При работе с инструментом важно знать теоретические основы. Во-первых, вам будет значительно проще искать ответы на вопросы в Google и понимать официальную документацию. Во-вторых, при обращении в профильные чаты вы будете называть вещи своими именами, что позволит быстрее получить ответ (или вообще получить его: если ваши слова и термины будут непонятны другим, вряд ли они смогут ответить на вопрос).
Алексей Барабанов, IT-директор «Хлебница» и спикер курса «RabbitMQ для админов и разработчиков», подготовил конспект, который поможет понять терминологию и базовые сущности RabbitMQ.

Другие конспекты:
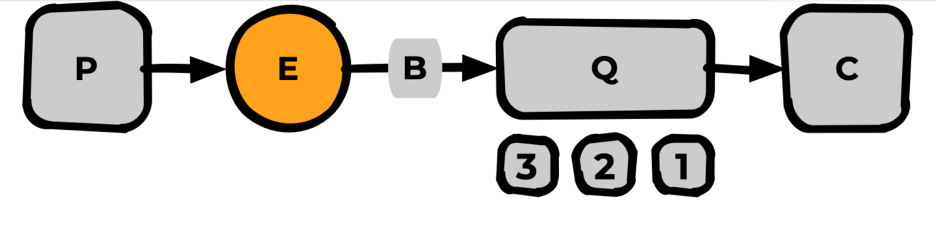
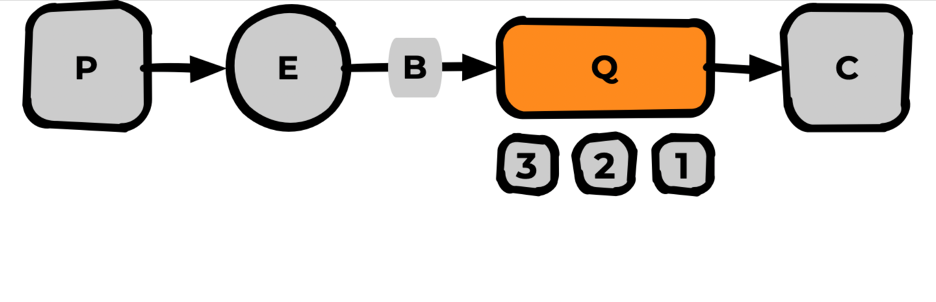
Базовая схема всех сущностей RabbitMQ

Пробежимся по названиям слева направо:
Publisher — публикует (паблишит) сообщения в Rabbit.
Exchange — обменник. Сущность Rabbit, точка входа для публикации всех сообщений.
Binding — связь между Exchange и очередью.
Queue — очередь для хранения сообщений.
Messages — сообщение, атомарная сущность.
Consumer — подписывается на очередь и получает от Rabbit сообщения.
Также встречаются термины:
Publishing — процесс публикования сообщений в обменник.
Consuming — процесс подписывания consumer ***на очередь и получение им сообщений.
Routing Key — свойство Binding.
Persistent — свойство сохранения данных при перезагрузке сервиса (также известное как стейт).
Publisher

Внешнее приложение (крон/вебсервис/что угодно), генерирующее сообщения в RabbitMQ для дальнейшей обработки.
Создаёт соединение (connection) по протоколу AMQP, в рамках соединения создаёт канал (channel). В рамках одного соединения можно создать несколько каналов, но это не рекомендуется даже официальной документацией RabbitMQ.
«Флаппинг» каналов: если Publisher для каждого сообщения создаёт соединение, канал, отправляет сообщение, закрывает канал, закрывает соединение, это очень плохая история. Rabbit становится плохо уже на ~300 таких пересозданий каналов в секунду. Будьте внимательны. Если нет возможности изменить Publisher, можно использовать amqproxy.
Важное замечание: не следует использовать amqproxy для consumer, есть проблемы одностороннего разрушения соединений.
Publisher может декларировать практически все сущности — exchanges, queues, bindings и др. На практике лучше подходит стратегия декларирования всех нужных сущностей consumer, но решать нужно для каждого проекта индивидуально.
Publisher всегда пишет в exchange. Даже если вы думаете, что он пишет напрямую в очередь, это не так. Он пишет в служебный exchange с routing key, совпадающим с названием очереди.
Publisher определяет delivery_mode для каждого сообщения — так называемый «признак персистентности». Это значит, что сообщение будет сохранено на диске и не исчезнет в случае перезагрузки Rabbit.
delivery_mode=1 — не хранить сообщения, быстрее.
delivery_mode=2 — хранить сообщения на диске, медленнее, но надёжнее.
Также publisher определяет Routing Key для каждого сообщения — признак, по которому идёт дальнейшая маршрутизация в Rabbit.

«RabbitMQ для админов и разработчиков»
Publisher может выставлять confirm флаг — отправлять указания Rabbitmq через отдельный канал подтверждения об успешной приёмке сообщений. Например, если у Rabbit закончится место на диске, то некоторое время он ещё будет принимать сообщения от Publisher. Publisher будет думать, что всё в порядке, хотя сообщения с высокой долей вероятности не дойдут до Consumer и не сохранятся в очереди для дальнейшей обработки. Полезная вещь, но ощутимо снижает скорость работы и сложно реализуема в однопоточных языках разработки.
Также есть флаг mandatory — указание Rabbit складировать сообщения, не имеющие маршрута в какую-либо очередь в отдельный Exchange. Редкий и мало используемый кейс.
Exchange
Базовая сущность RabbitMQ. Является точкой входа и маршрутизатором/роутером всех сообщений (как входящих от Publisher, так и перемещающихся от внутренних процессов в Rabbit)
Неизменяемая сущность: для изменения параметров Exchange нужно его удалять и декларировать заново.
Binding: не являются частью Exchange, можно менять отдельно.
Рассылает сообщение во все очереди с подходящими binding (но не более одного сообщения в одну очередь, если есть несколько подходящих binding).
Durable/Transient — признак персистентности Exchange. Durable означает, что exchange сохранится после перезагрузки Rabbit.
Exchange не подразумевает хранения! Это не очередь. Если маршрут для сообщения не будет найден, сообщение сразу будет отброшено без возможности его восстановления.
Binding
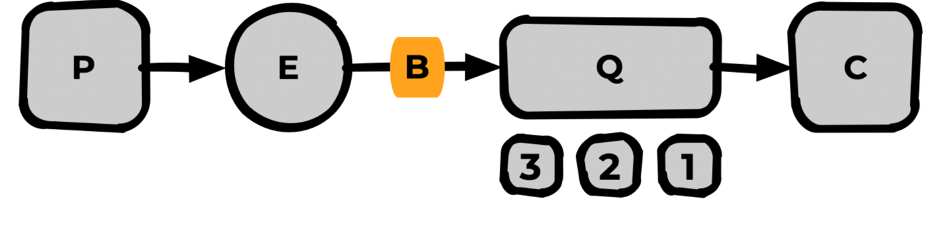
Базовая сущность Rabbit, статический маршрут от Exchange до Queue (от обменника до очереди).
Неизменяемая сущность: если нужно изменить binding, его удаляют и декларируют заново.
Bindings между парой exchange-очередь может быть несколько, но только с разными параметрами.
Параметры binding — или routingkey, или headers — в зависимости от типа Exchange.
Типы Exchange

После разбора binding вернёмся к типам Exchange, так как их работа неразрывно связана.
Выделяют четыре типа Exchange:
Fanout;
Direct;
Topic;
Headers.
Рассмотрим каждый более подробно.
Fanout
Exchange публикует сообщения во все очереди, в которых есть binding, игнорируя любые настройки binding (routing key или заголовки).
Самый простой тип и наименее функциональный. Редко бывает нужен. По скоростям выдает на тестах около 30000mps, но столько же выдает и тип Direct.
Пример работы:


Direct
Exchange публикует сообщения во все очереди, в которых Routing Key binding полностью совпадает с Routing Key Messages.
Наиболее популярный тип, по скорости сравнимый с fanout (на тестах не увидел разницы) и при этом обладающий необходимой гибкостью для большинства задач.
Пример работы:


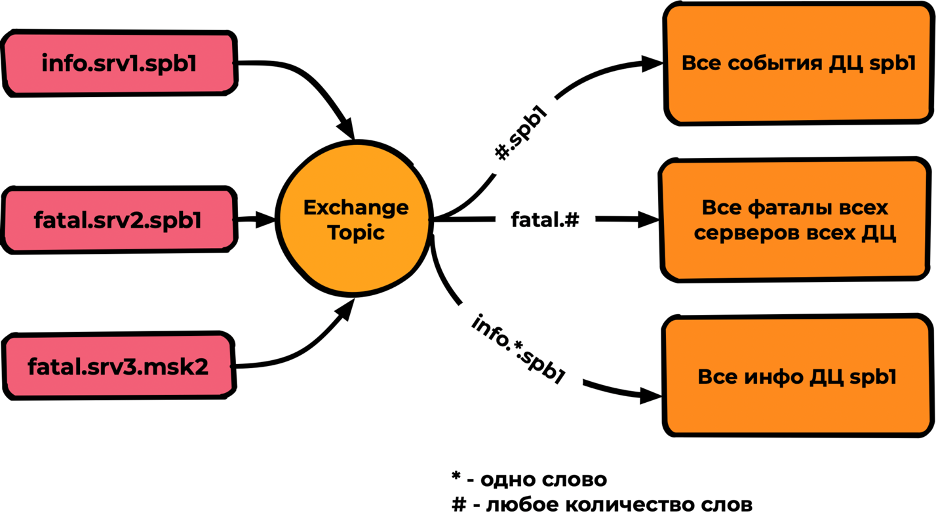
Topic
Тип Exchange, похожий на Direct, но поддерживающий в качестве параметров binding Wildcard * и #, где:
— совпадение одного слова (слова разделяются точкой);
# — любое количество слов.
Производительность топика на тестах показала скорости в три раза ниже fanaut/direct — не более 5000-10000mps
Пример использования:
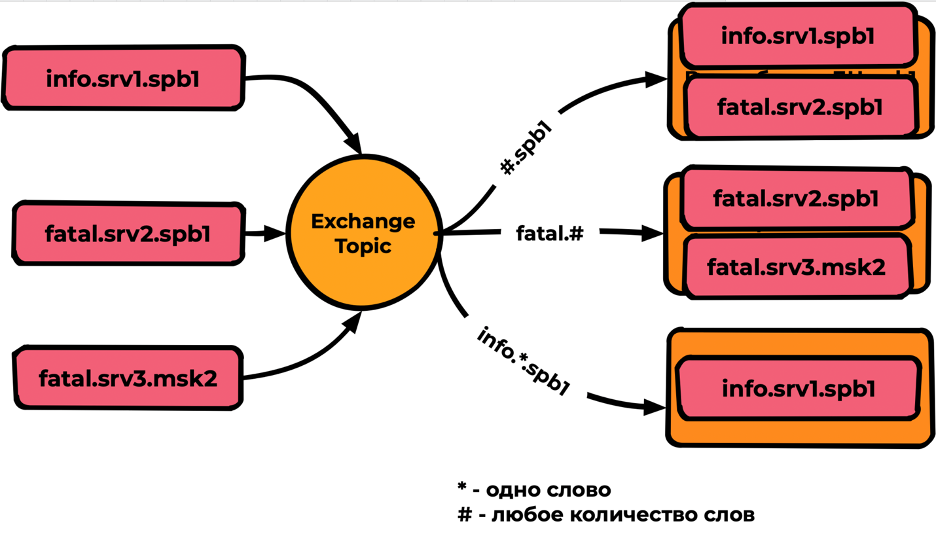
Результат:
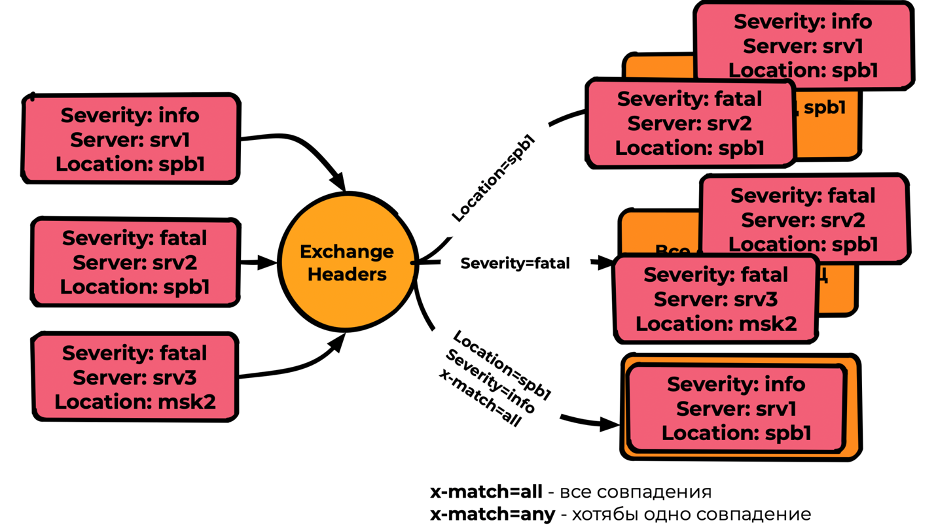
Headers
Наиболее гибкий, но наименее производительный тип. Скорости очень сильно зависят от сложности условий и поэтому труднопрогнозируемы. Оперирует не Routing key, а заголовками сообщений и binding. В binding указываются ожидаемые заголовки, а также признак x-match, где:
x-match=all — необходимы все совпадения для попадания сообщения;
x-match=any — необходимо хотя бы одно совпадение.

Queue
Базовая сущность RabbitMQ, представляет из себя последовательное хранилище для необработанных сообщений.
Хранение сообщений на диске (persistent) зависит от флага delivery_mode, назначаемым publisher для каждого сообщения.
Durable/Transient — признак персистентности очереди. Durable значит, что exchange сохранится после перезагрузки Rabbit.
Важно понимать, что даже если вы отправили сообщения с признаком delivery_mode=2 (persistent), но очередь задекларирована не как Durable, то при перезагрузке Rabbit очередь и все содержащиеся в ней сообщения будут безвозвратно утрачены.
Есть три типа очередей:
Classic — обычная очередь, используется в большинстве случаев.
Quorum — аналог классической очереди, но с обеспечением гарантий консистентности, достигаемый кворумом в кластере.
Stream — новый вид очередей (начиная с версии Rabbimq 3.9), пока ещё мало кем используемый, аналог принципов Apache Kafka.
Message

Базовая сущность RabbitMQ — само сообщение, несёт полезную нагрузку (payload), проходит весь путь от Publisher до Consumer.
Важные поля:
payload — полезная нагрузка, может быть как string, так и base64. Можно закидывать туда хоть картинки, но потом не надо удивляться огромным трафикам между сервисами. Теоретический лимит размера одного сообщения — 2Gb, но на практике рекомендуемый размер сообщения 128mb;
routing key — ключ маршрутизации, может быть только один для одного сообщения;
delivery_mode — признак персистентности;
headers — заголовки сообщения. Нужны для работы Exchange типа headers, а также для дополнительных возможностей Rabbit типа TTL.
Consumer

Замыкает обработку Сonsumer — демон, получающий сообщения из Queue и выполняющий ту самую логику, ради которой сообщение проделало весь этот путь. Например, отправка уведомления, запись в базу данных, генерация оффлайн отчёта или отправка сообщения в другую Queue.
Так же, как и Publisher, Consumer создаёт соединение (connection) по протоколу AMQP. В рамках соединения создаёт канал (channel) и уже инициирует consuming в рамках этого канала.
Consumer может декларировать практически все сущности — exchanges, queues, bindings и тд. На практике мы стараемся декларировать все сущности именно Consumer, но решать нужно для каждого проекта индивидуально.
Consumer подписывается только на одну очередь. Если вы хотите получать сообщения из разных очередей, правильнее будет корректно смаршрутизировать их потоки в одну очередь, чем городить пулы Consumer внутри приложения.
Сообщения в Consumer попадают по push-модели — протакливаются Rabbit в канал по мере их появления и (или) освобождения Consumer. Никакой периодики, задержки — это жирный плюс.
Prefetch count — важный параметр Consumer, обозначающий количество неподтверждённых Consumer сообщений в один момент. По умолчанию во многих библиотеках он равен 0 (по сути отключен). В такой ситуации Rabbit проталкивает все сообщения из очереди в Consumer, а тот во многих случаях при достаточном количестве сообщений просто отъезжает.
Если нет понимания, какое значение ставить, лучше ставить «1» — пока Consumer не обработает одно сообщение, следующее к нему не поступит. Как только Rabbit подтвердит обработку, следующее сообщение будет получено незамедлительно.
Когда вы поймёте, что у вас есть мультитред, и вы можете обрабатывать большие нагрузки, вы поднимете этот параметр, но уже осознанно.
Consumer может подтвердить обработку сообщения — механизм Acknowledge (ack). Или вернуть сообщение в Queue при неудачной обработке — механизм Negative acknowledge (nack).
Механизм nack также срабатывает автоматически при разрушении канала к Consumer. Это удобно использовать: если на горячую выключить Consumer, сообщения, которые он обрабатывал, автоматически вернутся в очередь.
AutoAck — флаг автоматического подтверждения всех протакливаемых сообщений (не требует ack от Consumer). Работает быстро, но не даёт никаких гарантий успешной обработки сообщений.
FIFO очереди
Основу Rabbit представляют собой именно такие очереди:
FIFO = first in - first out

Попадая в очередь, сообщения выходят из неё в той же последовательности, что и вошли. Последовательность определяется моментом попадания сообщения в очередь, не бывает «одновременных сообщений» в рамках одной очереди, у них всегда есть порядок.
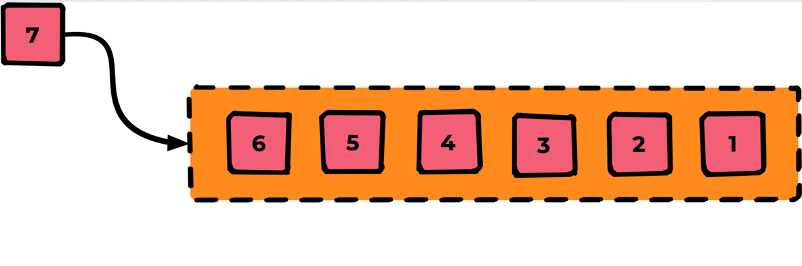
После выстраивания очереди по порядку мы переходим к «обслуживанию» этой очереди. Для этого подключается Consumer (например, как открытие одного кабинета в очереди к врачу).

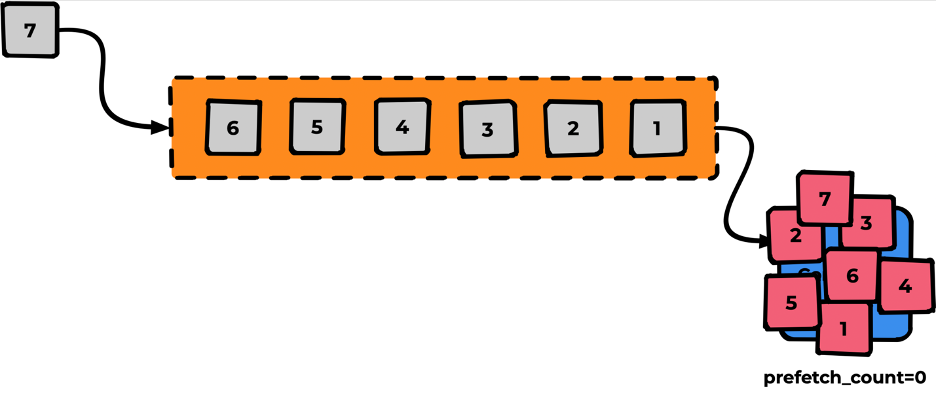
Если мы не укажем prefetch_count, его значение будет равным нулю. Это значит, что все сообщения протолкнутся в Consumer — ничего хорошего обычно в таком поведении нет. Аналогия: открылся кабинет, и все люди в очереди ввалились туда решать свои вопросы.
Поэтому мы явно укажем prefetch_count=1. Теперь без подтверждения более одного сообщения в Consumer находится не сможет.
Выглядит ожидаемо:

Далее после успешной обработки Consumer выполняет «ack» для данного сообщения:
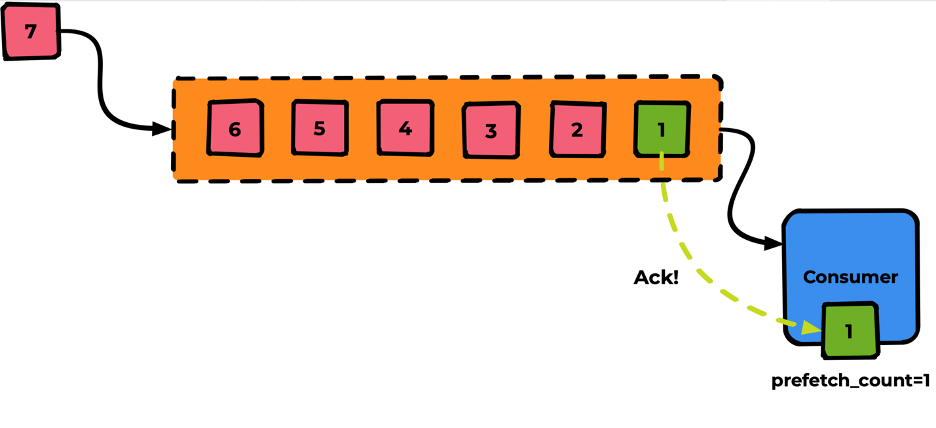
Получив ack, Rabbit удалит сообщение из очереди и незамедлительно протолкнёт в Consumer следующее сообщение (и так далее):

А если мы захотим увеличить скорость обработки? Можем поставить в «кабинете» ещё один «стол с врачом». Для этого укажем prefetch_count=2
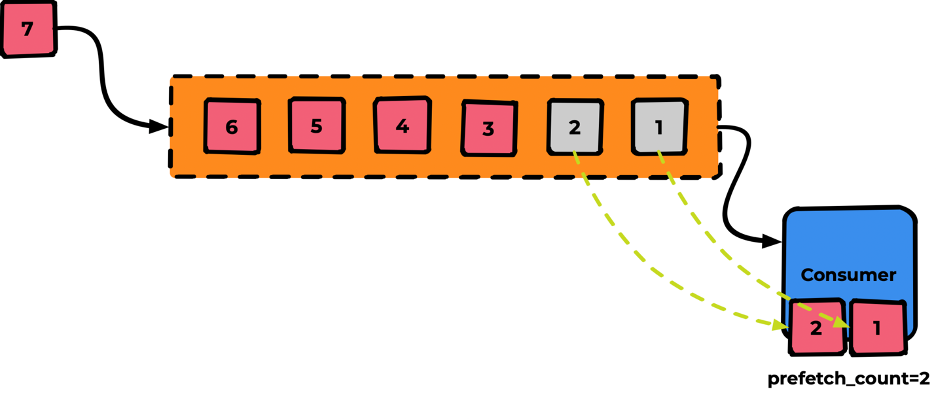
Теперь будет идти обработка сразу двух сообщений. А если мы хотим быстрее? Добавляем ещё один сonsumer-кабинет (например с prefetch_count=1)

Общая концепция горизонтальной масштабируемости выглядит именно так.

«RabbitMQ для админов и разработчиков»
Вместо заключения: полезные ссылки
Официальная документация RabbitMQ (на английском языке)

