2022 год войдет в историю как год прорыва генеративных нейронных технологий. Такие модели, как Midjourney, Stable Diffusion, DALL·E 2, Imagen и их аналоги, показали нам, что нейронная сеть по обычному текстовому описанию может создавать картины, не уступающие произведениям талантливых художников. Это вызвало многочисленные протесты со стороны творческого сообщества, но прогресс не остановить, и всё больше художников начинают использовать генеративные модели в своём рабочем процессе.
Наша команда решила адаптировать подход text-to-image к музыке в нотном домене. В результате этой работы у виртуальных ассистентов Салют появился навык «Маэстро», с помощью которого по текстовому запросу вы можете сгенерировать уникальные музыкальные композиции. Сейчас навык доступен в мобильных приложениях «Салют» и «Сбербанк Онлайн» и скоро будет доступен на умных устройствах Sber. Просто активируйте виртуального ассистента и скажите «Запусти Маэстро».
А как это всё работает, мы расскажем дальше.
Маэстро
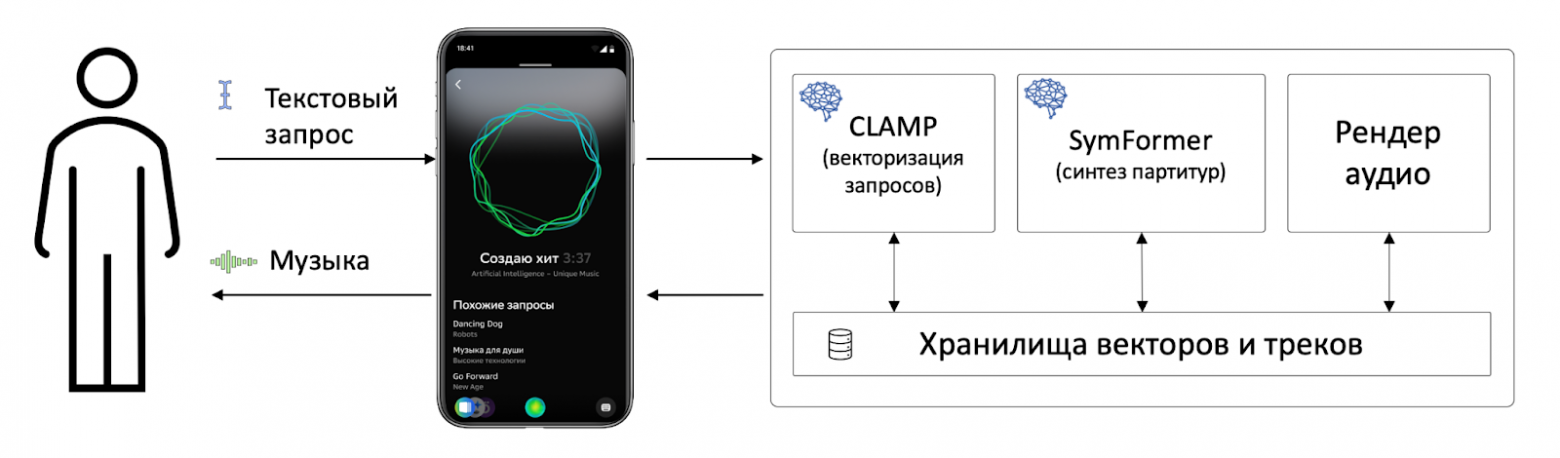
Как же устроен Маэстро?
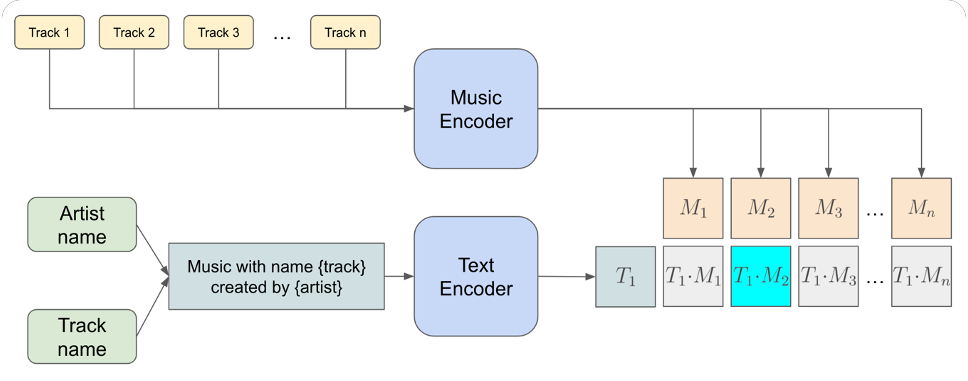
Навык «Маэстро» — это приложение для ассистентов Салют, взаимодействующее с ансамблем нейронных сетей. С помощью него пользователь может отправлять текстовые запросы к бэкэнду и получать результат в виде MP3-файла.
Текстовый запрос представляет из себя вымышленное название артиста и композиции. Полученный запрос с помощью модели CLaMP превращается в управляющий вектор, описывающий композицию на «понятном» для генератора мелодии «языке». Этот вектор, в свою очередь, отправляется в модель SymFormer для генерации композиции в нотном домене. Затем модуль рендеринга озвучивает получившуюся композицию виртуальными инструментами и возвращает пользователю готовый MP3-файл. После чего можно откинуться на спинку кресла и насладиться новым шедевром, если запрос оказался удачным, либо в ужасе тыкать на кнопку «стоп» в случае неудачного запроса.
SymFormer
Про модель SymFormer мы уже писали, пост можно прочитать по ссылке тут.
Напомним вкратце, как она работает.
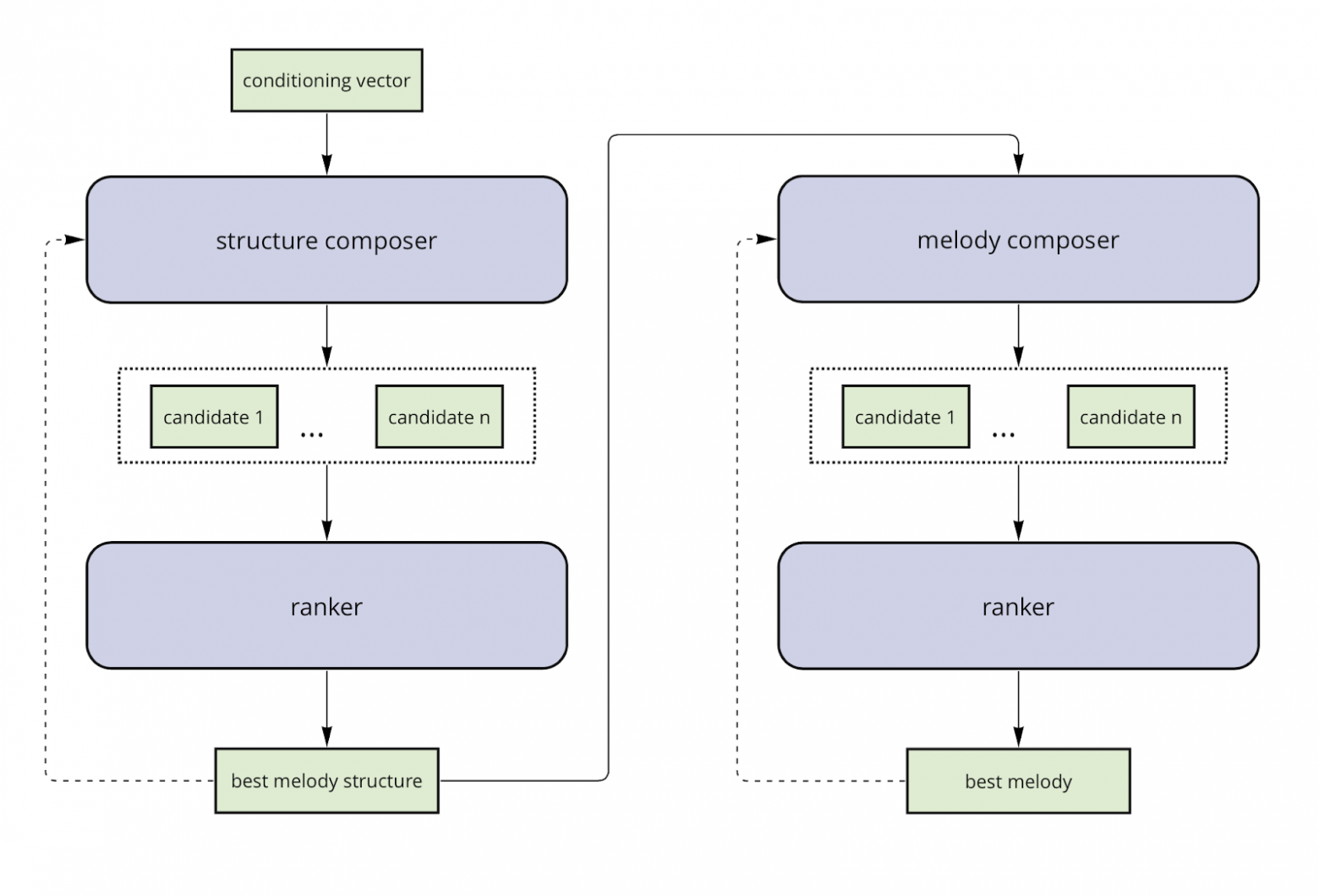
SymFormer — это каскад из трёх моделей: генератора структуры композиции (модель верхнего уровня), генератора мелодий (модель нижнего уровня) и ранжировщика промежуточных результатов. Оба генератора представляют собой связку «трансформер + вариационный автоэнкодер».
На вход модели верхнего уровня подаётся управляющий вектор, на основе которого модель создаёт последовательность управляющих векторов нижнего уровня. Получившийся набор векторов по сути является структурой нашей композиции, где каждый вектор несёт в себе информацию о музыкальном такте. Одновременно генерируется несколько последовательностей-кандидатов. Периодически модель-ранжировщик отбирает лучший промежуточный результат, и генерация продолжается с него.
Результат работы модели верхнего уровня подаётся на вход генератора мелодии, который также генерирует насколько мелодий-кандидатов, и промежуточные результаты отбираются той же самой моделью-ранжировщиком.
За время, прошедшее с прошлой публикации, мы сделали несколько улучшений модели.
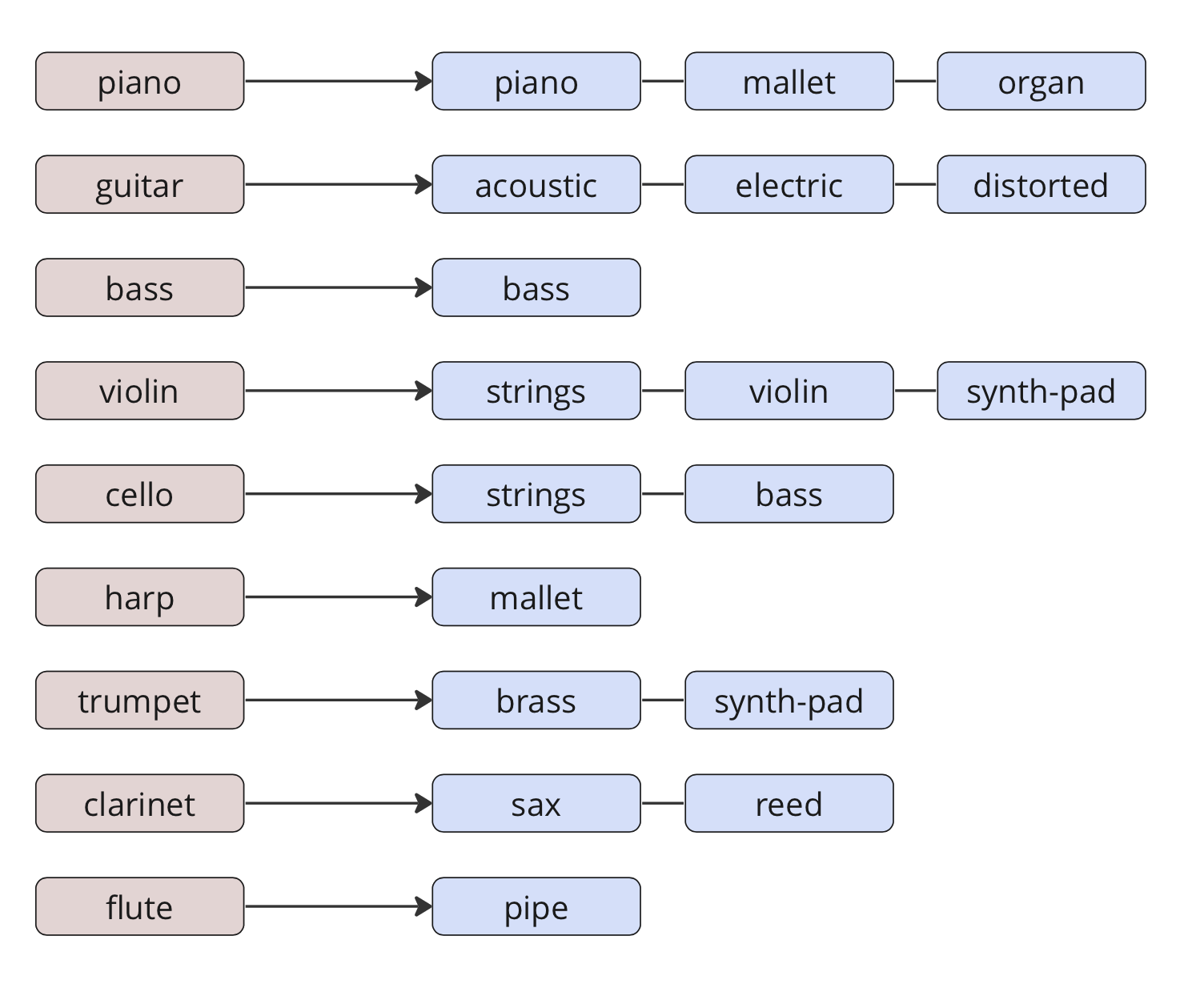
Первым важным улучшением было изменение группировки инструментов. Возможно, вы знаете, что стандартный MIDI набор состоит из 128 инструментов. Использовать их всех при тренировке модели — не очень хорошая идея, так как некоторых инструментов в обучающем датасете будет очень мало. Поэтому изначально мы объединили все инструменты в группы так, как показано в левой части рисунка. Такая группировка позволила получить достаточное количество примеров для каждого инструмента, но привела к «бедному» звучанию, так как одновременно в композиции мог играть только один инструмент из одной группы. Кроме того, модель «не знала» о разнице в исполнении между, например, акустическими и электрогитарами.
Чтобы решить эту проблему мы сделали перегруппировку инструментов, как показано в правой части изображения. В результате у нас появились разные виды струнных, клавишных и духовых инструментов, и модель поняла, чем фортепиано отличается от органа, а акустическая гитара — от электрической.
До перегруппировки инструментов:
После перегруппировки инструментов:
Стало лучше, но из-за увеличения количества групп мы вернулись к исходной проблеме — у нас уменьшилось количество примеров в каждой группе, и синтез некоторых инструментов стал хуже.
Мы создали списки взаимозаменяемых групп инструментов и стали аугментировать данные в процессе тренировки путём случайной замены одних инструментов на другие. Отличия между моделями до и после аугментации можно услышать в этих примерах.
До аугментации:
После аугментации:
Также мы провели ряд экспериментов по замене генератора структуры произведения на диффузионную модель. Первая попытка была достаточно удачной — по результатам side-by-side сравнения качество генерации оказалось примерно таким же, как и в лучшей трансформерной модели. Но этого оказалось недостаточно, чтобы принять решение о замене модели верхнего уровня. Тем не менее, возможность применения диффузионных моделей для генерации как структуры композиции, так и мелодии кажется нам перспективной и в будущем году. Мы собираемся сосредоточиться на этом направлении.
Но самым важным улучшением пайплайна генерации стала модель, позволяющая превращать текстовые запросы пользователя в управляющие вектора верхнего уровня.
CLaMP
В 2021 году компания OpenAI выпустила модель CLIP, которая позволяла измерить релевантность текстового описания изображению. Эта модель была успешно применена для создания модели DALL-E 2, позволяющей генерировать изображения по текстовому запросу.
CLIP представляет собой два энкодера. Первый — Vision Transformer, который получает на вход изображение и выдаёт нормированный вектор. Второй — трансформер типа BERT, который получает на вход текстовое описание того, что представлено на изображении, и также выдаёт нормированный вектор той же размерности, что и для изображений. Модель возвращает скалярное произведение этих двух векторов, которое по сути является уверенностью модели в том, что данное текстовое описание релевантно изображению.
В процессе тренировки подаются батчи, внутри которых для каждого текстового описания и каждого изображения модель считает меру близости. Затем с помощью кросс-энтропии вычисляется среднее качество работы модели отдельно для изображений (подбор релевантного текстового описания для изображений) и для текстов (подбор релевантного изображения текстовому описанию). Полученные два значения усредняются, что даёт конечное качество работы модели. Все меры близости домножаются на обучаемую константу перед вычислением кросс-энтропии.
Датасет был собран на основе 12 открытых датасетов (таких как MS-COCO и др.) и имел достаточно большой размер (400 млн пар), что позволило обучить всю модель с нуля.
Мы решили применить этот подход для нотного домена. С этой целью мы разработали модель CLaMP (Contrastive Language-Music Pre-training), имеющую схожую с CLIP архитектуру.
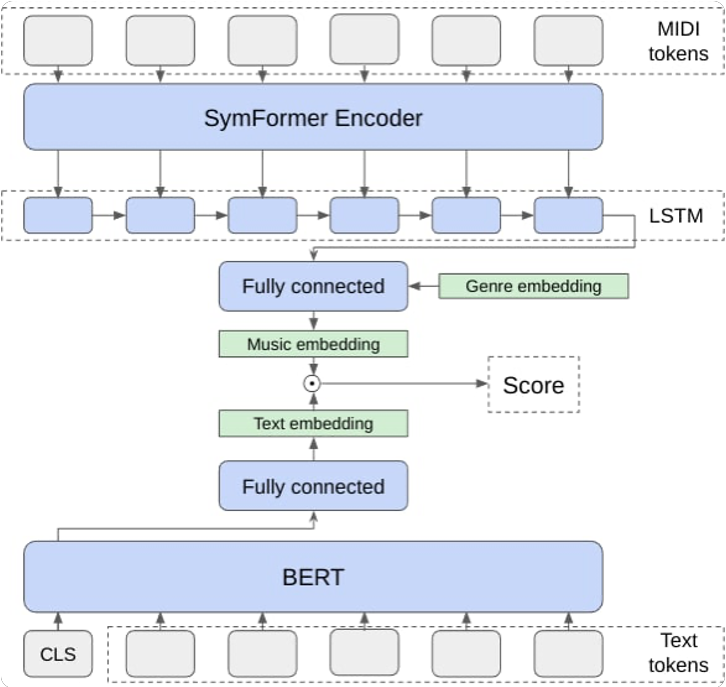
Основное отличие в обучении заключалось в том, что весь наш тренировочный датасет состоял из порядка 100 тысяч пар <название и автор произведения> — <MIDI файл>. Поэтому в качестве энкодеров были применены предтренированные замороженные модели — энкодер SymFormer, вместо ViT, и BERT, вместо текстового энкодера. Последние два слоя BERT были разморожены, а выход энкодера SymFormer подавался на LSTM слой. К выходам энкодеров применялись полносвязные слои. Скалярное произведение результирующих векторов давало меру близости текста и музыкального произведения.
В процессе экспериментов мы сделали вывод, что добавление метаинформации о треке со стороны музыкального энкодера улучшает качество модели. Для этого мы обучили эмбеддинги жанров и сконкатенировали их с выходом LSTM перед тем, как передать их в полносвязный слой.
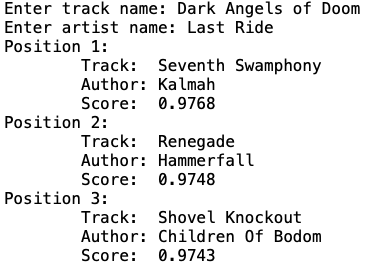
В качестве демонстрации работы модели мы придумали названия групп и композиций, которых не было в нашем датасете, и нашли ближайшие к ним реально существующие композиции.
В первом примере в качестве названия композиции мы выбрали «Dark Angels of Doom», а в качестве автора — «Last Ride». Очевидно, мы ожидаем, что эта вымышленная композиция будет находиться в векторном пространстве рядом с чем-то очень тяжелым. Так и оказалось. Если вы незнакомы с творчеством представленных групп, просто введите эти названия в поиске YouTube.
А Маэстро по этому же запросу сочинил вот такой трек:
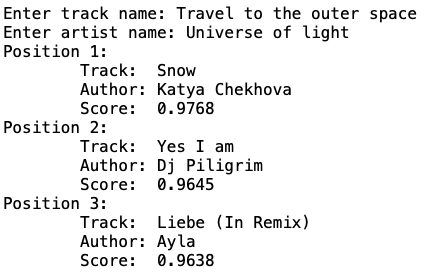
Во втором эксперименте мы надеялись получить от модели список треков с легкой танцевальной музыкой. Вот что получилось в результате.
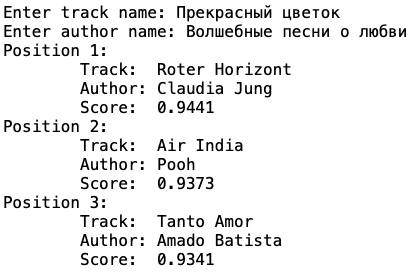
Ну и куда же без песен о любви. По результатам третьего запроса мы их и получили.
Рендеринг
После того, как мы получаем нотную партитуру, необходимо превратить её в настоящую музыкальную композицию, и этим занимается блок рендеринга.
Задача превращения партитуры в музыку является достаточно нетривиальной. С одной стороны, мы не можем подобрать какой-то один фиксированный набор инструментов и озвучивать им все композиции, так как жанр музыкального произведения во многом обусловлен характером звучания инструментов. С другой стороны, различных жанров, стилей и музыкальных направлений существует несколько тысяч, и создать уникальную аранжировку под каждый из них было бы достаточно проблематично. Кроме того, отдельной проблемой является качество используемых сэмплеров, а также сведение и мастеринг трека.
Качество существующих на сегодняшний день нейросетевых решений рендеринга MIDI показалось нам недостаточным, поэтому мы решили использовать профессиональные библиотеки: сэмплированные инструменты, синтезаторы, средства пред- и пост-обработки. Для реализации этого подхода была выбрана технология VST-плагинов, являющаяся стандартом для музыкальной индустрии.
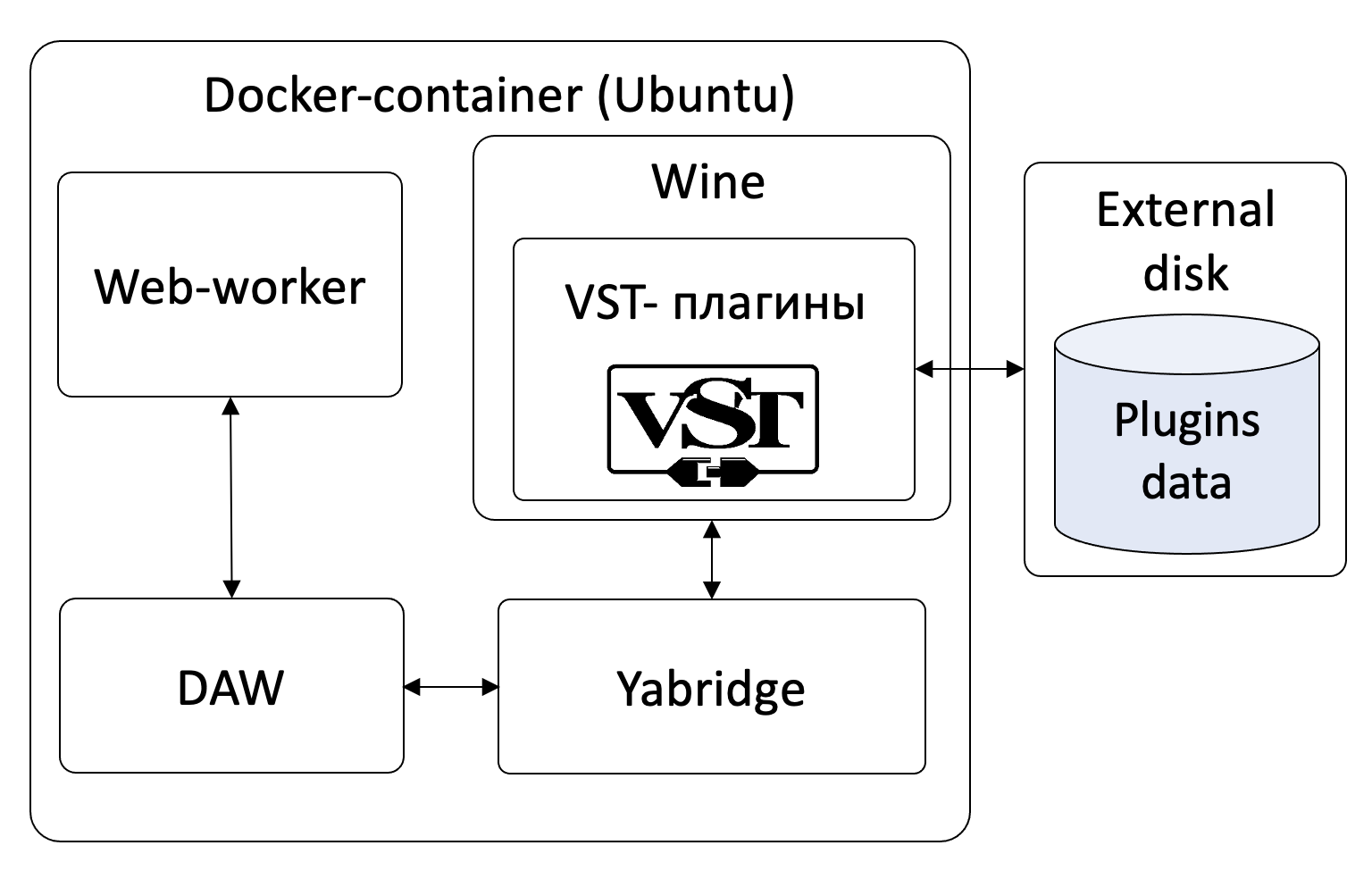
Ориентируясь на характер звучания, мы свели всё многообразие жанров к 42 «базовым» и разработали темплейты для рендеринга, включая настройки для сведения и мастеринга. Рендеринг осуществляется с помощью DAW (Digital Audio Workstation) под управлением ОС Linux, обращение к VST-плагинам происходит через связку Yabridge + Wine. Решение завернуто в Docker-контейнер и может быть автоматически масштабировано в зависимости от нагрузки.
Такой подход оказался достаточно ресурсоёмким, но мы решили пожертвовать временем работы сервиса рендеринга в пользу качества, и поэтому сейчас среднее время обработки одной композиции составляет около пяти минут.
Заключение
Мы проделали огромную работу, чтобы порадовать вас в наступающем новом году музыкой, созданной лично для вас под управлением Маэстро. Надеемся, что она принесёт вам много положительных эмоций, и, возможно, кто-то из вас даже захочет включить самостоятельно созданные композиции в новогодний плейлист.
Кстати, попробуйте в запросе на генерацию через наш навык добавить #елка или #новыйгод.

