Приветствую, коллеги.
В этой статье хочу поделиться с вами опытом построения системы мониторинга бизнес показателей в режиме реального времени, которая построена на основе сбора логов.
Перед тем, как погрузиться в технические детали, немного расскажу о причинах построения системы с такой архитектурой.
Итак, представим, что у нас имеется некоторое количество приложений, которые изначально “не обучены” отдавать аналитику в режиме реального времени. Задача заключается в том, чтобы построить систему мониторинга бизнес-показателей с минимальным вмешательством в эти системы.
Существует множество способов решить эту задачу, и как водится, все они обладают своими достоинствами и недостатками. Основное достоинство описываемого способа заключается в очень простой реализации на стороне приложения (с которого есть необходимость получать аналитику). Но если бы мы сейчас разрабатывали все те приложения, которые нужно “научить” делиться аналитикой, то мы бы, наверное, их подружили с брокером сообщений типа Kafka или Rabbit, а внедрять в уже существующие приложения работу с брокером сообщений (особенно, если брокеры очередей сообщений не развернуты в компании) значительно сложнее, чем просто научить приложения писать свои показатели в лог.
Итак, рассмотрим подробно, как устроена предлагаемая система:
В основе системы лежат события, которые генерируют приложения. События сохраняются в лог (stdout, файл,..). Обработчик (сборщик) логов (в режиме реального времени) распознает в логах события приложений и отправляет их в хранилище (БД).
Система аналитики, выполняя запросы к хранилищу, получает значения (состояние) показателей приложения.
Для того, чтобы было возможным из лога выделить события приложений, сохранять их нужно в специальном формате. Мы будем использовать следующий шаблон для сохранения событий:
<event>{"payload":"some data"}</event>
Т.е. наши события будут передаваться в лог в виде JSON обернутого в тег event.
Для наглядности приведем пример строки лога, содержащего событие (форматирование добавлено для читаемости):
2022-10-11T21:37:48.055Z [app] info: <event>{ "source":"WMS", "event":"order_assembly_start", "data":{"order_id": 101, "employee_id": 10, "sku_count": 5, "sku_weight": 1450, "sku_volume": 500 } }</event>
Общая архитектура решения выглядит следующим образом:

Поскольку система предполагает обработку логов приложений для извлечения событий и отправки их в хранилище, то бонусом к системе аналитики мы также можем получить централизованное хранилище логов, которое можно рассматривать как некоторую альтернативу ELK.
Техническая реализация
Далее мы реализуем тестовый стенд для демонстрации работы предлагаемой системы. Для того, чтобы стенд было проще воспроизвести, все его части мы будем разворачивать в Docker контейнерах.
Наша реализация будет построена на следующих Open Source продуктах:
Vector - сборщик логов с возможностями ETL
ClickHouse - OLAP база данных от Яндекс
Grafana - платформа для визуализации данных и алертинга
В качестве примера наш стенд будет обрабатывать события из абстрактной WMS системы, которая посылает события о начале и завершении сбора заказа. Задача разрабатываемой системы заключается в том, чтобы отображать количество заказов, которые находятся в обработке в текущий момент и в динамике.
Напишем скрипт на NodeJS, который будет имитировать работу WMS системы.
Его задача с некоторой периодичностью писать в лог события начала и завершения сборки заказа. События записываемые в лог будут иметь следующий формат:
Для события начала сборки заказа:
<event>{ "source":"WMS", "event":"order_assembly_start", "data":{ "order_id": 101, "employee_id": 10, "sku_count": 5, "sku_weight": 1450, "sku_volume": 500 } }</event>
Для события завершения сборки заказа:
<event> { "source":"WMS", "event":"order_assembly_end", "data":{ "order_id": 101 } } </event>
Как видно из примера события имеют одинаковую структуру и содержат следующие поля:
source - источник события (приложение)
event - тип события
data - объект с данными произошедшего события.
Теперь приведем код скрипта на JavaScript генерирующего события:
index.js
'use strict' const fs = require('fs'); const log_file = fs.createWriteStream(__dirname + '/../logs/demo-app.log', {flags : 'w'}); const log_stdout = process.stdout; const randomInteger = (min, max) => Math.floor(Math.random() * (max - min + 1)) + min; const sleep = (ms)=>new Promise(res => setTimeout(res, ms)); console.mon = function(d, service='app', level='info') { // const mess = typeof(d)==="string" ? d : `<event>${JSON.stringify(d)}</event>`; const out = `${new Date().toISOString()} [${service}] ${level}: ${mess}\n`; log_file.write(out); log_stdout.write(out); }; async function emulateWork(){ const processOrder = function (orderId, employee_id, sku_count, sku_weight, sku_volume){ const orderObjAssembly = { source: 'WMS', event: 'order_assembly_start', data: { order_id: orderId, employee_id, sku_count, sku_weight, sku_volume } } console.mon(orderObjAssembly); orderObjAssembly.event = 'order_assembly_end'; orderObjAssembly.data = {order_id: orderId} setTimeout(()=>console.mon(orderObjAssembly), randomInteger(1,10)*1000); } let iteration = 0; while (true){ console.mon(`iteration ${++iteration}`); //orderId, employee_id, sku_count, sku_weight, sku_volume processOrder(iteration, randomInteger(1,10), randomInteger(1,50), randomInteger(100,1000), randomInteger(1000,10000)); await sleep(1000); } } emulateWork();
Вкратце о том, что делает приведенный выше код:
Функция console.mon пишет данные в лог файл ./logs/demo-app.log,
В случае, если в функцию передается объект, то он записывается в лог в виде JSON и оборачивается в тег event.
Функция emulateWork имитирует поступление заказов, она каждую секунду генерирует поступление нового заказ который обрабатывается от 1 до 10 секунд.
Для того, чтобы запустить этот скрипт в Docker, подготовим docker-compose.yml конфиг:
docker-compose.yml
version: '3.8' services: main: container_name: business-system-simulation image: node:lts-alpine working_dir: /home/node/app user: "node" volumes: - ./:/home/node/app - ./logs/:/home/node/app/logs:rw command: npm run start restart: always
Запустим docker контейнер выполнив команду:
> docker compose up
Если все сделано правильно, то в консоле должны начать отображаться сообщения записываемые в лог:

С приложением генерирующего логи мы закончили, теперь давайте настроим сборщик логов.
В качестве сборщика логов мы будем использовать Vector, с подробной документацией его возможностей и настройке можно ознакомится на официальном сайте приложения. Представляет он из себя ETL конвейер, задача которого состоит в том, чтобы из некоторого источника получить данные (extract), если нужно как то их преобразовать (transform) и загрузить в некоторую систему назначения (load).
Каждая такая задача извлечения, преобразования, отправки описывается в конфигурационном файле сборщика и оформляется в виде секций. Название секций заключены в квадратные скобки и должны иметь следующие префиксы:
[sources.section_name] - для описания источника данных,
[transforms.section_name] - для описания трансформации данных
[sinks.section_name] - для описания места назначения (загрузки) данных.
Рассмотрим пример конфигурации сборщика:
vector.toml
[sources.debug_logs] # откуда сборщику логов брать данные. type = "demo_logs" # в качестве источника логов будут использоваться демо данные, подробнее: https://vector.dev/docs/reference/configuration/sources/demo_logs/ format = "shuffle" count = 3 lines = [ # массив демо данных '2022-10-11T21:37:48.055Z [app] info: <event>{"source":"WMS","event":"order_assembly_start","data":{"order_id":1,"target":1}}</event>', '2022-10-11T21:37:56.056Z [app] info: <event>{"source":"WMS","event":"order_assembly_end","data":{"order_id":1,"target":1}}</event>' ] [transforms.remap_debug_logs] # Секция настроек описывающая трансформацию данных inputs = ["debug_logs"] # Входные данные, ссылается на выше описанную секцию type = "remap" # задает тип трансформации, документация: https://vector.dev/docs/reference/configuration/transforms/ file="/etc/vector/transform.vrl" # ссылка на файл с алгоритмом преобразования данных [sinks.emit_debug_logs] # секция настроек описывающая место назначения inputs = ["remap_debug_logs"] # Входные данные, результат работы предыдущей секции type = "console" # Тип назначения (в консоль), документация: https://vector.dev/docs/reference/configuration/sinks/ encoding.codec = "json" # формат вывода данных
В этом примере в качестве источника данных используется несколько тестовых строк, которые прописаны непосредственно в конфигурационном файле, а в качестве места назначения логов используется вывод в консоль. Данные в нее выводятся в формате JSON. Это пример не использует каких-то внешних источников данных и нужен для того, чтобы разобраться с тем, как выполняется настройка сборщика, а также этот пример может помочь при отладке сборщика.
Как видно из конфигурации сборщика секция, которая отвечает за трансформацию данных [transforms.remap_debug_logs], ссылается на файл transform.vrl. В этом файле описан алгоритм преобразования данных. Каждая строка лога обрабатываемая сборщиком будет проходить через алгоритм трансформации описанный в этот файле.
Алгоритмы трансформации в сборщике логов Vector пишутся на языке Vector Remap Language, ознакомится с ним можно на странице документации.
Ниже приведен код скрипта трансформации:
transform.vrl
#transform.vrl .source= "" .event = "" .data = "" structured, err = parse_regex(.message, r'(<event>)(?P<event>.*?)(</event>)', numeric_groups: false) if err == null{ json, err_json = parse_json(structured.event) if err_json == null { .source= json.source .event = json.event .data = encode_json(json.data) } }
Входные данные поступают в скрипт через переменную “.”. Эта переменная представляет из себя именованный массив, поля которого содержат данные передаваемые из источника данных.
В зависимости от типа источника данных набор этих полей может отличаться.
Данные возвращаемые скриптом трансформации также должны быть помещены в поля переменной “.”.
В нашем примере во входных данных (переменная “.”) содержится три поля:
“message” - содержит обрабатываемую строку лога,
“source_type” - тип источника входных данных, в нашем примере она содержит строку “demo_logs”,
“timestamp” - метка времени сборщика логов, время когда сборщик логов считал данные.
Опишем алгоритм этого скрипта:
Первым делом к объекту потока данных (переменной “.”) добавляем поля source, event, data - эти поля мы будем заполнять данными для системы мониторинга (в том случае если они были обнаружены в строке лога).
С помощью регулярного выражения из строки лога выделяем подстроку, содержащуюся внутри тега event и помещаем ее в поле event именованного массива structured, т.е. structured.event у нас содержится JSON, переданный в лог через тег event.
Далее мы преобразуем полученную JSON строку в объект и извлекаем из него поля source, event и data и помещаем их в наш объект с данными переменную “.”. В результате работы скрипта на выходе процесса преобразования (переменной “.”) мы получаем дополнительные поля “source”, “event” и “data”, в которых содержаться данные для системы мониторинга, если таковые были записаны в лог.
Подготовим конфигурацию docker контейнера для запуска нашего сборщика:
docker-compose.yml
#docker-compose.yml version: "3.9" services: vector_agent: image: timberio/vector:0.23.X-alpine container_name: vector_agent volumes: - ./vector.toml:/etc/vector/vector.toml:ro - ./transform.vrl:/etc/vector/transform.vrl:ro
Запустим docker контейнер, выполнив команду:
> docker compose up
В результате мы в консоль должны получить примерно такие сообщения:
business-system-simulation | 2022-10-28T06:59:22.384Z [app] info: <event>{"source":"WMS","event":"order_assembly_start","data":{"order_id":45,"employee_id":2,"sku_count":22,"sku_weight":491,"sku_volume":1523}}</event>
Теперь давайте “скормим” нашему сборщику логи, которые генерирует наше тестовое приложение, для этого изменим его конфигурацию. Нам требуется изменить секцию входных данных [sources.debug_logs], настроив ее таким образом, чтобы на вход сборщику подавался файл с логом приложения:
vector.toml
[sources.debug_logs] type = "file" include = ["/logs/*.log"] [transforms.remap_debug_logs] inputs = ["debug_logs"] type = "remap" file="/etc/vector/transform.vrl" [sinks.emit_debug_logs] inputs = ["remap_debug_logs"] type = "console" encoding.codec = "json"
Подключим папку с логами нашего тестового приложения к docker контейнеру сборщика логов:
docker-compose.yml
#docker-compose.yml version: "3.9" services: vector_agent: image: timberio/vector:0.23.X-alpine container_name: vector_agent volumes: - ./vector.toml:/etc/vector/vector.toml:ro - ./transform.vrl:/etc/vector/transform.vrl:ro - ./../business-system-simulation/logs/:/logs/
Теперь наш сборщик логов должен выводить в консоль данные, которые пишутся в лог приложения:
Сообщение в консоль
{ "data": "{\"order_id\":70,\"target\":1}", "event": "order_assembly_end", "file": "/logs/demo-app.log", "host": "bba028090efe", "message": "2022-10-12T04:36:31.762Z [app] info: <event>{\"source\":\"WMS\",\"event\":\"order_assembly_end\",\"data\":{\"order_id\":70,\"target\":1}}</event>", "source_type": "file", "timestamp": "2022-10-12T04:36:31.967280549Z" }
Как вы наверное могли заметить, после смены источника данных в получаемых данных (переменной “.”) добавилось два дополнительных поля “file” и “host”, в которых соответственно находится ссылка на файл, с которого считывается лог и имя ПК.
Отложим ненадолго наш сборщик логов и создадим docker конфиг для нашей системы хранения ClickHouse:
docker-compose.yml
version: '3.7' services: ClickHouse-Server: image: yandex/clickhouse-server container_name: ClickHouse ports: - "8123:8123" - "9000:9000" volumes: - ./db:/var/lib/clickhouse # - ./users.xml:/etc/clickhouse-server/users.xml:rw
Запустим контейнер:
> docker compose up
Для дальнейшей работы нам понадобится в ClickHouse создать трех пользователей:
admin - админская учетная запись для управленя (полные права)
agent - учетная запись для сборщиков логов (доступ на добавление новых записей)
monitoring - учетная запись для мониторинга, будет использоваться Grafana (доступ только чтение)
По умолчанию в ClickHouse присутствует только пользователь default с пустым паролем и у этого пользователя нет прав на управление пользователями и ролями через запросы SQL. Для того что чтобы добавить эти права согласно документации, необходимо включить соответствующую настройку у пользователя в файле users.xml. Данный файл размещен внутри контейнера ClickHouse /etc/clickhouse-server/users.xml. Для удобства работы с этим файлом мы перенесем его из контейнера к себе на хост и пропишем ссылку на него из хоста в контейнер. Для того, чтобы скопировать файл из контейнера на хост, выполним команду:
> docker cp ClickHouse:/etc/clickhouse-server/users.xml /docker_folder_patch/users.xml
Прокинем ссылку на файл users.yml из хоста в docker контейнер, прописав в docker-compose.yml в разделе volumes ссылку:
- ./users.xml:/etc/clickhouse-server/users.xml
Теперь раскомментируем в файле users.xml у пользователя default настройку access_management, сохраним файл и перезапускаем ClickHouse выполнив команду:
> docker-compose restart
Перейдем к созданию пользователей, для подключения к базе данных можно воспользоваться менеджером баз данных DBeaver или любым другим, в наборе которого присутствует драйвер подключения к ClickHouse.
Для подключения используем:
адрес сервера: localhost
порт: 8123
имя пользователя: default
Подключившись к серверу ClickHouse выполним запрос:
> SHOW USERS
если в ответ получили:
default
значит у нашего пользователя есть необходимые привилегии и можно приступать к созданию пользователей.
Создадим пользователя admin в нашем случае с паролем qwerty:
> CREATE USER admin IDENTIFIED WITH sha256_password BY 'qwerty';
И назначим ему полные права:
> GRANT ALL ON *.* TO admin WITH GRANT OPTION
Теперь когда у нас есть админская учетная запись, “обезвредим” учетную запись default. Для этого отредактируем файл users.xml: Комментируем обратно у пользователя default опцию access_management, а в опции password пропишем пароль.
Следующие запросы выполняем под пользователем admin, которого ранее создали.
Создадим базу данных log_storage для хранения логов:
> CREATE DATABASE IF NOT EXISTS log_storage
Добавим пользователя agent:
> CREATE USER agent IDENTIFIED WITH sha256_password BY 'qwerty';
установим ему права на чтение и запись в базе log_storage:
> GRANT INSERT ON log_storage.* TO agent
> GRANT SELECT ON log_storage.* TO agent
Добавим пользователя monitoring:
> CREATE USER monitoring IDENTIFIED WITH sha256_password BY 'qwerty';
Установим ему права только на чтение из базы log_storage:
>GRANT SELECT ON log_storage.* TO monitoring
Для того чтобы проверить, какие права каким пользователям назначены, выполним запрос:
> SHOW ACCESS
На этом базовая настройка ClickHouse завершена.
Для дальнейшей настройки сборщика логов нам нужно создать таблицы, в которых будут храниться данные, получаемые из логов. Создадим таблицу “logs_event”, в ней будут храниться события приложений:
logs_event
CREATE TABLE log_storage.logs_event( `timestamp` DateTime, `source_type` String, `host` String, `source` String, `event` String, `data` String) ENGINE = MergeTree() PARTITION BY toYYYYMM(timestamp) ORDER BY (timestamp, source_type, host, source, event);
А также создадим таблицу “logs_app”, в ней будут храниться обычные логи приложений:
logs_app
CREATE TABLE log_storage.logs_app( `timestamp` DateTime, `source_type` String, `host` String, `message` String) ENGINE = MergeTree() PARTITION BY toYYYYMM(timestamp) ORDER BY (timestamp, source_type, host);
Теперь поменяем конфигурацию нашего сборщика, чтобы он отправлял в clickhouse логи приложения в таблицу “logs_app”, а события приложения в таблицу “logs_event”:
vector.toml
[sources.app_logs] # эта секция описывает настройки того откуда сборщику логов брать данные. type = "file" include = ["/logs/*.log"] [transforms.remap_app_logs] # Секция настроек описывающая трансформацию данных inputs = ["app_logs"] # Входные данные, ссылается на выше описанную секцию type = "remap" # задает тип трансформации, документация: https://vector.dev/docs/reference/configuration/transforms/ file="/etc/vector/transform.vrl" # ссылка на файл с алгоритмом преобразования данных [transforms.filter_events] # Секция фильтрации событий inputs = ["remap_app_logs"] type = "filter" condition = '.event != ""' [transforms.filter_logs] # Секция фильтрации лога приложения inputs = ["remap_app_logs"] type = "filter" condition = '.event == ""' [sinks.emit_events] # секция описывающая место доставки событий приложения type = "clickhouse" inputs = ["filter_events"] endpoint = "http://192.168.229.133:8123" auth.strategy = "basic" auth.user = "agent" auth.password = "qwerty" database = "log_storage" table = "logs_event" skip_unknown_fields = true encoding.timestamp_format = "unix" batch.max_events = 100 batch.timeout_secs = 5 [sinks.emit_logs] # секция описывающая место доставки логов приложения type = "clickhouse" inputs = ["filter_logs"] endpoint = "http://192.168.229.133:8123" auth.strategy = "basic" auth.user = "agent" auth.password = "qwerty" database = "log_storage" table = "logs_app" skip_unknown_fields = true encoding.timestamp_format = "unix" batch.max_events = 100 batch.timeout_secs = 5
Для наглядности приведем схему ETL процесса, описанной в конфигурации:

Опишем конфигурацию сборщика: в секции [sources.app_logs] содержится настройка, откуда забирать логи приложений. Данные логов, полученные из секции [sources.app_logs] поступают для преобразования в секцию [transforms.remap_app_logs] и в случае, если строка лога содержит событие (данные обернутые в тег event), то данные этого события извлекаются из строки лога и выносятся в отдельные поля source, event, data. После процесса преобразования данные лога поступают на фильтры [transforms.filter_events] и [transforms.filter_logs], задача которых состоит в том, чтобы разделить поток данных на два. На выходе [transforms.filter_events] будут содержаться только события приложений, а на выходе фильтра [transforms.filter_logs] только обычные логи. Определение того, является ли обрабатываемые данные событием или строкой лога, происходит по данным поля “event” которое заполняется именем события на этапе трансформации данных в секции [transforms.remap_app_logs] в результате работы скрипта “transform.vrl”.
Далее данные, прошедшие через фильтр [transforms.filter_events], направляются в хранилище описанное в секции [sinks.emit_events], а данные прошедшие через фильтр [transforms.filter_logs] направляются в хранилище описанное в секции [sinks.emit_logs].
В секциях настройки хранилищ описываются настройки подключения к базе данных ClickHouse и то, в какие таблицы будут доставляться данные. Хочется обратить особое внимание на следующие настройки хранилищ:
batch.max_events = 100
batch.timeout_secs = 5
Эти настройки заставляют сборщик логов выступать в роли буфера данных. Т.е. как видно из названия настроек, данные в хранилище будут отправляться раз в пять секунд или раньше, если накопится 100 элементов для отправки. Делается это для оптимизации работы ClickHouse, поскольку он отлично справляется с вставкой данных “пачками”, но крайне не любит “построчную” вставку.
Для того чтобы проверить, что все работает, запустим все наши контейнеры,после чего
выполним SQL запрос (например воспользовавшись DBeaver) к хранилищу ClickHouse:
> SELECT * FROM log_storage.logs_event LIMIT 10
Если все сделано правильно и события из приложения передаются в хранилище, то мы должны получить примерно такой результат:

Итак, мы настроили наш сборщик на передачу событий и логов приложения в ClickHouse, но данные событий хранятся сериализованные в JSON, что не очень пригодно. Для извлечения данных из JSON у ClickHouse есть специальный набор функций. Воспользуемся ими для того, чтобы извлечь данные, хранящиеся в событиях:
Пример SQL
SELECT `timestamp`, `source`, `event`, JSONExtract(data, 'order_id', 'Int') AS order_id, JSONExtract(data, 'employee_id', 'Int') AS employee_id, JSONExtract(data, 'sku_count', 'Int') AS sku_count, JSONExtract(data, 'sku_volume', 'Int') AS sku_volume, JSONExtract(data, 'sku_weight', 'Int') AS sku_weight FROM log_storage.logs_event WHERE event ='order_assembly_start' LIMIT 10
В результате получим данные, извлеченные из JSON и помещенные в одноименные колонки:

Для того, чтобы не писать такие громоздкие запросы, можно создать представление (view):
Пример создания View
CREATE VIEW log_storage.event_order_assembly_start__view AS SELECT `timestamp`, `source`, `event`, JSONExtract(data, 'order_id', 'Int') AS order_id, JSONExtract(data, 'employee_id', 'Int') AS employee_id, JSONExtract(data, 'sku_count', 'Int') AS sku_count, JSONExtract(data, 'sku_volume', 'Int') AS sku_volume, JSONExtract(data, 'sku_weight', 'Int') AS sku_weight FROM log_storage.logs_event WHERE event ='order_assembly_start'
И теперь, написав запрос к представлению, мы получим аналогичный результат:
Запрос к View
SELECT `timestamp`, `source`, `event`, order_id, employee_id, sku_count, sku_volume,sku_weight FROM event_order_assembly_start__view LIMIT 10
Минус использования таких представлений заключается в том, что если мы будем использовать в запросах условия по полям, которые хранятся в JSON, то движку базы данных придется сканировать все записи, содержащиеся в таблице-первоисточнике для проверки на условия запроса, что мягко говоря не самым лучшим образом скажется на производительности. Поэтому хорошим решением будет использовать материализованные представления, поскольку такой вид представления фактически создает полноценную таблицу с данными описанных в запросе создания представления.
Создадим материализованное представление для события “order_assembly_start” :
Создание материализованного представления для события order_assembly_start
CREATE MATERIALIZED VIEW log_storage.event__order_assembly_start ENGINE = MergeTree() PARTITION BY toYYYYMM(timestamp) ORDER BY (timestamp, order_id, employee_id) POPULATE AS SELECT `timestamp`, `source`, `event`, JSONExtract(data, 'order_id', 'Int') AS order_id, JSONExtract(data, 'employee_id', 'Int') AS employee_id, JSONExtract(data, 'sku_count', 'Int') AS sku_count, JSONExtract(data, 'sku_volume', 'Int') AS sku_volume, JSONExtract(data, 'sku_weight', 'Int') AS sku_weight FROM log_storage.logs_event WHERE event ='order_assembly_start'
А также создадим материализованное представление для события “order_assembly_end”:
Создание материализованного представления для события order_assembly_end
CREATE MATERIALIZED VIEW log_storage.event__order_assembly_end ENGINE = MergeTree() PARTITION BY toYYYYMM(timestamp) ORDER BY (timestamp, order_id) POPULATE AS SELECT `timestamp`, `source`, `event`, JSONExtract(data, 'order_id', 'Int') AS order_id FROM log_storage.logs_event WHERE event ='order_assembly_end'
В результате события о начале и завершении сборки заказов будут храниться в представлениях “event__order_assembly_start” и “event__order_assembly_end”.
Возможно, в каких-то случаях будет лучше делать маппинг данных событий в таблицу назначения с помощью сборщика логов. В нашем случае тогда извлечение данных из события происходило бы на уровне скрипта трансформации данных и имело бы следующий вид:
transform.vrl
.source= .event = "" structured, err = parse_regex(.message, r'(<event>)(?P<event>.*?)(</event>)', numeric_groups: false) if err == null{ json, err_json = parse_json(structured.event) if err_json == null { .source = json.source .event = json.event .order_id = json.data.order_id .employee_id= json.data.employee_id .sku_count = json.data.sku_count .sku_volume = json.data.sku_volume .sku_weight = json.data.sku_weight } }
и таблица для доставки данных, соответственно, должна была бы иметь все необходимые колонки. Такой способ будет предпочтителен в том случае, если мы извлекаем только один вид события из одного приложения. Но в случае большого количества приложений и видов событий поддержка скриптов трансформации станет трудоемкой задачей. Поэтому мы “сливаем” в clickhouse данные в виде JSON и уже на стороне clickhouse централизованно делаем маппинг данных событий при помощи материализованных представлений.
Создание дашборда в Grafana
Прежде всего подготовим конфигурацию docker контейнера для запуска Grafana:
docker-compose.yml
version: '3.7' services: grafana: container_name: grafana image: grafana/grafana-enterprise:9.2.0-ubuntu environment: - GF_SECURITY_ADMIN_USER=admin - GF_SECURITY_ADMIN_PASSWORD=admin volumes: - ./provisioning/dashboards:/etc/grafana/provisioning/dashboards - ./provisioning/datasources:/etc/grafana/provisioning/datasources ports: - "3000:3000" restart: unless-stopped
Запустим docker контейнер
> docker compose up
Откроем в браузере адрес http://localhost:3000
Авторизация в Grafana, введя логин и пароль admin
Создадим в Grafana источник данных Clickhouse, но поскольку Grafana “из коробки” не поддерживает ClickHouse, сначала нужно установить плагин, который добавит к Grafana возможность работать с ClickHouse. Итак, переходим в Configuration -> Plugins
И в строке поиска вводим Clickhouse, из результатов поиска выбираем плагин ClickHouse и нажимаем Install:
Теперь Grafana поддерживает работу с ClickHouse. Создадим источник данных для работы с нашим хранилищем, для этого перейдем в Configuration -> Data sources
и нажмем кнопку Add data source, после чего в строке поиска введем Clickhouse и из предложенного результата выберем ClickHouse:

В открывшемся диалоге настроим соединение с ClickHouse, для этого введем следующие настройки:
Server address: вводим ip своего хоста
Server port: 9000
Username: monitoring
Password: qwerty
Default database: log_storage
Остальные настройки оставим с значениями по умолчанию.
Нажмем кнопку “Save & test”, и если все сделано правильно, то должно появиться сообщение “Data source is working”:

Проверим работу соединения с clickhouse, для этого перейдем в раздел Explore
и установим настройки, как показано на изображении:

И нажмем кнопку Run query. Если все сделано правильно, то в нижней части страницы отобразится таблица с данными из ClickHouse.
Теперь напишем запрос, который будет выводить динамику количества заказов, находящихся в отборке за указанный период времени:
Запрос получения количества заказов в динамике
WITH toStartOfDay(toDate('2022-10-20')) AS startDate, toStartOfDay(toDate('2022-10-21')) AS endDate, 60 AS time_interval, (SELECT groupArray((timestamp, order_id)) FROM log_storage.event__order_assembly_start WHERE timestamp BETWEEN date_add(DAY, -1, startDate) AND endDate) AS oredrs_start, (SELECT groupArray((timestamp, order_id)) FROM log_storage.event__order_assembly_end WHERE timestamp BETWEEN date_add(DAY, -1, startDate) AND endDate) AS oredrs_end SELECT time, assemble FROM ( SELECT time_series.time as time, arrayMap(x->x.2, arrayFilter(x -> x.1 <= time, oredrs_start)) as orders_id_start, arrayMap(x->x.2, arrayFilter(x -> x.1 <= time, oredrs_end)) as orders_id_end, arrayIntersect(orders_id_start, orders_id_end) as orders_intersect, length(orders_id_start) as orders_id_start_lengtht, length(orders_intersect) as orders_intersect_length, orders_id_start_lengtht - orders_intersect_length as assemble FROM (SELECT arrayJoin(arrayMap(x -> toDateTime(x), range(toUInt32(startDate), toUInt32(endDate), time_interval))) time) time_series )
В секции WITH задаются параметры запроса:
startDate - содержит начало периода,
endDate - содержит конец периода,
time_interval - периодичность в секундах через которые нужно делать срезы данных.
В результате выполнения запроса должны получить данные следующего вида:
Пример результата запроса
time |assemble| -------------------+--------+ 2022-10-21 01:16:00| 3| 2022-10-21 01:17:00| 6| 2022-10-21 01:18:00| 5|
Теперь давайте создадим дашбоард в Grafana для того, чтобы отобразить эти данные в виде графика.
Для этого в Grafana воспользуемся меню Dashboards -> New dashboard

В открывшемся диалоге выбираем “Add new panel”.
И приступим к настройке виджета. По умолчанию виджет имеет тип Time series, оставим его как есть. Выберем в качестве источника данных (Data source) ранее нами созданный источник данных ClickHouse.
Теперь нужно написать запрос ,результат которого мы хотим отображать на графике.
Для виджета Time series запрос должен возвращать в первой колонке дату и время (метку времени), а во второй и последующих колонках - значения временных меток.
Коннектор ClickHouse позволяет настраивать запрос в двух режимах “Query Builder” и “SQL Editor”. Переключимся в режим “SQL editor” и введем в поле запроса запрос, который ранее мы уже использовали для отображения динамики собираемых заказов.
Для того, чтобы данные запрашивались согласно выбранного в Grafana периоде в запросе, нужно использовать макроподстановки. Их задача передать в запрос параметры, которые выбраны в интерфейсе Grafana. Подробнее о возможных макро выражениях, которые доступны для коннектора clickhouse, можно ознакомиться в документации.
В нашем запросе в секции WITH определены параметры: startDate, endDate и time_interval
WITH
toStartOfDay(toDate('2022-10-20')) AS startDate,
toStartOfDay(toDate('2022-10-21')) AS endDate,
60 AS time_interval,
Заменим их статические значения на макро-выражения:
WITH
$__fromTime AS startDate,
$__toTime AS endDate,
$__interval_s AS time_interval,
Нажмем кнопку Run query для того, чтобы выполнить запрос.
Если все сделано правильно, то на виджете отобразится график с динамикой собираемых заказов:

Нажмем кнопку Apply для того, чтобы завершить настройку виджета.
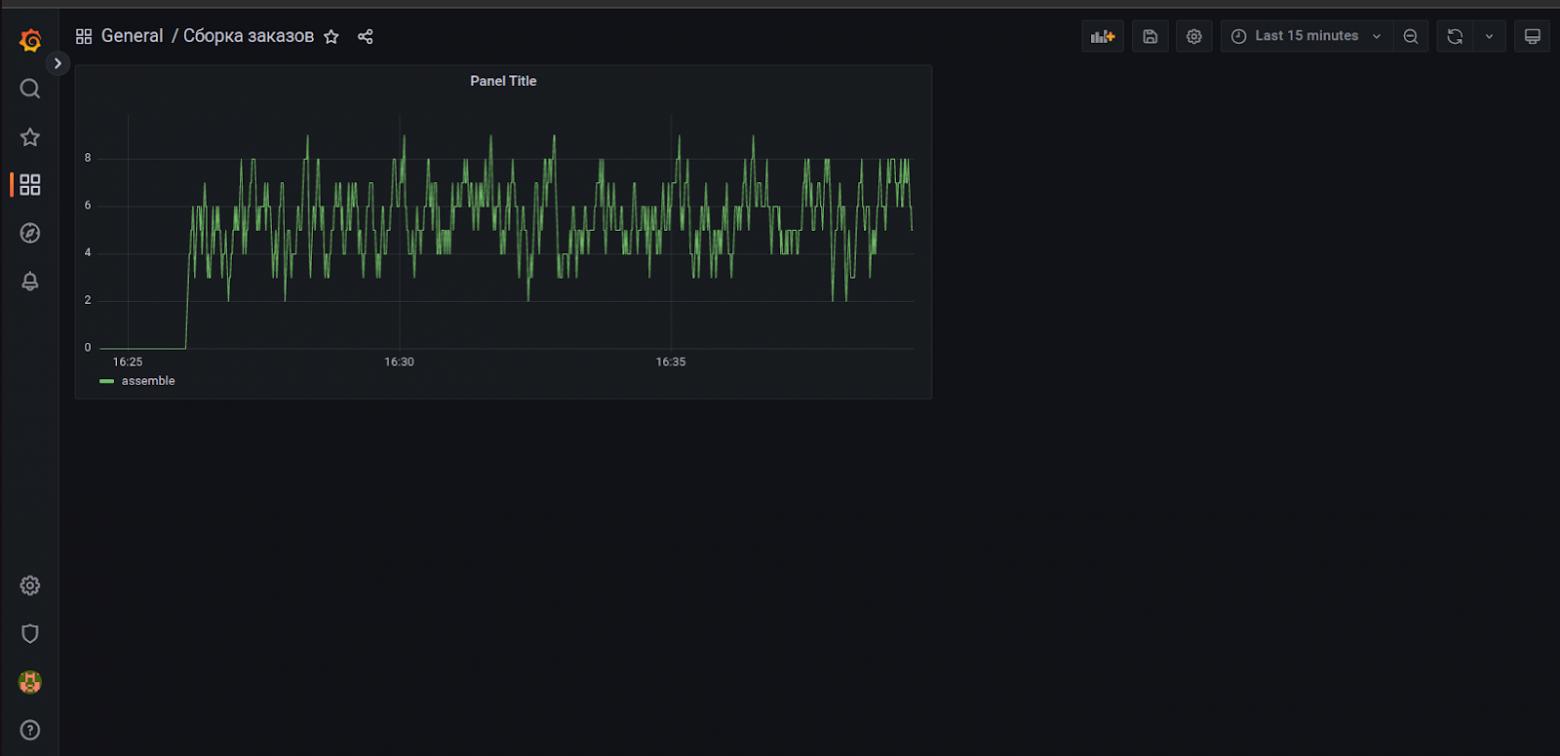
Добавим еще один виджет для отображения количества заказов, которые на текущий момент находятся в сборке. Тип виджета выберем “Gauge”, и в качестве запроса введем:
SQL запрос для виджета Guage
WITH $__fromTime AS startDate, $__toTime AS endDate, (SELECT groupArray((timestamp, order_id)) FROM log_storage.event__order_assembly_start WHERE timestamp BETWEEN date_add(DAY, -1, startDate) AND endDate) AS oredrs_start, (SELECT groupArray((timestamp, order_id)) FROM log_storage.event__order_assembly_end WHERE timestamp BETWEEN date_add(DAY, -1, startDate) AND endDate) AS oredrs_end SELECT assemble FROM ( SELECT arrayMap(x->x.2, arrayFilter(x -> x.1 <= endDate, oredrs_start)) as orders_id_start, arrayMap(x->x.2, arrayFilter(x -> x.1 <= endDate, oredrs_end)) as orders_id_end, arrayIntersect(orders_id_start, orders_id_end) as orders_intersect, length(orders_id_start) as orders_id_start_lengtht, length(orders_intersect) as orders_intersect_length, orders_id_start_lengtht - orders_intersect_length as assemble )
Сохраним и на дашборде получим примерно следующий результат:

Пожалуй, на этом закончим работу с Grafana, данные из приложения мы получили и вывели на дашборд, а наводить красоту можно бесконечно долго, что выходит за рамки этой статьи.
На что хотелось бы еще обратить внимание - так это на то, что работоспособность наших сборщиков нужно контролировать, и для этого у Vector есть возможность отправки своих метрик в Prometheus.
Также хочется отметить, что поскольку наше тестовое приложение работает в docker контейнере, а логирумые данные в том числе передаются в stdout, то мы можем в качестве источника данных для сборщика логов использовать docker logs, что сильно упрощает сборку логов и избавляет нас от необходимости писать логи в файл. При использовании этого источника данных во входной переменной потока данных “.” добавляются поля “container_name” и “stream” и их, соответственно, нужно добавить в таблицу назначения данных лога.
Часто системы сбора логов строятся с использованием брокеров очередей. Обычно это Kafka, в нашем тестовом стенде мы не стали этого делать, чтобы не усложнять систему, но добавить в наш систему Kafka достаточно просто поскольку используемый в нашем стенде сборщик логов Vector имеет возможность отправлять данные в Kafka, а в Clickhouse есть специальный движок таблиц, предназначенный для загрузки данных из Kafka.
Тут наверное должно быть заключение. Напишу его наверное после того как ознакомлюсь с вашей конструктивной критикой :)
GitHub с исходниками.

