Всем привет! Меня зовут Илья, я фронтенд-разработчик в hh.ru. В статье расскажу, как внедрить GraphQL на фронте, не переломав всё на своем пути.
В проекте мы используем React и Redux, для асинхронных запросов у нас есть собственная библиотека, а бэкенд работает на Java. Для получения данных используем страничные URL, а когда заходим на страницу, прямо по URl-у забираем все данные Аяксом. Это влечет за собой две проблемы — overfetching и underfetching. Проще говоря, либо у нас избыток данных, которые используются в данном рендере, либо их нехватка. Эту беду и призван решить GraphQL.
Если лень читать или больше нравится видеоформат — вам сюда.

Начнем ресерч
Итак, мы вместе с бэкендом уходим на ресерч. В процессе бэк выбирает свой фреймворк, а мы смотрим, что у нас там есть на фронте. А там целых три фреймворка — Relay, Apollo и URQL.
Relay
Relay — это библиотека Фейсбука, очень мощный инструмент. В нем целая плеяда возможностей, но он оказывает довольно сильное влияние на архитектуру фронтенда и даже бэкенда. Это нам не очень подходит.
Apollo
https://www.apollographql.com/docs/react/
У Apollo потрясающее комьюнити, очень много пакетов, плюшек и свистелок. Это очень подкупает, но поскольку это большой фреймворк, он теряет в гибкости. Впрочем, все еще оставаясь привлекательным. Советую посмотреть доклады Павла Черторогова, он очень здорово качает тему GraphQL, и Apollo в частности. Если вы начинаете делать что-то с нуля, я бы посоветовал использовать только Apollo, он дает офигенный старт, и в принципе создает хорошую базу для приложения или клиент-сервера на Node.js или BFF.
URQL
https://formidable.com/open-source/urql/docs/
Теперь про URQL. В отличие от двух предыдущих — это библиотека, и нам она очень понравилась. Она позволяет гибко все настроить и оказывает не такое сильное влияние на архитектуру в самом приложении. А поскольку у нас React и Redux, достаточно старый стек и приложению больше пяти лет, нам требуется гибкое решение, чтобы пробовать разные гипотезы. URQL хорошо подходит для использования GraphQL на маленьких и больших проектах. Он максимально гибкий и при этом имеет такие же плюшки, как Apollo. Да, их не настолько много, но комьюнити активно развивается.
Ниже приведена таблица с указанием плюсов и минусов URQL по отношению к другим фреймворкам.
https://formidable.com/open-source/urql/docs/comparison/#comparison-by-features
All features are marked to indicate the following:
- ✅ Supported 1st-class and documented.
- ? Supported and documented, but requires custom user-code to implement.
- ? Supported, but as an unofficial 3rd-party library. (Provided it's commonly used)
- ? Not officially supported or documented.
Core Features
| urql | Apollo | Relay | |
|---|---|---|---|
| Extensible on a network level | ✅ Exchanges | ✅ Links | ✅ Network Layers |
| Extensible on a cache / control flow level | ✅ Exchanges | ? | ? |
| Base Bundle Size | 5.9kB (7.1kB with bindings) | 32.9kB | 27.7kB (34.1kB with bindings) |
| Devtools | ✅ | ✅ | ✅ |
| Subscriptions | ✅ | ✅ | ✅ |
| Client-side Rehydration | ✅ | ✅ | ✅ |
| Polled Queries | ? | ✅ | ✅ |
| Lazy Queries | ✅ | ✅ | ✅ |
| Stale while Revalidate / Cache and Network | ✅ | ✅ | ✅ |
| Focus Refetching | ✅ @urql/exchange-refocus |
? | ? |
| Stale Time Configuration | ✅ @urql/exchange-request-policy |
✅ | ? |
| Persisted Queries | ✅ @urql/exchange-persisted-fetch |
✅ apollo-link-persisted-queries |
✅ |
| Batched Queries | ? | ✅ apollo-link-batch-http |
? react-relay-network-layer |
| Live Queries | ? | ? | ✅ |
| Defer & Stream Directives | ✅ | ? | ? (unreleased) |
Switching to GET method |
✅ | ✅ | ? react-relay-network-layer |
| File Uploads | ✅ @urql/exchange-multipart-fetch |
? apollo-upload-client |
? |
| Retrying Failed Queries | ✅ @urql/exchange-retry |
✅ apollo-link-retry |
✅ DefaultNetworkLayer |
| Easy Authentication Flows | ✅ @urql/exchange-auth |
? (no docs for refresh-based authentication) | ? react-relay-network-layer |
| Automatic Refetch after Mutation | ✅ (with document cache) | ? | ✅ |
Итого: в результате ресерча мы поняли, что нам не подходит ни Relay, ни Apollo, ни URQL. Бэкенд сообщил, что ему необходимо сделать достаточно много изменений в бэке и архитектуре, и, если бы они начали это делать одновременно с нашим фронтендом, то мы бы просто заморозили разработку.
Нам было нужно очень гибкое решение где-то в сторонке, чтобы мы могли писать запросы GraphQL, не сильно вмешиваясь в архитектуру фронтенд приложения. Мы договорились решать всё на сетевом уровне: оставляем приложение как есть, делаем запросы и инжектим клиент в библиотеку для асинхронных экшенов. Но прежде чем это сделать, мы выдвинем некоторые требования, которые хотелось бы видеть от нашей разработки.
Требования
- GraphQL клиент
- CI/CD и pre-commit
- Playground
- Unit-тесты
- Стабы
- GraphQL схема
Делаем GraphQL клиент
Мы используем на проекте axios и к нему написано много интерцептеров, которые также должны работать и для graphql запросов.
Для работы graphql на проекте понадобятся пакеты graphql, graphql-tag
Выполняем
yarn add graphql
yarn add -D graphql-tag
// Функция print работает с ast, преобразовывая его в строку запроса import { print } from 'graphql/language/printer'; // Наша обертка над axios import { HttpClient, HttpClientError } from 'Modules/http/httpClient'; import { graphQLEndPoint } from 'Utils/domain'; const httpGraphqlClient = new HttpClient({ baseURL: graphQLEndPoint, }); const getHttpConfig = ({ query, variables, ...rest }, operationName) => ({ method: 'POST', data: { // в query попадает ast, которое подготовлено лоадером вебпак graphql-tag/loader // утилитой print из graphql ast преобразуем query в строку query: print(query), variables, // данные для мониторинга operationName, }, params: { // дополнительно к запросу запишем параметр operationName, чтобы в логах видеть конкретную операцию graphqlEndpoint?operationName=xxx operationName, }, ...rest, }); const extractOperationName = (query) => { const { definitions } = query; const [def] = definitions; const { name: { value }, } = def; return value; }; const checkOperationType = (query, operationType) => { const { definitions } = query; const [def] = definitions; const { operation } = def; return operation === operationType; }; const request = async (config) => { const { query, operationType } = config; const operationName = extractOperationName(query); if (!checkOperationType(query, operationType)) { throw new HttpClientError('fetcherGraphQL request invalid operation'); } const { data } = await httpGraphqlClient.request(getHttpConfig(config, operationName)); return data; }; // Example async function fn() { const { data } = await request({ query: GraphQlQueryFile }) return data; }
Наша библиотека для асинхронных экшенов
Поговорим о нашей асинхронной библиотеке, чтобы вы понимали, как у нас работает код, и в чем фишка внедрения GraphQL на уровне сети. Для асинхронных операций у нас есть middleware. Называется она signal-middleware и находится в этом репозитории. Signal-middleware достаточно простая: у нас есть некоторый сигнал, мы на этот сигнал подписываемся по ключу и выполняем тот или иной action. Сюда мы можем заинжектить любые нужные нам функции. В данном случае сюда инжектится базово dispatch и, например, store.
Получили по ключику нашу функцию callback, исполнили, сделали запрос, записали ответ, и если что-то не так — обработали. В нашем случае библиотека доработана. Мы дополнительно провайдим наши клиенты для http-запросов. Добавив префикс :gql: в наименование сигнала, мы понимаем, какой http-клиент нужно заинжектить.
import { addReaction } from 'signal-middleware'; // http клиенты import fetcher from 'Utils/fetcher/fetcher'; import fetcherGraphQL from 'Utils/fetcher/fetcherGraphQL'; // addReaction.js export default (signalName, cancelType, signalReaction) => { let [cancelName, reactionHandler] = [cancelType, signalReaction]; const processFetcher = signalName.includes(':gql:') ? fetcherGraphQL : fetcher; if (typeof cancelName === 'function') { cancelName = null; reactionHandler = cancelType; } const reaction = (storeUtils, ...args) => reactionHandler( { ...storeUtils, fetcher: cancelName === null ? processFetcher : processFetcher.uniq(cancelName), }, ...args ); addReaction(signalName, reaction); }; // signal.js addReaction(`:gql:signal`, async ({ fetcher }) => { const data = await fetcher.query(GraphQLQueryFile); //.... })
Проверки на CI/CD и pre-commit
Проверки на этапах CI/CD и pre-commit нужны в ситуации, если мы как-то ошибемся и наша схема не сойдется с бэкендом. Или что-то может пойти не так: мы передадим не тот аргумент, обратимся к полю, которого не существует или опечатаемся.
Настраиваем конфигурацию graphql на проекте, используя graphql-config
# .graphqlrc # Путь до схемы schema: "./.codegen/schema.graphql" # Путь до операций и фрагментов documents: "./app/**/**/*.graphql"
Далее подключаем плагин для eslint @graphql-eslint/eslint-plugin
Настраиваем конфигурацию:
// .eslintrc { "files": "*.graphql", "extends": "plugin:@graphql-eslint/operations-recommended", "plugins": ["@graphql-eslint"], "rules": { "prettier/prettier": [2, { "parser": "graphql" }], "spaced-comment": "off", "@graphql-eslint/executable-definitions": "error", "@graphql-eslint/fields-on-correct-type": "error", "@graphql-eslint/fragments-on-composite-type": "error", "@graphql-eslint/known-argument-names": "error", "@graphql-eslint/known-directives": "error", "@graphql-eslint/known-type-names": "error", "@graphql-eslint/no-anonymous-operations": "error", "@graphql-eslint/no-deprecated": "error", "@graphql-eslint/no-unused-variables": "error", "@graphql-eslint/provided-required-arguments": "error", "@graphql-eslint/scalar-leafs": "error", "@graphql-eslint/unique-argument-names": "error", "@graphql-eslint/unique-input-field-names": "error", "@graphql-eslint/unique-variable-names": "error", "@graphql-eslint/value-literals-of-correct-type": "error", "@graphql-eslint/variables-are-input-types": "error", "@graphql-eslint/variables-in-allowed-position": "error", "@graphql-eslint/require-id-when-available": "off", // Ограничиваем глубину запроса "@graphql-eslint/selection-set-depth": ["error", { "maxDepth": 20}], // Правила нейминга для операции и фрагментов "@graphql-eslint/naming-convention": [ "error", { "VariableDefinition": "camelCase", "OperationDefinition": { "style": "PascalCase", "forbiddenPrefixes": ["Query", "Mutation", "Subscription", "Get"], "forbiddenSuffixes": ["Query", "Mutation", "Subscription"] }, "FragmentDefinition": { "style": "camelCase", "forbiddenPrefixes": ["Fragment"], "forbiddenSuffixes": ["Fragment"] } } ], // Метчинг нейминга для файлов "@graphql-eslint/match-document-filename": [ "error", { "fileExtension": ".graphql", "query": { "style": "camelCase", "suffix": ".query" }, "mutation": { "style": "camelCase", "suffix": ".mutation" }, "fragment": { "style": "camelCase", "suffix": ".fragment" } } ] } }
Напишем запрос:
query Person($id: Int!) { person(id: $id) { ... on PersonItem { area { someField } } } }
Делаем наш обычный git-add и выполним команду lint-staged, который у нас запускает линтинг. Команда запустилась, но линтинг сообщает, что мы не можем это зафиксить: someField нет на типе Area.
5:9 error Cannot query field "someField" on type "Area" @graphql-eslint/fields-on-correct-type ✖ 1 problem (1 error, 0 warnings)
Как результат, ошибку отловим на pre-commit или на этапе CI/CD.
Playground
В качестве плейграунда мы выбрали песочницу GraphiQL. Существует еще ряд графических редакторов для GraphQL, но этот понравился нам больше всего. Находится плейграунд в этом репозитории, он достаточно простой, кастомизированный, и нам этого достаточно.
Мы решили подключать его как cdn. У нас есть сборка, которую мы перекладываем в папочку build, подготовленные файлы — graphiql.min.jsи graphiql.min.css. И подключаем в html.
Заходим в плейграунд и выполняем простой запрос, который будет выглядеть так: выберем всех кандидатов, которые есть в базе.

Запрос выполнен — получили ожидаемый результат (плейграунд с готовой документацией и хорошей интроспекцией). А написанный запрос точно так же переносится в код.
Unit-тесты
Для нашего GraphQL клиента написали небольшую функцию, с помощью которой можно замокать данные. Под капотом мы используем Nock, библиотеку для мок сети, к ней написали маленькую обертку.
Пример запроса:
query PersonExample { person { name } } // ... const result = await request(PersonExample); // Имя запроса будет подставлено параметром // http://localhost/graphql?operationName=PersonExample //...
Напишем функцию, которая будет перехватывать все запросы по параметру operationName.
import nock from 'nock'; import { graphQLEndPoint } from 'Utils/domain'; const [endPointUrl] = graphQLEndPoint.split('/graphql'); /** * Мок функция для удобной работы с сетевыми http-запросами graphql * * @param {string} requestName имя query или mutation для сопоставления запроса * @prop {object={}} params * @prop {boolean} [params.persist] сохранять все перехватчики */ export const createMockFetcherGraphQL = (requestName, { persist = false } = {}) => { const scope = persist ? nock(endPointUrl).persist() : nock(endPointUrl); // const request = scope.post(`/graphql?operationName=${requestName}`); return { /** * Прокси метод над nock.reply * * @see https://github.com/nock/nock#specifying-replies * @see https://github.com/nock/nock/blob/main/types/index.d.ts#L165-L184 * @param {number} statusCode * @param {object|function} [reply={}] для удобства используем как body или callback для доступа к req * @returns */ reply(statusCode, reply) { return request.reply(statusCode, reply); }, }; }; /** * Сброс моков */ export const clearMocksFetcherGraphQL = () => { nock.cleanAll(); nock.restore(); };
Теперь любой запрос на проекте можем перехватить c помощью createMockFetcherGraphQL('operationName') и подменить тело ответа.
Для наглядности рассмотрим пример, в котором хотим проверить, правильно ли прокидываются наши variables.

Подготавливаем сет данных expectVariables и expectResponse, в которых мы заинтересованы. Вызываем функцию, она должна сработать, когда у нас будет FetcherGraphQLGetTest.
Делаем запрос, сравниваем, подходят ли перехваченные variables, которые у нас есть в запросе.
Проверка прошла успешно. Именно таким образом мы можем мокать данные в unit-тестах.
Стабы
В нашем стандартном клиенте есть механизм стабов, поэтому хотелось бы видеть его и в GraphQL. Тут достаточно простая реализация: у нас есть некоторый запрос, мы смотрим на фиче-флаг — если он включен, отдаем стабы по operationName.
async function request(config) { //.. try { if (featureEnabled(FEATURE_STUB)) { const result = await stubs(`graphql/${operationName}`, 'POST'); try { if (result) { // result это объект new Response(стаб); const { data } = await result(); return data; } } catch (err) { return Promise.reject(err.response.data); } } } catch (ignore) {} //... }
Подготавливаем json файлы, которые будут подменять тело ответа при вызове stubs(graphql/operationName);
// Делаем проверку на окружение, чтобы стабы не попали в продакшн сборку if (process.env.NODE_ENV === 'development') { // eslint-disable-next-line import/no-dynamic-require const requireHelper = (file) => require(`App/stubs/json/${file}.json`); hardcodedItems = [ { regexp: 'example', action: createResponse(bindReceiver(requireHelper('get-example')), 200), method: 'GET', delay: 0, }, { regexp: 'graphql/PersonsList', method: 'POST', action: createResponse(bindReceiver(requireHelper('persons.query')), 200), delay: 0, }, ]; }
У нас есть подготовленный стаб для операции PersonsList.
Есть страничка “persons”. На скриншоте видно, что данные получаем из запроса graphql?operationName=PersonsList
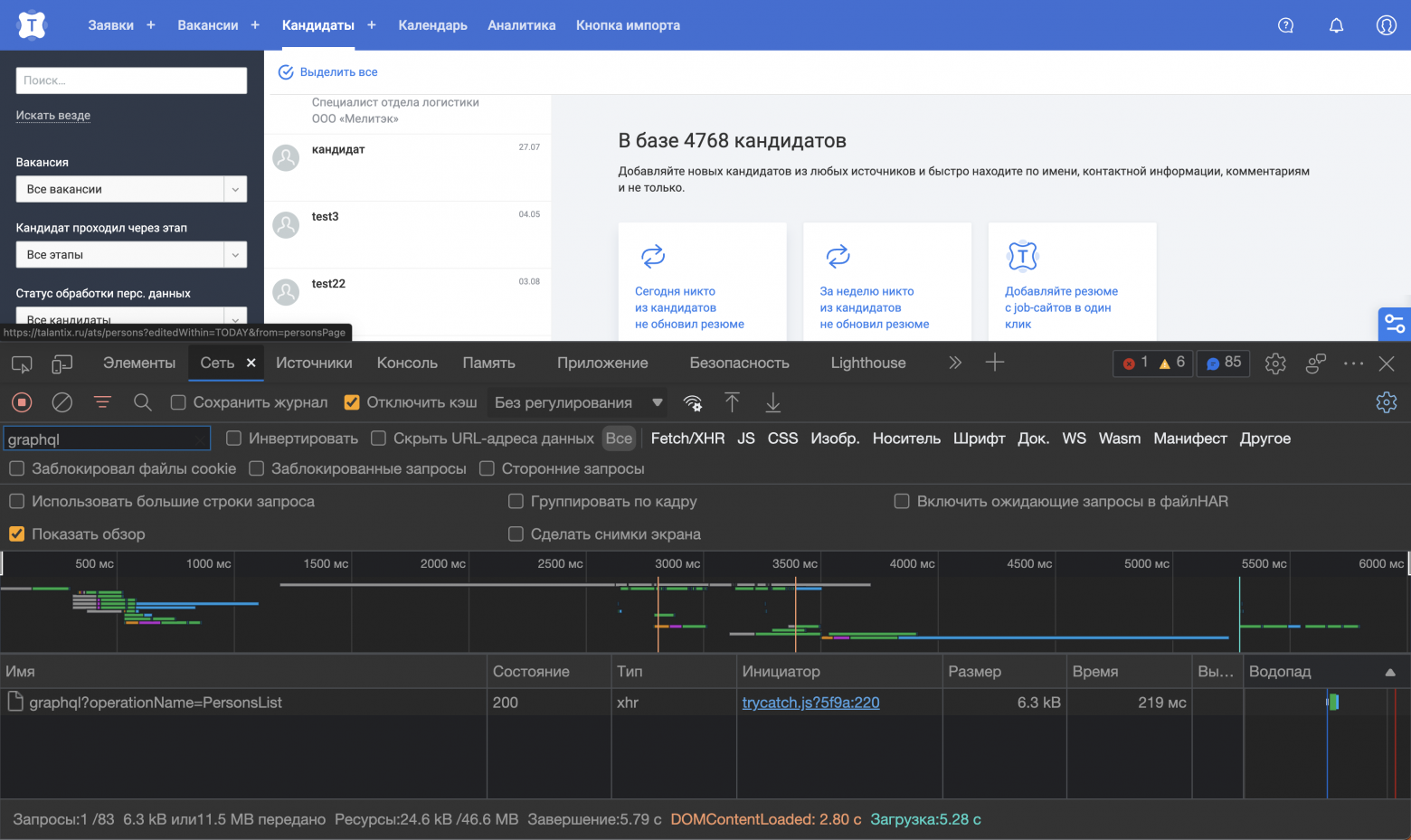
Включаем стаб и для наглядности что-нибудь поменяем. Выполним достаточно простой пример: сделаем всем кандидатам зарплату, например, 100500.

Такой механизм стабов помогает разрабатывать в отрыве от бэкенда, готовить компоненты к данным или пробовать на фронтенде сложную логику.
Более подробно об этой фиче рассказывает Никита Мостовой в докладе "Стабы для фронтенда".
Получение GraphQL схемы
Для этого написали простой скрипт, который делает запрос к graphql серверу и преобразовывает ответ в готовый SDL graphql.
const { getIntrospectionQuery, buildClientSchema, printSchema } = require('graphql/utilities'); async function fetchSchema() { try { // eslint-disable-next-line no-console console.log('fetchSchema', 'start', GRAPHQL_END_POINT_SCHEMA); const { data: { data: introspection }, } = await axios({ url: GRAPHQL_END_POINT_SCHEMA, method: 'POST', headers: { Accept: 'application/json', 'Content-Type': 'application/json', }, data: JSON.stringify({ query: getIntrospectionQuery(), operationName: 'IntrospectionQuery' }), }); // eslint-disable-next-line no-console console.log('fetchSchema', 'ok'); return buildClientSchema(introspection); } catch (e) { console.error(`fetchSchema ${e.message}`); } } //...
Полученную схему складываем в папку codegen.
По такому принципу мы и работаем с бэкендом. А если говорить о подходе сode-first, то мы просто переключаемся на стенды, где раскатана бэк-ветка с новой схемой, и оттуда забираем схему.
Поскольку наш проект живет в одном репозитории, бэкенды сами умеют подкладывать файлы на билде в нужную нам папку без какого-либо сетевого запроса.
Боевая задача
Самое время попробовать нашу новую игрушку на боевой задаче. Задача состоит из страницы кандидата: там у нас есть и фильтрация, и пагинация, и получение всех персон. Попробуем сделать это сначала в плейграунде, а потом и в коде.
У нас есть список с пагинацией, в левом сайдбаре живут фильтры, с помощью которых можно отсортировать кандидатов по возрасту, вакансии или зарплате.
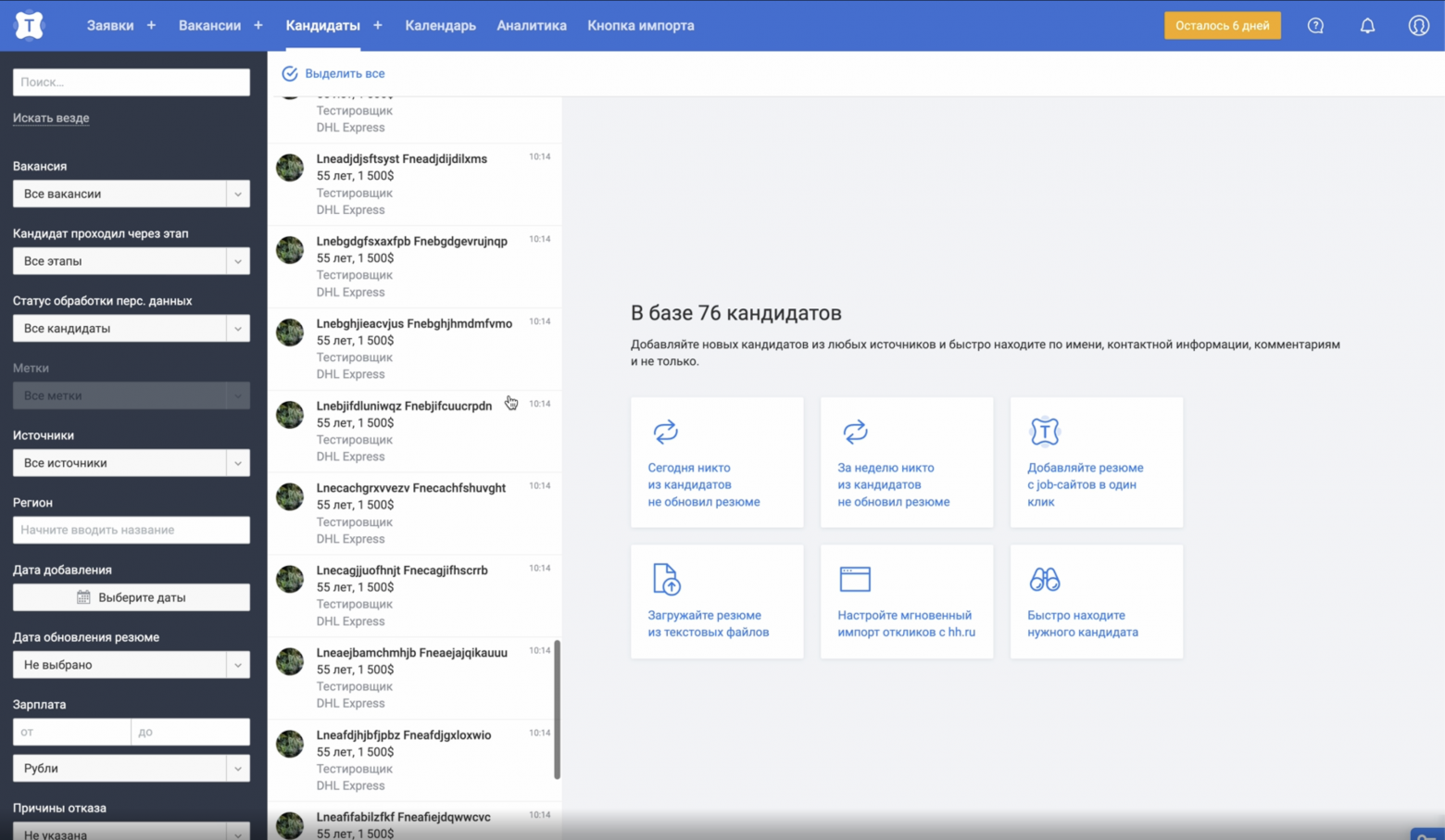
Попробуем перенести все это на GraphQL и сделаем запрос в GraphQL Playground.
Пробуем в Playground
Пишем наш первый запрос, назовем его PersonsList. Начинаться он будет с ключевого слова query. Нам подсказывают, что у нас есть persons — то что нужно, здесь у нас будут кандидаты. Появился резолвер, у него есть три аргумента, но нам пока интересен только аргумент first. Он определяет, сколько элементов нам нужно выдать для рендера. Для наглядности возьмем три кандидата.
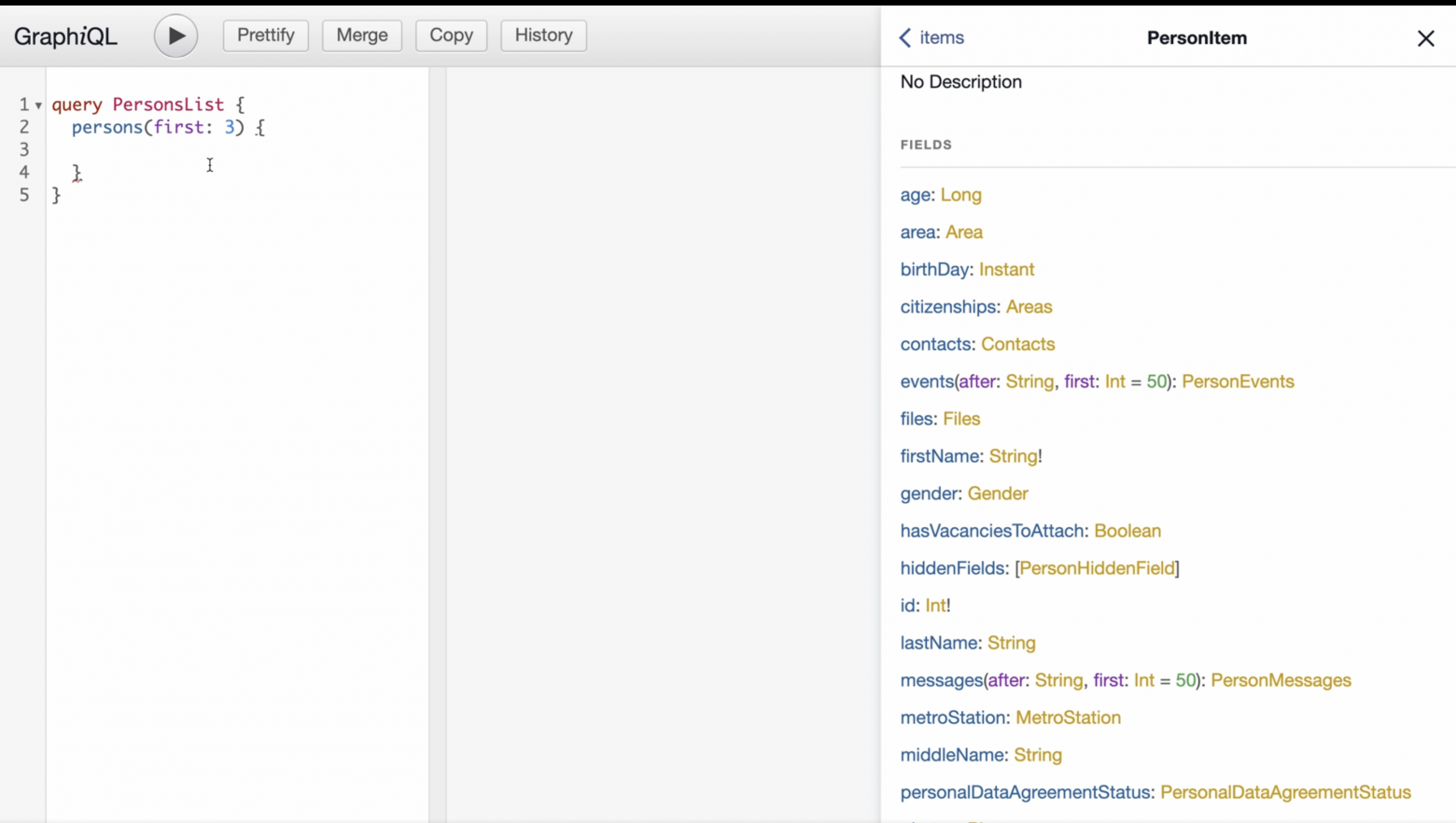
Посмотрим, что у нас внутри person: фильтры, pageinfo и items. Из айтемов нам нужны: firstName, lastName, age и id. Запишем в запрос:

Справа на скриншоте — тело ответа.
Окей, persons получили. Теперь попробуем сделать пагинацию. Проваливаемся в документацию и выбираем pageInfo:

Здесь видим такой флажочек — есть ли у нас следующий список кандидатов и endCursor, после которого нам надо будет выдать следующую пачку. Попробуем воспользоваться этим резолвером и посмотрим, что у него внутри:

Видим, что у нас действительно есть следующая пачка кандидатов и есть курсор, после которого нам выдадут следующую партию. Проще говоря, это указатель, после которого необходимо начинать работать над следующим списком.
Еще здесь есть аргумент after, в который мы вставим то, что скопировали из endCursor:

Запрос выполнился, появилась следующая пачка кандидатов. Пагинация работает как надо.
Следующая задача — сделать фильтры из сайдбара, который я демонстрировал выше. В рамках нашей тестовой задачи будем фильтровать кандидатов по возрасту. Для начала нам нужно понять, какие состояния у фильтров. Пишем filters и смотрим, что GraphQL предлагает нам по PersonsFilters:
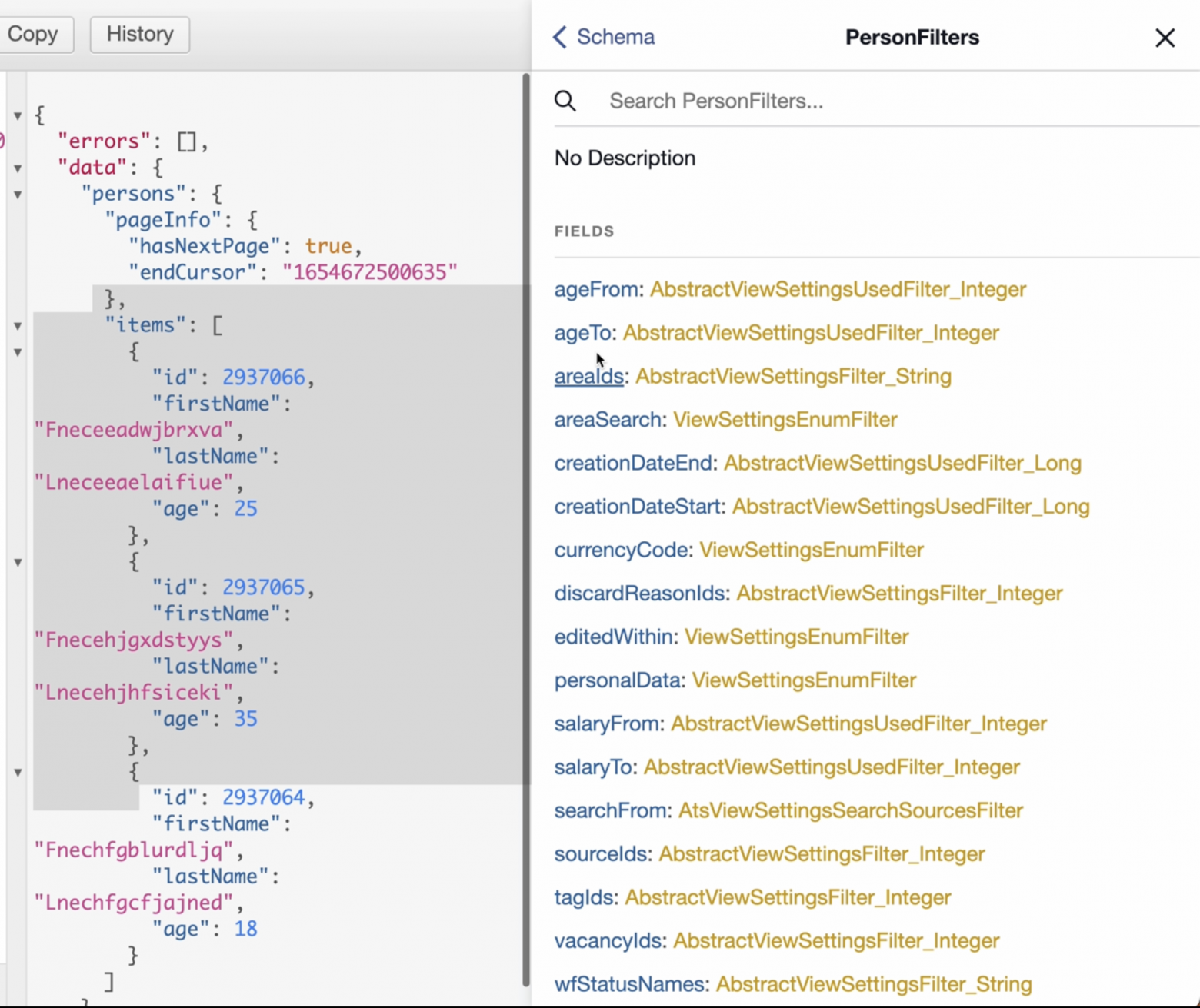
Очень удобно, что можно провалиться прямо на ходу — интроспекция отличная. Можно посмотреть информацию о каждом поле. У нас есть ageFrom и поле used, которое говорит, какой возраст используется в данный момент.
Напишем, что наш query принимает аргументы и попробуем их передать. Начнем с $cursor, потому что мы уже его проработали. Обозначим, что это поле string. В after тоже будет приходить $cursor. Теперь попробуем его прокинуть.

Запрос выполнился, пришли те же самые кандидаты. А, значит, все работает. Теперь попробуем с фильтром. Впишем его в query, назовем $filterInput: PersonFilterInput. Передадим его в persons и выполним запрос.
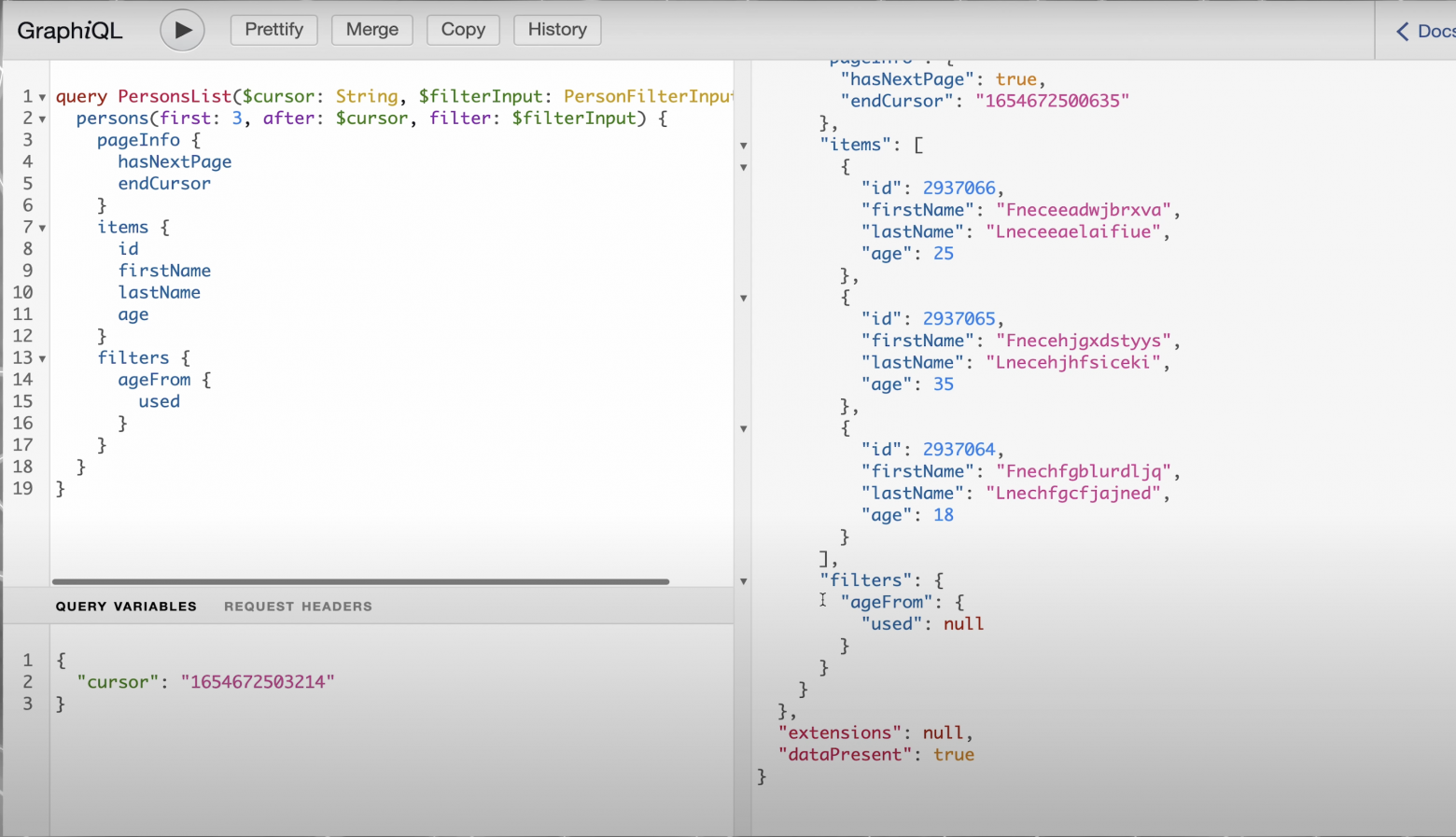
Запрос прошел, но used пустой. Выходит, нужно прокинуть параметры для фильтра. Пишем ageFrom и фильтруем кандидатов от 25 лет. Запускаем.

Огонь! Отфильтровали новых кандидатов — все, кому меньше 25 лет, полностью исключены из выборки. Также в поле used появился флажок с активным фильтром. Итого: у нас получилось организовать фильтрацию и пагинацию — всё, что требовалось для выполнения задачи.
Пробуем в коде
Открываем наш асинхронный код, отвечающий за загрузку персон. Здесь у нас есть реакция, ключевой сигнал и тот же самый запрос, который делаем при страничном get. Мы что-то спрашиваем, обновляем и выполняем запрос:

Как это будет выглядеть в GraphQL? Да практически так же. У нас точно такой же сигнал и обработка. Единственное отличие — префикс, который позволяет прокидывать по другому префиксу правильный клиент для запроса. В нашем случае он называется fetcher:

Всё то же самое: делаем запрос, подготавливаем данные. Они немного отличаются по телу функции, потому что нам приходится мириться с тем, что нам нужно мапить данные под другие резолверы и экшены. Несущественный минус, поскольку всё это достаточно легко обработать.
Передаем в запрос PesonaListQuery и variables, которые мы прокидывали еще в playground.
Вот и вся наша реализация. Мы приложили минимум усилий, чтобы сделать GraphQL-запрос. У нас просто появился флажок, который спрашивает, что использовать для загрузки списка персон: GraphQL или старый страничный url. А сам запрос состоит из тех же самых полей.
Вместо заключения
У GraphQL есть свои преимущества и недостатки. Преимущества: бэкенд и фронтенд работают по строго типизированной схеме, документированный API из коробки и большое комьюнити. Недостатком является отсутствие в GraphQL классического подхода обработки ошибок (как с HTTP-кодами: мониторинг, подсчет SLA, откаты релизов при “пятисотках").
Итак, у нас получилось бесшовно внедрить GraphQL и получить плюшки фреймворков, не переломав всё на своем пути, а также предусмотреть последующую интеграцию во фреймворк или библиотеку.

