JVM основная платформа для Big Data решений, таких как Hadoop, Spark, Presto, NiFi но на производительность значительно влияют копирование/сериализация данных "на каждый чих" с последующей сборкой мусора и отсутствие SIMD оптимизаций при работе с данными.
А можно ли в программе на JVM прочитать сотни гигабайт Parquet файлов без Spark/Hadoop? В этом нам поможет библиотека Apache Arrow - проект, которым объединяются десятки решений для работы с Большими Данными. Но для этого даже не обязателен кластер с тысячами ядер и петабайты хранилища! Обработку данных начнем с "золотого стандарта" для open source: PostgreSQL 14 + PostGIS 3.2.0, а продолжим на OpenJDK 11 + Apache Arrow 9.0.0.
В качестве примера измерим с неизвестной точностью "среднюю температуру по больнице" - мы посчитаем число школьных зданий по всему миру в проекте OpenStreetMap. И когда говорят что образование избыточно и в школе дают много лишних знаний, то сразу же хочется задать компьютеру этот вопрос, сверив его с географией.
Итак, исходные данные для примера - OpenStreetMap planet-220704.osm.pbf Как их преобразовать в parquet файлы здесь рассматривать не буду, могу лишь порекомендовать OpenStreetMap Parquetizer как один из вариантов.
Начнем с классического решения для обработки - в PostGIS мы посчитаем что по всему миру 1005636 зданий помеченных как школа.
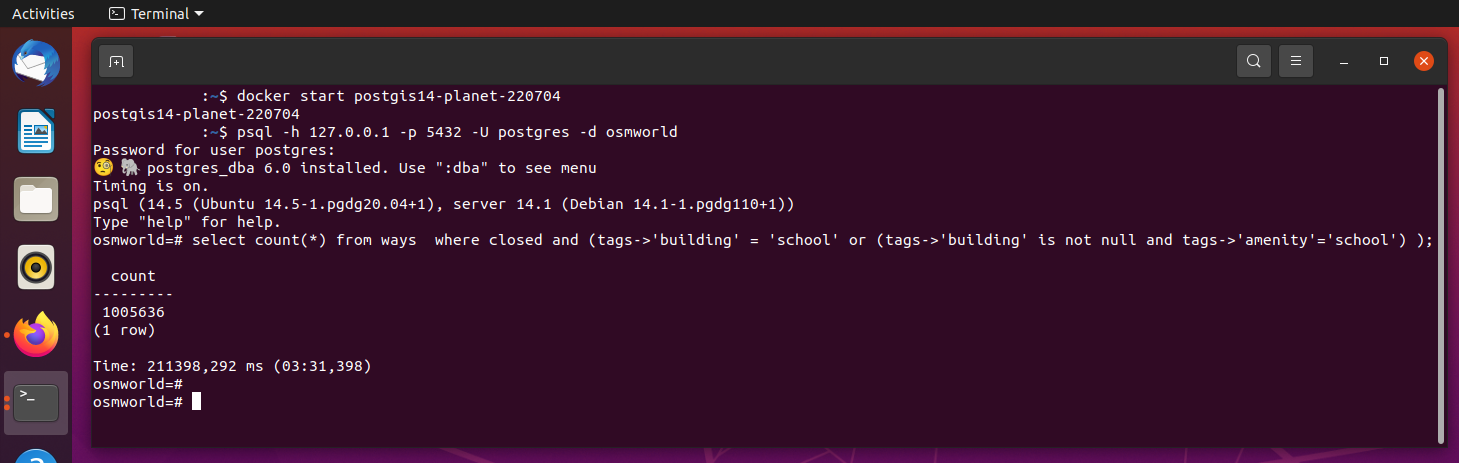
Данные планеты возьмем из PostGIS в схеме совместимой с pgsnapshot, с установленным расширением h3-pg . База данных занимает 588 GB и запущена в докер контейнере на ноутбуке с 16Гб ОЗУ и M.2 накопителем Samsung 970 EVO Plus:

Для картинки с КДПВ данные были подготовлены запросом и для желающих повторить визуализацию, я сохранил данные вместе с полигонами границ в gist:
create table school as select h3_3, count(*) as "count" from ways where closed and (tags->'building' = 'school' or (tags->'building' is not null and tags->'amenity'='school')) group by h3_3 order by 2 desc
Разбивка данных на регионы для агрегации производилась в иерархической системе H3 на уровне разбивки 3. И визуализированы в QGIS только те регионы в которых больше 100 зданий школ на регион. Приблизительая площадь региона 12393км2
select h3_to_geo_boundary_geometry(h3_3::h3index), count from school where count>100


Насколько полны данные по школам в OpenStreetMap - большой вопрос. Обычно данные более актуальны в городах-миллионниках. OpenStreetMap работает на тех же принципах что и википедия, так что в случае неточностей все вопросы к сообществу.
А теперь решение по подсчету количества школ во всем мире на Apache Arrow. Добавляем зависимости в maven
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.github.igor-suhorukov</groupId> <artifactId>osm_parquet_dataset_example</artifactId> <version>1.0-SNAPSHOT</version> <properties> <maven.compiler.source>8</maven.compiler.source> <maven.compiler.target>8</maven.compiler.target> <arrow.version>9.0.0</arrow.version> </properties> <dependencies> <dependency> <groupId>org.apache.arrow</groupId> <artifactId>arrow-dataset</artifactId> <version>${arrow.version}</version> </dependency> <dependency> <groupId>org.apache.arrow</groupId> <artifactId>arrow-memory-unsafe</artifactId> <version>${arrow.version}</version> </dependency> </dependencies> </project>
И считаем школы по миру:
package com.github.igorsuhorukov.arrow.osm.example; import org.apache.arrow.dataset.file.FileFormat; import org.apache.arrow.dataset.file.FileSystemDatasetFactory; import org.apache.arrow.dataset.jni.NativeMemoryPool; import org.apache.arrow.dataset.scanner.ScanOptions; import org.apache.arrow.dataset.scanner.Scanner; import org.apache.arrow.dataset.source.Dataset; import org.apache.arrow.memory.BufferAllocator; import org.apache.arrow.memory.RootAllocator; import org.apache.arrow.util.AutoCloseables; import org.apache.arrow.vector.BitVector; import org.apache.arrow.vector.VectorSchemaRoot; import org.apache.arrow.vector.complex.MapVector; import org.apache.arrow.vector.complex.impl.UnionMapReader; import org.apache.arrow.vector.ipc.ArrowReader; import org.apache.arrow.vector.util.Text; import java.io.File; import java.util.concurrent.atomic.AtomicLong; import java.util.stream.StreamSupport; public class CalculateSchoolCount { public static final int BATCH_SIZE = 100000; public static final Text BUILDING_KEY = new Text("building"); public static final Text SCHOOL_VALUE = new Text("school"); public static final Text AMENITY_KEY = new Text("amenity"); public static void main(String[] args) throws Exception{ if(args.length!=1){ throw new IllegalArgumentException("Specify source dataset path for parquet files"); } File datasetPath = new File(args[0]); if(!datasetPath.exists()){ throw new IllegalArgumentException(); } long startTime = System.currentTimeMillis(); try (BufferAllocator allocator = new RootAllocator()) { FileSystemDatasetFactory factory = new FileSystemDatasetFactory(allocator, NativeMemoryPool.getDefault(), FileFormat.PARQUET, datasetPath.toURI().toURL().toExternalForm()); final Dataset dataset = factory.finish(); ScanOptions options = new ScanOptions(BATCH_SIZE); final Scanner scanner = dataset.newScan(options); try { AtomicLong totalSchoolCnt = new AtomicLong(); StreamSupport.stream(scanner.scan().spliterator(), true).forEach(scanTask -> { long schoolCnt=0; try (ArrowReader reader = scanTask.execute()) { while (reader.loadNextBatch()) { VectorSchemaRoot root = reader.getVectorSchemaRoot(); BitVector closed = (BitVector) root.getVector("closed"); MapVector tags = (MapVector) root.getVector("tags"); UnionMapReader tagsReader = tags.getReader(); for(int row=0, size = root.getRowCount(); row < size; row++){ if(closed.get(row) != 0){ tagsReader.setPosition(row); boolean building=false; boolean buildingSchool=false; boolean amenitySchool=false; while (tagsReader.next()){ Text key = (Text) tagsReader.key().readObject(); Text value = (Text) tagsReader.value().readObject(); if(key!=null && key.equals(BUILDING_KEY)){ if(value!=null && value.equals(SCHOOL_VALUE)){ buildingSchool = true; break; } building=true; if(amenitySchool){ break; } } if(key!=null && value!=null && key.equals(AMENITY_KEY) && value.equals(SCHOOL_VALUE)){ amenitySchool = true; if(building){ break; } } } if(buildingSchool || (building && amenitySchool)){ schoolCnt++; } } } tags.close(); closed.close(); root.close(); } totalSchoolCnt.addAndGet(schoolCnt); } catch (Exception e) { throw new RuntimeException(e); } finally { AutoCloseables.closeNoChecked(scanTask); } }); long executionTime = System.currentTimeMillis() - startTime; System.out.println(totalSchoolCnt.get()+" ("+executionTime+" ms)"); } finally { AutoCloseables.close(scanner, dataset); } } } }
Результат запуска этой программы: 1005636 (806575 ms)

Итак, решение далеко от идеального как минимум по лишним аллокациям объектов и отсутствующим фичам в java Dataset API: не хватает чтения только требуемых для расчета колонок, filters push-down. Но и идея была показать что обработать 188,2Гб сжатых zstd Parquet файлов можно в java без Hadoop/Spark!

Dataset API в Java еще далек от функционала Python, так что для желающих помочь проекту с 10К звездочками на Github тут полный простор для действий! Из пока отсутствующих полезных фич - работа со схемами партиционирования данных Hive/directory/file name style. Еще ждет слияния мой PR на поддержку Apache ORC формата в java Dataset API.
Apache Arrow пытается быть общим форматом данных в ОЗУ для работы с колоночными данными в программах на разных языках программирования, также проект включает в себя JIT движок выражений Gandiva и Dataset API как универсальный способ читать и обрабатывать данные различных схем партиционирования в Parquet,ORC,Arrow IPC, csv из файловой системы или объектного хранилища по S3 API. Общий формат значит, что можно использовать разделяемую память, чтобы передавать данные без конвертации между разными языками программирования, использовать memory mapped файлы для работы с Arrow IPC файлами и RDMA для обмена данными через сеть. Все эти особенности можно рассматривать как основу СУБД следующих поколений и как улучшение текущих проектов, например Spark с помощью Intel OAP(ввели dataset API data source и векторизацию обработки для Spark SQL). Apache Arrow является основой для GPGPU Rapids от NVidia.
Для интерсующихся как читать данные в Arrow Dataset API можете посмотреть мою реализацию arrow_to_database загрузчика Apache Parquet и Arrow IPC файлов в базу данных через JDBC ну и конечно же документацию Apache Arrow.
Если тема работы с Apache Arrow или геоданными интересна, пишите про что хотели бы чтобы я рассказал в следующей статье. Добро пожаловать в комментарии к посту!
Мое резюме по географии школ надо еще проверить, есть предположения с какими объектами есть отрицательная корреляция. Если упростить систему образования и еще и разработчикам перестать развиваться/актуализировать свои знания, как призывают в последние дни на Хабре, то IMHO все скатится туда же как и у Пневмослона в песне "Многое можно..."

