
Активности в операционной системе могут быть самыми разнообразными. Это может быть и запуск нового процесса или потока, и обращение к файловой системе, и выделение памяти, и многое другое. Могут возникнуть ситуации, когда (вследствие действий злоумышленника и\или программной\аппаратной ошибки) эта активность становится аномальной, то есть поведение системы начинает отличаться от ожидаемого. Запуск неизвестного процесса на этапе эксплуатации изделия, потребление процессом необычно большого количества памяти, установка сетевых соединений, которых быть не должно в системе - всё это примеры аномальной активности, возможно требующие внимания со стороны пользователя или разработчика.
Потребители нашей операционной системы (ЗОСРВ “Нейтрино”), имеют доступ к достаточно большому арсеналу средств, обеспечивающих надежность и безопасность системы. Среди них системы контроля целостности компонентов, встроенные средства защиты информации, средство обнаружения потенциально опасных программ (антивирус) и средства обеспечения высокой готовности (отказоустойчивости). Однако, в контексте мониторинга аномальных активностей их становится недостаточно. Это подтолкнуло нас к разработке программного комплекса мониторинга аномальных процессов (ПК МАП). В его основу лежат механизмы сбора и анализа состояния системы, а также технологии машинного обучения.
Сбор информации об активности процессов
В ЗОСРВ “Нейтрино” имеется большое количество способов получения информации об активности процессов. Схематически они показаны на рисунке:
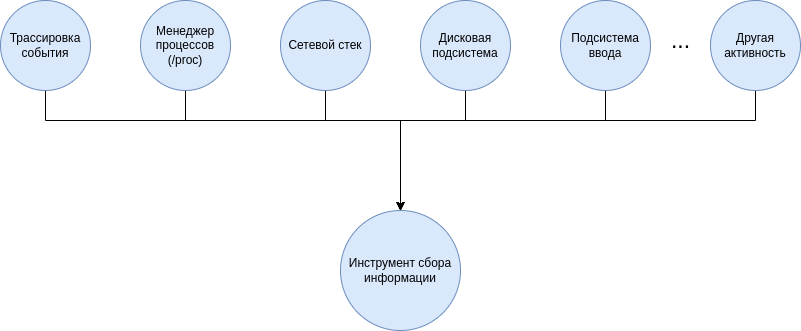
Трассировка событий
В составе ЗОСРВ “Нейтрино” имеется диагностическая версия микроядра (procnto-instr), которая обладает развитым механизмом трассировки и протоколирования событий. Он позволяет отслеживать взаимодействие между ядром ОС и любым активным потоком или процессом. Это могут быть, например, вызовы ядра, изменение состояний потоков, прерывания, и многое другое.
Механизм получения информации об активности процессов является следующим. Диагностическое ядро, а также системные вызовы и прикладной код, генерируют трассировочные события по различным операциям, которые автоматически копируются в набор буферов, сгруппированных в циклическом связном списке. Как только количество событий в буфере достигает определённого значения, ядро информирует утилиту сбора данных о заполнении буфера. После получения данных, утилита выполняет их фильтрацию и интерпретацию, чтобы подготовить эти данные к анализу.
Использование диагностического ядра может повлиять на производительность системы. Хотя падение производительности может составлять всего несколько процентов, по сравнению с версией ядра без этого механизма, его использование на “боевом” железе часто применяется для накопления диагностической информации о работе системы.
Менеджер процессов и потоков
В качестве источника информации об активности процессов также может использоваться виртуальная файловая система /proc. В сравнении с трассировкой она не влияет на производительность целевой системы, но позволяет получать некоторые данные для анализа. В этом случае мы получаем значительно меньшее количество информации, нежели в случае с использованием диагностического ядра, но этого вполне достаточно, чтобы оценить состояние того или иного процесса.
Таким образом, операционная система позволяет привилегированному процессу получать информацию об активности процессов и потоков в системе. Программный комплекс мониторинга аномальных процессов использует виртуальную файловую систему /proc и собирает следующую информацию:
запущенные процессы и потоки;
потребление памяти;
состояние стека;
открытые файловые дескрипторы;
открытые соединения (включая сетевые);
состояние каналов;
запущенные таймеры;
обработчики прерываний;
разделяемые библиотеки в памяти.
Помимо перечисленных источников информации об активности, ими также может выступать сетевой стек (анализ сетевого трафика), дисковая подсистема (операции чтения/записи), или, например, подсистема ввода (анализ действий пользователя). Вариантов действительно много.
Машинное обучение на встраиваемых системах
Первой задачей являлся выбор и портирование фреймворка машинного обучения.
Критерии выбора
Классический подход к использованию нейронных сетей обычно основывается на нескольких этапах: сбор и подготовка данных, обучение нейросети, сбор данных на конечной системе в процессе эксплуатации и их анализ на сервере. Для решения поставленной задачи такой подход не годится, поскольку требуется, чтобы все процессы происходили на встраиваемой системе. Это обусловлено несколькими факторами. Во-первых, безопасностью, поскольку информация об активности не должна покидать пределы устройства. Во-вторых, возможностью принимать управляющие решения непосредственно на встраиваемой системе в случае необходимости. В-третьих, необходимостью корректировки поведения нейросети в процессе работы. Из этого следует ещё одно ограничение - в силу (зачастую) ограниченного количества ресурсов встраиваемых систем, выбираемое решение должно быть высокопроизводительным.
В настоящий момент ситуация с машинным обучением на встраиваемых системах в парадигме edge-computing (когда данные обрабатываются не на серверах, а непосредственно на встраиваемых устройствах) в целом весьма грустная. Чаще всего предлагаются закрытые решения для конкретного набора оборудования, что существенно ограничивает их применимость. Кроме того, речь идёт чаще всего только о применении обученной нейросети для анализа данных (инференс) на встраиваемых системах, но не про обучение нейронной сети (это всё равно выносится за пределы этих устройств).
Резюмируя вышесказанное, к фреймворку предъявлялись особые критерии.
Почему именно Interference

Одним из фреймворков, который мог бы функционировать целиком и полностью на встраиваемых системах, без необходимости задействовать дополнительные вычислительные мощности (edge-computing), является кроссплатформенная библиотека с открытым исходным кодом Interference. Библиотека реализует интерференционную модель нейронной сети, которая принципиально отличается от большинства классических моделей нейронных сетей. Структура нейронных сетей в этой модели максимально приближена к структуре биологических нейронных сетей в головном мозге человека. Нейрон в этой модели представляет собой самоорганизующийся объект, а его обучение происходит за счёт перемещения рецепторов под действием нейромедиатора, который выделяется синапсами (как в биологическом нейроне). Сигнал подаётся последовательно, распределённо по времени, при этом количество данных обучения получается значительно меньше по сравнению с классическими моделями (что позволяет экономить память) – необходимо хранить только координаты рецепторов в конечный момент времени и длины их траекторий. Для успешной классификации данных достаточно одного нейрона на один класс. Ещё одной важной особенностью является то, что нейронные сети этой модели можно легко дообучать, без необходимости начинать обучение с нуля.
Интерференционная модель нейронной сети зарекомендовала себя в решении задач распознавания изображений, но в силу своей универсальности может быть применена и к задаче динамического анализа, в частности, для обнаружения аномалий в наборе данных.
Другим важным аспектом является то, что библиотека написана на чистом C++ без дополнительных зависимостей, что обуславливает скорость работы и простоту ее портирования. В библиотеке реализована система вычислительных бэкендов, которая позволяет переключаться между разными способами производить вычисления, а также реализовывать новые - под специфичные вычислители. К ним на уровне архитектуры могут относиться OpenGL [ES], OpenCL, специализированные DSP и др. Это позволяет переносить вычислительную нагрузку на GPU и другие специализированные устройства.
Что из себя представляет монитор активности
Структура ПК МАП
Программный комплекс состоит из основного сервиса, непосредственно осуществляющего сбор и анализ данных (amon) и утилиты управления (amoncfg). Структура amon представлена на следующей схеме:
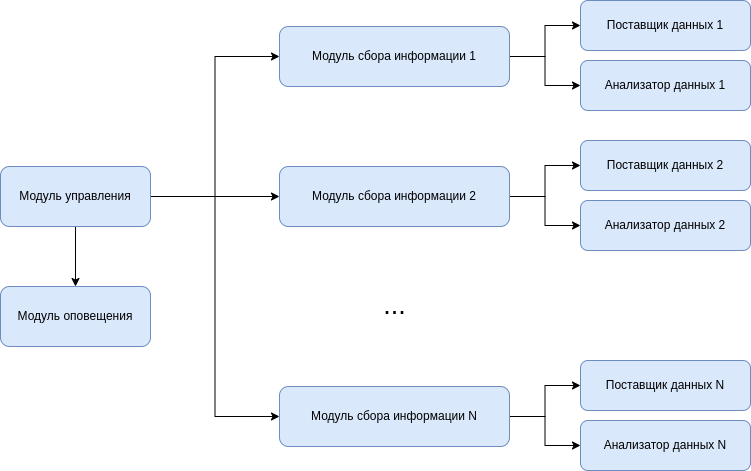
На схеме представлены следующие компоненты:
модуль управления - осуществляет управление другими модулями и предоставляет интерфейс взаимодействия с сервисом;
модуль оповещения - хранит информацию об аномалиях и генерирует оповещения при их появлении;
модуль сбора информации - управляет процессом получения и анализа информации;
поставщик данных - предоставляет информацию об активности;
анализатор данных - выполняет анализ посредством нейронной сети.
Конфигурация
Для начала работы с программным комплексом необходимо наличие конфигурационного файла. Пример конфигурационного файла представлен ниже:
{ "name": "default", "buffer_size": 1000, "providers": [ { "name": "kernel", "processes": [ "io-usb", "io-hid" ], "data": [ "threads", "libs", "mem" ], "polling_time": 3000, "structure": "structures/kernel/structure.json", "anomaly_action": "scripts/action.sh" } ] }
Здесь:
buffer_size - размер кольцевого буфера для сообщений об аномалиях.
providers - список источников данных активности.
name - имя поставщика данных.
processes - список процессов, которые необходимо анализировать.
data - список типов активности, которые необходимо анализировать.
polling_time - интервал опроса.
structure - путь к файлу, хранящему структуру нейронной сети. Этот же файл структуры используется для хранения всех данных обучения.
anomaly_action - путь к скрипту, который будет автоматически запущен при выявлении аномальной активности.
Сценарий использования
Основой программного комплекса является сервис amon, который осуществляет непосредственно сбор и анализ данных, выявление аномалий, а также уведомление и опциональное автоматическое выполнение действий, заданных пользователем. После успешного запуска сервис создаёт устройство /dev/amon, через который можно осуществлять взаимодействие с ним.
Схематически сценарий использования представлен на картинке:
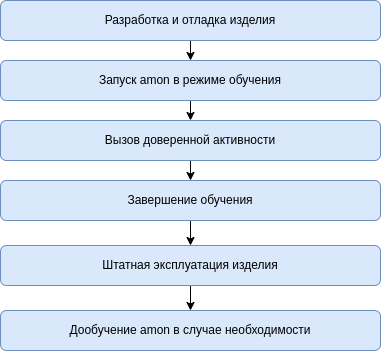
После запуска необходимо однократно выполнить обучение нейронной сети на эталонной системе в течение некоторого времени. Обучение является ответственным процессом и напрямую влияет на эффективность выявления аномалий, поэтому следует убедиться, что активность во время обучения является доверенной (термин поясняется далее).
После окончания обучения комплекс переключается в режим анализа активности. При обнаружении аномальной активности, информация о ней будет сохранена в лог и может быть прочитана различными способами. Если обнаруженная активность на самом деле не является аномальной, администратор имеет возможность дообучить нейронную сеть и принять эту активность как доверенную без переобучения всей сети. Также поддерживается автоматическое выполнение сценариев при обнаружении аномальной активности.
Поддерживается большое количество способов взаимодействия с сервисом amon (через менеджер ресурсов /dev/amon). Основное взаимодействие осуществляется через утилиту amoncfg. С помощью утилиты cat можно вывести журнал обнаруженных аномалий. Также существует открытое API, которое позволяет разработать собственное клиентское приложение, взаимодействующее с сервисом amon.
Практическое применение
Некоторые примеры использования
Запуск сервиса amon с указанием файла конфигурации:
amon -c /usr/local/conf &
Переход в режим обучения:
amoncfg -L
Переход в режим анализа активности:
amoncfg -R
Вывод статистики по анализу активности:
amoncfg -l
Пример вывода представлен на рисунке:
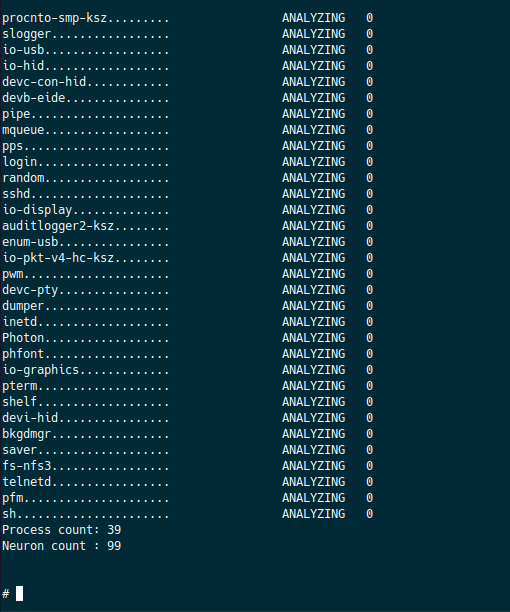
Здесь отображается список запомненных процессов, текущий режим (обучение или анализ) и количество детектированных аномалий в их работе.
Просмотр сведений об аномалиях:
amoncfg -a
Дата ID Процесс Элемент Доп. информация 20.01.2023 12 test-io mem Чрезмерное потребление памяти
Вывод показывает, что некий процесс test-io начал потреблять нестандартно много памяти, о чём amon и сообщил.
Замеры производительности
Тестирование производительности программного комплекса проводилось на разных стендах, здесь опишем результаты со стенда на Intel NUC6i3SYB (архитектура Skylake, 2 ядра, 2.3 ГГц), интервал опроса - 3 секунды.
На рисунке ниже представлена зависимость использования ЦП от количества анализируемых процессов.
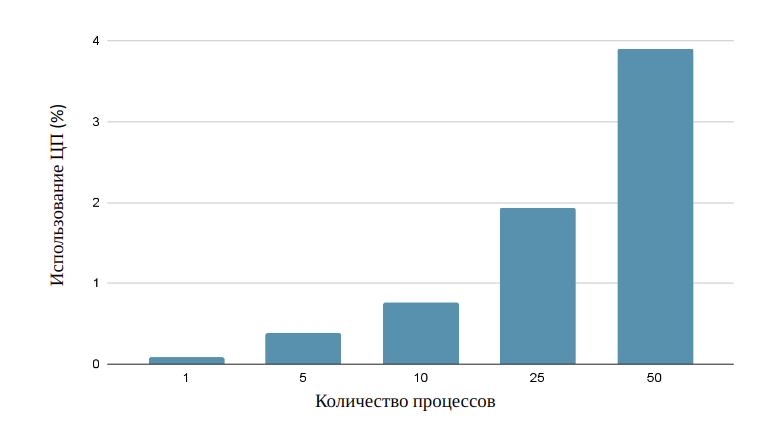
Из рисунка видно, что при анализе активности 50 процессов нагрузка на ЦП составляет менее 4% (использовался однопоточный режим).
Спасибо за уделённое время и внимание!
Подробнее узнать о научной составляющей нейросетевой тематики можно здесь:

