Это вторая статья, посвященная графовой базе данных Neo4j. Первую статью о моделировании схемы данных можно почитать тут: https://habr.com/ru/post/677296/
Суть статьи — небольшое практическое отступление до того, как мы разберем новые концепции в Neo4j.
Все приведенные в статье примеры будут работать, если скачать и поставить себе по ссылке локально бесплатную копию Neo4j с предустановленной Movie DBMS.
Написание запросов
Разберем простейший синтаксис написания запросов к Neo4j по CRUD.
Чтение данных
Для начала, надо вспомнить что в структуре данных у нас есть:
Nodes — сущности;
Labels — метки к сущностям;
Relationships — однонаправленные отношения между сущностями;
Properties — свойства сущностей или отношений.
Очень упрощенно, основной шаблон запроса для чтения записей можно описать следующим образом:
(<var>:<entity> [{<property>: <value>[, ...]}])<direction>[:<relationship>]<direction>(<var>:<entity>[{<property>: <value>[, ...]}])
Согласен, с примером будет понятнее :)
Вспомним нашу базу данных с фильмами и актерами, и попробуем сделать запрос к ней
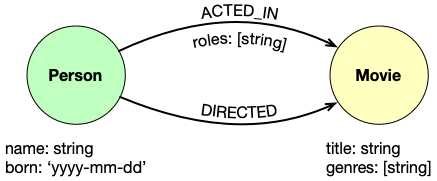
// Найти все фильмы MATCH (m:Movie) RETURN m
Для получения какой-то выборки используется ключевое слово MATCH (точная копия SELECT из RDBMS).
m:Movie — тут мы присваиваем переменной m все найденные Movies по заданным условиям.
RETURN p — явно указываем что должен вернуть наш запрос.
Больше примеров:
// Найти всех актеров с именем Tom Hanks: MATCH (p:Person {name: 'Tom Hanks'}) RETURN p
{name: 'Tom Hanks'} — условие фильтрации по сущности Person
Но, графовая БД не была бы таковой, если бы в ней не было главной особенности: связей между сущностями.
Давайте найдем все фильмы, в которых играл Tom Hanks:
MATCH (p:Person {name: 'Tom Hanks'})-->(m) RETURN m.title
m — тут мы присваиваем переменной m все найденные зависимые сущности по заданным условиям.
Отлично! Но неправильно :) Потому что это вернет нам все его связи со всеми зависимыми сущностями по всей базе данных, если таковые будут. Нам это не нужно, мы хотим получить фильмы, в которых он играл. Добавим тип связи ACTED_IN:
MATCH (p:Person {name: 'Tom Hanks'})-[:ACTED_IN]->(m) RETURN m.title
Уже лучше, но тоже неточно. Этот запрос вернет все сущности, в которых он играл, не только фильмы. Он же мог играть и в театральных постановках, правильно?
Эти примеры выше работают благодаря так называемомой способности traverse, если говорить в терминах Neo4j.
Нода, хоть как-то связанная с другой нодой (даже через другие N нод), соответственно, — traversable-нода.
Конкретно в нашей схеме данных других сущностей нет, поэтому получим только Movies. Но лучше не копить техдолг, а явно указать что мы ожидаем только фильмы:
MATCH (p:Person {name: 'Tom Hanks'})-[:ACTED_IN]->(m:Movie) RETURN m.title
Теперь отлично!
Больше примеров:
// Найти список всех актеров из "Матрицы" MATCH (m:Movie {title: 'The Matrix'})<-[:ACTED_IN]-(p:Person) RETURN p // Найти всех режиссеров, родившихся до 1970 года // Обратите внимание: нам не важно ЧТО именно они режиссировали, // поэтому тип ноды не указываем: MATCH (p:Person)-[:DIRECTED]->() WHERE p.born < 1970 RETURN p
Можно комбинировать связи:
// Найти все фильмы, в которых Tom Hanks // был одновременно актером ИЛИ режиссеором: MATCH (m:Movie)<-[:ACTED_IN|:DIRECTED]-(p:Person {name: 'Tom Hanks'}) RETURN m.title, p.name
В общем случае, ключевое слово WHERE работает почти так-же, как и в RDBMS, поэтому на нем подробно останавливаться не буду. Однако есть интересные применения в контексте проверки связей:
// Найти всех актеров, которые играли в фильмах, // но не являлись при этом режиссером фильма: MATCH (p:Person)-[:ACTED_IN]->(m:Movie) WHERE NOT exists( (p)-[:DIRECTED]->(m) ) RETURN p.name, m.title // Обратиться к атрибуту связи: // найти имя актера, который играл Нео в Матрице MATCH (p:Person)-[r:ACTED_IN]->(m:Movie) WHERE 'Neo' IN r.roles AND m.title='The Matrix' RETURN p.name, r.roles
Запись данных
Для добавления данных в Neo4j используется слово MERGE, однако будет большой ошибкой проводить полную аналогию с ключевыми словами CREATE или INSERT из RDBMS.
Дело в том, что MERGE создает паттерн в базе данных.
Проще сразу с примерами:
// Создать ноду Person с именем Michael Cain MERGE (p:Person {name: 'Michael Cain'}) // Создать две ноды (да, это один запрос на три строчки) MERGE (p:Person {name: 'Katie Holmes'}) MERGE (m:Movie {title: 'The Dark Knight'}) RETURN p, m
Небольшое отступление: можно также использовать ключевое слово CREATE с той лишь разницей, что CREATE не будет проверять по первичному ключу существует ли уже такая нода в БД — это дает ему огромное преимущество в скорости. CREATE чаще всего используют для дампов, чтобы быстро можно было их развернуть на чистой базе. MERGE занимается вставкой данных более аккуратно — с проверкой всех условий, но и более медленно.
Создадим простой паттерн через MERGE:
MATCH (p:Person {name: 'Michael Cain'}) MATCH (m:Movie {title: 'The Dark Knight'}) MERGE (p)-[:ACTED_IN]->(m)

Ничего не изменилось.
Дело в том, что в этом запросе MATCH говорит нам о том, что мы должны найти записи, а MERGE о том, что мы должны создать связь между ними. Однако, если записи не найдены, то связь и не создастся. Для гарантированного создания сущности или связи можно использовать MERGE для всех трех частей запроса:
MERGE (p:Person {name: 'Michael Cain'}) MERGE (m:Movie {title: 'The Dark Knight'}) MERGE (p)-[:ACTED_IN]->(m) // или в одну строку: MERGE (p:Person {name: 'Michael Cain'})-[:ACTED_IN]->(m:Movie {title: 'The Dark Knight'}) RETURN p, m
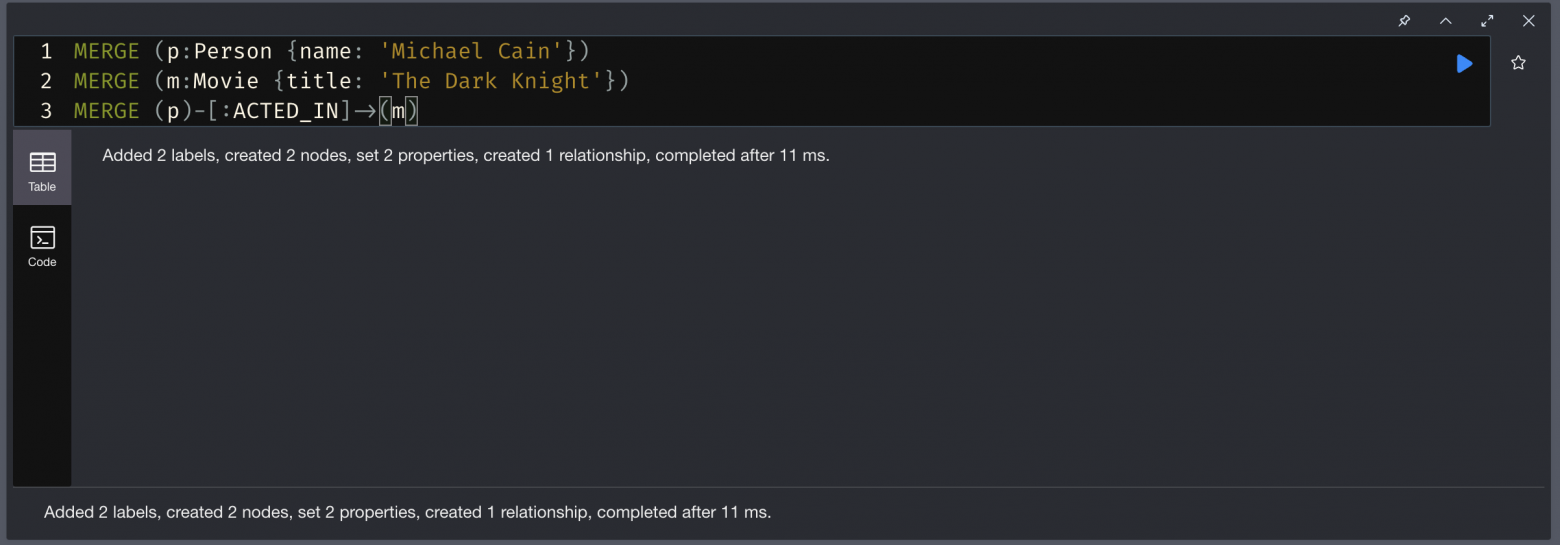
Что тут происходит по логике обработчика запроса:
Neo4j пытается найти сущность
Personс именем Michael Cain;Если сущность найдена, то Neo4j смотрит все ее связи
ACTED_IN;Затем среди этих связей Neo4j ищет
Movieс названием The Dark Knight.
Если хотя-бы на одном из этих этапов не было найдено объектов, то будет создан весь паттерн. То есть, если даже фильм The Dark Knight существует, а актер Michael Cain нет, то будет создан новый фильм с таким названием. Это важнейшая особенность, которую стоит учитывать, чтобы избегать дублирования данных.
Попробуем воспроизвести это:
// Выполним трижды запрос на добавление актеров в один и тот-же фильм MERGE (p:Person {name: 'Yuri Nikulin'})-[:ACTED_IN]->(m:Movie {title: 'The Diamond Arm'}) RETURN p, m MERGE (p:Person {name: 'Nina Grebeshkova'})-[:ACTED_IN]->(m:Movie {title: 'The Diamond Arm'}) RETURN p, m MERGE (p:Person {name: 'Andrei Mironov'})-[:ACTED_IN]->(m:Movie {title: 'The Diamond Arm'}) RETURN p, m // Найдем все записи с этим названием фильма MATCH (m:Movie {title:'The Diamond Arm'})<-[:ACTED_IN]-(p:Person) RETURN m,p

Решением такого кейса может быть создание всех сущностей отдельно и затем отдельно связей между ними. Всё отдельными запросами.
Более сложный пример для создания паттернов:
// В нашей базе Oliver Stone и Rob Reiner никогда не работали вместе, // то есть у них нет общего фильма. // // В этом запросе мы ищем обоих // и создаем новый отличный безымянный фильм для них :) MATCH (oliver:Person {name: 'Oliver Stone'}), (reiner:Person {name: 'Rob Reiner'}) MERGE (oliver)-[:DIRECTED]->(movie:Movie)<-[:ACTED_IN]-(reiner) RETURN movie
Также полезно знать, что для добавления и обновления атрибутов используется ключевое слово SET:
MATCH (p:Person)-[r:ACTED_IN]->(m:Movie) WHERE p.name = 'Michael Cain' AND m.title = 'The Dark Knight' SET r.roles = ['Alfred Penny'], r.year = 2008 RETURN p, r, m
Удаление данных
Это, пожалуй, самый простой раздел, потому что ломать — не строить :)
Самое важное знание тут — это то, что нельзя удалить ноду, пока у нее есть хоть одна связь.
Удалим все фильмы с названием The Diamond Arm, которые мы создали ранее:
MATCH (p:Person) WHERE p.name = 'Jane Doe' DELETE p

Окей, нельзя удалять пока есть связи. Для быстрой починки этого у нас есть ключевая пара слов DETACH DELETE. Но если мы используем такое для удаления фильмов, то никогда потом не найдем актеров из них, которых тоже хотелось бы удалить.
Тогда удалим сначала актеров, потом сами дубликаты фильмов:
// Отцепим (DETACH) и удалим актеров фильмов с названием The Diamond Arm MATCH (m:Movie {title:'The Diamond Arm'})<-[:ACTED_IN]-(p:Person) DETACH DELETE p // Удалим сами дубликаты фильмов с названием The Diamond Arm. // Отцеплять (DETACH) уже не нужно, т.к. актеров вместе со связями // мы удалили только что MATCH (m:Movie {title:'The Diamond Arm'}) DELETE m
Для удаления атрибутов можно просто присвоить им значение null или явно вызвать ключевое слово REMOVE:
// Вот так MATCH (p:Person) WHERE p.name = 'Gene Hackman' SET p.born = null RETURN p // Или так MATCH (p:Person)-[r:ACTED_IN]->(m:Movie) WHERE p.name = 'Michael Cain' AND m.title = 'The Dark Knight' REMOVE r.roles RETURN p, r, m
Заключение
Как видно из примеров выше, работать с графовыми БД довольно просто, но в то же время необычно для тех, кто много времени проводит с SQL, нужно немного перестроить мышление.
А о том, как это сделать я расскажу в следующих статьях ;-)

