Эрзянский язык из финно-угорской семьи – один из официальных в республике Мордовия, и на нём говорят сотни тысяч людей, но для него до сих пор не было почти никаких технологий машинного перевода, кроме простых словарей. Я попробовал создать первую нейросеть, способную переводить с эрзянского на русский (и с натяжкой ещё на 10 языков) и обратно не только слова, но и целые предложения.
Пока её качество оставляет желать лучшего, но пробовать пользоваться уже можно.
Как я собирал для этого тексты и обучал модели – под катом.
Введение
В последние годы технологии обработки естественного языка совершили большой скачок. Но, увы, основной эффект этого скачка пришелся на так называемые высокоресурсные языки, такие как английский и русский, для которых регулярно публикуются новые датасеты и обученные модели. В последние годы всё больше языков освещаются в публикациях по NLP. Но для большинства из примерно 7000 языков мира до сих пор не создано технологий автоматического перевода. Для некоторых нет даже просто качественных и полных словарей.
Последние пару лет я создавал ресурсы в основном для своего родного русского языка, а недавно впервые попробовал заняться языком, который не знаю вообще, и для которого существует не так много готовых ресурсов. Я выбрал язык Эрзя (myv), один из официальных языков в Мордовии (ещё один - родственный ему язык Мокша) и попробовал обучить для него энкодер предложений и модель для машинного перевода.
На эрзянском говорят несколько сотен тысяч человек (точного числа никто не знает из-за особенностей переписи населения). Кроме Мордовии, эрзянские сообщества есть в других регионах РФ (например, в Самарской области) и других странах (например, в Украине). Язык считается находящимся под угрозой, ибо в крупных городах типа Саранска он всё больше вытесняется русским, однако в сельских сообществах эрзянский передаётся молодым поколениям вполне активно. Эрзянский язык (как и мокшанский) относится к финно-угорской семье; его родственники – финский, эстонский и венгерский (а в РФ – например, языки Мари и Коми). В России на эрзянском пишут в основном кириллицей, и я работаю пока только с ней. Но существует и орфография на основе латиницы, и если вы готовы помочь мне собрать тексты в этом правописании – пишите в личку, и я попробую добавить его в следующую версию моих моделей.
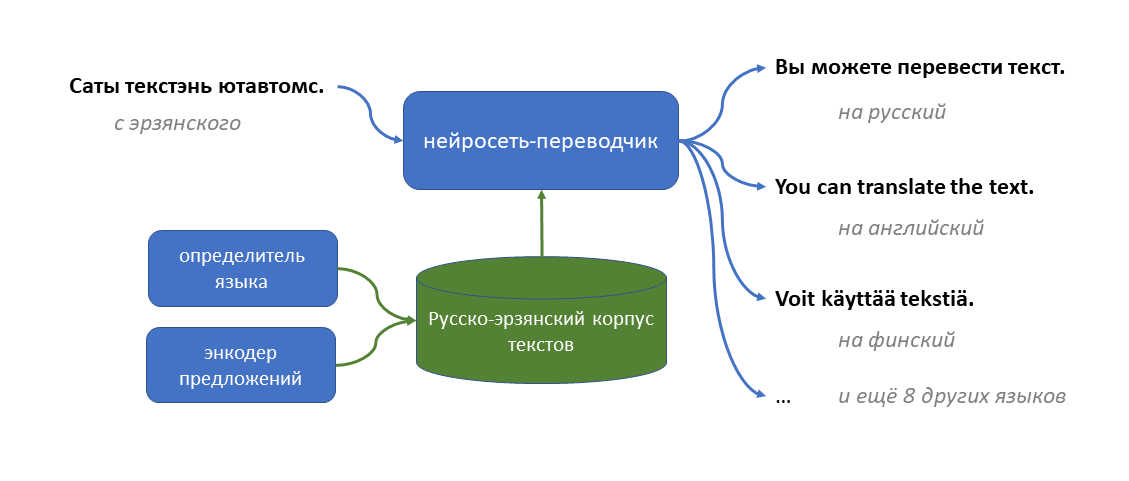
Несмотря на существенное число носителей и официальный статус эрзянского, систем машинного перевода для него почти не существует. Первое исключение, которое я нашел, это эрзянско-мокшанский переводчик (основанный на правилах) созданный Джеком Рюэтером. Второй пример – нейросеть от университета Хельсинки для перевода между несколькими финно-угорскими языками, включая эрзянский; на неё я наткнулся уже после своих экспериментов. Мне же хотелось создать первую систему, способную переводить между эрзянским и массовыми языками, типа русского и английского, и по возможности легко расширяемую на новые языки.
Чтобы прийти к этой цели, я собрал в интернете корпус текстов на эрзянском, и для части этих текстов сопоставил им русские переводы. В процессе мне пришлось обучить две модели: одну для детекции языка, и одну – для извлечения векторных представлений эрзянских предложений. С собранными текстами я сначала обучил пару моделей для перевода между русским и эрзянским, а потом расширил их на 10 других языков. Всё это я описал в статье. Качество получилось далеким от идеального, но я надеюсь, что моя работа станет бейзлайном, который кто-нибудь вскоре побьёт. Суммарно я потратил на эту работу около 10 рабочих дней и 10 долларов денег (на Google Colab): как видите, для создания моделей машинного перевода не обязательно обладать ресурсами масштаба Яндекса или Меты.
В остальном тексте поста я поведаю, как именно я собирал тексты и обучал модели. Возможно, вы вдохновитесь моим опытом и попробуете улучшить машинный перевод для эрзянского или даже создать его с нуля для каких-нибудь иных малоресурсных языков.
Сбор текстов
Я начал со словарей, ибо для эрзянского они существуют давно. Брал отсюда: 1 2 3 4 5 6. Парсил html с помощью beautifulSoup, pdf - посредством pdfminer; и с тем, и с другим пришлось повозиться. Суммарно мне удалось собрать 48 тысяч пар эрзянских и соответствующих им русских слов и словосочетаний. Увы, для автоматического перевода одних словарей мало: они не помогают ни с морфологией (изменением формы слова), ни с синтаксисом (построением из отдельных слов целых предложений). И то, и другое теоретически можно было бы описать правилами, но для этого надо быть лингвистом и хорошо знать оба языка. Поэтому я пошёл по пути машинного обучения: пусть нейросети сами разберутся, как формировать слова и составлять из них предложения.
Для обучения моделей машинного перевода используются так называемые параллельные корпуса, то есть большие наборы текстов с одинаковым смыслом на разных языках (как правило, сопоставленные друг с другом на уровне предложений). Обычно такие корпуса хорошо ищутся на сайте OPUS, но для эрзянского там нашлось всего 3 тысячи предложений, собранных с сайта Wikimedia и выровненных с русским. 3 тысячи – это очень мало для такой задачи; для хорошего машинного перевода нужно что-то ближе к миллиону. Поэтому остальные параллельные тексты мне пришлось искать самому. В общем-то, из всего моего подхода к созданию переводчика, этот этап - наиболее завязанный на человека и на конкретный язык. Всё остальное, кажется, можно воспроизводить для других языков практически вслепую.
Начал я с двух стандартных источников: Библии и Википедии. Библия переведена на большее число языков, чем любая другая книга, и в ней пронумерованы абзацы, что очень удобно для сопоставления текстов на разных языках. Википедия не так удобна для поиска параллельных текстов (статьи на одну тему на разных языках редко имеют полностью одинаковое содержание), зато она покрывает большой набор тем, и на эрзянском там 7719 статей (правда, в основном коротеньких).
На Википедии (93K случайно выбранных статей из 323 языков) и Библии (мокшанской и эрзянской) я обучил модель fastText для определения языка по тексту. Почему не воспользовался готовой? Потому что в ней нет мокшанского, и в ранней версии моих экспериментов эрзянский с ним сильно путался (и с другими языками с кириллическим алфавитом тоже). После сжатия модель весит 2.2 мегабайта и выложена тут. Дальше я пользовался ей для фильтрации предложений из некоторых источников, менее надежных, чем Википедия.
Очень много эрзянских текстов оказалось в проекте Wikisource, выкладывающем литературные произведения в открытый доступ. Кроме этого, я скачал много книг и газет в pdf отсюда и отсюда, а еще попарсил сайт издания Эрзянь Правда. Наконец, я насобирал эрзянских текстов в старом добром ЖЖ: воспользовался встроенным поиском по сайту и собрал 1132 постов, содержащих 100 наиболее употребительных эрзянских слов. Многие из этих текстов содержали и предложения на других языках или смесь языков, но модель для определения языка позволила их отфильтровать.
Таким образом, я оказался с кучей эрзянских текстов, для части которых был приблизительный русский аналог. Но для обучения модели «приблизительного аналога» на уровне текста недостаточно: нужно отобрать из корпуса пары предложений, которые соответствуют друг другу по смыслу наверняка. И для этого мне понадобилась еще одна модель: энкодер предложений.
Энкодер предложений для эрзянского
Энкодер предложений - это модель, которая на вход принимает короткий текст, а на выходе возвращает многомерный вектор, причем такой, что у текстов, похожих по смыслу, векторы близки друг к другу в математическом смысле. Про энкодеры предложений для русского языка я писал тут и здесь. А если такая модель понимает два языка, то её можно использовать для майнинга параллельных пар предложений из пары связанных текстов (например, из статей русской и эрзянской Википедии на одну и ту же тему). Алгоритм такой:
Разбиваем тексты на предложения (пакет razdel).
Вычисляем вектор каждого предложения, и считаем косинусную близость каждого предложения первого текста к каждому предложению второго.
На случай, если модель не очень точная, вставляем два костыля. Чтобы отсечь пары предложений, сильно отличающихся по длине, домножаем косинусную близость каждой пары на отношение длины более короткого предложения к более длинному. А чтобы отсечь предложения, похожие на всё сразу (такие попадаются), вычитаем из близости для каждой пары по 0.2 средних близости составляющих её предложений к топ-10 своим ближайшим соседям. Число 0.2 я подбирал на глаз.
Находим такие подпоследовательности предложений в русском и эрзянском тексте, что они идут в одном и том же порядке, и что сумма близостей пар предложений с одинаковым номером - максимальна.
Если средняя близость друг к другу выбранных таким образом пар предложений выше порога (который я подбирал отдельно для каждого источника текстов), мы считаем их параллельными.
Проблема в том, что энкодера предложений для эрзянского не существовало. Но был LaBSE на основе BERT, который делает это для 100 языков, и логично было попробовать адаптировать его для еще одного. Для этого я сначала расширил словарь модели: прогнал алгоритм byte pair encoding на собранном мной эрзянском корпусе и отобрал им 20к новых токенов (слов либо кусочков слов), наиболее часто встречающихся в эрзянских текстах. Я добавил эти токены в модель (попутно выкинув токены для других языков, кроме русского и английского, как тут) и принялся дообучать её в несколько этапов:
Обновлял только эмбеддинги токенов – так, чтобы эмбеддинги русских слов или предложений и соответствующих им эрзянских становились как можно более похожими друг на друга.
Обновлял все параметры модели (токены и 12 трансформерных слоёв), обучая модель решать сразу три задачи: приближение векторов эрзянских предложений к соответствующим русским; угадывание пропущенных слов в эрзянском предложении; определение по паре предложений, совпадает у них смысл или нет.
Полученную модель я выложил на huggingface. Её можно скачивать и дообучать на разные задачи понимания эрзянского языка. Ну а сам я использовал её для майнинга параллельных текстов алгоритмом, описанным выше. Намайнить удалось 11К пар предложений из Википедии, и ещё столько же - из разных книг и художественных произведений. Думаю, намайнить можно было и больше, но я, как человек, не знающий эрзянского, настроил пороги фильтрации предложений построже, чтобы нечаянно не набрать мусора.
Три тысячи пар предложений я отложил в качестве валидационной и тестовой выборки. Я выбрал их случайным образом из 6 разнообразных и более-менее надёжных источников: Библии, сборника эрзянских сказов Шеяновой, советской конституции 1938 года, описаний мордовских народных игр Брыжинского, современных художественных произведений на эрзянском, и Википедии. Собранный и разбитый на части корпус можно скачать отсюда.
Обучение моделей для перевода
В качестве базовой модели для перевода я выбрал mBART-50: трансформерную нейросеть, обученный переводить между 50 языками. Вместо этого мог взять M2M-100 или даже NLLB-200 (хотя на момент начала моих экспериментов она ещё не вышла); наверняка качество могло бы от этого вырасти; в следующих экспериментах надо будет попробовать. Я добавил в неё 20К новых слов и кусочков слов для эрзянского языка, а потом обучил на своём корпусе две копии этой модели: одну для перевода с русского на эрзянский, другую – наоборот.
Качество перевода получилось вроде бы ненулевым, поэтому я решил обнаглеть и попробовать добавить в модель ещё 10 языков: арабский, немецкий, английский, испанский, финский, французский, хинди, турецкий, украинский, и китайский. Все эти языки mBART-50 уже видел при предобучении, поэтому ему должно быть не очень сложно. В итоге одна модель (myv-mul) у меня переводит с эрзянского на 11 других языков, а вторая (mul-myv) – с этих языков на эрзянский.
Пары предложений новых языков с русским я взял из датасета CCMatrix, и по ходу дообучения дополнял их эрзянскими переводами из своей русско-эрзянской модели, чтобы потом учить другую модель переводить эти эрзянские тексты на иностранный. Кроме этого, я переводил на 10 новых языков эрзянские тексты из своего русско-эрзянского или чисто эрзянского корпуса, и затем учил модель переводить эти переводы обратно уже на эрзянский. Таким образом, я использовал несколько вариантов обратного перевода:

Заняло это обучение несколько суток в Google Colab (результат сохранялся на Google disk, и блокноты каждый день приходилось перезапускать). В результате модель оказалась способна переводить примерно так:

Оценка качества
В какой-то момент мне захотелось закрепить успех и измерить качество своих моделей. Для эрзянско-русского перевода у меня уже был отложенная выборка из 6 разных источников. Для ещё двух языков, английского и финского, несколько сотен параллельных предложений нашлось в эрзянском корпусе Universal Dependencies, собранном всё тем же Jack'ом Rueter'ом. Все эти предложения я перевёл во всех возможных направлениях (с эрзянского на русский/английский/финский и наоборот) и сравнил мои переводы с человеческими с помощью двух метрик: BLEU и ChrF++. Они обе вычисляют долю совпадения между двумя предложениями, но BLEU сравнивает только слова и словосочетания, а ChrF++ – ещё и кусочки из нескольких букв (это помогает, если слово написано с опечаткой или в другом падеже). У обоих метрик максимальное значение 100, но на практике оно не достигается, ибо у одного и того же предложения может быть очень много корректных переводов.

Наблюдений можно сделать несколько. Во-первых, перевод между эрзянским и нерусскими языками пока очень слабенький: видимо, на обратном переводе уехать сложно, и стоит добавить в обучающих корпус хоть немного настоящих параллельных текстов для этих языков. Во-вторых, даже перевод между русским и эрзянским ещё расти и расти: у SOTA систем для высокоресурсных языков BLEU обычно где-то между 40 и 80. В-третьих, скоры BLEU очень разнятся в зависимости от домена: они высокие для конституции и Википедии, где много дословных переводов, и сильно ниже у художественных текстов, где переводы гораздо более разнообразные и непредсказуемые.
Имеет ли смысл вообще пользоваться моим переводчиком, или его качество пока настолько низкое, что переводить им бессмысленно? Чтобы понять это, я нашёл трёх волонтёров – носителей эрзянского, и попросил их оценить качество 29 случайно выбранных переводов между русским и эрзянским. Я предложил им пятибалльную шкалу, где 1 – бесполезный перевод, 5 – идеальный перевод, а 3 – приемлемый перевод без критических ошибок. Потом для каждого перевода я взял самую низкую из трёх оценок волонтёров. Оказалось, что 58% переводов с эрзянского на русский получили хотя бы тройку (средний балл 2.75). Для переводов с русского на эрзянский доля троек и выше вышла 53%, а средний балл – 2.71.
Короче говоря, модели выдают приемлемые переводы пока где-то в половине случаев.
Самостоятельно попробовать применить их вы можете тут.
И что дальше?
Задача машинного перевода для эрзянского языка пока явно не решена, но я хотя бы положил начало этому пути. Все мои результаты выложены в свободный доступ (список ссылок – тут), и я приглашаю вас пробовать улучшать их. Сам я тоже собираюсь улучшать модели сразу по нескольким направлениям:
Сбор большего количества эрзянских и параллельных текстов и их более качественная фильтрация;
Создание ещё большего количества обучающих текстов автоматическими средствами, например, с помощью словарей и пакета UralicNLP (как в этой статье);
Использование более крутых предобученных моделей, таких как NLLB-200.
Я открыт к сотрудничеству. Если вы владеете эрзянским и можете помочь мне с более аккуратным сбором текстов, или если вы хотите создать системы машинного перевода для какого-нибудь другого языка – пишите в комменты или сразу в личку.

