Статей о работе с PostgreSQL и её преимуществах достаточно много, но не всегда из них понятно, как следить за состоянием базы и метриками, влияющими на её оптимальную работу. В статье подробно рассмотрим SQL-запросы, которые помогут вам отслеживать эти показатели и просто могут быть полезны как пользователю.

Зачем следить за состоянием PostgreSQL?
Мониторинг базы данных также важен, как и мониторинг ваших приложений. Необходимо отслеживать процессы более детализировано, чем на системном уровне. Для этого можно отслеживать следующие метрики:
Насколько эффективен кэш базы данных?
Какой размер таблиц в вашей БД?
Используются ли ваши индексы?
И так далее.
Мониторинг размера БД и её элементов
1. Размер табличных пространств
SELECT spcname, pg_size_pretty(pg_tablespace_size(spcname)) FROM pg_tablespace WHERE spcname<>'pg_global';
После запуска запроса вы получите информацию о размере всех tablespace созданных в вашей БД. Функция pg_tablespace_size предоставляет информацию о размере tablespace в байтах, поэтому для приведения к читаемому виду мы также используем функцию pg_size_pretty. Пространство pg_global исключаем, так как оно используется для общих системных каталогов.
2. Размер баз данных
SELECT pg_database.datname, pg_size_pretty(pg_database_size(pg_database.datname)) AS size FROM pg_database ORDER BY pg_database_size(pg_database.datname) DESC;
После запуска запроса вы получите информацию о размере всех баз данных, созданных в рамках вашего экземпляра PostgreSQL.
3. Размер схем в базе данных
SELECT A.schemaname, pg_size_pretty (SUM(pg_relation_size(C.oid))) as table, pg_size_pretty (SUM(pg_total_relation_size(C.oid)-pg_relation_size(C.oid))) as index, pg_size_pretty (SUM(pg_total_relation_size(C.oid))) as table_index, SUM(n_live_tup) FROM pg_class C LEFT JOIN pg_namespace N ON (N.oid = C .relnamespace) INNER JOIN pg_stat_user_tables A ON C.relname = A.relname WHERE nspname NOT IN ('pg_catalog', 'information_schema') AND C .relkind <> 'i' AND nspname !~ '^pg_toast' GROUP BY A.schemaname;
После запуска запроса вы получите детальную информацию о каждой схеме в вашей базе данных: суммарный размер всех таблиц, суммарный размер всех индексов, общий суммарный размер схемы и суммарное количество строк во всех таблицах схемы.
4. Размер таблиц
SELECT schemaname, C.relname AS "relation", pg_size_pretty (pg_relation_size(C.oid)) as table, pg_size_pretty (pg_total_relation_size (C.oid)-pg_relation_size(C.oid)) as index, pg_size_pretty (pg_total_relation_size (C.oid)) as table_index, n_live_tup FROM pg_class C LEFT JOIN pg_namespace N ON (N.oid = C .relnamespace) LEFT JOIN pg_stat_user_tables A ON C.relname = A.relname WHERE nspname NOT IN ('pg_catalog', 'information_schema') AND C.relkind <> 'i' AND nspname !~ '^pg_toast' ORDER BY pg_total_relation_size (C.oid) DESC
После запуска запроса вы получите детальную информацию о каждой таблице с указанием её схемы, размера без индексов, размере индексов, суммарном размере таблицы и индексов, а также количестве строк в таблице.
Контроль блокировок
Если вашей базой данных пользуется большего одного пользователя, то всегда есть риск взаимной блокировки запросов и появления очереди с большим количеством запросов, которые будут находиться в ожидание. Чаще всего такое может возникнуть при обработке большого количества запросов, использующих одинаковые таблицы. Они будут мешать завершиться друг другу и не давать запуститься другим запросам. Больше об этом можно прочитать в официальной документации. Мы же рассмотрим способы нахождения блокировок и их снятия.
1. Мониторинг блокировок
SELECT COALESCE(blockingl.relation::regclass::text, blockingl.locktype) AS locked_item, now() - blockeda.query_start AS waiting_duration, blockeda.pid AS blocked_pid, blockeda.query AS blocked_query, blockedl.mode AS blocked_mode, blockinga.pid AS blocking_pid, blockinga.query AS blocking_query, blockingl.mode AS blocking_mode FROM pg_locks blockedl JOIN pg_stat_activity blockeda ON blockedl.pid = blockeda.pid JOIN pg_locks blockingl ON (blockingl.transactionid = blockedl.transactionid OR blockingl.relation = blockedl.relation AND blockingl.locktype = blockedl.locktype) AND blockedl.pid <> blockingl.pid JOIN pg_stat_activity blockinga ON blockingl.pid = blockinga.pid AND blockinga.datid = blockeda.datid WHERE NOT blockedl.granted AND blockinga.datname = current_database();
Данный запрос показывает всю информацию о заблокированных запросах, а также информацию о том, кем они заблокированы.
2. Снятие блокировок
SELECT pg_cancel_backend(PID_ID); OR SELECT pg_terminate_backend(PID_ID);
PID_ID - это ID запроса, который блокирует другие запросы. Чаще всего хватает отмены одного блокирующего запроса, чтобы снять блокировки и запустить всю накопившуюся очередь. Разница между pg_cancel_backend и pg_terminate_backend в том, что pg_cancel_backend отменяет запрос, а pg_terminate_backend завершает сеанс и, соответственно, закрывает подключение к базе данных. Команда pg_cancel_backend более щадящая и в большинстве случаев вам её хватит. Если нет, используем pg_terminate_backend.
Показатели оптимальной работы вашей БД
1. Коэффициент кэширования (Cache Hit Ratio)
SELECT sum(heap_blks_read) as heap_read, sum(heap_blks_hit) as heap_hit, sum(heap_blks_hit) / (sum(heap_blks_hit) + sum(heap_blks_read)) as ratio FROM pg_statio_user_tables;
Коэффициент кэширования - это показатель эффективности чтения, измеряемый долей операций чтения из кэша по сравнению с общим количеством операций чтения как с диска, так и из кэша. За исключением случаев использования хранилища данных, идеальный коэффициент кэширования составляет 99% или выше, что означает, что по крайней мере 99% операций чтения выполняются из кэша и не более 1% - с диска.
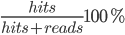
2. Использование индексов
SELECT relname, 100 * idx_scan / (seq_scan + idx_scan) percent_of_times_index_used, n_live_tup rows_in_table FROM pg_stat_user_tables WHERE seq_scan + idx_scan > 0 ORDER BY n_live_tup DESC;
Добавление индексов в вашу базу данных имеет большое значение для производительности запросов. Индексы особенно важны для больших таблиц. Этот запрос показывает количество строк в таблицах и процент времени использования индексов по сравнению с чтением без индексов. Идеальные кандидаты для добавления индекса - это таблицы размером более 10000 строк с нулевым или низким использованием индекса.
3. Коэффициент кэширования индексов (Index Cache Hit Rate)
SELECT sum(idx_blks_read) as idx_read, sum(idx_blks_hit) as idx_hit, (sum(idx_blks_hit) - sum(idx_blks_read)) / sum(idx_blks_hit) as ratio FROM pg_statio_user_indexes;
Данный коэффициент похож на обычный коэффициент кэширования, но рассчитывается на данных использования индексов.
4. Неиспользуемые индексы
SELECT schemaname, relname, indexrelname FROM pg_stat_all_indexes WHERE idx_scan = 0 and schemaname <> 'pg_toast' and schemaname <> 'pg_catalog'
Данный запрос находит индексы, которые созданы, но не использовались в SQL-запросах.
5. Раздувание базы данных (Database bloat)
SELECT current_database(), schemaname, tablename, /*reltuples::bigint, relpages::bigint, otta,*/ ROUND((CASE WHEN otta=0 THEN 0.0 ELSE sml.relpages::float/otta END)::numeric,1) AS tbloat, CASE WHEN relpages < otta THEN 0 ELSE bs*(sml.relpages-otta)::BIGINT END AS wastedbytes, iname, /*ituples::bigint, ipages::bigint, iotta,*/ ROUND((CASE WHEN iotta=0 OR ipages=0 THEN 0.0 ELSE ipages::float/iotta END)::numeric,1) AS ibloat, CASE WHEN ipages < iotta THEN 0 ELSE bs*(ipages-iotta) END AS wastedibytes FROM ( SELECT schemaname, tablename, cc.reltuples, cc.relpages, bs, CEIL((cc.reltuples*((datahdr+ma- (CASE WHEN datahdr%ma=0 THEN ma ELSE datahdr%ma END))+nullhdr2+4))/(bs-20::float)) AS otta, COALESCE(c2.relname,'?') AS iname, COALESCE(c2.reltuples,0) AS ituples, COALESCE(c2.relpages,0) AS ipages, COALESCE(CEIL((c2.reltuples*(datahdr-12))/(bs-20::float)),0) AS iotta /* very rough approximation, assumes all cols */ FROM ( SELECT ma,bs,schemaname,tablename, (datawidth+(hdr+ma-(case when hdr%ma=0 THEN ma ELSE hdr%ma END)))::numeric AS datahdr, (maxfracsum*(nullhdr+ma-(case when nullhdr%ma=0 THEN ma ELSE nullhdr%ma END))) AS nullhdr2 FROM ( SELECT schemaname, tablename, hdr, ma, bs, SUM((1-null_frac)*avg_width) AS datawidth, MAX(null_frac) AS maxfracsum, hdr+( SELECT 1+count(*)/8 FROM pg_stats s2 WHERE null_frac<>0 AND s2.schemaname = s.schemaname AND s2.tablename = s.tablename ) AS nullhdr FROM pg_stats s, ( SELECT (SELECT current_setting('block_size')::numeric) AS bs, CASE WHEN substring(v,12,3) IN ('8.0','8.1','8.2') THEN 27 ELSE 23 END AS hdr, CASE WHEN v ~ 'mingw32' THEN 8 ELSE 4 END AS ma FROM (SELECT version() AS v) AS foo ) AS constants GROUP BY 1,2,3,4,5 ) AS foo ) AS rs JOIN pg_class cc ON cc.relname = rs.tablename JOIN pg_namespace nn ON cc.relnamespace = nn.oid AND nn.nspname = rs.schemaname AND nn.nspname <> 'information_schema' LEFT JOIN pg_index i ON indrelid = cc.oid LEFT JOIN pg_class c2 ON c2.oid = i.indexrelid ) AS sml ORDER BY wastedbytes DESC;
Раздувание базы данных - это дисковое пространство, которое использовалось таблицей или индексом и доступно для повторного использования базой данных, но не было освобождено. Раздувание происходит при обновлении таблиц или индексов. Если у вас загруженная база данных с большим количеством операций удаления, раздувание может оставить много неиспользуемого пространства в вашей базе данных и повлиять на производительность, если его не убрать. Показатели wastedbytes для таблиц и wastedibytes для индексов покажет вам, есть ли у вас какие-либо серьезные проблемы с раздуванием. Для борьбы с раздуванием существует команда VACUUM.
6. Проверка запусков VACUUM
SELECT relname, last_vacuum, last_autovacuum FROM pg_stat_user_tables;
Раздувание можно уменьшить с помощью команды VACUUM, но также PostgreSQL поддерживает AUTOVACUUM. О его настройке можно прочитать тут.
Ещё несколько запросов, которые могут быть вам полезны
1. Показывает количество открытых подключений
SELECT COUNT(*) as connections, backend_type FROM pg_stat_activity where state = 'active' OR state = 'idle' GROUP BY backend_type ORDER BY connections DESC;
Показывает открытые подключения ко всем базам данных в вашем экземпляре PostgreSQL. Если у вас несколько баз данных в одном PostgreSQL, то в условие WHERE стоит добавить datname = 'Ваша_база_данных'.
2. Показывает выполняющиеся запросы
SELECT pid, age(clock_timestamp(), query_start), usename, query, state FROM pg_stat_activity WHERE state != 'idle' AND query NOT ILIKE '%pg_stat_activity%' ORDER BY query_start desc;
Показывает выполняющиеся запросы и их длительность.
Заключение
Все запросы выше собраны мной из интернета при появлении каких-либо вопросов или проблем в моей базе данных. Если есть ещё запросы, которые могут быть полезны для пользователей PostgreSQL, буду рад, если вы поделитесь ими в комментариях. Надеюсь, статья поможет вам и сохранит ваше время.

