К старту нашего флагманского курса по Data Science делимся расшифровкой видео от Себастьяна Лагу — разработчика игр, тьютора и популяризатора IT, который на своём
Начнём
Всем привет, я хочу попробовать научить свой компьютер распознавать разные каракули и просто картинки. Решить эту задачу можно разными способами, но сегодня меня интересуют нейросети.
Впервые это загадочное слово я услышал около 10 лет назад и вскоре попытался с помощью нейросети сделать так, чтобы маленькие существа из палочек ходили сами по себе. Мой код для обработки физики, видимо, был немного глючным, потому что это был мой самый успешный результат:
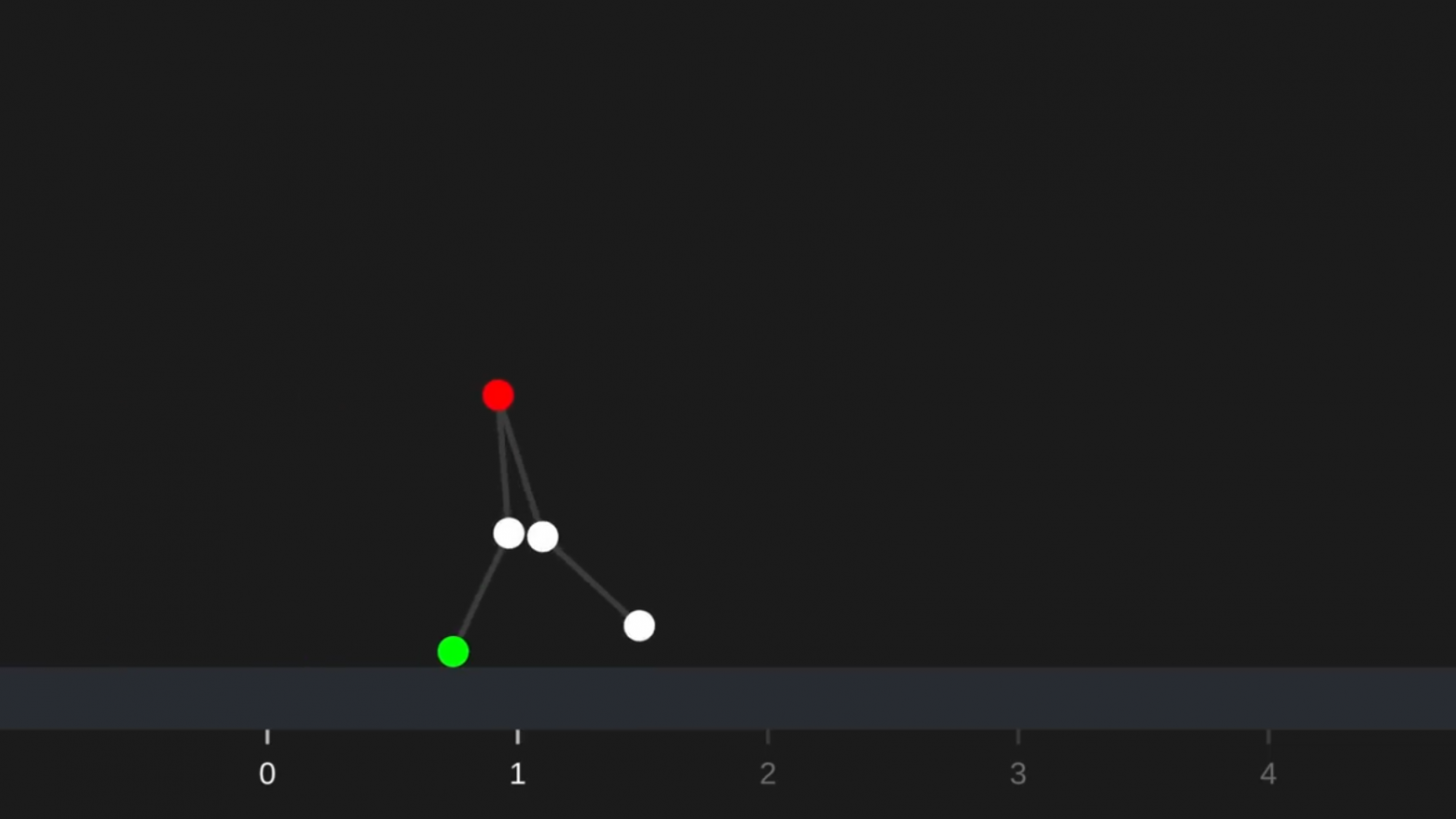
Не считая случаев, когда существо падало, а затем

В качестве второго эксперимента я решил попробовать
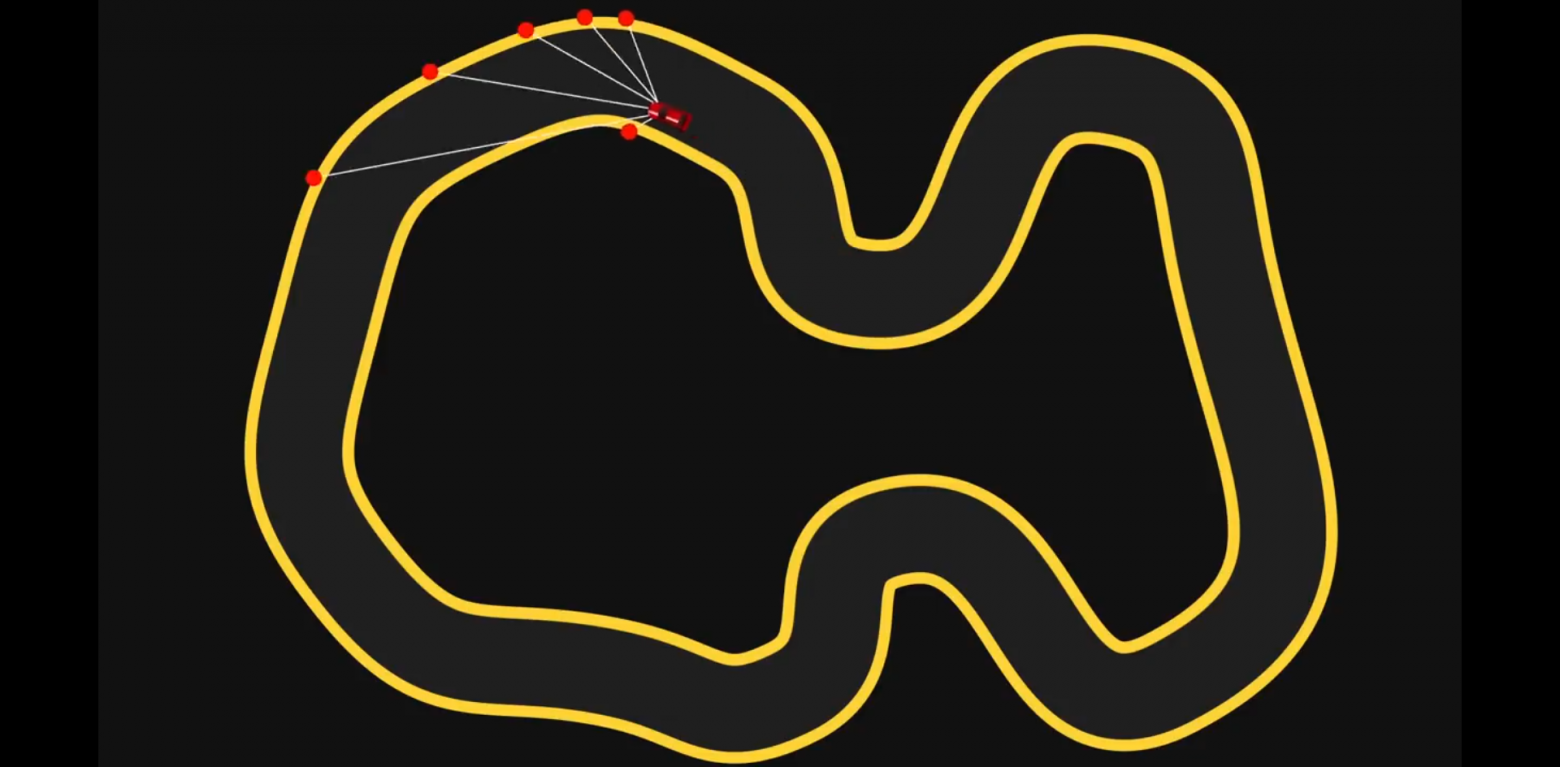
Конечно, поначалу это выглядит совершенно безнадёжно. Но, если мы позволим им конкурировать, а затем возьмём несколько лучших, клонируем несколько раз со случайными мутациями в их сетях, а затем позволим конкурировать уже им, и так далее, в итоге мы получаем автомобиль, который вполне успешно может ездить самостоятельно.
Последнее, что я пытался сделать пару лет назад, — обучить сети распознаванию цифр, написанных от руки. Как только мы создадим нашу маленькую нейронную сеть, это будет первой задачей, на которой мы её проверим:

После этого посмотрим, можно ли научить тот же код распознавать эти крошечные изображения предметов одежды и аксессуаров:

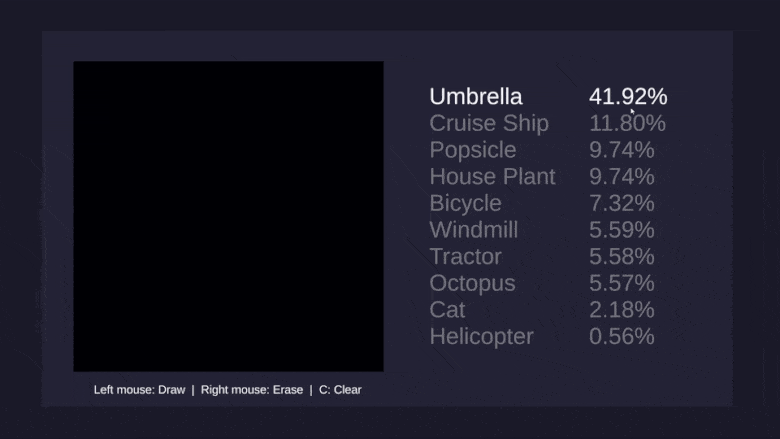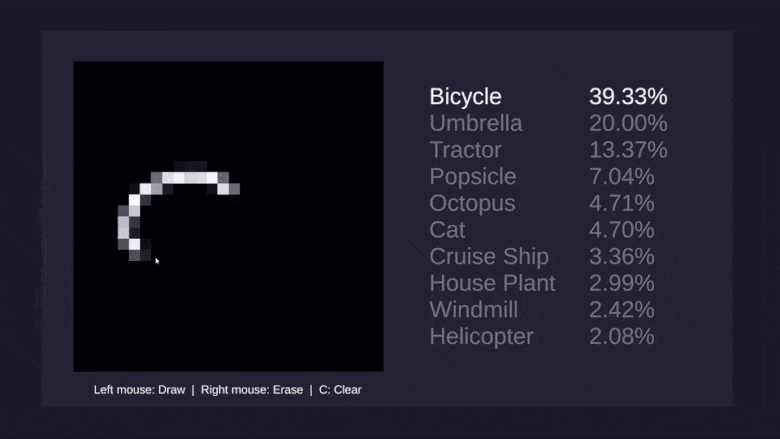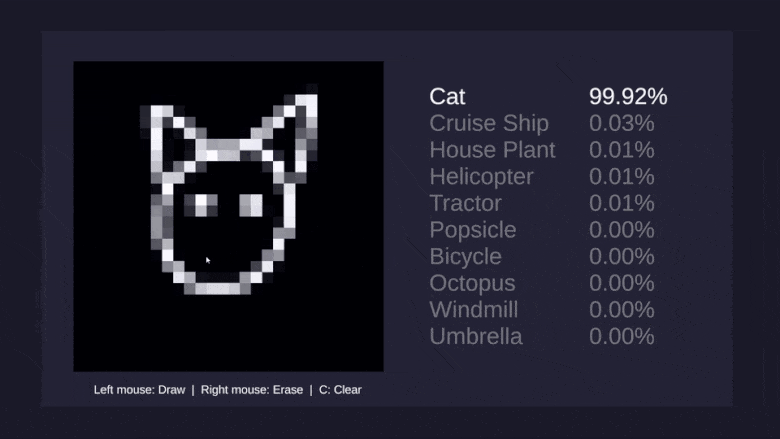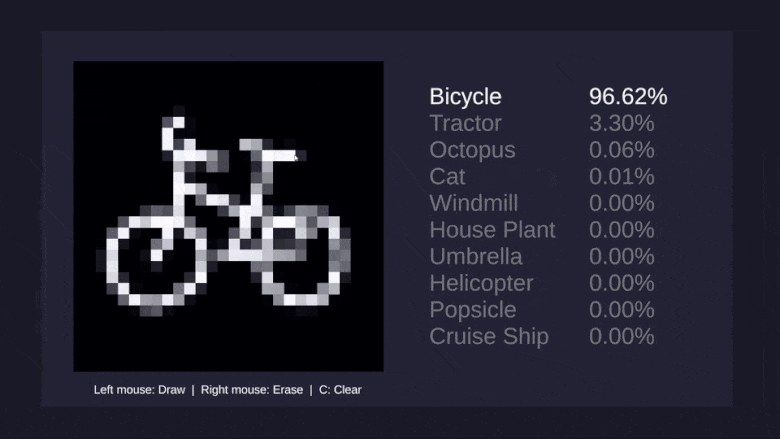
И, наконец, хотелось бы научить сеть распознавать рисунки десяти самых разных предметов: вертолётов, зонтиков, осьминогов и ветряных мельниц:

На самом деле, мы могли бы попробовать ещё

Но это значительный скачок в сложности. Поэтому, если для нашей простой сети это окажется слишком сложным, впоследствии нам придётся обновить её до
Границы принятия решений
Чтобы понять, как мы собираемся построить нашу нейронную сеть, давайте представим простой пример. Мы нашли необычный новый фрукт, пурпурный, колючий, с оранжевыми пятнами, очень вкусный:

Как ни странно, некоторые из этих фруктов оказались ядовитыми и вызывают ужасную боль в животе. Итак, давайте рассмотрим эти вымышленные фрукты. Мы увидим, что их внешний вид различается по двум основным параметрам: размер пятен и длина шипов:

Можно попробовать нарисовать график с размером пятен на одной оси и длиной шипов на другой. Затем мы могли бы собрать много разных фруктов и нанести их все на график на основе этих атрибутов.
Храбрые добровольцы согласились пробовать эти фрукты, так мы смогли промаркировать, какие из них безопасны, а какие нет:
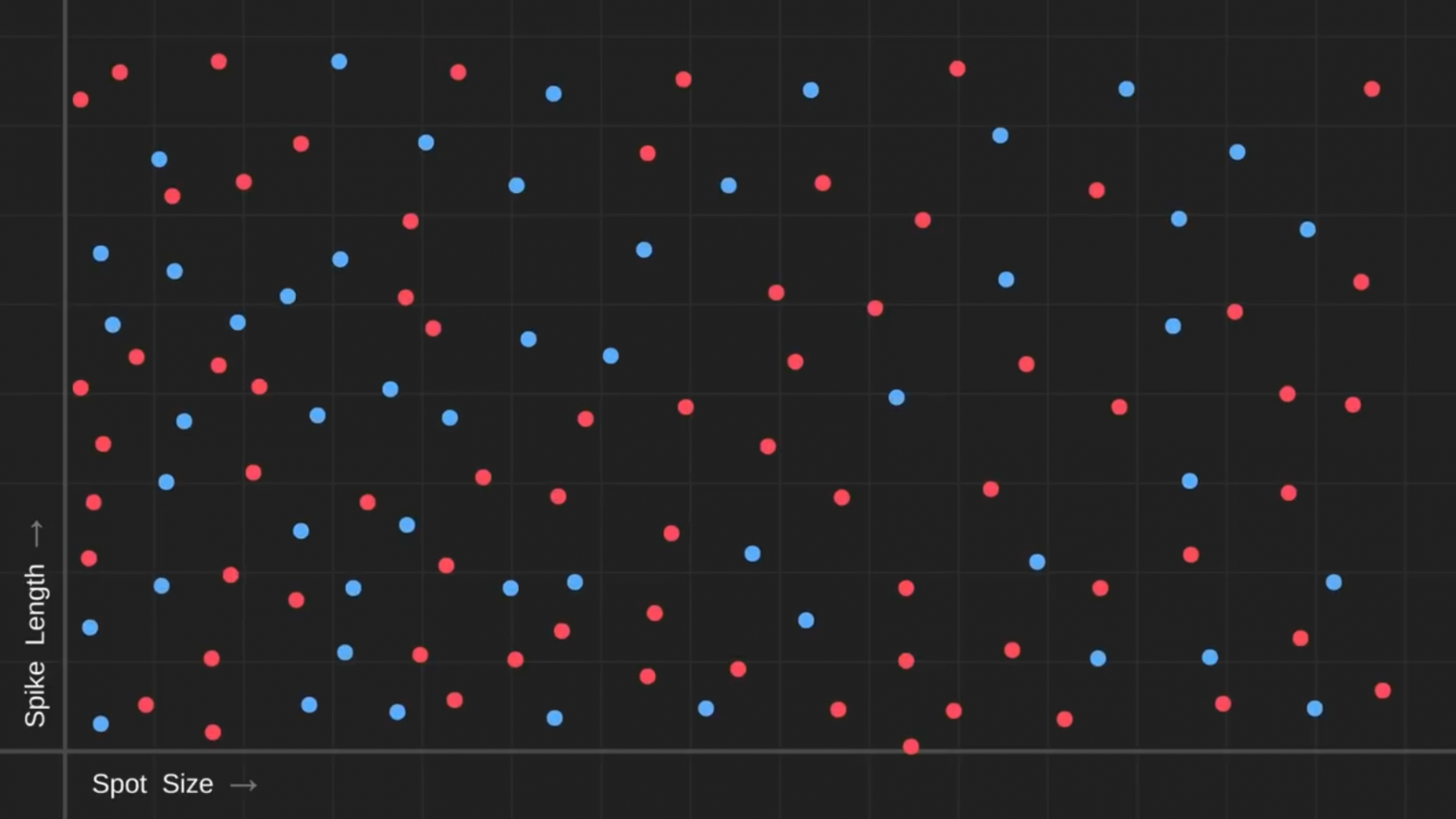
Если результат в конечном счёте выглядит вот таким вот случайным образом, то пятна и шипы, вероятно, не имеют отношения к тому, ядовит ли фрукт, и нам придётся придумать

Здесь можно провести небольшую линию, называемую границей принятия решения, и сказать, что любой фрукт, который находится по эту сторону границы, вероятно, ядовит, а по другую сторону, скорее всего, безвреден:
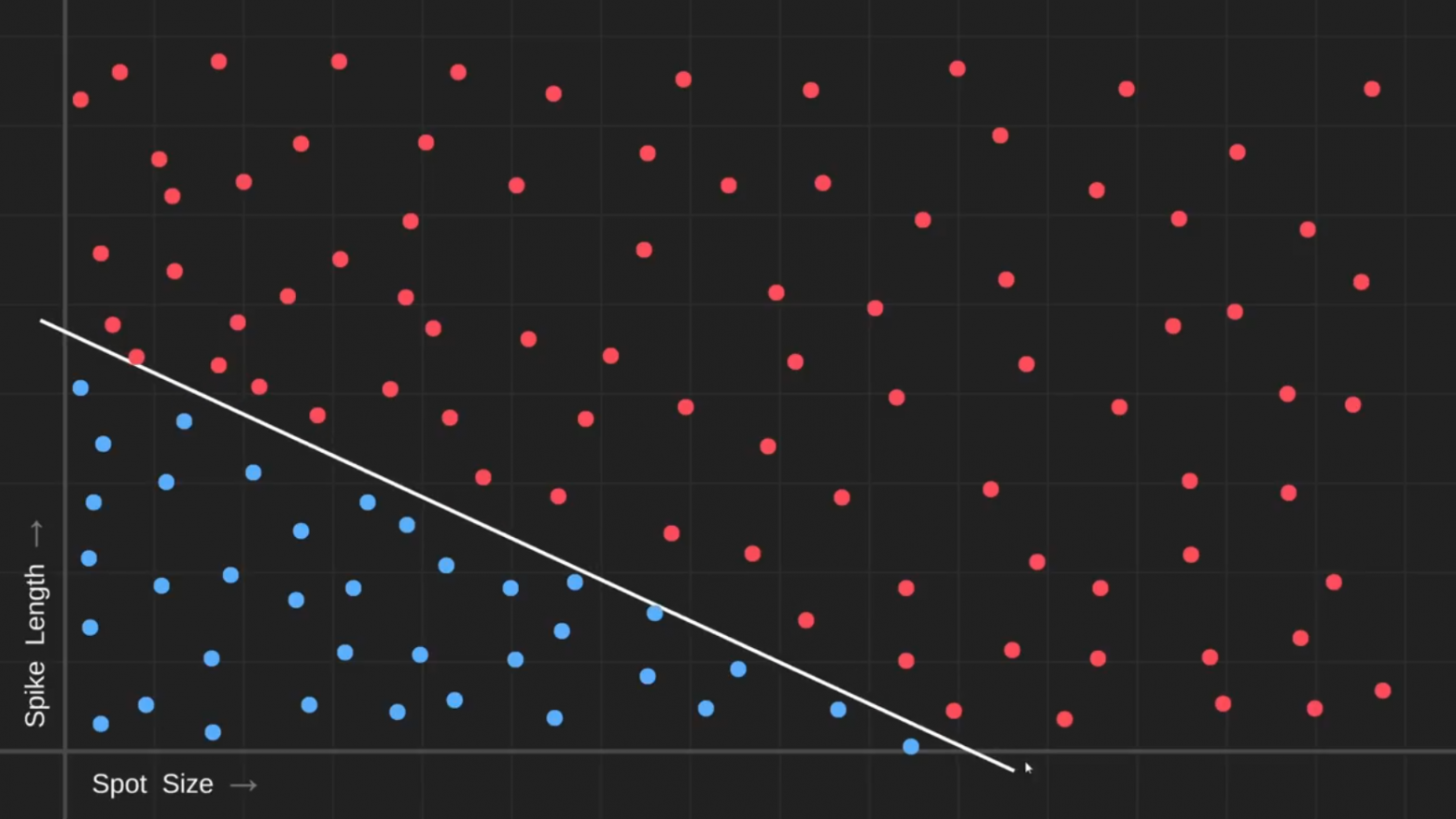
Итак, наш самый первый шаг — создать простую сеть, способную это определить.
Просто и понятно расскажем об IT и поможем стать востребованным профессионалом:
- «Уверенный старт в IT». Пройдите лучший курс для новичков: попробуйте 9 профессий и освойте подходящую именно вам.
- Полный курс по Data Science. Получите одну из самых перспективных профессий за 24 месяца.
- «C#-разработчик». Станьте профессионалом в разработке за 12 месяцев.

Веса
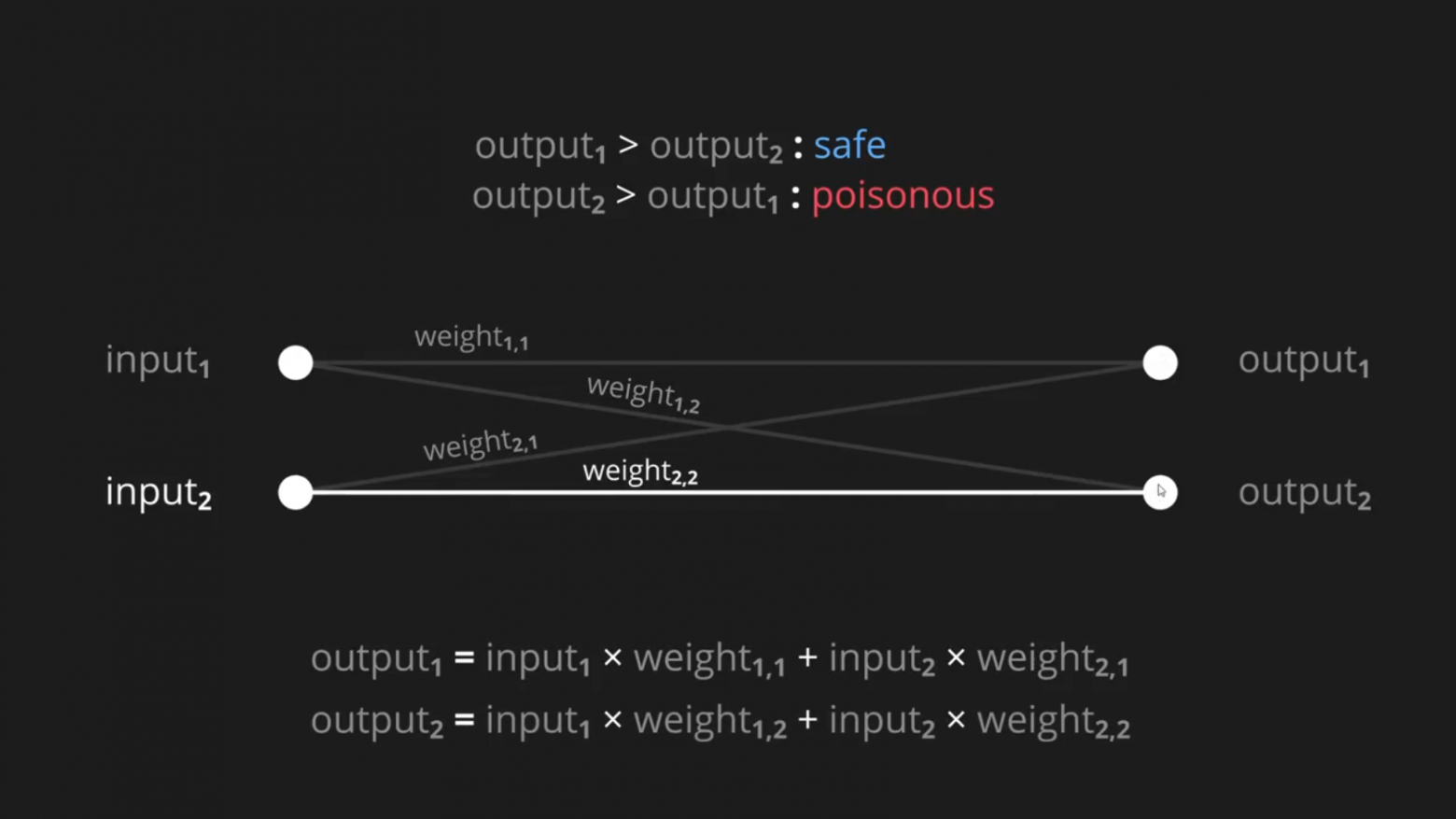
У нас есть два входных параметра для нашей задачи: размер пятен и длина шипов, а также два возможных результирующих параметра: безопасный или ядовитый. Если значение первого результирующего параметра больше второго, то мы предполагаем, что фрукт безопасен, если наоборот, то предполагается, что он ядовит.

Вы можете подумать, что два результирующих параметра — это довольно экстравагантно! Почему бы просто не иметь один? И сказать, что положительное значение означает безопасный, а отрицательное — ядовитый?
Мы, конечно, могли бы сделать так, но в следующих задачах будет более двух возможных результатов, поэтому полезно иметь отдельный результирующий параметр для каждого из них.
Итак, эти результирующие параметры, очевидно,
Таким образом, фактическое значение первого результирующего параметра будет равно первому входному параметру, умноженному на вес его соединения, и второму входному параметру, умноженному на вес его соединения. То же самое будет и со вторым результирующим параметром:
Я быстро написал код для выполнения этих расчётов. Вы можете увидеть их вот здесь, в функции Classify:

Затем, чтобы визуализировать происходящее, есть функция Visualize:

Она запускается для каждого пикселя на графическом дисплее и просит сеть предсказать, будет фрукт безопасным или ядовитым, а затем соответствующим образом окрашивает график. Итак, давайте посмотрим, что она делает. Сейчас результат выглядит очень параноидально. Кажется, нейросеть думает, что всё отравлено:

Но здесь, в углу, у нас есть веса нашей сети, так что я немного поиграю с ними. Посмотрим, смогу ли я получить ту границу принятия решения, которую мы хотим:
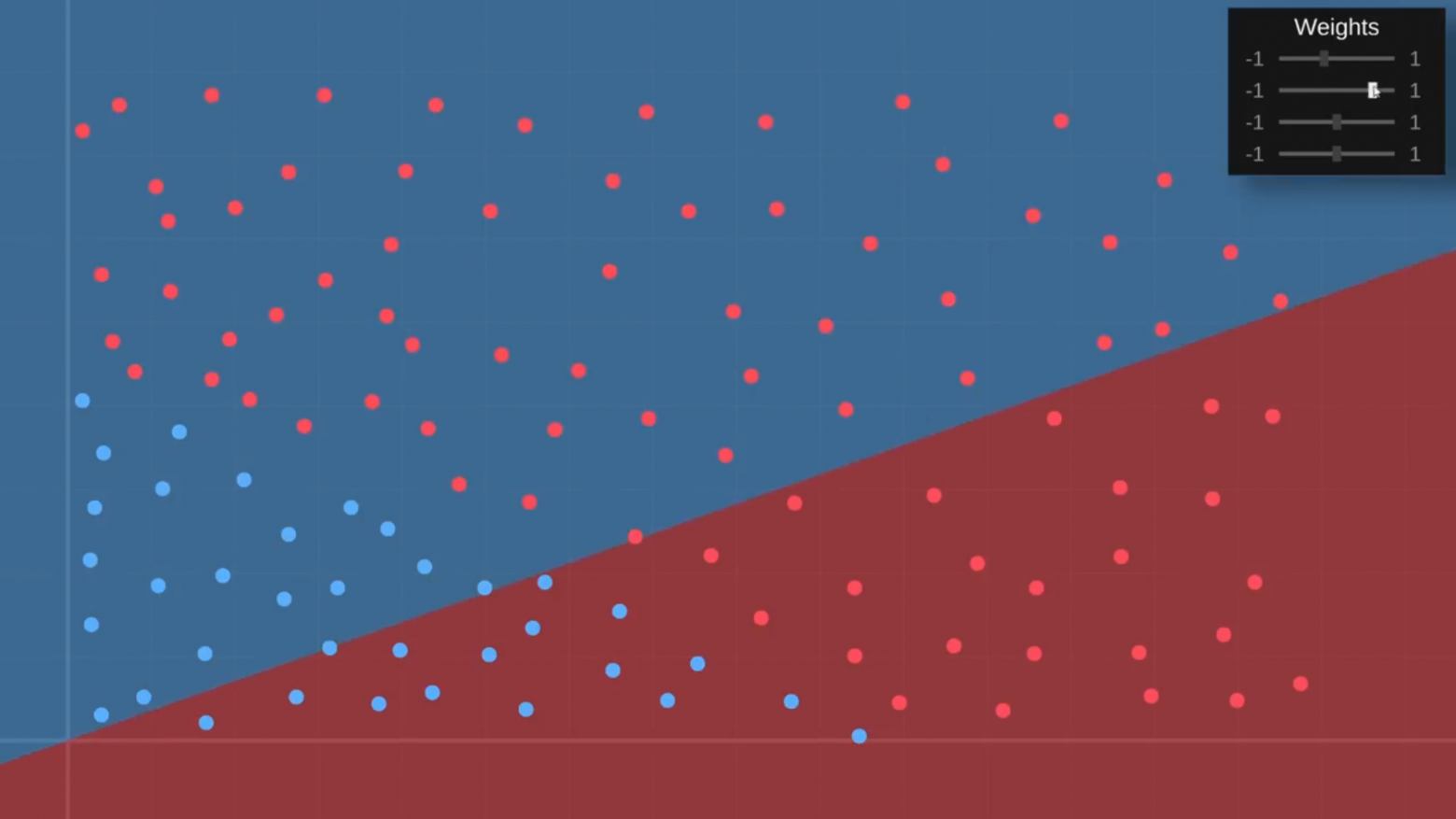
К сожалению, что бы я ни делал, я могу только заставить границу вращаться вокруг начала графика вот здесь, тогда как нам нужно иметь возможность сдвигать её по вертикали.
Смещения
Итак, давайте вернёмся к коду и немного модернизируем нашу сеть, добавив два новых значения под названием bias_1 и bias_2. Они просто добавятся к взвешенным входным параметрам в коде, что позволит нам перемещать эти значения вверх или вниз:

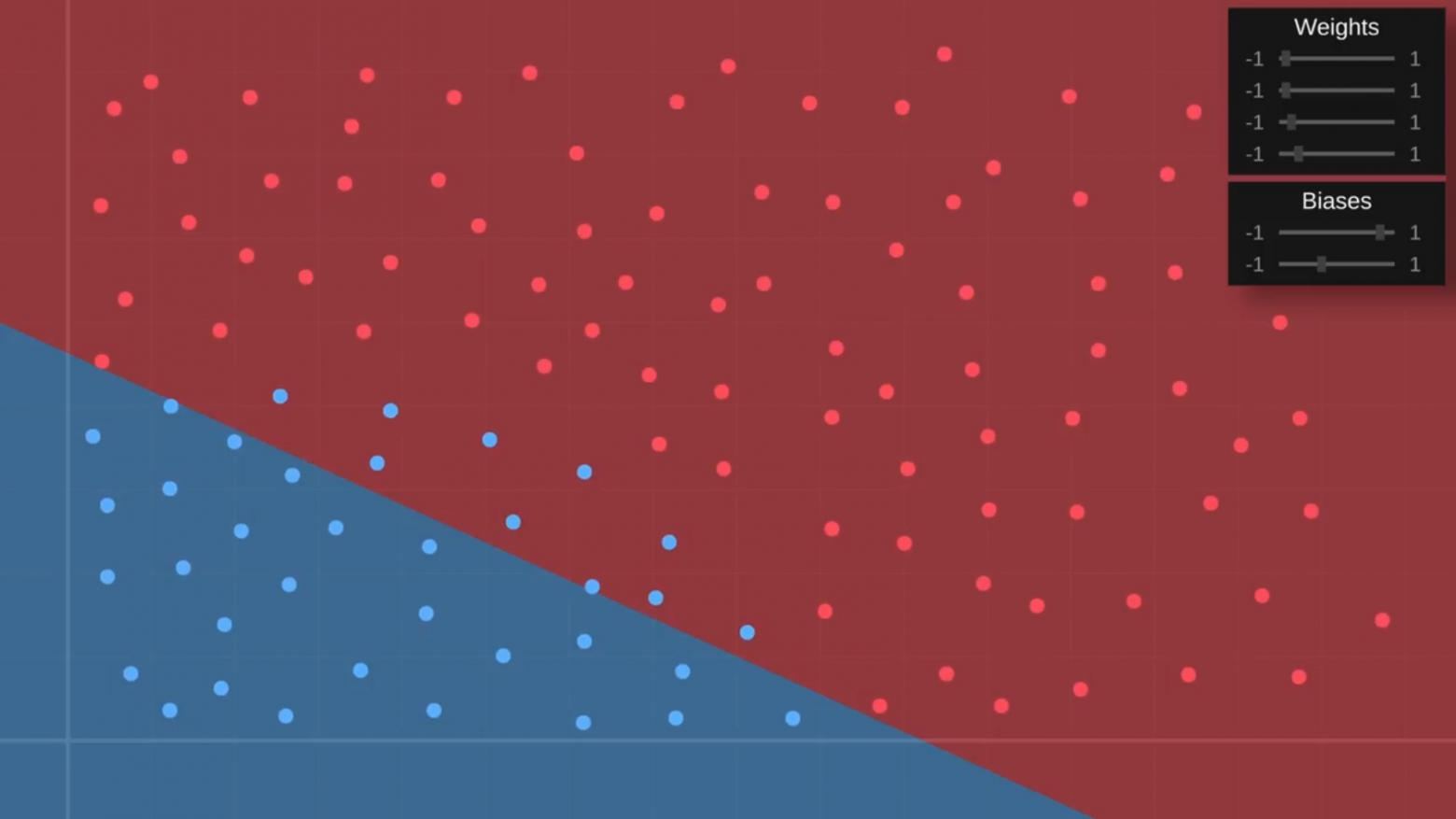
Хорошо, давайте попробуем ещё раз. Я снова поиграю с весами, чтобы попытаться получить правильный угол границы, а затем перейду к смещениям.
Управлять этим немного сложно, но при помощи терпения мы в конце концов сможем вручную обучить небольшую сеть правильно классифицировать фрукты на нашей тренировочной выборке:

Это была довольно простая задача, поэтому давайте представим, что наши данные о фруктах на самом деле выглядели примерно так:
Это, конечно, сложнее, потому что мы больше не можем отделить безопасное от ядовитого с помощью прямой линии, поэтому нам нужно будет ещё немного обновить нашу нейронную сеть.
Скрытые слои
Один из способов улучшить нейронную сеть — просто увеличить её. Нет смысла менять количество входных или выходных параметров, потому что они определяются задачей, которую мы пытаемся решить. Вместо этого можно создать новый слой, который находится между ними. Эти «промежуточные» слои называются «скрытыми»:

Они могут иметь столько узлов, сколько нам нужно, и у нас может быть даже несколько скрытых слоёв, но давайте пока не будем усложнять.
Когда эти входные значения передаются на следующий слой, они будут умножаться на свои веса, как мы видели ранее, и суммироваться со значением смещения, вместе создавая взвешенные входные параметры для этого узла. Как только вычисления для всех узлов среднего слоя будут закончены, эти значения могут быть переданы дальше таким же образом, чтобы сформировать взвешенные входные параметры для следующего слоя:

Даже для этой крошечной сети, имеющей всего 12 весов и 5 смещений, довольно утомительно записывать все расчёты вручную, как я сделал здесь, поэтому я собираюсь выбросить этот код и поработать над более разумным решением.
Программируем нейросеть
Итак, я начал с создания скрипта Layer, в котором хранятся значения веса для всех входящих соединений, а также значения смещения для каждого узла в слое. Здесь они настраиваются в зависимости от количества входящих и исходящих узлов:
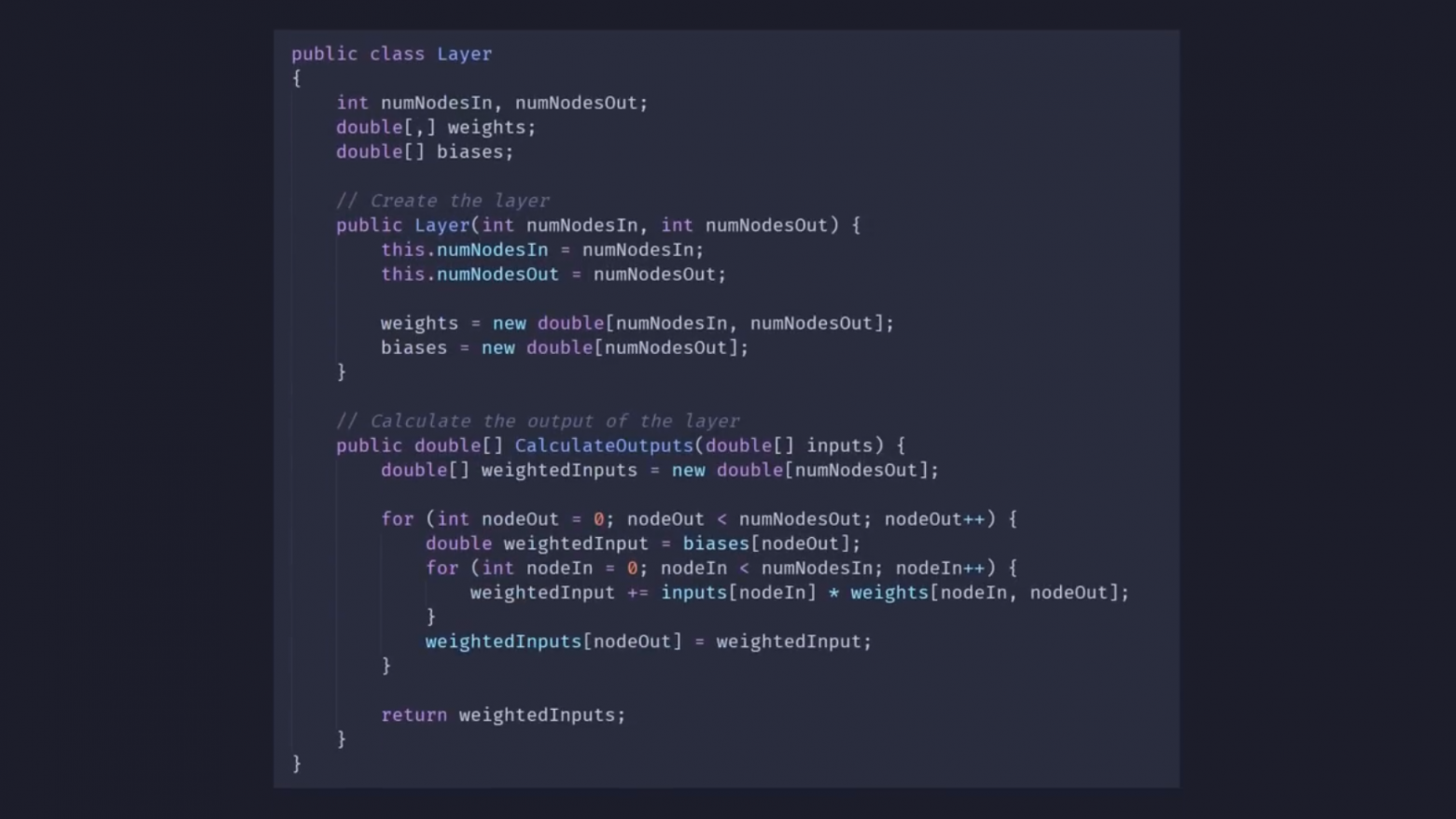
Для ясности: в коде я представляю этот слой как имеющий, например, 3 входящих и 2 исходящих узла. Тогда в этом слое будет 2 входящих и 3 исходящих узла:

На самом же деле этот слой просто представляет значения, переданные нашей сети, он ничего не делает, поэтому он не будет настоящим слоем в коде.
Но вернёмся к скрипту Layer. Всё, что осталось здесь рассмотреть, — функция CalculateOutputs. Она принимает некоторые входные значения и вычисляет взвешенные входные данные, просто перебирая в цикле каждый исходящий узел, устанавливая соответствующий weightedInput в значение смещения этого узла:

Затем она перебирает все входящие значения, умножая каждое из них на вес их соединения и добавляя результат к текущему weightedInput. На данный момент эти взвешенные входные значения затем возвращаются в качестве результирующих значений слоя.
Далее у нас есть класс NeuralNetwork, который содержит массив этих слоёв. Поэтому, когда создаётся сеть, ей нужно указать, сколько узлов должно быть в каждом слое, и она использует эту информацию, чтобы настроить их все так, как указано в коде ниже.

Теперь здесь находится функция для вычисления выходных значений всей сети, и всё, что она делает, — это перебирает все слои, вычисляет выходные значения каждого слоя и использует их в качестве входных значений для следующего слоя. Как только эти входные значения проходят через всю сеть, они становятся результирующими.
Наконец, функция Classify работает практически так же, как и раньше, она просто вычисляет выходные значения и возвращает индекс наибольшего значения. Итак, сейчас я создам сеть с тремя слоями, что даст гораздо больше параметров для экспериментов, и давайте посмотрим, что ещё интересного мы можем сделать!

Что ж, оказывается, добавление дополнительного слоя совсем не помогает. По крайней мере само по себе. Чтобы сделать эту границу изогнутой, нам нужно позволить слоям оказывать нелинейное влияние на результат.
Функция активации
Итак, давайте вернёмся к нашему дизайну и увеличим масштаб одного узла.
В грубой аналогии с биологическими нейронными сетями мы можем представить этот узел как нейрон, а взвешенные входные значения будем считать своего рода стимулами. Если стимул достаточен, это должно вызвать срабатывание нейрона, что в нашей модели может означать вывод значения 1; тогда как, если стимул меньше, чем нужно, нейрон не сработает, поэтому мы выводим 0:
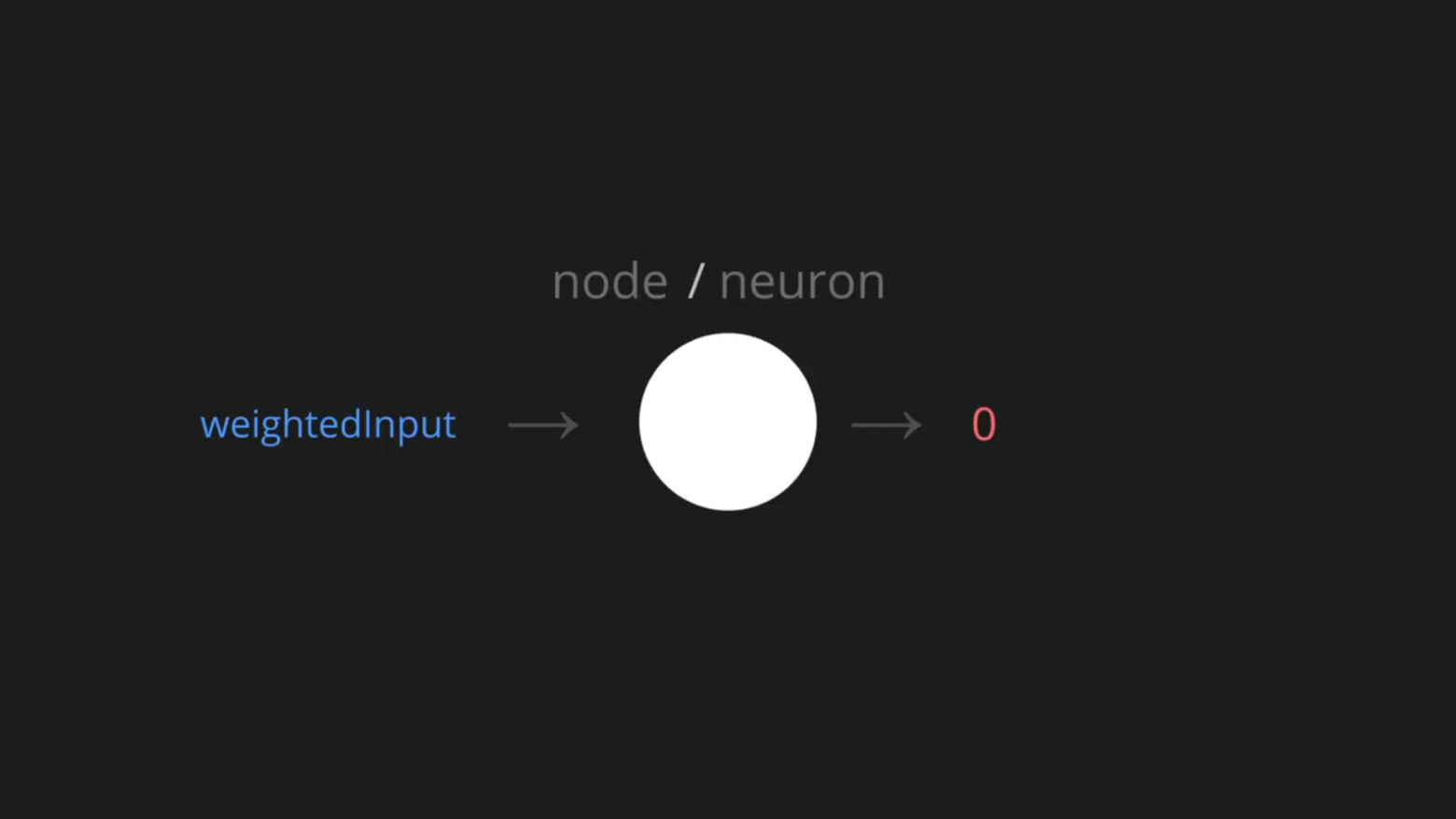
Я буду называть эти выходные значения «значениями активации». Нужно просто написать небольшую функцию, которая принимает взвешенные входные значения и вычисляет эти значения активации.

Давайте быстро покажем это на графике:
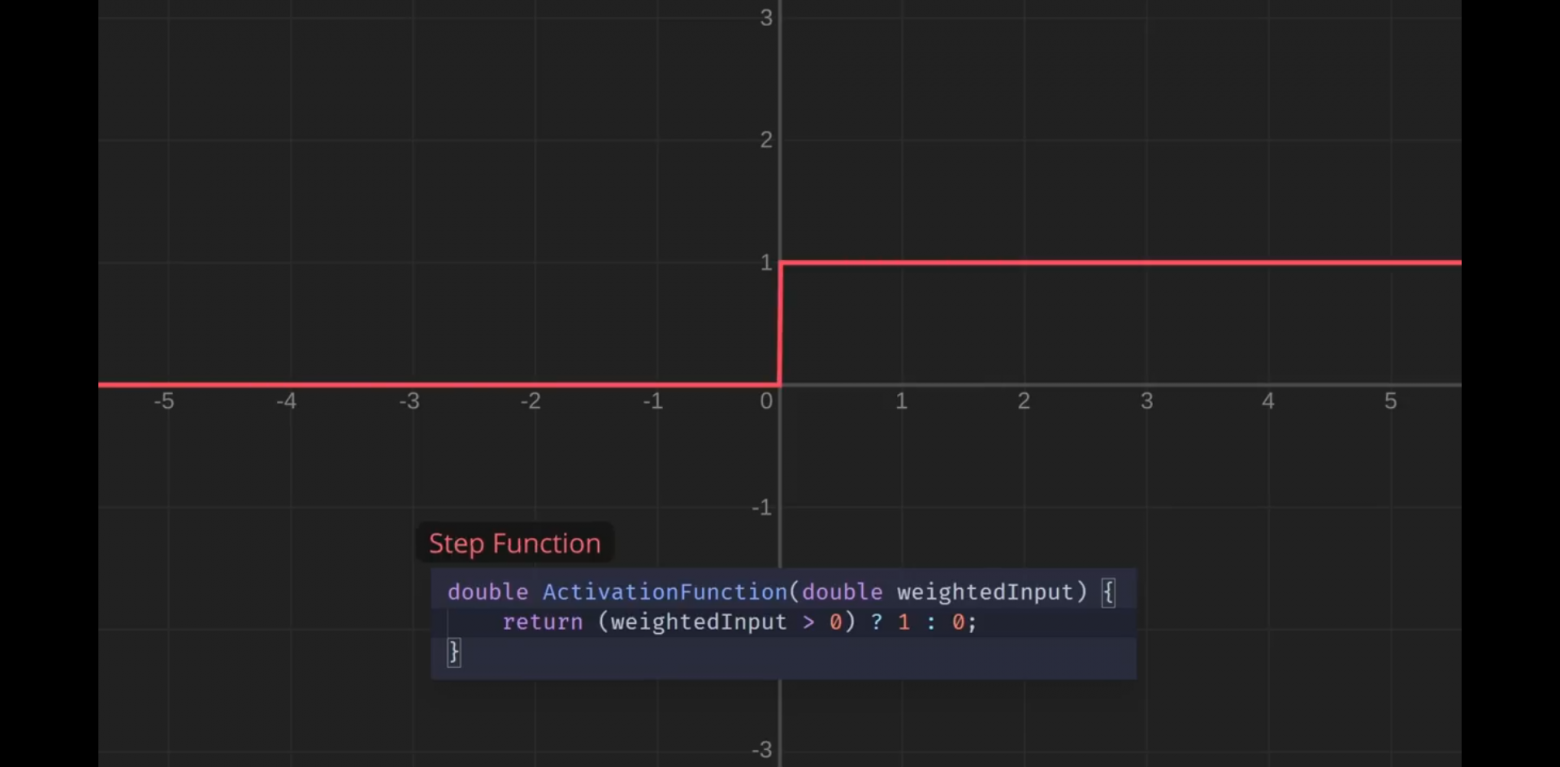
Таким образом, по оси X здесь показаны взвешенные входные значения, а по оси Y — соответствующие значения активации. Эта функция активации даёт нам более сложные границы принятия решений.
Однако, прежде чем мы сможем попробовать её, нужно перейти к скрипту Layer. Давайте, вместо того чтобы выводить здесь взвешенные входные значения, пропустим их через функцию активации, а затем вместо них выведем эти значения активации:

Итак, возвращаясь к увлекательному процессу случайной настройки ползунков до тех пор, пока

И, конечно, увеличение размера сети сейчас позволит нам создавать всё более причудливые формы. Но этой крошечной сети уже достаточно, чтобы правильно сортировать воображаемые фрукты.

Кстати, вы могли заметить, что смещения больше не просто сдвигают всю границу вверх или вниз, вместо этого они легко смещают значение, которое входит в функцию активации. Итак, если вспомнить биологическую аналогию, это будет похоже на порог, который стимул должен превысить, чтобы активировать конкретный нейрон.
А теперь
Давайте вернёмся к нашему выбору функции активации и для решения проблемы заменим её
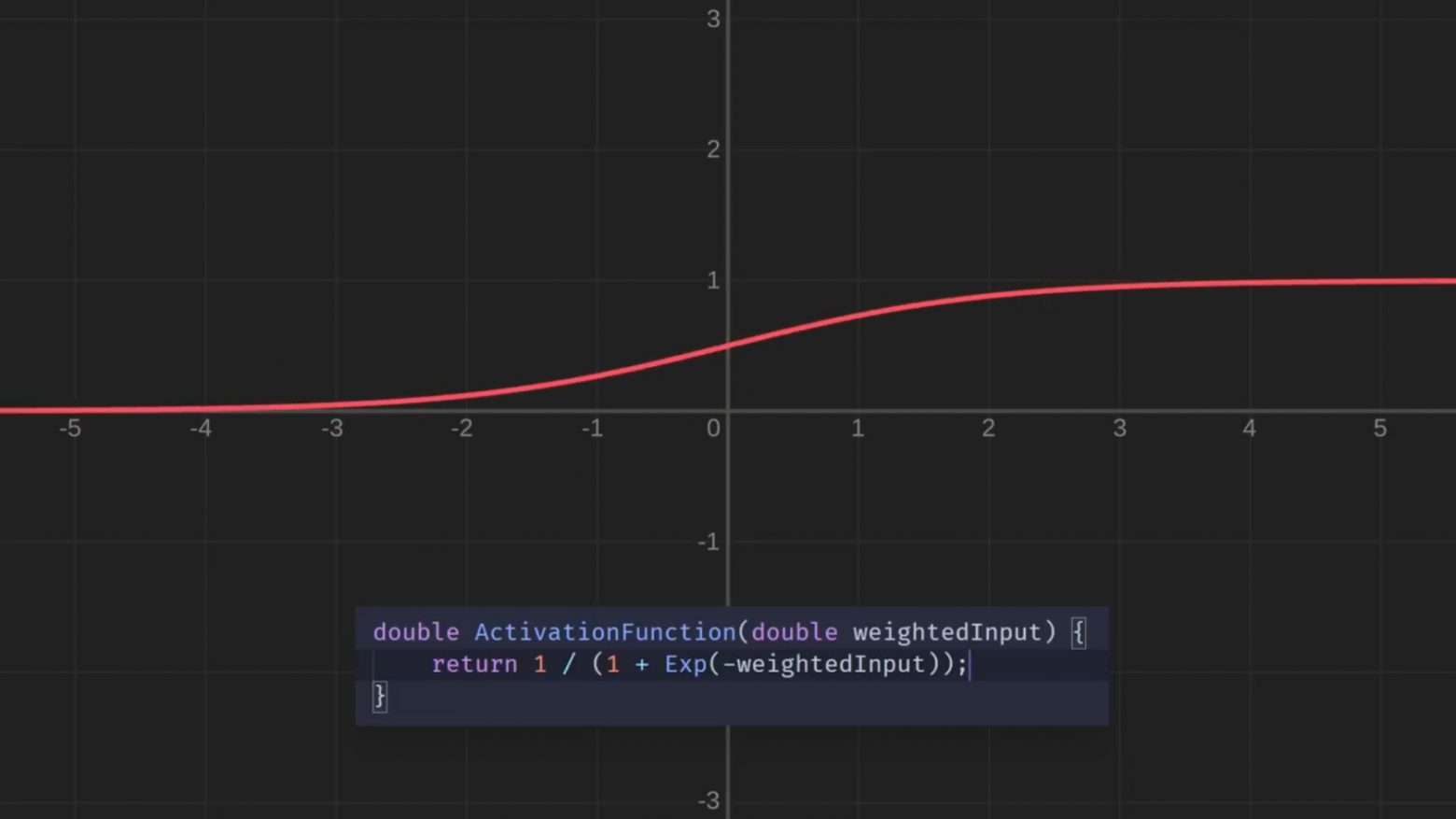
Теперь границы сглажены. Между прочим, эта функция называется сигмоидной. Сигмоидная функция — лишь одна из многих функций, с которыми люди экспериментировали для нейронных сетей. А вот ещё несколько, просто для интереса:
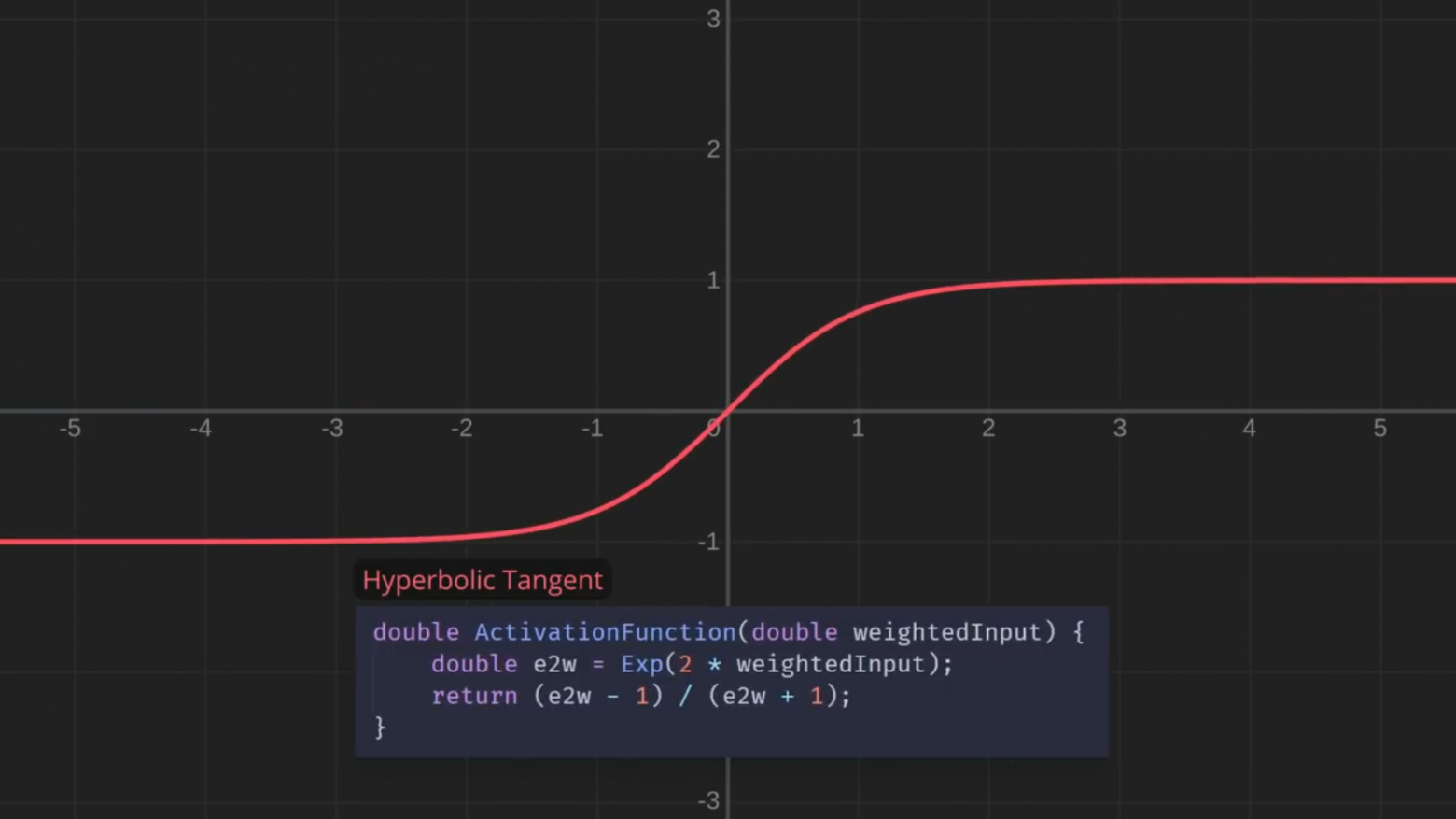

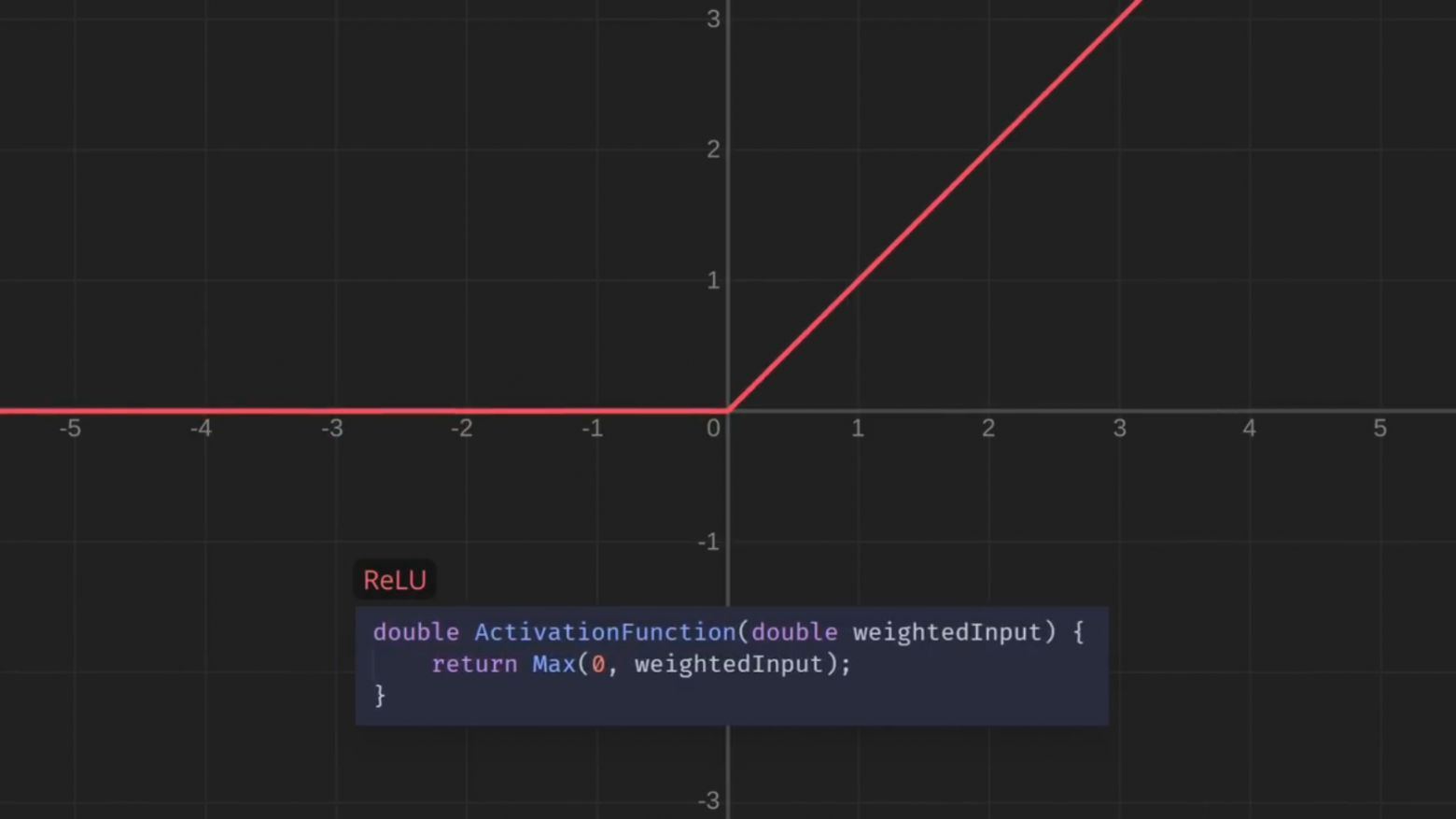
Давайте пока остановимся на этом и посмотрим, как изменится ситуация. Я ещё поиграю с этими ползунками — и у нас получатся красивые, плавные границы. И, что важнее, небольшая настройка одного ползунка больше не приводит к резкому изменению вывода:

Бесконечно пытаться обучать эту сеть вручную весело, но цель, конечно же, состоит в том, чтобы компьютер делал всё это сам. Нам нужен способ измерить, насколько хорошо это работает. Один из способов сделать это — просто подсчитать количество известных точек данных, которые классифицируются правильно. Но есть проблема: в большинстве случаев небольшая корректировка одного из ползунков на самом деле не изменит это число, ведь компьютер не знает, была ли корректировка полезной. Поэтому нужно попытаться найти способ измерять успехи поточнее.
Давайте снова подумаем о выходных значениях нашей сети, которые теперь скапливаются
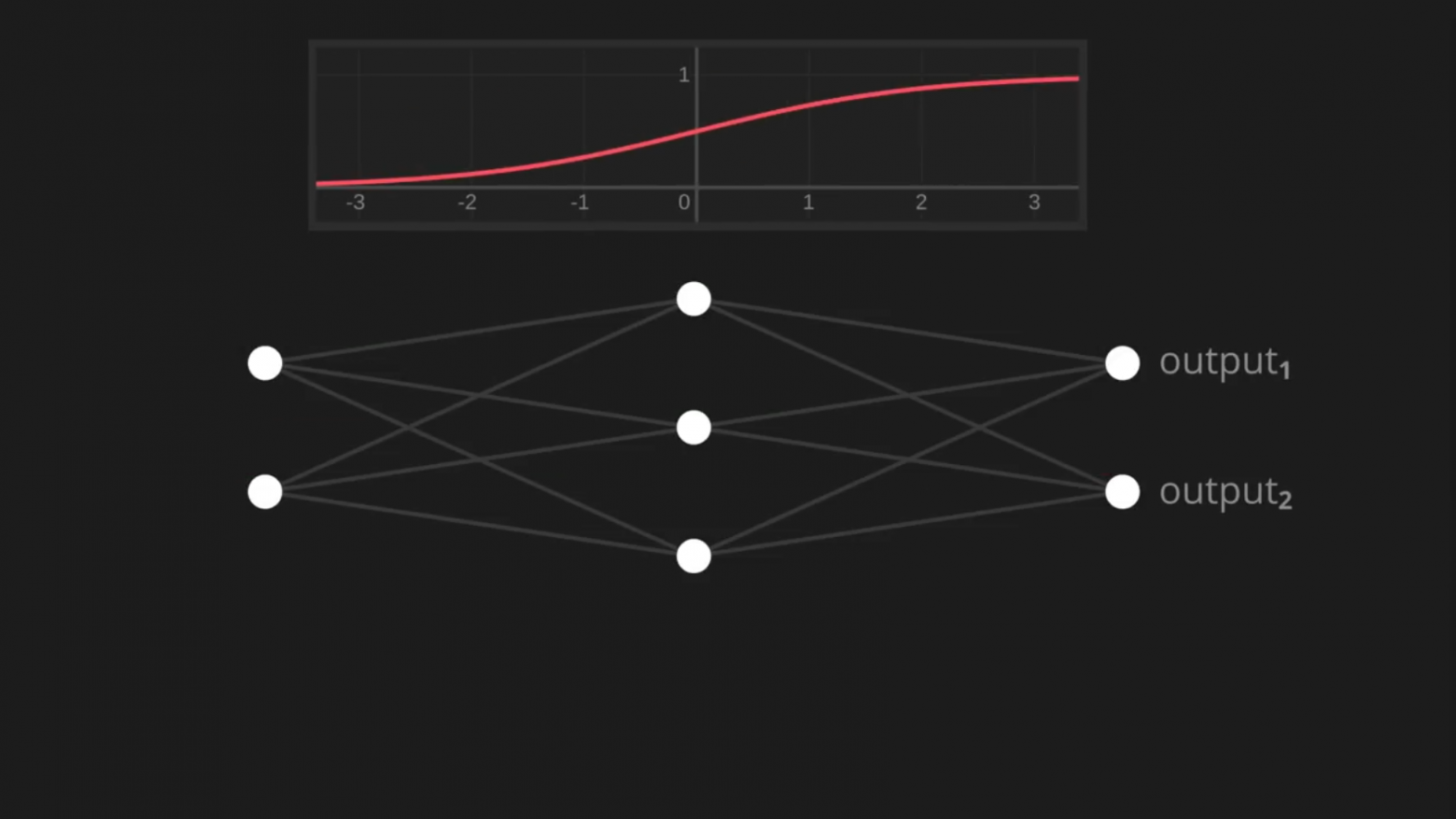
Если мы даём сети входные данные о безопасном фрукте, то надеемся увидеть 1 в качестве первого выходного значения и 0 в качестве второго. Эти значения дают полную уверенность в безопасности фрукта. Для ядовитых фруктов всё должно быть наоборот.

Итак, мы знаем, какими должны быть выходные значения для наших обучающих данных, поэтому я добавил в скрипт Layer небольшую функцию NodeCost, которая принимает выходную активацию одного узла вместе с нужным значением:
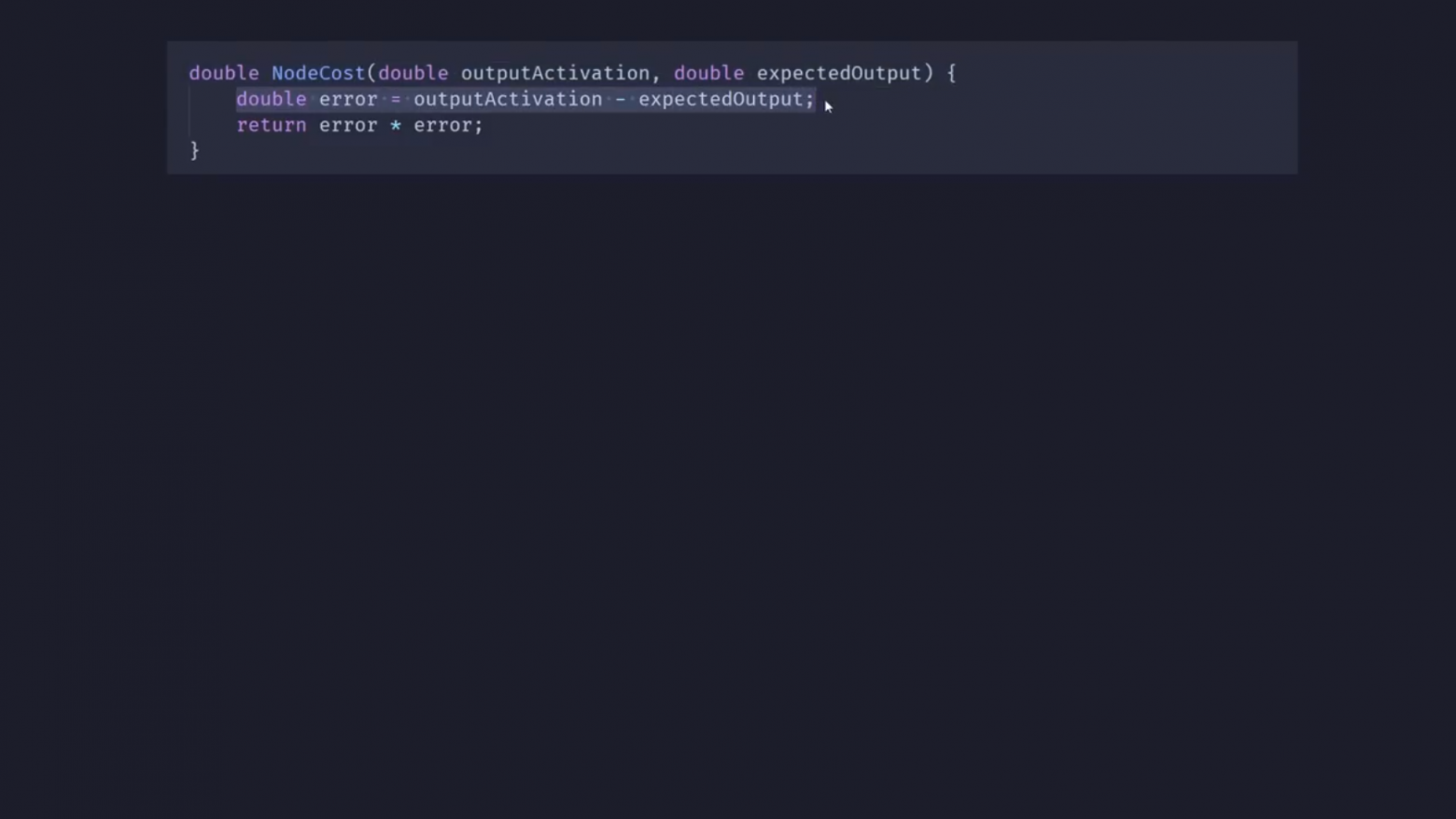
Всё, что она делает, — вычисляет разницу между ними и возводит результат в квадрат, чтобы сделать его положительным и подчеркнуть, что большие различия требуют гораздо более срочного исправления, чем небольшие.
Затем я добавил в NeuralNetwork функцию NodeCost, которую ещё называют функцией потерь. Она принимает одну точку данных, например один из наших фруктов, и пропускает свои входные значения через сеть, чтобы получить выходные значения.
Затем, используя выходные значения, NodeCost перебирает все узлы в выходном слое и просто суммирует каждое из их отдельных значений, чтобы получить общее значение, — меру того, насколько хорошо работает сеть для заданной точки данных.
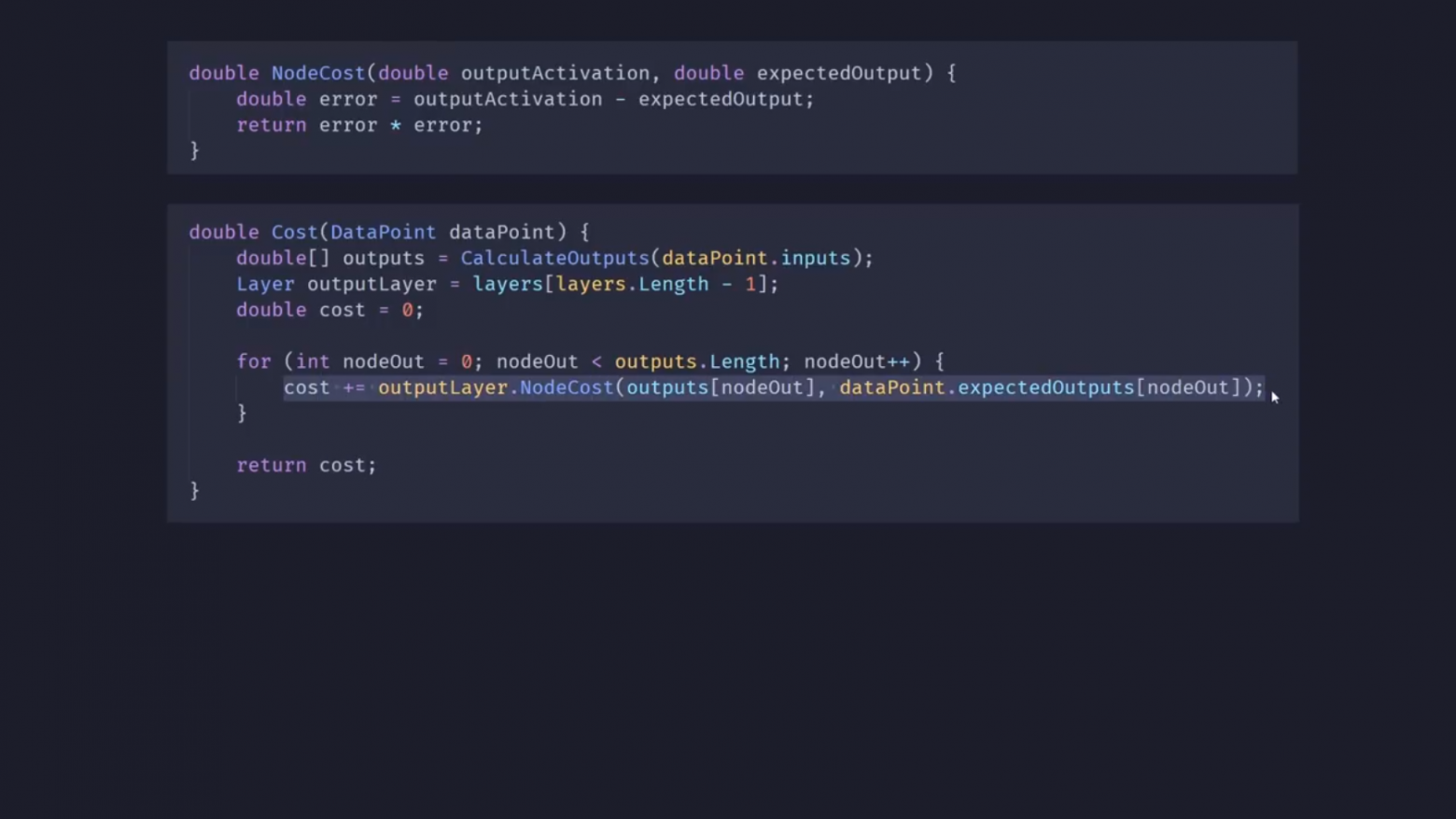
Однако нас больше всего интересует, как сеть работает со всеми точками данных, поэтому вот ещё одна версия функции потерь, которая на этот раз принимает несколько точек данных, просто суммирует результат для каждой из них и возвращает среднее значение.
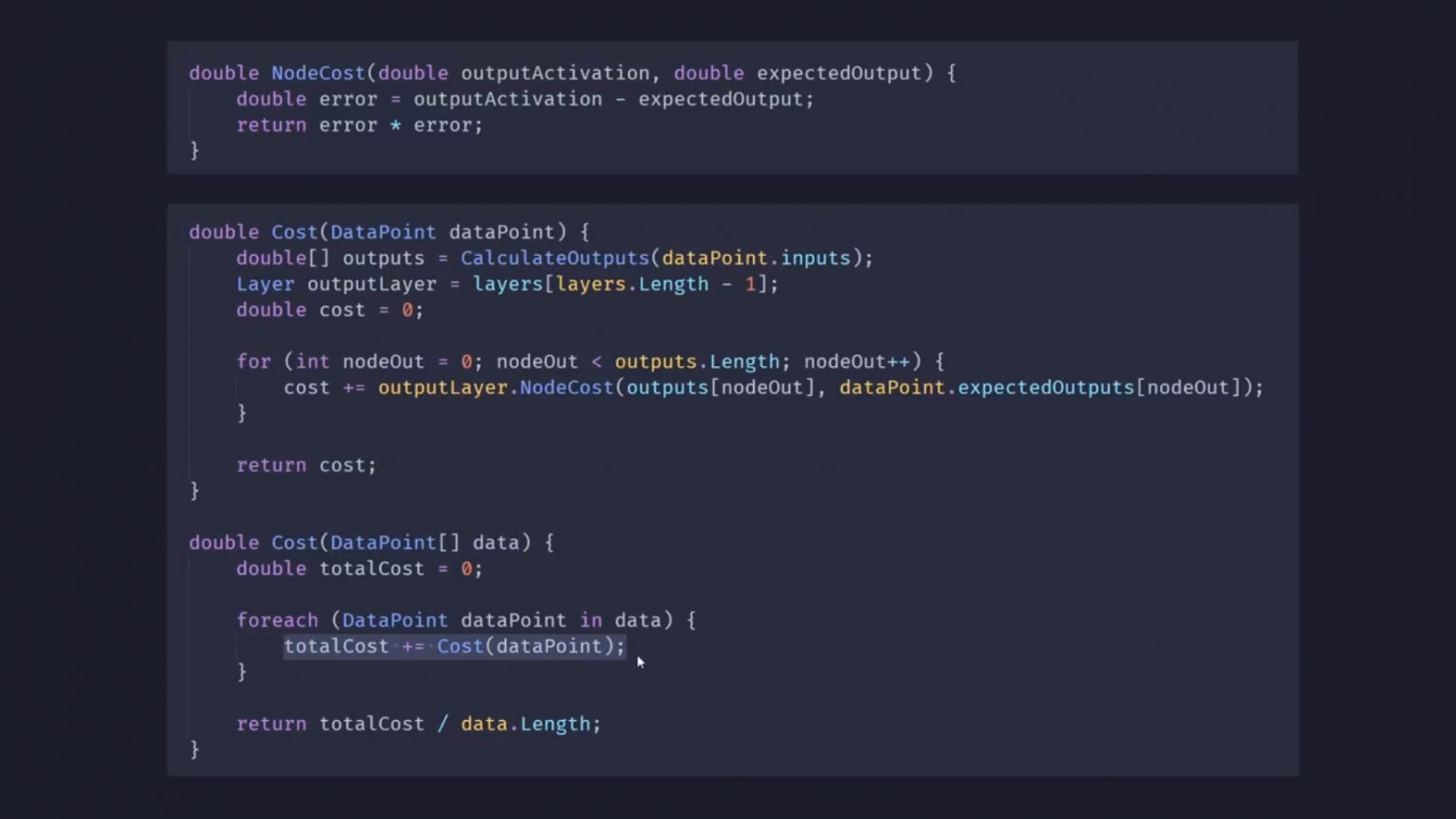
Таким образом, вы можете видеть это значение в нижней части экрана, и цель сети теперь состоит в том, чтобы просто найти здесь значения для 17 весов и смещений, которые приводят к наименьшему среднему значению cost.
В случае нашей крошечной сети мы, вероятно, могли бы обойтись методом проб и ошибок, но сети будут становиться намного больше по мере решения всё более сложных задач, поэтому мы обязательно должны попытаться найти лучшее решение.
О нём поговорим в следующей статье цикла.
А ещё поможем освоить самые востребованные IT-профессии:
- «Уверенный старт в IT». Пройдите наш лучший курс для новичков: попробуйте 9 профессий и освойте подходящую именно вам.
- Полный курс по Data Science. Самая перспективная профессия за 24 месяца.
- «C#-разработчик». Станьте разработчиком с широким набором навыков за 12 месяцев.


