

DataOps Unleashed — конференция, на которой обсуждают DataOps, CloudOps и AIOps, лекторы рассказывают об актуальных тенденциях и передовых методах запуска, управления и мониторинга пайплайнов данных и аналитических рабочих нагрузках.
Команда VK Cloud Solutions перевела конспект выступлений, которые показались полезны автору статьи. DataOps-специалисты ведущих ИТ-компаний объясняли, как они устанавливают предсказуемость данных, повышают достоверность и снижают расходы на работу с пайплайнами.
Вступительная лекция
Видеозапись выступления
Сейчас все работают с данными, поэтому DataOps переживает взрывной рост. Как командам идти в ногу с возрастающим спросом на данные? Кунал Агарвал, соучредитель и президент компании Unravel Data, рассказал о трех «К», мешающих эффективной работе команд по обработке данных:
- Крайняя сложность. Возникает из-за пайпланов и стеков данных. Чтобы сформировать современный стек, компании компонуют от 6 до 20 систем.
- Координация. Координация — это совместная работа дата-инженеров, специалистов по операциям с данными, дата-архитекторов и руководителей структурных подразделений. В работе этих специалистов недостаточно хорошо отлажены повторяющиеся стабильные процессы.
- Команда. В отрасли наблюдается сильный кадровый дефицит.
Все эти проблемы характерны и для облачных сред, в которых есть дополнительные сложности — управление и стоимость.
У DataOps-сообщества есть инструменты и процессы для решения этих проблем:
- Крайняя сложность. Благодаря наблюдаемости в full stack DataOps может упростить процессы управления, оптимизировать потоки, повысить надежность, качество и производительность приложений, работающих с данными. У специалистов появляется единый надежный источник истины, на который они могут положиться.
- Координация. DataOps может автоматизировать задачи, для решения которых раньше приходилось обращаться к экспертам, и значительно ускорить их масштабирование.
- Команда. Благодаря надежности и повторяемости процессов DataOps может ускорить взаимодействие между членами команды.
- Облако. DataOps создает интеллектуальное управление, позволяющее использовать все преимущества облачных решений и обойти стороной их недостатки.
Цикл операционной аналитики
Видеозапись выступления
Практики для работы с ПО пожирают бизнес, и работа с данными — не исключение. DataOps направляет компании в сторону повторяемости, гибкости и высокой скорости обработки данных. Но пока все равно с трудом удается преодолеть разрыв между экспертами, полагающимися на данные, и специалистами по подготовке данных. Boris Jabes, президент компании Census, ставшей пионером операционной аналитики и подхода reverse ETL, рассказал, как окончательно преодолеть этот разрыв с помощью операционной аналитики и подняться до золотого стандарта DevOps-принципов: непрерывного цикла данных.
DevOps — это набор практик, сокращающих время от внедрения изменения в системе до момента выхода его в продакшн без снижения высокого качества работы. Этот набор практик включает разные этапы: разработку, тестирование, упаковку, релиз, конфигурирование и мониторинг — и на каждом этапе применяют специальные инструменты. Это не просто последовательность этапов — это цикл, сокращающий время от создания до поставки готового решения и при этом обеспечивающий высокое качество.
А есть ли аналогичный цикл в DataOps? Команды по обработке данных часто попадают в ловушку «отправить запрос и подождать». Цикл обратной связи между командой по обработке данных и бизнес- или продакт-командами в большей степени зависит от конкретных обстоятельств.
Инструменты Reverse ETL, как у компании Census, открывают дорогу операционной аналитике, которая берет данные из хранилища и создает CI/CD-пайплайн для деплоймента аналитики в реальном времени прямо в операционных инструментах. Вот как выглядит цикл операционной аналитики.
- Берем необработанные данные из источников данных и создаем модели, чтобы извлечь из них ценную для бизнеса информацию.
- Возвращаем ценные сведения в операционные приложения, чтобы автоматизировать бизнес-операции.
- Переносим новые данные из приложения в источники — цикл завершен.

Применяя такой цикл, можно внедрить подход Data-as-a-Product: артефакты данных напрямую связаны с бизнесом и помогают принимать решения. Раньше команда по обработке данных предоставляла услуги и принимала заказы. Теперь она становится критически важным звеном, поддерживающим гибкость бизнеса.
Прощайте, неработающие пайплайны и задержки релизов!
Видеозапись выступления
Достичь наблюдаемости пайплайнов данных в сложной среде становится все труднее. Компании выделяют дополнительные средства и тратят сотни человеко-часов на анализ влияния, который приходится выполнять вручную. Joseph Chmielewski, старший инженер в компании Manta, утверждает, что это можно исправить. В своем выступлении он рассказывает, как внедрить DataOps в рабочую среду, наладить автоматический мониторинг и тестирование и избавить ваших сотрудников от утомительной «ручной» работы.
В одной недавно вышедшей статье говорится, что в DataOps довольно трудно оркестрировать код и данные в разных инструментах и мониторить комплексную среду. Опрос о «наиболее серьезных технических трудностях DataOps, с которыми сегодня сталкиваются корпоративные команды по обработке данных», показал, что с проблемами оркестрации сталкивают 44% специалистов.
Чем сложнее среда данных, тем чаще «мертвые зоны» вызывают ошибки и инциденты. Исправить их не так-то просто, если наблюдаемость пайплайна данных ограничена. Эти мертвые зоны возникают из-за «неизвестных неизвестных» — данных, которые пользователь не учел или о которых ничего не знал. В сложной системе непросто рассмотреть детали: разные наборы данных имеют разную логику или структуру. И мертвые зоны возникают, когда у пользователя нет полного обзора.
Вот некоторые признаки невыявленных мертвых зон:
- Из-за нарушенной зависимости приложение перестает работать.
- Из-за неизвестной уязвимости системы безопасности происходит утечка персональных данных.
- Из-за последнего обновления системы возникает сбой в составлении отчетов на последующем этапе.
Йозеф приводит реальный пример влияния таких мертвых зон на работу предприятия:
Крупной автомобильной компании нужно было разобраться в экосистеме данных, чтобы ускорить управление изменениями и профилактику инцидентов. DataOps-команда безуспешно пыталась построить график зависимостей вручную. Команда дата-инженеров тратила 30–40% рабочего времени на отслеживание зависимостей и потоков данных. DataOps-команде удалось выявить в потоках данных мертвые зоны, которые нужно было устранить, — это были области на пересечении с работой других отделов. Ручная работа занимала слишком много времени, приводила к ошибкам и не давала устойчивых результатов в долгосрочной перспективе.
Автоматическое data lineage — хорошее решение, позволяющее устранить мертвые зоны и обеспечить наглядность в пайплайнах для всех пользователей данных. Это достигается благодаря анализу метаданных, подробному документированию потоков данных и воспроизводимым, проверяемым или справочным результатам анализа за весь период времени.
Возвращаясь к примеру с автомобильной компанией. После внедрения автоматического data lineage сопоставление данных стало занимать несколько минут, компания получила полный обзор среды и смогла автоматически сопоставлять весь путь данных. Это помогло непрерывно отслеживать и анализировать действующие в компании процессы.
В результате на 25% сократились сроки разработки, тестирования и аналитики продакшн-данных. На 25% выросла скорость операций с данными. Время отказа от приложений и перехода в облако сократилось на 30%. Компания сэкономила миллионы долларов на соблюдении требований Общего регламента ЕС по защите персональных данных.
Благодаря решениям вроде Manta все пользователи получают полный обзор пайплайна. Такая организация работы:
- сокращает сроки принятия решений на базе аналитических данных;
- дает всем пользователям полный обзор пайплайнов;
- позволяет организовать мониторинг состояния данных во времени;
- гарантирует точность и достоверность данных;
- позволяет автоматически анализировать влияние, чтобы предотвращать инциденты и сокращать сроки миграции приложений.
Облачное Data Lakehouse невозможно без открытых технологий
Видеозапись выступления
Torsten Steinbach, ведущий архитектор в IBM, подробно рассказал о том, как его команда взрастила и встроила open-tech-решения в современную платформу Data Lakehouse. В своем выступлении он остановился на анализе табличных форматов с точки зрения согласованности данных, удобстве использования мета-хранилищ и каталогов, шифровании для защиты, индексах пропуска данных для повышения производительности и фреймворках пайплайнов.
Эволюция Big Data-систем прошла четыре этапа:
- В 90-х корпоративные хранилища данных были хорошо интегрированными и оптимизированными системами.
- В 2000-х благодаря озерам данных Hadoop и стекам ELK появилась возможность использовать на недорогом типовом оборудовании открытые форматы данных и настраиваемое масштабирование.
- В 2015 году популярность обрели облачные озера данных, эластичные и со схемой работы use/pay per job, объектными хранилищами и дезагрегированной архитектурой.
- Сегодня мейнстримом стали Data Lakehouses — благодаря целостности, безопасности данных, высокой производительности и масштабируемости, а также функциям работы в реальном времени.

Системы больших данных служат для онбординга больших данных для аналитики. Большие данные поступают из разных источников (баз данных или телеметрических потоков) и входят в цикл аналитических операций (изучение, подготовка, обогащение, оптимизация, запрос и т. п.).
Традиционно, чтобы добиться высокого качества и заявленного в SLA времени реагирования, система больших данных должна включать и облачное озеро данных, и хранилище.
Data Lakehouse — это озеро данных с качеством обслуживания на уровне хранилища. В нем можно:
- работать с дезагрегированными данными в объектном хранилище;
- принимать и обрабатывать эластичные и разнородные данные;
- использовать механизмы обработки запросов.
В нем поддерживаются открытые форматы, файловые и табличные. Кроме того, Data Lakehouse может предоставляться как услуга.
Торстен подробно останавливается на шести признаках Lakehouse, типичных для качества обслуживания на уровне хранилищ данных:
1. Согласованность данных. В традиционном объектном хранилище не поддерживаются локальные обновления: новые записи прикрепляются как отдельные файлы. Файлы полностью перезаписываются, даже если изменили или удалили только одну ячейку или один ряд. Многопоточные операции записи и параллельные операции чтения могут мешать друг другу. В результате при выполнении запроса невозможно гарантировать согласованную историю версий. Локальная реорганизация, очистка и сжатие тоже невозможны.
В Lakehouse соответствие требованиям ACID достигается использованием табличных форматов для фиксации истории версий метаданных, которые хранятся вместе с данными.
2. Принудительное применение схемы. Технически любые библиотеки, инструменты или модули могут читать и записывать файлы в объектном хранилище в облачном озере данных. Это еще один аргумент в поддержку открытости архитектуры озера. Однако в этом случае нет принудительного применения схемы, которое гарантировало бы, что схема новых файлов данных согласуется с уже существующими. Или, по крайней мере, совместима с ними.
В Lakehouse используют табличные форматы для разработки общих библиотек, чтобы выполнять операции чтения и записи. Это обеспечивает выполнение схемы, определенной в файлах метаданных.
3. Табличный каталог. Hive Metastore остается золотым стандартом табличных каталогов с эпохи Hadoop. Но в его работе возникают сложности, если количество файлов измеряется шести-семизначными числами или разделы перечислены иерархически.
В Lakehouse реализовано следующее решение: информация о списках файлов децентрализуется с помощью файлов метаданных. Для кросс-табличных транзакций и истории версий используются новые табличные каталоги поверх табличных форматов (Nessie, LakeFS). Следующий рубеж — это объединить табличные каталоги с метаданными в реальном времени: Kafka Schema Registry (Confluent) и Apicurio Registry.
Наиболее популярные Open Source-проекты табличных форматов, созданные между 2017 и 2019 — Apache Iceberg (Netflix), Delta Lake (Databricks) и Apache Hudi (Uber).
- В них реализована абстракция между физическими файлами (например, Parquet) и логическими таблицами.
- Данные хранятся в разных файлах, включающих и данные, и метаданные. Для приема и чтения используют специальные библиотеки, встроенные в модули. Библиотеки выполняют составные функции управления данными (сжатие, очистку), поддерживая масштабируемые данные посредством децентрализации.
- Они поддерживают транзакции и историю версий на уровне таблиц с помощью изоляции снимков для одновременных запросов и приема данных, ретроспективных запросов, «локальных» обновлений и удалений, а также управляемой эволюции схемы.
4. Производительность и масштабируемость. Форматы файлов — ключевой фактор, связанный с производительностью и масштабируемостью. Распространенные форматы, такие как Parquet и ORC, содержат определенную статистику, например, минимальные и максимальные значения и фильтры Блума. Во многих модулях их можно использовать, чтобы пропускать файлы при оптимизации. К сожалению, им все еще приходится читать «подвалы» файлов Parquet/ORC. При этом они не охватывают все индексирование хранилищ данных SOTA, например, кластеризованные индексы со столбцами include.
В Lakehouse реализована поддержка специальных Open Source-фреймворков для индексации, например, XSkipper от IBM и Hyperspace от Microsoft. Данные индекса хранятся в специальных файлах Parquet в объектном хранилище, так что Lakehouse может индексировать файлы любого формата кроме Parquet и ORC.
5. Защита данных. В традиционных хранилищах данных используют механизм Access Control Lists (ACLs) с детализацией на уровне бакета или объекта. Таким образом, невозможно решить задачу подробных ACLs, например, на уровне столбца. Принудительное применение подробного доступа в модулях запросов нежизнеспособно: это убило бы понятие открытости и разнородности в Lakehouse. Далее в традиционных хранилищах строгие требования к безопасности предъявляются только к провайдерам и операторам объектных хранилищ.
Lakehouse нужно подробное принудительное применение доступа и шифрование данных внутри файлов. Комбинированное решение представляет собой Apache Parquet Encryption, которое не зависит от хранилища и транспортируемых доверенных данных. В нем есть поддержка ключей шифрования на уровне столбцов и «подвалов», а еще ACLs для столбцов посредством ACLs на базе ключей (в службе управления ключами).
6. Автоматизация пайплайнов. ETL-пайплайны, которые работают с данными в движении в реальном времени, используют коннекторы Spark или Flink. Они нужны для чтения или записи данных в тему Kafka, с абстракцией, дополнительно реализуемой через Apache Beam. Такие пайплайны размещают потоковые данные в объектном хранилище, например Iceberg, и поддерживают потоковые преобразования topic-2-topic.
Пакетные ETL-пайплайны для данных со Spark используют коннекторы в открытых фреймворках рабочих потоков (MLFlow, Luigi, Kubeflow, Argo, Airflow), а также бессерверные триггеры и последовательности встроенных событий, предоставляемые по принципу FaaS.

На схеме выше показана бессерверная платформа данных, реализованная IBM по принципу lake-as-a-service на основе открытых технологий:
- Центральная служба — SQL Query, которая в бессерверном режиме выполняет прием данных, их пакетную ETL-обработку, каталогизацию и запросы к ним. Решение полностью основано на Spark.
- Cloud Object Storage полностью S3-совместимо с использованием разных открытых форматов.
- Event Streams — это управляемый сервис Kafka с реестром схем, в котором данные в реальном времени подключаются к Cloud Object Storage.
- Watson Studio — это сервис оркестрации на основе Kubeflow для автоматизации заданий пайпланов.
- Интеграция службы Cloud Functions/Code Engine с бессерверными и FaaS-функциями выполняется с помощью триггеров событий и последовательностей.
- Эту платформу можно подключить к приложению с помощью Python, JDBC, REST API и других коннекторов, таких как Dremio.
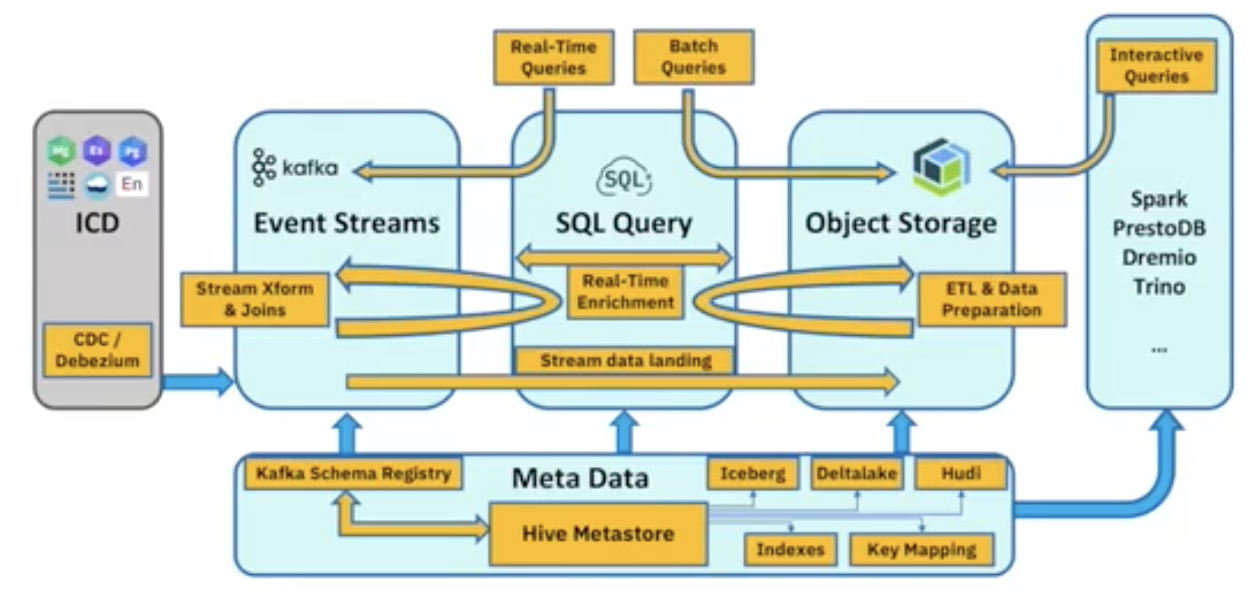
Представление IBM о Lakehouse, работающем с данными в реальном времени, показано на схеме выше. Они планируют повторную централизацию слоя метаданных и его интеграцию с реестром схем Kafka, чтобы создать единое хранилище метаданных для неактивных данных и данных в движении. Это хранилище управляет информацией об индексации и сопоставлении ключей и адаптировано для работы с табличными форматами. Все операции в объектном хранилище можно делать в реальном времени.
Открытые сервисы, такие как Spark, PrestoDB, Dremio и Trino, можно интегрировать в платформу Lakehouse IBM, чтобы воспользоваться ее преимуществами.
Происхождение, цель и методы реализации наблюдаемости данных
Видеозапись выступления
Наблюдаемость данных (Data Observability, DO) — пока еще новое понятие. С ее помощью компании могут выявлять, разрешать и предотвращать проблемы с качеством данных. Для этого необходим непрерывный мониторинг их состояния с течением времени. Kevin Hu, соучредитель компании Metaplane, глубоко погрузился в тему наблюдаемости данных. В своем выступлении он рассказал о ее происхождении, определил сферу применения и компоненты наблюдаемости и поделился действенными советами о внедрении наблюдаемости на практике.
С середины 2010-х хранилища встали на самый верх цепочки создания выгоды с помощью данных. На практике это экосистема параллельно развивающихся инструментов, которые упрощают извлечение и загрузку данных из источников в хранилище. Они трансформируют эти данные и делают их доступными для конечных пользователей.
С появлением «современного стека» все больше данных централизованно размещают в одном месте, после чего используют для критически важных приложений: в области операционной аналитики, обучения ML-моделей и изучения удобства использования ИТ-продукта. Мы можем менять данные даже после размещения их в хранилище: то, что раньше было неизменным, стало гибким. Это увеличило объемы данных, их важность и фрагментацию поставщиков.
Команды по обработке данных могут многому научиться у разработчиков ПО. С инструментами наблюдаемости ПО, такими как Datadog, Grafana и New Relic, каждая команда разработчиков научилась быстро собирать метрики из всех систем и моментально получать аналитические сведения об их работоспособности. Они трансформировали мир программного обеспечения: витиеватая низкоинформационная среда, в которой невозможно было получить подробные данные, превратилась в прозрачную и наблюдаемую.
Три столпа наблюдаемости программного обеспечения — это метрики, отслеживание и логи:
- Метрики — цифровые значения, которые описывают компоненты программной системы на протяжении определенного времени. Например, использование ресурсов процессора микросервисами, время отклика конечной точки API или размер кэш-памяти в базе данных.
- Трассировки — описывают зависимости между элементами инфраструктуры. Например, жизненный цикл запроса приложения от конечной точки API к серверу и потом к базе данных.
- Логи — самый низкоуровневый элемент информации. Описывает и состояние элемента инфраструктуры, и его взаимодействие с внешним миром.
Опираясь на эти основы, разработчики и DevOps-инженеры могут получить четкое и наглядное представление об инфраструктуре и ее изменениях во времени.

Отталкиваясь от вышеперечисленных основ, Кевин пришел к четырем основам наблюдаемости данных:
- Метрики. Если данные числовые, у них есть статистика распределения показателей: среднее, стандартное отклонение и коэффициент асимметрии распределения. Если мы имеем дело с категориями, сводная статистика распределения представляет собой количество групп и их уникальность. Для всех типов данных можно рассчитать такие метрики, как полнота, наличие или отсутствие конфиденциальной информации, точность.
- Метаданные. Метаданные включают такие свойства, как объем, схема и свежесть данных — все это можно масштабировать независимо, сохраняя при этом статистические характеристики.
- Lineage. Data lineage определяет двунаправленные зависимости между датасетами, которые различаются по уровню абстракции от lineage целых систем, таблиц, столбцов и значений.
- Логи. В логах регистрируется, как данные взаимодействуют с внешним миром. Их можно классифицировать как взаимодействие «машина-машина» (перемещения, трансформации) и «машина-человек» (создание новых моделей данных, работа с дашбордами, построение ML-моделей).
Чтобы внедрить наблюдаемость данных, нужно понимать, какие бизнес-цели ставит перед собой компания. Вот пять ключевых целей, перечисленных в порядке увеличения уровня абстракции: сэкономить время разработчиков; избежать расходов, связанных со снижением качества данных; повысить эффективность команды по обработке данных; расширить data awareness; сохранить доверие.
Как можно измерить прогресс? Кевин привел несколько примеров метрик для двух целей:
- Чтобы сэкономить время разработчиков, посмотрите на количество проблем с качеством данных, длительность их выявления и устранения.
- Если вы хотите сохранить доверие, отслеживайте качественные опросы стейкхолдеров (например, NPS), количество входящих тикетов и цели и условия соглашений об уровне обслуживания.
Качество данных затрагивает всю компанию, но ответственность за последствия лежит на командах по обработке данных. Вам понадобится выяснить, кто в этой ситуации стейкхолдер, чтобы предоставить необходимую поддержку как можно раньше. Стейкхолдерами могут быть производители данных, которые входят в команду разработчиков, продукта или выхода на рынок. Или дата-аналитики, которые анализируют данные и конструируют модели данных. Или потребители: руководство, инвесторы и финансовые аналитики.

Чтобы обеспечить высокую эффективность наблюдаемости, нужно выстроить процессы:
- Профилактику — условия контрактов, Agile, модульное тестирование.
- Активную наблюдаемость — CI/CD hook.
- Пассивную наблюдаемость — непрерывный мониторинг.
- Набор методов по устранению инцидентов (PICERL).
Для настройки этих процессов существует множество инструментов: можно пробовать Open Source-проекты, создавать проприетарные или приобретать коммерческие решения.
Создание отказоустойчивой системы. Как Wistia обеспечила взаимодействие и наблюдаемость в пайплайнах данных
Видеозапись выступления
Есть ощущение, что специалисты по обработке данных часами играют в детективов, выслеживая, где же случился сбой в пайплайне. Donny Flynn, архитектор пользовательских данных в компании Census, продвигающей подход Reverse ETL, и Chris Bertrand, дата-сайентист в компании Wistia, подробно рассказали о важности взаимодействия и наблюдаемости при создании отказоустойчивых систем по работе с данными. Они также объяснили, как Reverse ETL помогает превратиться из сыщика в героя.
Census — это центральный элемент современного стека данных, инструмент Reverse ETL по операционной аналитике. Snowflake — это облачное хранилище данных, которое выступает единым источником истины для бизнеса. У вас есть разные источники данных в виде бизнес-приложений и SaaS-инструментов. У вас есть трансформации (dbt), которые происходят в хранилище данных, и аналитические данные для инструментов бизнес-аналитики (Looker). Вполне возможно, ваше хранилище принимает события из Segment. Census синхронизирует данные из хранилища и инструментов бизнес-аналитики с операционными инструментами.

Census совместима с экосистемой пайплайнов данных. Это могут быть решения для потоковой передачи событий, например, Snowplow, Kafka или Fivetran, которые переносят данные в ваш датахаб. Или оркестраторы заданий вроде Airflow, Prefect или Dagster.

Наблюдаемость становится важнейшим приоритетом для дата-инженеров. Особенно если учитывать, с чем приходится сталкиваться пайплайнам: с управляемыми серверами, меняющимися типами данных, ограничениями памяти и процессоров, непрогнозируемыми объемами данных и кодом с ошибками. А из сторонних сервисов при этом приходят данные об ошибках, нюансах схем, ограничений тарифов и стоимости использования API. Причем каждый инструмент воспринимает эти концепции по-разному.
Оповещения идут рука об руку с наблюдаемостью. Как вы узнаете о сбоях в работе? Это непростой компромисс — получать оповещения о серьезных проблемах и не отвлекаться на мелочи. Крайне важно определить, как и когда вы получаете сообщения о сбое, даже когда ваша компания разрабатывает и внедряет новые процессы.
Как Wistia использует Census для внедрения наблюдаемости? Исходная архитектура данных выглядит так:

- Пользователи Wistia, работающие с компьютеров и смартфонов, взаимодействовали с приложением, написанным на Rails, и использовали MariaDB. Их специалисты по продажам и работе с клиентами используют Salesforce, так что для них важно получать информацию об использовании Wistia из основного приложения. Поэтому они выполнили пользовательскую интеграцию, с помощью которой API обращается с вызовом к Salesforce.
- В то же время они использовали Fivetran, чтобы реплицировать экземпляры MariaDB в хранилище Amazon Redshift.
Почему в Wistia решили изменить эту архитектуру? При пользовательской интеграции с Salesforce возникает пять проблем:
- Из-за изменений в хранилище данных потребовалась ревизия кода на уровне приложения, а это весьма обременительная задача.
- Из-за изменений в хранилище данных нужно было работать с базой кода Rails (Ruby) — для нетехнических специалистов это сложно.
- Есть доступ только к данным приложения.
- Архитектура была кастомизирована для CRM-схемы Wistia.
- Любые системные сбои отправлялись в экземпляр Bugsnag как мусор, так что они реагировали на эти ошибки.
В итоге в Wistia переработали архитектуру:
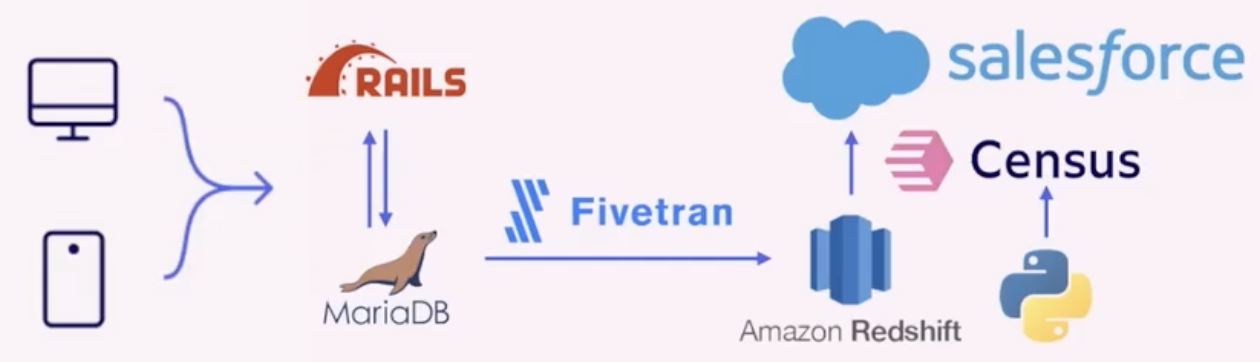
Теперь в парк их ИТ-продуктов попадает Census. Они работают с API Census, использующим скрипты Python, чтобы управлять синхронизацией данных между Redshift и Salesforce. В результате им больше не нужно отправлять данные из Rails в Salesforce. Вот к каким улучшениям это привело:
- Для внесения изменений в хранилище данных теперь нужно проходить тесты dbt.
- Для внесения изменений в хранилище данных нужно работать с более знакомым языком — SQL.
- Есть доступ ко всем данным в хранилище.
- Архитектура все еще кастомизирована для CRM-схемы Wistia.
- В случае системного сбоя по электронной почте отправляются оповещения, а мониторинг встроен во внутренние системы.
Команда VK Cloud Solutions тоже развивает экосистему для построения Big Data-решений. Вы можете ее протестировать — для этого мы начисляем новым пользователям 3 000 бонусных рублей.
Что почитать по теме:
