Вам, наверное, знаком подход радикальной простоты, который заключается в том, чтобы иметь как можно меньше систем и наименьшее количество строк кода и конфигурации. Это снижает затраты на техническое обслуживание и делает изменения дешёвыми и лёгкими. Но радикальная простота не означает использование ассемблерного кода или C.
Так подходит ли SQL для этой задачи или лучше использовать что-то другое?
При написании серверного кода для чтения из базы данных разработчики обычно используют прямой SQL либо ORM. ORM экономит время на написании SQL-кода, но снижает производительность и увеличивает потребность в большем количестве классов. Прямой SQL быстрее и содержит меньше типовых строк кода, но его сложнее изменить.
В то же время многие разработчики предпочитают перейти на React и SPA с GraphQL, что позволяет использовать гораздо меньше кода для написания серверного приложения, продуктом которого является HTML. Но GraphQL кажется концепцией, которая упрощает чтение данных из одного или нескольких источников данных. Поэтому с появлением GraphQL я задался вопросом, будет ли GraphQL лучше ORM для записи представлений данных в приложениях. В лучшем случае вы пишете HTML-шаблон и запрос GraphQL без какого-либо другого кода.
Мы сфокусируемся на той части кода, которая производит чтение данных, а не запись. И я считаю, что они могут отличатся. Зачем использовать разный код для чтения и записи в базу данных? По моему опыту, чтение и запись масштабируются по-разному, и, хотя использование одного и того же кода для чтения и записи может показаться преимуществом, это часто усложняет изменение кода. Мы хотим видеть, что та часть веб-приложения, которая выполняет операции чтения, может извлечь выгоду из GraphQL.
В качестве примера используем простое приложение для задач «Task app», с пользователями и прикреплёнными к ним задачами, у которых есть статус. Мы реализуем страницу, на которой отображаются все задачи для одного пользователя с указанием пользователя и статуса.
Давайте посмотрим, как использовать GraphQL для рендеринга HTML-шаблонов на стороне сервера. Мы сравниваем решение GraphQL с базовым SQL и с ORM. Я использую Golang с Graphjin для GraphQL, GORM для ORM и PGX для простого SQL-решения.
SQL
Создаём БД SQL:
CREATE TABLE users( id BIGINT unique PRIMARY KEY, name TEXT ); CREATE TABLE status ( id INT unique, status TEXT ); CREATE TABLE tasks ( id BIGINT PRIMARY KEY, title TEXT, user_id bigint REFERENCES users(id), status_id INT REFERENCES status(id) );
SQL с PGX
Начнём с написания простого SQL-решения. Для этого используем PGX в качестве библиотеки Golang. Нам нужна модель для размещения данных, в которую мы передаём HTML-шаблон. Модель — это просто данные из задач:
type PgxTaskList struct { Tasks []PgxTask } type PgxTask struct { Id int64 Title string Status string User string }
Затем нам нужен некоторый SQL-код для чтения из базы данных. Код может быть обобщен и существуют библиотеки, которые устраняют шаблонность, например, с помощью функции, которая сопоставляет результирующие строки базы данных со структурой.
Но в этом примере мы пишем низкоуровневый SQL-код в качестве базового уровня для сравнения.
rows, err := pool.Query(context.Background(), "select t.id,t.title,u.name,s.status from tasks t, users u, status s where t.user_id=$1 and t.user_id=u.id and t.status_id=s.id" , user) if err != nil { panic(err) } p := pgxbench.PgxTaskList{} tasks := make([]pgxbench.PgxTask, 0) for rows.Next() { var id int64 var title string var status string var user string err := rows.Scan(&id, &title, &user, &status) if err != nil { panic(err) } t := pgxbench.PgxTask{ Id: id, Title: title, User: user, Status: status, } tasks = append(tasks, t) } p.Tasks = tasks
Сопоставление строк SQLX
На один уровень выше обычного SQL используется библиотека rowmapper, подобная sqlx в Golang. Структуры будут такими же, как и в SQL, но шаблонный код будет сокращён до:
err := db.Select(&tasks, "select t.id Id,t.title Title,u.name Name,s.status Status from tasks t, users u, status s where t.user_id=u.id and t.status_id=s.id and t.user_id=$1", user)
Это стандартная практика сокращения кода. SQLX использует отражение для сопоставления структур, что, как я предполагаю, будет стоить некоторой производительности. Существуют и другие библиотеки с функцией rowmapper, которые имеют больше кода, но лучшую производительность. Ох уж эти компромиссы!
Gorm
GORM — это объектно-реляционный mapper (ORM) для Golang. ORM преобразует вызовы методов в SQL и помещает данные в модель. В случае использования GORM нам нужна модель:
type GormTaskList struct { Tasks []Task } type User struct { ID uint Name string } type Status struct { ID uint Status string } type Task struct { ID uint Title string UserID uint User User StatusID uint Status Status }
Затем мы можем запросить базу данных с помощью одной строки:
db.Where("user_id = ?", userId).Preload("User").Preload("Status").Find(&tasks)
и передать данные в шаблон. Мы используем preload для зависимых объектов, в противном случае нам пришлось бы загружать их позже или при обращении к ним. Я предполагаю, что таким образом мы получаем наилучшую производительность.
Генерация JSON в Postgres
Вы можете напрямую сгенерировать JSON в базе данных, а затем отобразить его в шаблоне. С помощью небольшого трансформатора, который преобразует $ и $$ в row_to_json, json_agg и json_build_object:
WITH tasks AS $( SELECT t.id id, t.title title, u.name name, s.status status FROM tasks t, users u, status s WHERE t.user_id=u.id AND t.status_id=s.id AND t.user_id=$1 ) $$( 'tasks', (SELECT * from tasks) )
код Go — это просто:
row, err := pool.Query( context.Background(), query, args...) if err != nil { panic(err) } defer row.Close() row.Next() var json map[string]interface{} if err := row.Scan(&json); err != nil { panic(err) } return c.Render(http.StatusOK, template, json)
Этот код одинаков для всех обработчиков и может быть использован повторно. Изменяется только запрос и шаблон.
Чтение задач с помощью GraphQL
Мы используем Graphing в качестве серверной библиотеки Golang для выполнения GraphQL в базе данных Postgresql. С GraphQL нам нужен только один запрос:
query GetTasks { tasks(where: { user_id: $userId } ){ id title user { id name } status { id status } } }
Запрос возвращает JSON, который мы можем напрямую ввести в шаблон.
Производительность
Предостережение: я не специалист по бенчмаркингу Go. Я также не специалист по pgx, sqlx, GORM или Graphjin. Я заинтересован не в том, чтобы подделать бенчмарк, а в том, чтобы найти способ ускорить выполнение кода или оптимизировать конфигурации.
Тесты проводились на WSL/Windows 11, Postgres 15, Go 1.19.3, Ryzen 3900x/12c, 32gb/3600, твердотельном накопителе WD SN850.
Анализ производительности каждого из решений приводит к некоторым сюрпризам. Общая картина не вызывает удивления, обычный SQL самый быстрый, GraphQL самый медленный, а SQLX mapper и ORM находятся между ними. Однако удивительно то, насколько хуже работает mapper по сравнению с рукописным SQL. Второй сюрприз заключается в том, насколько близки ORM и GraphQL. Я бы подумал, что GraphQL намного хуже по производительности по сравнению с ORM.
Основными драйверами может быть то, что GraphQL и ORM создают больше объектов и запускается GC. Кроме того, ORM и GraphQL создают все более сложные запросы. Их можно было бы изучить в будущем.
Используем k6 для нагрузочного тестирования приложения. Все страницы делают то же самое, загружают задачи для одного случайного пользователя в память и отображают их в HTML — в обычном SQL, с помощью SQLX, с помощью GORM и с помощью Graphjin. БД небольшая, но реалистичная для небольшого стартапа, 10000 задач в БД, 100 пользователей, 100 задач/пользователь, 5 статусов. При использовании индексов я не думаю, что размер таблицы задач оказал бы большое влияние.
(“concurrent users” == vu в k6)

И P90 мс, которые требуются для одного запроса:
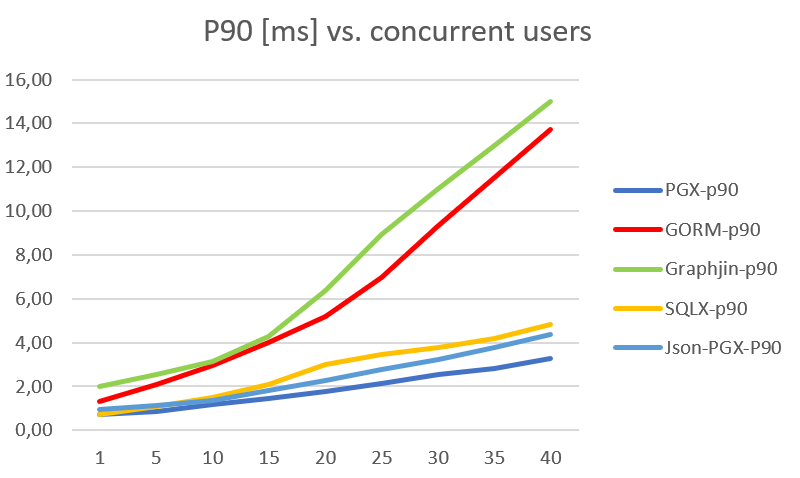
Сравнение
Строки кода для решения GraphQL самые маленькие, вам нужен только запрос и никакого кода Go. Это делает добавление атрибута в представление очень простым: добавьте в запрос GraphQL и в шаблон. Далее следует решение ORM с изменениями в модели и HTML-шаблоне. ORM нужны изменения в структуре и SQL, SQL-решению нужны изменения в запросе, сопоставлении и структуре. И все они нуждаются в изменениях в HTML.
Решение GraphQL выглядит наиболее чистым с точки зрения количества строк кода и изменений, необходимых для добавления одного нового атрибута.
У GraphQL есть проблемы с производительностю, но это не так плохо, как я предполагал. Если вы уже используете ORM, игнорируя разделение чтения/записи, ORM может быть лучшим решением, но оказывает большее влияние на производительность, чем думают многие люди. Обычный SQL является самым быстрым, но требует наибольшего количества изменений, и его труднее читать и понимать. Производительность GraphQL и ORM непрозрачна, сложнее для понимания и оптимизации.
Самым большим недостатком GraphQL, по-видимому, является добавление ещё одной зависимости. Graphjin — это немаленький пакет, который сам по себе имеет множество сторонних зависимостей. Другая зависимость противоречит радикальной простоте и поэтому является компромиссом.
Но из-за скорости разработки и простоты внесения изменений, при сохранении достаточной производительности, я рассмотрю GraphQL для своих будущих проектов разработки на стороне сервера.
Спасибо за внимание!

