EMNLP — это одна из самых больших конференций в области обработки естественных языков. В этом году конференция проходила с 7 по 11 декабря в Абу-Даби. Из кучи статьей, представленных на конференции, я хотел бы выделить три, которые привлекли моё внимание. Эти статьи не самые полезные или известные, но они точно достойны упоминания. Две статьи были представлены в виде постеров, у третьей было полноценное выступление на конференции. Моя любимая из этих трех статей — PoeLM, статья про генерацию стихов на испанском языке с формальными ограничениями.
PoeLM: A Meter- and Rhyme-Controllable Language Model for Unsupervised Poetry Generation
Статья: Ormazabal et al., 2022
Организации: Университет Страны Басков, Meta AI, Копенгагенский университет.
Основная мысль: Генерация стихов с формальными ограничениями на испанском и баскском с использованием языковой модели, обученной на непоэтических текстах, с помощью контролирующих префиксов.
Код и данные: тут, но без кода самой модели.
Зачем?

Могут ли современные языковые модели писать стихи? Конечно, могут, это можно быстро проверить с помощью ChatGPT. Сложности возникнут при попытке наложить ограничения, такие как фиксированное количество слогов или определенную схему рифмы или ритма.
Можно ли заставить языковые модели генерировать стихотворения с ограничениями? Один из способов — модифицировать алгоритм декодирования, что сложно реализуемо для современных языковых моделей, поскольку они оперируют не на уровне слов, а на уровне токенов, которые не являются ни словами, ни слогами. В этой статье описан альтернативный способ. Для него понадобится корпус обычных непоэтических текстов и система, способная делать разбиение на слоги и анализировать рифмы.
Обучаем языковую модель
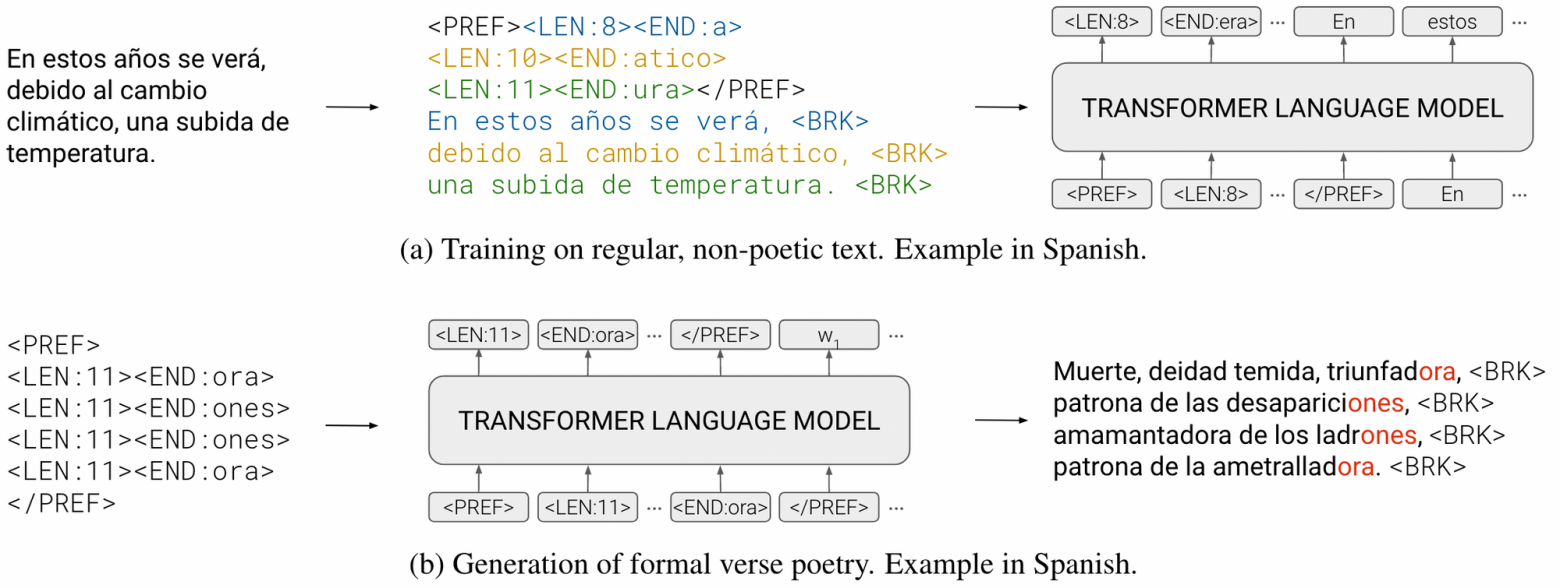
Берём обычный текстовый корпус и делим его на фразы.
Группируем тексты в блоки из N фраз, где N — случайное число.
Дополняем группы контролирующими префиксами, включающими количество фраз, количество слогов и рифмованные окончания для каждой фразы.
Обучаем классическую трансформерную языковую модель, например GPT-2, со специальными токенами для эффективной токенизации префикса.

Префикс на картинке выше означает четыре строки, в каждой из них 11 слогов, первая и последняя строки заканчиваются на "echo", а промежуточные строки — на "ura". Модель научится использовать этот префикс, так как генерировать тексты с такими подсказками легче, чем без них.
Генерация
Выбираем схему рифмовки и количество слогов.
Создаём контролирующий префикс. Авторы делают это по заданной схеме (например, "abba"), отбирая каждый рифмующийся слог независимо из пяти наиболее часто встречающихся последних слогов обучающего корпуса.
Опционально подаём первую строчку стиха.
Генерируем множество кандидатов, используя обученную языковую модель.
Отсеиваем кандидатов, которые не соблюдают формальные ограничения на количество слогов и схему рифмовки.
Переранжируем оставшиеся кандидаты по беглости, используя ту же самую модель, но без контролирующего префикса.
Печатаем стих с наивысшей оценкой после переранжирования.
Оценка качества

На пятом этапе выкидывается 69% стихов на испанском. При этом для обычных языковых моделей 100% стихов не подходят под формальные ограничениям, в основном из-за неверного количества слогов. 37% людей предпочитают сгенерированные стихи тем, которые написаны известными поэтами, при сравнении стихов с одинаковой первой строкой.
Можно ли повторить эту схему для русского?
Да, но есть нюанс. У стихов на русском присутствует ещё и ритмическая схема: ямб, хорей, амфибрахий и так далее. Для её учёта нужно как минимум модифицировать структуру префикса. Кроме того, ещё нужны надежные системы для деления на слоги, определения рифмы и расстановки ударений. Я планирую в следующем году адаптировать эту работу к русскому языку, и если вы хотите помочь, пишите.
Почему эта статья мне интересна?
Шесть лет назад мы с Даней Анастасьевым разработали систему для генерации стихов на русском, rupo, статья на Хабре, видео-доклад. Это была языковая модель на основе LSTM с несколькими уникальными особенностями: она предсказывала тексты справа налево, отдельно используя леммы слов и их грамматические значения, и была основана на использовании конечных автоматов при декодировании. С тех пор технологии значительно продвинулись вперед, поэтому сегодня создать подобную систему, вероятно, проще.
Draw Me a Flower: Processing and Grounding Abstraction in Natural Language
Статья: Lachmy et al., 2022
Организации: Университет имени Бар-Илана, AI2.
Код и данные: тут, но там нет моделей, только данные.
Основная мысль: Создание бенчмарка для оценки понимания абстракций в естественном языке с привязкой к рисованию узоров на гексагональной сетке.

Зачем?
Известно, что большие языковые модели не могут правильно считать или делать численные прикидки, отвечать на вопросы Ферми. Даже простейшие задачи на навигацию являются проблемой, хотя тут помогает вычисление по шагам, chain-of-thought. Но что насчет абстракций? Когда вы говорите своему голосовому ассистенту "возьми три пиццы, одну барбекю, одну пепперони и одну маргариту, первые две большие, маргариту среднюю, к 5 часам вечера", он должен вас понять. Речь идет не только об эллипсисах, но и об условиях, циклах, функциональной декомпозиции, рекурсии и других механизмах.
.")
Для численного измерения степени способности моделей оперировать абстрактными понятиями мы можем "приземлять" ее в различных виртуальных мирах. В случае этой статьи авторы использовали гексагональную доску с 10x18 плитками и восемью цветами.
Данные

Набор данных для этого исследования был собран с помощью краудсорсинга на Amazon MTurk. Процесс аннотирования был разделен на два этапа: на первом этапе группа аннотаторов писала инструкции на основе изображений, а на втором этапе другая группа пыталась воссоздать изображения на основе инструкций. Все расхождения устранялись путем ручной проверки. Полученный набор содержит 175 уникальных изображений, 620 наборов инструкций из суммарно 4177 шагов.
Эксперименты

Авторы протестировали два типа моделей, на основе классификации и генерации. В классификации использовалась DeBERTa для предсказания состояния каждой плитки. В генерации T5 по тексту инструкций предсказывала набор действий. Модели тестировались при различных настройках, различающихся по количеству доступной им информации об истории и текущем состоянии доски. Модели cработали значительно хуже, чем люди, и cмогли обработать только базовые абстракции.
.")
Почему эта статья интересна?
Это наглядный пример того, насколько сложна проблема обработки абстракций для моделей естественного языка. Этот бенчмарк позволяет быстро определить, каких механизмов абстракции не хватает в этих моделях. Я подозреваю, что модели для генерации кода будут лучше справляться с этой задачей, и мне было бы интересно проверить эту гипотезу.
Dungeons and Dragons as a Dialog Challenge for Artificial Intelligence
Статья: Callison-Burch et al., 2022
Организации: Пенсильванский университет, Google Research.
Код и данные: Пока нет, должны быть здесь.
Основная мысль: Создание бенчмарка для диалоговых систем, который основан на диалогах из D&D, где задачами являются генерация следующего хода диалога в игре и предсказание состояния игры.

Зачем?
Dungeons & Dragons (D&D, DnD; Подземелья и драконы) — настольная ролевая игра в жанре фэнтези. В игре участвуют ведущий (так называемый «мастер») и несколько игроков, число которых варьируется в зависимости от редакции и пожеланий участников. Обычно один игрок руководит в игровом мире действиями одного персонажа. Мастер действует от лица всех неигровых персонажей, описывает окружающую среду и происходящие в ней события. В течение игры каждый участник задаёт действия для своего персонажа, а результаты действий определяются мастером в соответствии с правилами. Случайные события моделируются броском кубика. — Вики
Многие наборы данных для NLP очень узкоспециализированы, сфокусированы на конкретной задаче. А вот D&D — это вид человеческой деятельности, требующий высокого уровня понимания языка от всех участников. Игра требует целый ряд навыков, таких как генерация текстов, поиск в базе знаний, многосторонние беседы, постановку целей, рассуждения на основе здравого смысла, определение намерений и отслеживание состояний, что делает ее идеальным испытательным стендом для оценки моделей обработки естественного языка.
Примеры других применений ИИ в D&D: создание фотографий персонажей и, конечно же, знаменитый AI Dungeon.
Данные


Авторы взяли данные с веб-форума D&D Beyond, где люди играют, по очереди публикуя на форуме свои ходы. Это не единственный возможный источник данных о сессиях D&D. Например, в наборе данных CRD3 использовались стенограммы шоу Critical Role.
Эвристики на основе правил использовались для извлечения информации о состоянии игры из текстов. Они были основаны на регулярных выражениях и распознавании именованных сущностей. Кроме того, в случаях, когда эвристики не помогли извлечь информацию, использовался классификатор на основе свёрточных сетей. Набор данных включает не только "ролевые" тексты, но и комментарии не от лица персонажей.
Эксперименты
LaMDA — большая языковая модель Google, аналогичная GPT-3, была дообучена для решения двух задач: отслеживания состояния игры и генерации текста на следующий ход. Авторы экспериментировали с различными вариантами дообучения модели, включая использование состояний из текущего или предыдущего хода в качестве контролирующих префиксов. Для оценки работы модели были привлечены шесть профессиональных разметчиков, интересующихся жанром фэнтези и с опытом игры в D&D, в том числе три человека, которые бывали «мастерами».

Результаты оценки показывают, что адаптация модели под D&D тексты приносит пользу, но влияние контролирующих префиксов мало. Однако эти префиксы позволяют модели отыгрывать роли в игре, а значит можно использовать её как замену «мастера» или игроков в реальных играх.

А вот результаты для задачи отслеживания состояний могли бы быть и лучше. Модели были переданы все предыдущие сообщения и соответствующие им переменные состояния, а также текст текущего поста. Ожидалось, что она выдаст правильные переменные состояния. Точность модели составила 58%, если учитывать все слот. Эти результаты показывают, что использование одной лишь большой языковой модели недостаточно для решения этой задачи, и что для большей эффективности нужны дополнительные модификации.
Заключение
В заключение, можно было бы написать о том, как всё это потенциально важно для NLP и всего человечества, но главное тут не это. Эти три статьи меня вдохновили, и, надеюсь, мне удалось корректно передать их смысл и это ощущение. На конференции было много более полезных, но при этом гораздо менее интересных статей. В конце концов, зачем заниматься наукой или инженерным делом, если это не доставляет тебе удовольствия? Удачи!

