет задержки на роутере на запись данных;
процесс сжатия масштабируется максимально выгодно;
меньше экземпляров кластера;
не нагружаем хранилище как в первом варианте.
Минусы:
дополнительный трафик в кластере — между хранилищем и упаковщиком;
некоторая дополнительная нагрузка на хранилище — плюс по одной операции чтения и записи;
нужно реализовать отдельную роль — упаковщик;
нужно реализовать логику распаковки на роутере.
Это может быть полезно:
если вы хотите быстро записывать данные - сразу записывать не сжимая;
регулировать скорость сжимания - либо уменьшить число инстансов, либо наоборот - увеличить, и через это более гибко расходовать свои ресурсы.
Эффект переноса сжатия на роутер
На фоне предложенных вариантов хочется проследить эффект от переноса сжатия с хранилища на роутер, как наиболее производительный. Давайте соберем маленький кластер на два экземпляра — роутер и хранилище. И попробуем нагрузить его при разных способах упаковки.
Реализация стенда:
Максимальная продолжительность испытаний выбрана 30 секунд. Потому, что с одной стороны не слишком долго ждать выполнения тестов, с другой – этого достаточно для тестирования нагрузки. За это время мы генерируем 100 тысяч запросов на запись на роутер от лица 10 виртуальных пользователей. Консольный вывод результатов можно посмотреть здесь. Ниже результаты сведены в одну таблицу.
Показатель \ Сценарий | Без сжатия | ZLIB | ZSTD | LZ4 |
Запросов выполнено, шт | 100000 | 100000 | 46964 | 100000 |
Длительность выполнения запросов, сек | 14.1 | 27.8 | 30.0 | 15.7 |
K6 data_received, MB | 23 | 23 | 11 | 23 |
K6 data_sent, MB | 341 | 342 | 160 | 341 |
http_req_blocked, µs | 2.46 | 1.81 | 2.12 | 2.17 |
http_req_connecting, ns | 13 | 7 | 20 | 16 |
http_req_duration, ms | 0.716 | 2.27 | 5.78 | 0.934 |
http_req_failed, % | 0 | 0 | 0 | 0 |
http_req_receiving, µs | 31.1 | 25.59 | 25.8 | 28.71 |
http_req_sending, µs | 20.08 | 16.78 | 19.42 | 19.22 |
http_req_waiting, ms | 0.665 | 2.22 | 5.74 | 0.886 |
RPS | 7076 | 3595 | 1565 | 6351 |
iteration_duration, ms | 1.4 | 2.77 | 6.38 | 1.56 |
Итак мы видим, что по ключевым параметрам, таким как число запросов в секунду (RPS), задержке (http_req_duration) и общему времени выполнения запроса (iteration_duration) - вариант со сжатием на роутере выгодно отличается от сжатия в хранилище.
В первую очередь это происходит потому, что сжатие методом ZSTD происходит дольше, чем методом ZLIB. Также свой вклад вносит то, что данные от роутера до хранилища идут уже сжатые и таким образом в само хранилище нужно записывать меньше данных. Также плюсом идёт то, что не нужно нагружать хранилище сжатием.
Выводы
Tarantool развивается и обрастает новыми фичами. Встроенный в 2.10EE механизм сжатия полезен, но не является панацеей. Порядок действий зависит от конкретной ситуации — отсюда и возникают рекомендации по применению.
Если у нас нет желания или возможности использовать внешнюю библиотеку - мы можем использовать встроенное сжатие методом LZ4. Данный метод позволяет высвободить 40% места почти без просадки по RPS (6351 LZ4 против 7076 без сжатия). При этом включается фактически «одной галочкой» — на мой взгляд весьма неплохо.
Если требуется жать сильнее, или производительнее, или дешевле — нужны дополнительные усилия, которые описаны выше.
Скачать Tarantool можно на официальном сайте, а получить помощь — в Telegram-чате.
