Привет, Хабр!
Человечество уже написало кучу программ, которые хранят информацию в базах данных. Базы данных, как правило, побуждают думать о мире с точки зрения объектов. В случае Билайна это могут быть абоненты или сотовые вышки, у каждого из них есть какое-то состояние, и мы берём эту информацию, кладём её в базу данных, после чего строим на этом аналитику – допустим, считаем количество абонентов.
Вроде всё хорошо, но у такого подхода обнаружились и недостатки – например, обработка данных при таком подходе откладывается на самый последний этап, когда нам уже понадобилась аналитика. А это может занять довольно много времени, что приводит к задержкам аналитики. Это натолкнуло на мысль о том, что порой удобнее думать о мире в парадигме событий. Каждое событие тоже может иметь своё описание, как и вещь – но главная идея состоит в том, что событие является указанием во времени о появлении факта. Например, если бы мы для подсчёта абонентов имели поток событий – добавление нового абонента, отключение или перевод – мы могли бы быстро посчитать количество абонентов на текущий момент, если бы мы знали их начальное количество и постоянно обрабатывали этот поток.
Для хранения потоковой информации использовать структуру под названием log. Название вам знакомо, и не случайно вы с ней сталкиваетесь, читая консольный вывод приложений. Суть в том, что log – это просто упорядоченная во времени последовательность объектов. Когда происходит событие, мы можем просто добавлять его в конец лога с небольшим описанием происшедшего. Это скажет нам о том, что это событие произошло в определённое время относительно других событий. Всё это выглядит достаточно просто.
Kafka – это как раз система управления распределёнными логами. Логи в Kafka называются topic. Kafka заботится о том, чтобы топики надёжно хранились, записывались на диск, реплицировались между серверами, чтобы сбои на аппаратном уровне не приводили к потере данных. Топики в Kafka могут храниться за разные промежутки времени – это может быть несколько часов, несколько дней, лет, и вообще сколько угодно. Топики могут быть разного размера – в них может быть пара событий в день/неделю, или тысячи; на это тоже нет аппаратных ограничений. Думать о топиках можно как об упорядоченном наборе событий.
Примеры
Использование Kafka неплохо встраивается в популярную микросервисную архитектуру. Например, есть три сервиса, которые нужно интегрировать между собой. Первый S1 как-то собирает данные из источников, S2 их преобразует и делает какие-то подсчёты, а S3 их визуализирует. Способов интегрировать их вместе есть много, например, они могут общаться друг с другом при помощи топиков Kafka. S1 может класть полученные данные в топик Kafka, второй читать их оттуда, делать только ему известные преобразования, и класть результат в другой топик. Он сразу станет доступным для получения и обработки третьим. Он тоже может сразу получать сообщения из этого топика и сразу их визуализировать. Можно сказать, что подобная интеграция сделана с использованием событий, а не объектов.
На многих проектах такая система работает уже довольно давно. Подход, в котором измерения запускались по расписанию на какой-то подготовленной выборке данных, уже не устраивает. Проектам нужно обрабатывать данные сразу, чем раньше, тем лучше. Использование событий как раз позволяет строить такие решения.
Давайте опустимся на один уровень архитектуры ниже, и посмотрим, что собой представляет Kafka и как с ней взаимодействовать. Когда мы говорим о Kafka, как правило мы говорим о кластере, состоящем из нескольких брокеров. Брокеры – слой хранения данных, отправкой же и получением данных занимаются сервисы kafka connect_Как правило каждый брокер обслуживает несколько топиков.
А каждый топик – это набор партиций, каждая из которых является логом. Честнее было бы сказать, что топик – это набор логов. Но работать с партициями напрямую в Kafka совершенно необязательно, поэтому топик можно представлять как лог.
Партиции в Kafka нужны для нескольких вещей. Во-первых, для распределения доступа к сообщениям в топике. Во-вторых, партиция – это единица репликации между брокерами. Начнём с первого.
Распределение доступа к сообщениям в топике
Сервисы, которые отправляют сообщения в Kafka, принято называть продюсерами. У продюсера есть возможность указать номер партиции, в которую он хочет, чтобы сообщение попало, но это не обязательно. Если указан только топик, без партиции, партиция определится исходя из ключа сообщения, а для хэширования будет использования алгоритм Murmur2. Прикольный алгоритм, почитайте про него, если интересно. Если у сообщения нет ключа – а такое тоже возможно – партиция будет распределяться случайным образом, алгоритмом RoundRobin. Выглядеть это может как-то так: мы засылаем какое-то количество событий, и они как-то попадают в партиции.
И тут уже можно заметить несколько интересных вещей. Во-первых, если продюсер не указал партицию, то сообщения по партициям распределятся примерно равномерно. Во-вторых, порядок сообщений при хранении в Kafka гарантируется лишь в рамках одной партиции – этот факт нужно учитывать при разработке систем, работающих с Kafka.
Что ж, теперь у нас есть топик с тремя партициями - давайте посмотрим, как будет происходить чтение. Kafka разделяет разных потребителей данных с топика по идентификатору GroupId. Разные потребители с разными идентификаторами читают топик совершенно независимо друг от друга. Внутри же одной consumer-группы (consumer-группа и группа id — это всё одно и то же) дела обстоят интереснее. Чтение сообщений из Kafka можно разделить на два этапа: это непосредственно получение сообщения и подтверждение получения. В зависимости от настроек, когда консьюмер пытается запросить у Kafka «дай мне сообщение», вы получите сколько-то сообщений. После чего вы можете подтвердить факт прочтения этих сообщений, и в таком случае Kafka для вашей группы id сохранит место, с которого вы продолжите читать в следующий раз.
Вот, например, вы считали и подтвердили. Дальше считали уже начиная с того места, где остановились, и подтвердили. И ещё раз считали и, например, по какой-то причине перестали – упали, не подтвердив последние чтение. В следующий раз, когда вы снова продолжите получать данные с этого топика, вы продолжите с того места, с которого подтвердили прочтение последний раз. Как я уже говорил, в рамках консьюмер-группы партиции используются для распределения доступа к сообщениям. В рамках одной консьюмер-группы у нас может быть несколько консьюмеров. И в таком случае каждый из них будет получать сообщения из определенной партиции. Так как сообщения распределены по партициями равномерно, то каждый консьюмер будет получать примерно одинаковое количество сообщений. Это позволит нам как раз балансировать на балансировать вычитку этих сообщений. Это также означает, что держать количество консьюмеров в рамках одной консьюмер группы больше, чем количество партиций, бесполезно - потому что по принципу Дирихле у нас окажется, что есть консьюмер, у которого нет партиций, которые он будет читать. Сам процесс распределения партиций по инстансам консьюмеров называется, очевидным образом, «балансировка», и происходит каждый раз, когда меняется набор активных консьюмеров в рамках группы.
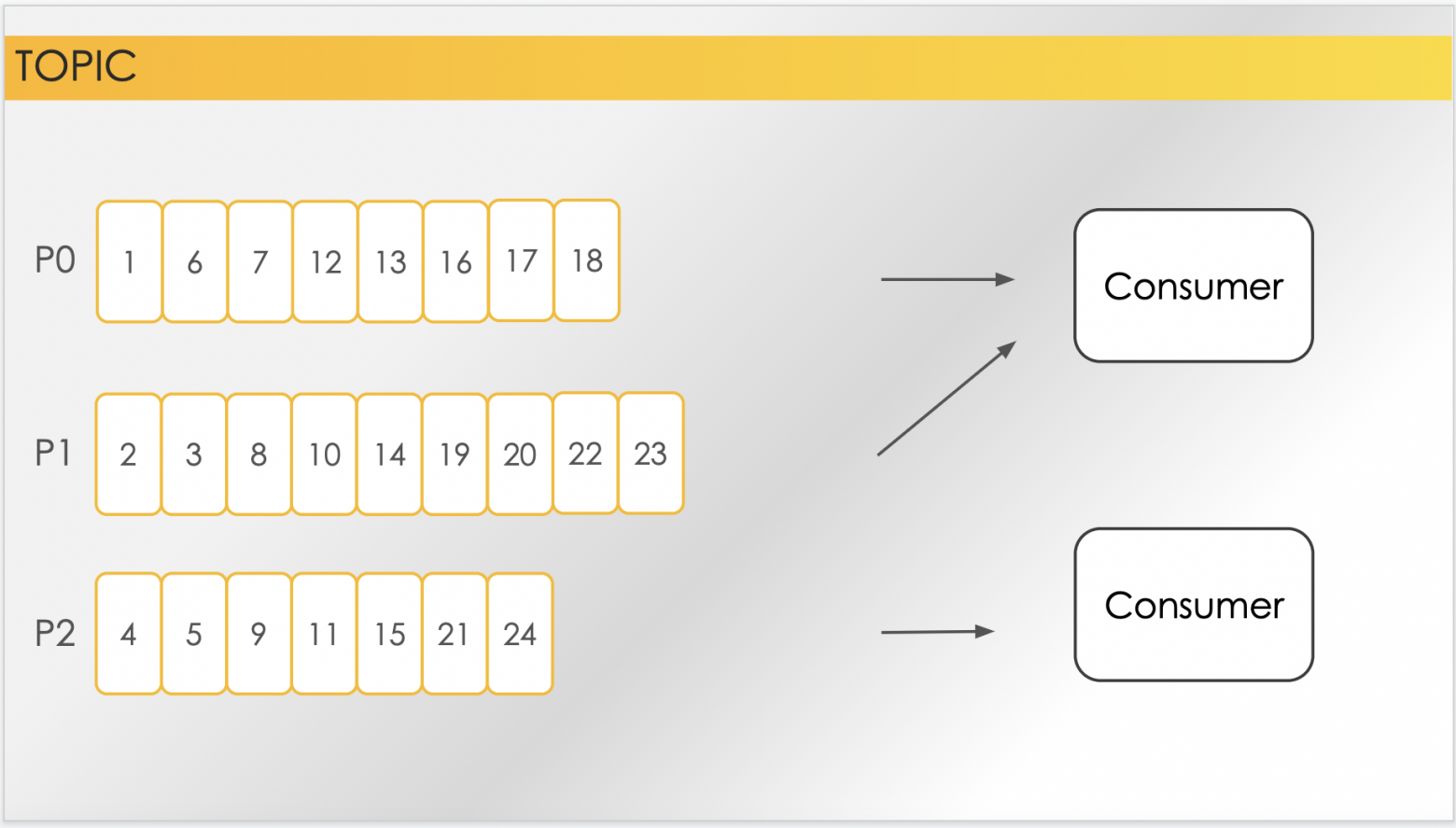
Например, как на слайде: у нас было два консьюмера, которые читали топик с тремя партициями. Две партиции читал один консьюмер, третью читал другой. По какой-то причине первый читать перестал, и в таком случае все сообщения из всех трёх партиций начнут попадать оставшемуся активному консьюмеру. А когда второй консьюмер, например, появится снова, то опять произойдет балансировка и примерно равномерно распределятся сообщения.
Репликации партиций между брокерами
Для каждой партиции топика из брокеров кластера определяется лидер — это брокер, который ответственен за приём новых сообщений в партицию для обеспечения репликации данных. Из остальных брокеров, в зависимости от настроек, выбираются те, которые будут хранить или поддерживать копию этих данных. То есть, само количество копий партиции определяется настройками топика, и называется «фактор репликации».
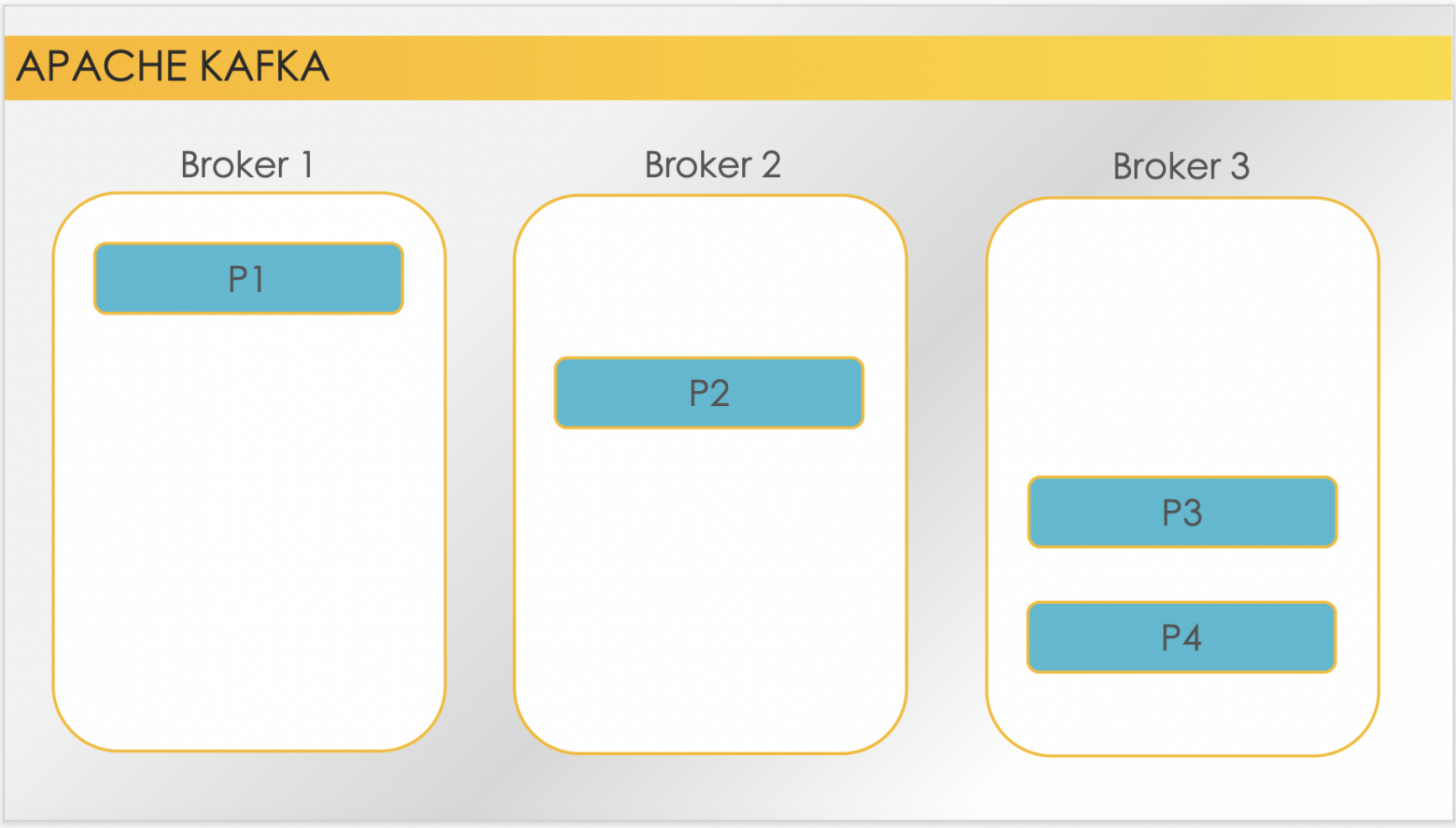
Вот так, например, будет выглядеть топик с четырьмя партициями на кластере из трёх брокеров с фактором репликации, равным «3». То есть, у каждой партиции есть лидер, и каждая партиция представлена в трёх копиях на кластере. Но, как правило, брокеров всё же меньше, чем реплик, потому что репликация — это всегда большой overhead и на место, и на производительность. Поэтому вот примерно так может выглядеть тот же самый топик на том же самом кластере с фактором репликации «2». И репликация понятным образом позволяет реализовать механизм отказоустойчивости. Когда по какой-либо причине один из брокеров выходит из строя, происходит выбор новых лидеров из оставшихся в живых брокеров с репликами. Также происходит выбор новых реплик, которые остались живы. После того, как какой-то упавший брокер снова станет доступен, снова произойдет балансировка, и какие-то лидеры и партиции уедут на него.
Теперь про физическое представление данных.
Kafka хранит сообщения в партициях топиков, сериализованном байтовый массив виде. Вопрос сериализации-десериализации решается на уровне клиентов Kafka. Сами сообщения состоят из трёх частей — это ключ, header и значение, и каждая часть может быть сериализована и десериализована самостоятельно. В настоящий момент в Билайне этот вопрос решается самостоятельно продуктовыми командами, не стандартизирован, и можно использовать любые способы сериализации «из коробки». Kafka предоставляет механизмы десериализации и сериализации стандартных типов, типа int, float, string так далее, и в самом простом варианте код, который записывает сообщение в Kafka на языке Scala будет выглядеть как-то так.
Необходимо соответственно создать объект класса properties, в него передать параметры для подключения к Kafka (это bootstrap-сервис), классы, которые будут ответственны за сериализацию, включая значение и client.id, который используются для того, чтобы расставлять в сообщении metadata каким именно продюсером оно отправлено. После чего создать экземпляр класса KafkaProducer и вызвать его метод send, передав туда объект ProducerRecord, куда уже непосредственно передать данные.
Естественно, этот код написан с использованием стандартной библиотеки работы с Kafka, однако и других библиотек великое множество. Плюс ко всему каждый уважающий себя фреймворк для работы с данными поддерживает способ передачи данных через Kafka – будь то Spark, Flink что угодно.
Нужно ещё добавить тут о возможности синхронной отправки сообщений. Например, отправить сообщение в Kafka (сам send) можно сделать тремя способами.
Первый – «отправить и забыть» условно. Так как метод send возвращает объект feature от record metadata, можно вызвать у него метод get и сделать отправку сообщения в Kafka синхронно: дождаться ответа от Kafka, что она получила сообщение и как-то это обработать. Или же можно вызвать метод send, передав туда экземпляр, реализующий интерфейс callback, метод onCompletion которого будет вызван тогда же? когда придет ответ от Kafka, что она получила сообщение. Пользоваться этим можно, но не обязательно, потому что с доступностью у Kafka всё нормально.
Также хочется добавить, что важным, на мой взгляд, дополнением к контролю интеграции сервисов через Kafka есть контроль над контрактом над топиками. Для этого есть формат сериализации под названием Avro с использованием схем registry. Avro сам по себе это формат бинарной сериализации с использованием схемы данных. Схема выглядит примерно вот так – это JSON-подобная структура, у которой есть имя, и которая описывает поля непосредственно объектов, пытающихся этим способом сериализоваться. Вот, например, схема, содержащая поле с названием id типа long, и поле с названием name типа string. Она будет сериализовывать и ответственна за вот такие вот объекты.
А код, работающий с Avron-сериализацией будет выглядеть уже примерно как-то так. Отличается он тем, что мы для, например, значения используем уже другой сериализатор – KafkaAvroSerializer. Также мы передаем один из конфигурационных параметров — это путь к схеме registry. Это ещё одна штука, про которую я чуть позже расскажу. Соответственно, после чего нам уже нужно вместо строки передать объект в продюсер GenericRecord, он собирается из схемы, и также туда проставляются значения этого объекта. И всё это уже выглядит несколько сложнее, и резонный вопрос - зачем это всё нужно.
Затем, что это позволяет всё же зафиксировать интеграционный контракт на топики, то есть, фиксировать факт того, что в топике представлены только сообщения определенного формата. Это достигается как раз за счёт использования сериализаторов, работающих со схемой registry. Как это работает: сама схема registry — это инструмент для хранения и версионирования схем. И когда продюсер с помощью KafkaAvroSerializer-а попытается сериализовать сообщение для отправки в топик, схема будет пытаться зарегистрироваться в схеме registry. И если возникнут какие-то проволочки с тем, что схема изменилась, или не может быть совместима с тем, что уже есть - будет выкинуто исключение и отправлено сообщение продюсеру, и тем самым предотвращено попадание в топик сообщений, которые нельзя десериализовать по схеме. То есть, уже обратный процесс - то есть, прочитать, исходя из этой схемы.
Ещё примеры
Давайте теперь рассмотрим уже непосредственно код, который читает сообщения с Kafka. Это выглядит всё примерно тем же самым образом, собирается такой же объект property. Единственное что - идентификатор client.id меняется на идентификатор группы. Это как раз тот идентификатор группы, который Kafka использует для распределения сообщений. Нужно создать объект KafkaConsumer с настройками, которые мы составили до этого, после чего подписаться на список топиков (можно подписаться сразу на несколько топиков), после чего вызвать метод poll объекта консьюмер, передав ему, сколько мы готовы ждать новое сообщение.
Политик на этот счёт у Kafka тоже несколько. Kafka за один poll отдаст вам либо MaxPollRecords сообщений (это ещё один из параметров консьюмер, который можно передать), либо все оставшиеся сообщения в топике, либо будет ждать столько, сколько вы передадите как аргумент методу poll новых сообщений, пока не придут. После чего мы можем уже по ним проитерироваться и их как-то разобрать. И это все представляет самый простой случай чтения с Kafka.
В случае же Билайна Kafka ещё закрыта Kerberos-авторизацией. Для того, чтобы авторизоваться по Kerberos, используя языки программирования, нужно передать в Kafka ещё ряд настроек. Первая — это security protocol; SASL_PLAINTEXT будет означать, что Kafka в принципе нужно использовать авторизацию для доступа к брокерам. Потом sasl.kerberos.service.name, kafka — это идентификатор сервиса, который будет керберосом использоваться для аутентификации на брокерах, и пути к двум файлам. Первое — это путь к конфигурации самого Kerberos, где проходить аутентификацию. Второе - и файл jaas.conf, в котором содержатся инструкции для Kerberos, откуда брать явки и пароли для аутентификации.
Если добавить эти property к тому, что было, мы можем увидеть, как в реальности в Билайне выглядит конфигурация для того, чтобы работать с Kafka. Это уже выглядит совсем никак не смешно, и напрашивается на то, чтобы закрыть это всё в какую-то библиотеку для работы с Kafka в Билайне.
Сейчас такая работа уже ведётся, презентовать её пока надобности нет, но если у кого-то есть желание поучаствовать в разработке, либо потестировать то, что уже сделано в качестве библиотеки для того, чтобы проще было конфигурировать приложение для работы с Kafka - можете ко мне приходить.
В целом это всё, о чём я хотел рассказать. Если у вас есть вопросы или уточнения, буду рад ответить в комментариях.

