Советов «как ускорить веб-приложение» в интернете немало. Но при попытке применить их на деле может вспоминаться мем «делойте хорошее а плохое не делойте». Ситуации очень различаются, и универсальные рецепты плохо подходят.
Поэтому на нашей конференции HolyJS Наталья Стусь поделилась тем, как выглядела работа над производительностью не в «вакууме», а конкретно в случае Авто.ру. Конечно, поскольку всё индивидуально, вы не сможете тут же сделать всё в своём проекте «точно так же». Но вот извлечь какие-то полезные принципы и понять, на что обратить внимание, вполне можно. Участникам конференции доклад понравился, и теперь для Хабра мы сделали его текстовую версию (а для тех, кто предпочитает видео, доступна запись).
Далее повествование — от лица Натальи.
Последние полтора года я занимаюсь перформансом проекта Авто.ру. И сегодня хочу рассказать о концепции, к которой я пришла за это время, — как работать над перформансом, как искать проблемы и находить решения. Сначала расскажу немного истории и про саму концепцию, потом приведу примеры, а в конце перечислю инструменты, которые я использовала.
Примерно полтора года назад мне пришла задача. Если измерить производительность сайта Авто.ру с помощью Lighthouse, то мы получим определенное число. Его надо улучшить, чтобы оно стало как можно ближе к 100.

Не очень понятная постановка задачи, да? А что мы обычно делаем, когда приходит непонятная задача? Идем в поисковик искать ответы на наши вопросы. Я нашла статью, в которой хорошо описаны все метрики и улучшения.
Там нашлось более 20 советов:

Какие-то у нас и так уже были внедрены. Какие-то были неприменимы к нашему проекту. Какие-то были немного странными: «уменьшите время ответа сервера» — ну спасибо, а как именно-то? Но все они довольно базовые и абстрактные, так что не сильно меня вдохновили.
Затем я решила посмотреть, как обстоят дела у других. Нашла в интернете несколько кейсов ребят из VK, Авито и других компаний. Но в основном там были описаны решения, которые подходят только под конкретные проекты. Одни ребята добавили скелетоны, и это сработало. Но у нас они уже давно есть. Кто-то перешел с одного фреймворка на другой. Окей, но мы свой фреймворк любим и уходить с него не хотим (ну и это очень дорого).
Тогда остается думать, экспериментировать, находить и устранять проблемы. За полтора года хаотичного поиска проблем я смогла составить концепцию, с помощью которой можно совершенствовать перфоманс приложений.
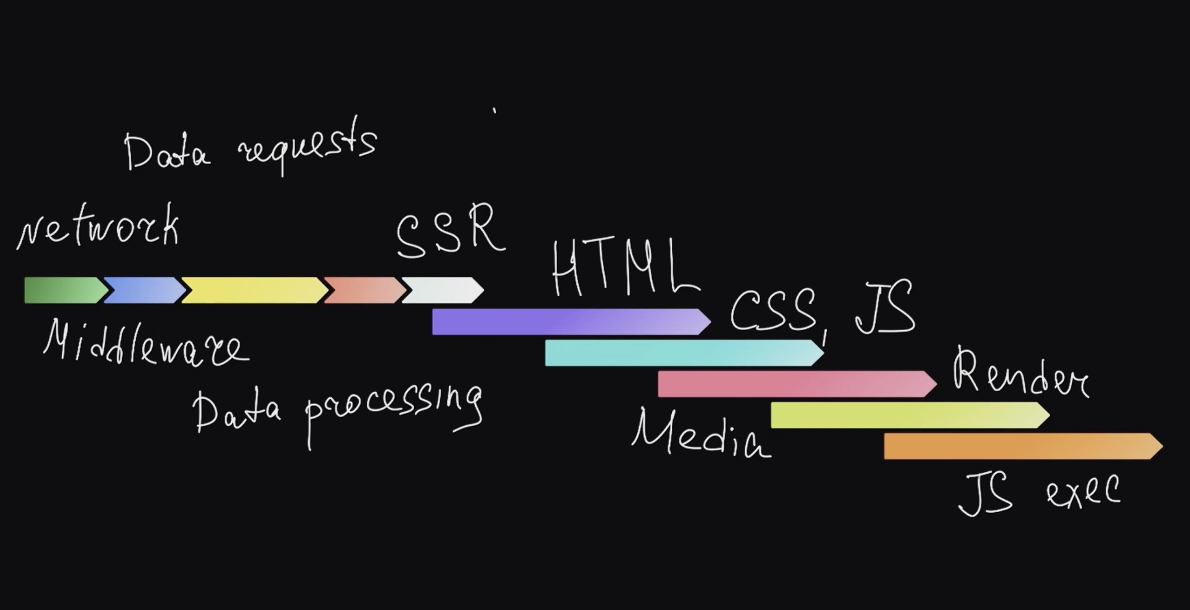
Основная идея — идти не от метрик, как это советуют обычно в статьях, а от того, как работает само приложение. Декомпозировав его работу, вы сможете разбираться отдельно с каждым конкретным этапом.
На Авто.ру у нас получилась примерно такая схема из этапов, которые проходят в нашем приложении от момента запроса пользователя до завершения рендеринга:
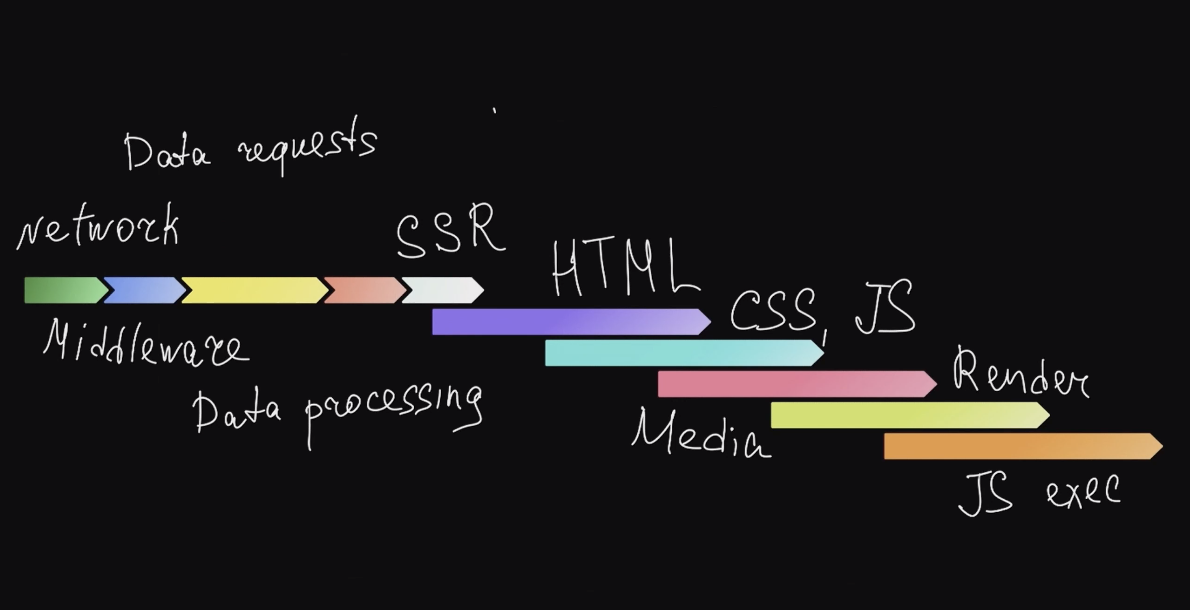
Серверная часть — это сеть, middleware, запрос данных, обработка данных и SSR. А на клиентской части скачиваются HTML, CSS, JS, рендерятся картинки, выполняется JS. Это относительная схема — в клиентской части всё не именно так накладывается друг на друга. Ну и у каждого проекта схема будет своя.
На этой схеме можно понять, где появляются Web Vitals — основные метрики жизнеспособности нашего сайта:
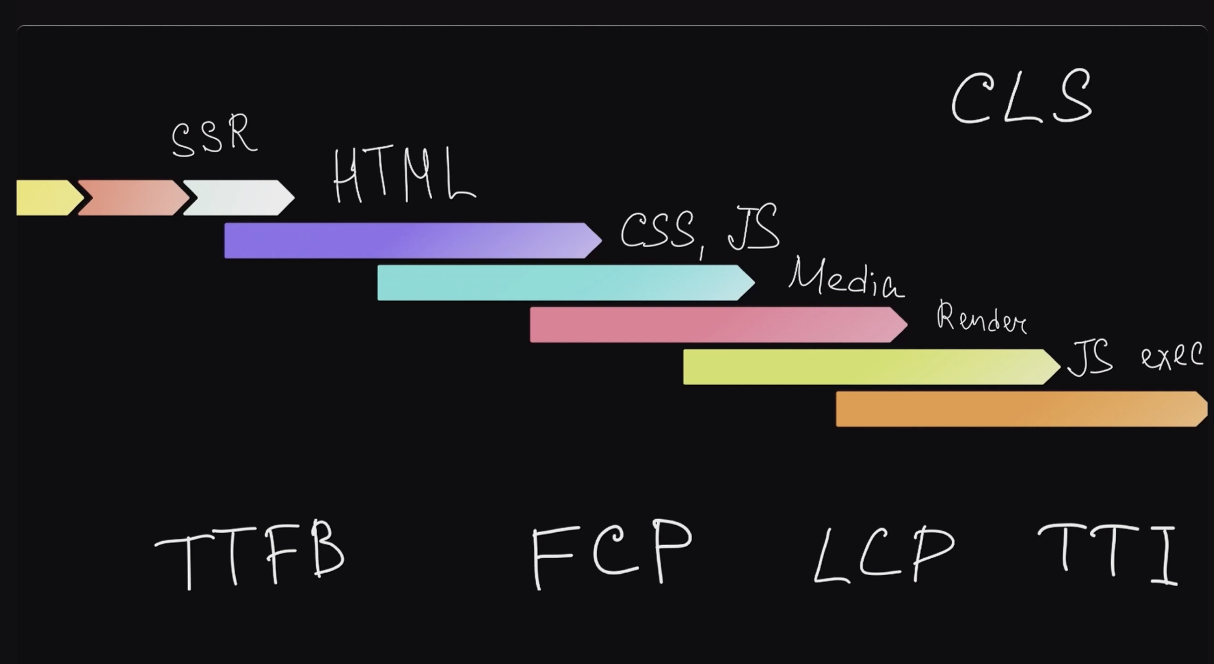
Где-то в конце отработки серверной части появляется метрика Time to First Byte (TTFB) — когда пользователь начинает получать данные от нашего сервера.
В начале рендеринга появляется метрика First Contentful Paint (FCP) — когда на экране у пользователя появляется что-то значимое (текст, иконки и т.д.)
Largest Contentful Paint (LCP) — это когда пользователь уже видит большой кусок текста, большое видео или что-то другое, за чем он, скорее всего, и пришел на вашу страницу.
Time to Interactive (TTI) — время, за которое пользователь может начать взаимодействовать с вашим приложением: нажимать кнопочки, вводить текст и т.д.
Отдельно стоит метрика Cumulative Layout Shift (CLS) — это не время, а параметр, который показывает, насколько отрисовавшийся контент смещается в процессе дальнейшего рендеринга. Это может приводить к визуальным неудобствам или мискликам.
Пример замеров одной из наших страниц:
Расскажу, как работать с этой схемой. Мы будем смотреть на каждый этап работы приложения и задавать разные вопросы, например: «можно ли этого не делать?», «можно ли это сделать раньше или позже?» или «можно ли сократить этот запрос?».
Первый этап — сеть. Но поскольку это не совсем зона ответственности фронтенд-приложения, мы пропустим этот этап и перейдем к следующему.
Middleware

Если у фронтенд-приложения есть серверная часть, то ещё до начала сбора данных для страницы там могут быть задействованы middleware-составляющие.
Как оценить время их работы? Можно всё залогировать, а можно сделать трейсы — это более удобная визуализация. Я покажу на примере одной из страниц Авто.ру, как выглядит трейс:
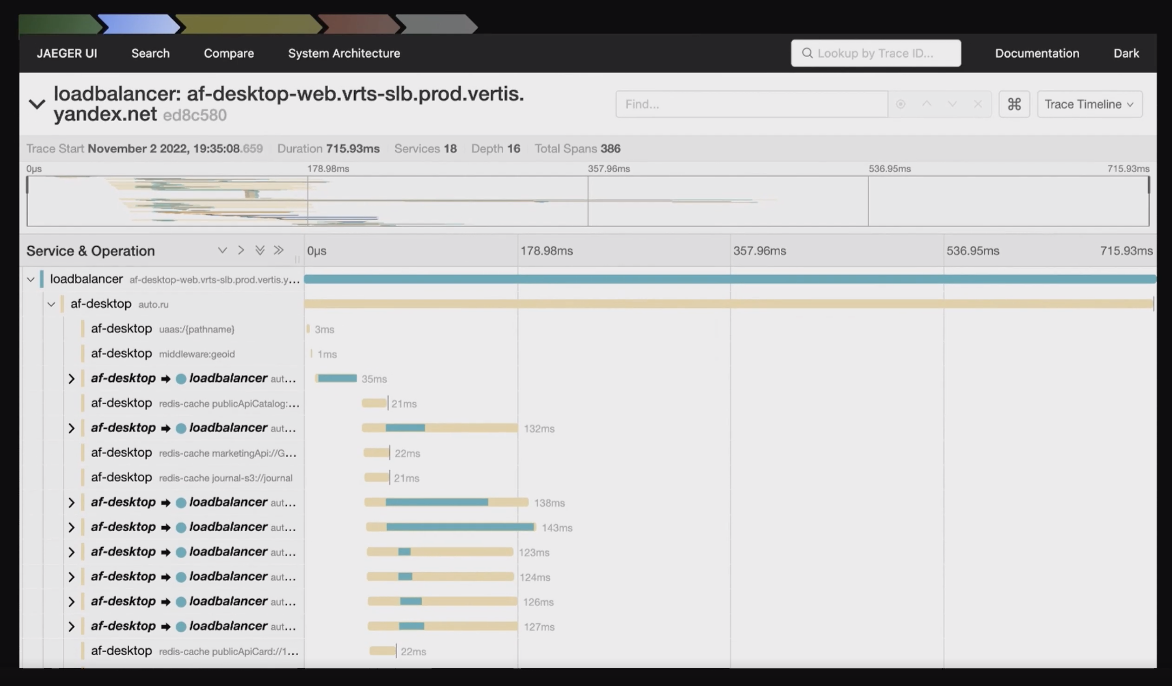
Здесь вся серверная часть для одной из страниц Авто.ру представлена в виде таких трейсиков, видно время выполнения каждого элемента. В данном случае это трейс страницы листинга объявлений на Авто.ру. Наш листинг – это страница с результатами поиска по объявлениям:
Чтобы нарисовать ее, надо сделать много разных запросов, что видно по трейсам. И в числе прочего для этой страницы есть трейс middleware:

Здесь видно, что запрос выполняется очень быстро и оптимизировать особо нечего. Однако эта штука блокирует всю дальнейшую серверную часть, и если вы увидите, что у вас Middleware выполняются достаточно долго, то можно покопаться и посмотреть, что там происходит.
Запросы данных

Теперь перейдем к запросам данных. В нашем случае эта часть очень объемная и самая долгая, потому что у нас много данных собирается по разным сервисам, бэкендам, эндпоинтам. Что я предлагаю сделать? Взять трейс или лог и посмотреть на самые длинные спаны. Но неплохо посмотреть и на более короткие — как минимум, если вы увидите, что там есть что-то ненужное, то сможете это убрать и снизить нагрузку на сервер. А на какой-то другой странице они вам и перфоманс могут улучшить.

В моем случае я нашла интересную вещь:

Спан внизу за 393 миллисекунды — это запрос самих объявлений, которые мы показываем на странице листинга. Но еще есть спан на зловещие 666 миллисекунд. Я стала разбираться, что это такое, и выяснила, что этот запрос на вдвое большее число объявлений, чем мы отображаем на странице, он нужен для показа блока с другими конфигурациями данной машины. Мы поговорили с продакт менеджерами и поняли, что этот блок можно немного урезать, и в итоге смогли просто убрать долгий запрос. Получили неплохой прирост в скорости.
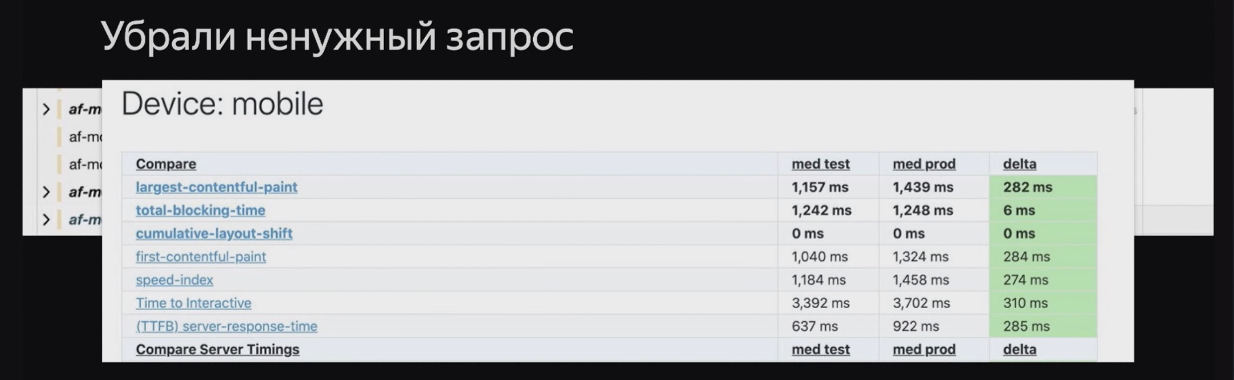
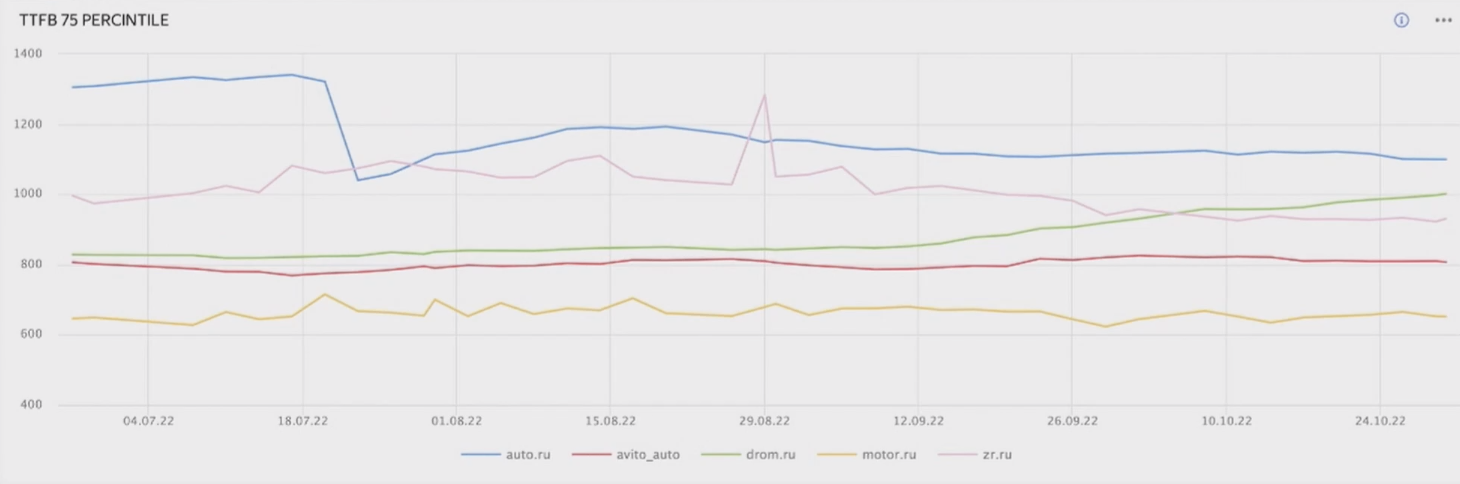
Это результаты тестов, где сравниваются две версии, — до изменений и после. Получилась довольно большая разница в 258 миллисекунд в TTFB. А вот так выглядел график запросов на пользователях (смотреть на синюю линию):
Но бывает и так, что мы убираем ненужный запрос, а график не меняется:
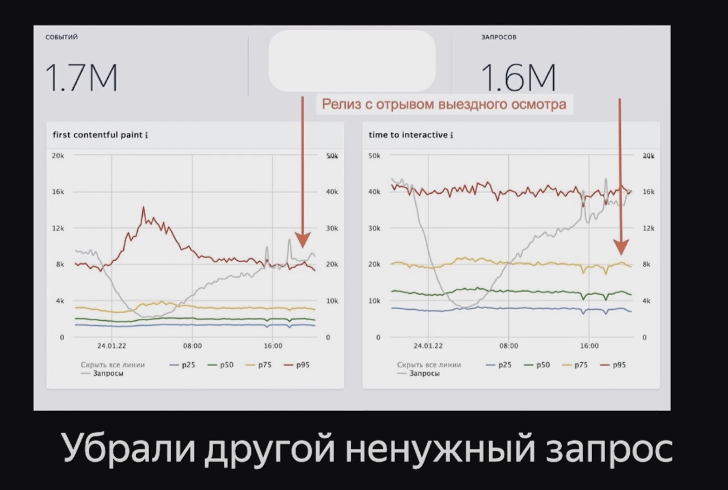
Или меняется совсем другой график ?:
")
На что еще мы можем повлиять? Например, здесь мы видим, что некоторые запросы начинают выполняться только после того, как получили ответ от других.
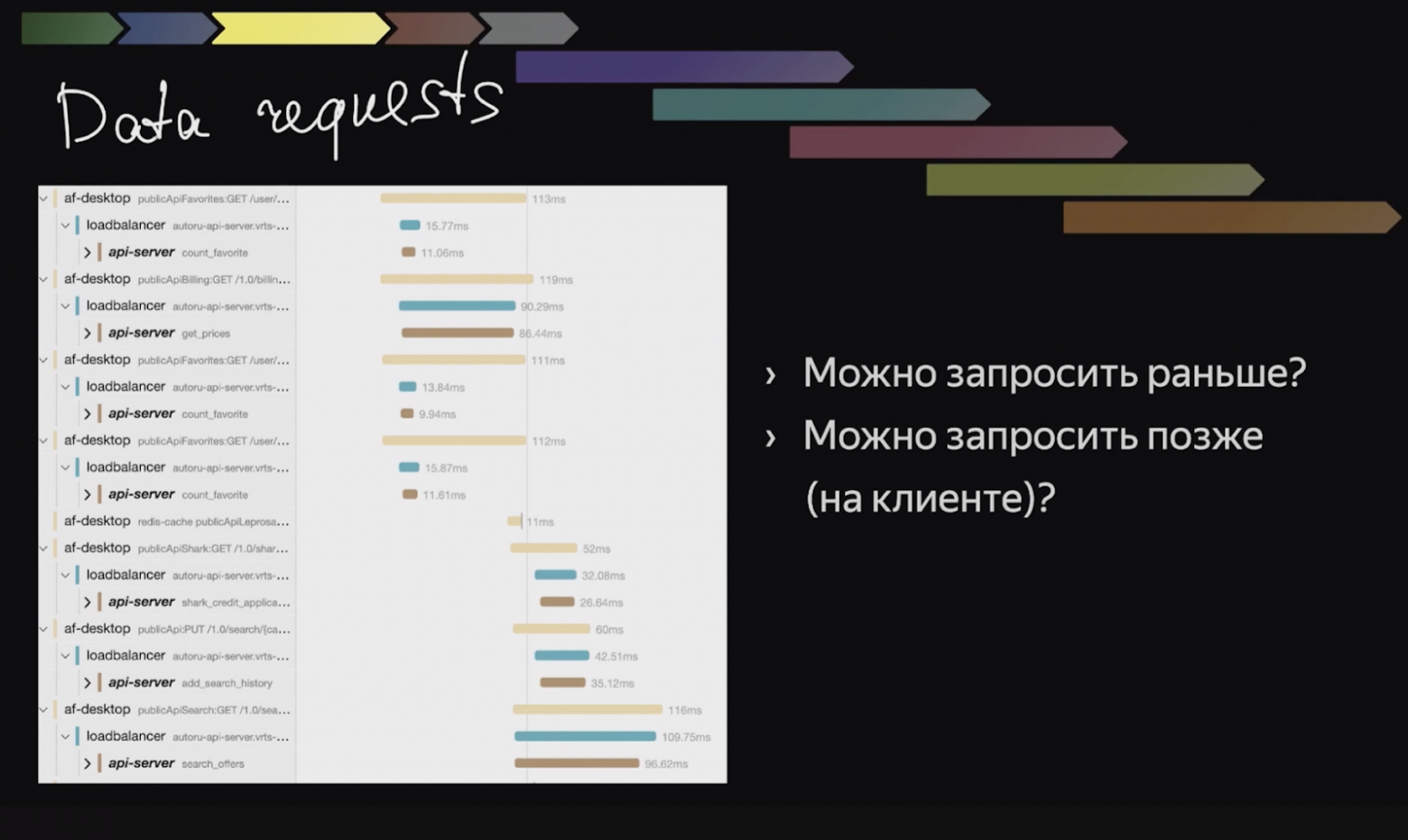
Скорее всего, это зависимые запросы или ретраи. Это нужно проанализировать — возможно, не все зависимости правда нужны. Возможно, это запросы, которые зависят от пользователя и их можно сделать на клиенте. Но в моем случае тут ничего не нашлось.
После того, как мы убрали самый долгий запрос, находим новый самый долгий запрос :)

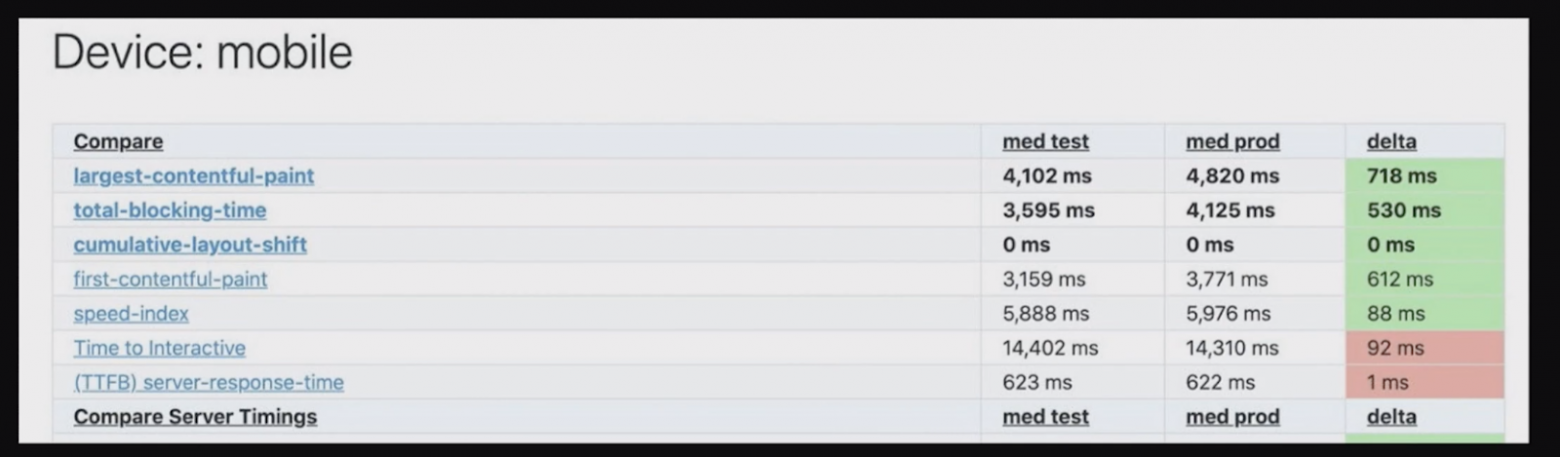
Это запрос за объявлениями. Бэк по большой базе объявлений выбирает подходящие 37 штук. Разработчики бэкенда сказали, что ускорить эту штуку они не могут. Но можно запрашивать меньше, тогда отвечать будет быстрее. Тогда я пошла к менеджерам, чтобы узнать, зачем нам именно 37 объявлений, почему не 20, например. В итоге пришли к тому, что для мобильного листинга, где у нас бесконечный скролл, можно запрашивать в два раза меньше объявлений, и пользователи это не заметят (конечно же, проверили эту теорию в эксперименте, прежде чем раскатывать на всех). После уменьшения количества запрашиваемых на сервере объявлений мы получили прирост в 200 миллисекунд TTFB

Обработка данных

После того, как мы получаем данные с бэкенда, мы, возможно, делаем с ними что-то еще — пересчитываем, вырезаем, склеиваем. И это тоже можно залогировать. У нас отдельного трейса на это нет, но здесь можно посмотреть на разницу спанов — сколько работала сеть, сколько работал фронтовый сервер. И если она будет большая, то надо смотреть, почему она такая. Возможно, вы что-то очень долго вычисляете после запросов данных.

У нас в этом месте не было критических кейсов, поэтому нет примеров.
Server-Side Rendering

Мы используем Server-Side Rendering, потому что нам важно отдавать весь контент поисковым роботам. И его тоже можно затрейсить, залогировать или построить красивый график. Здесь пример нашего трейса и графика:

График показывает время Server-Side Rendering, то, как долго сервер строит верстку HTML. Оно было 400 миллисекунд до того, как мы уменьшили размер выдачи. А после — стало 250 миллисекунд.

Соответственно, кроме времени запроса мы уменьшили время Server-Side Rendering, и здесь разница 230 мс TTFB складывается из обоих показателей: ускорения запроса и ускорения SSR.

Все, что я только что рассказала о серверной части, складывается в показатель TTFB. Если у вас потоковый SSR, то она наступает немного раньше, чем закончится SSR. Если не потоковый – то ровно после того, как закончился SSR и клиенту по сети начало приходить то, что сервер нарендерил.

Как понять, на каких страницах вообще есть проблемы с TTFB? Можно поискать их по логам. Мы логируем суммарное время работы сервер над отдельным URL’ом и если поискать в логах по Response time > 1000 ms, например, то мы найдем запросы, которые стоит проанализировать. Можно взять их Request_id, посмотреть по нему лог и увидеть, что же там так долго происходило.
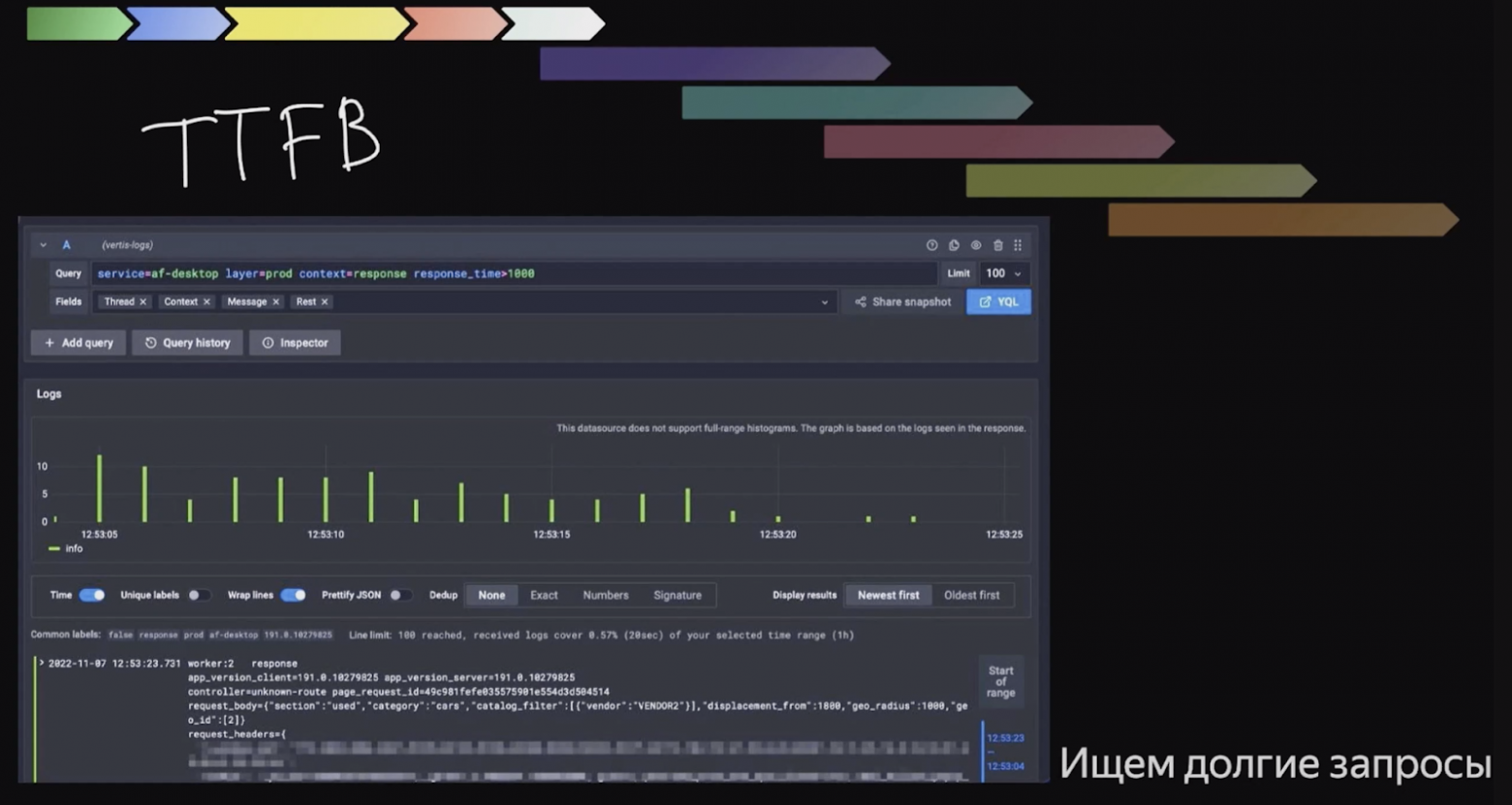
Кейс с запросом на 666 миллисекунд, где запрашивался ненужный блок данных, я нашла именно так.
TTFB зависит не только от того, как работает приложение, но и от того, на чем оно работает. Приложение запущено на серверах, а у них может быть разное железо.
У нас есть два дата-центра с разным железом. В одном 75-й перцентиль TTFB составляет 875 миллисекунд, в другом — 750.

Получается, больше 100 миллисекунд разницы только за счет железа. Так что если к вам приходит менеджер и говорит, что у приложения слишком большой TTFB, то проблема может быть не только в самом приложении, но и в железе. Клиентская часть выполняется в клиентском браузере, и эта часть зависит от устройства, с которого пользователь открывает ваш сайт. А серверная часть зависит от железа — об этом тоже нужно помнить и не гнаться за абсолютным показателем в условные 200 мс TTFB.
Клиентская часть

Клиентская часть начинается с того, что HTML, который мы отрендерили на сервере, приходит в браузер, начинает скачиваться и парситься. Здесь скорость зависит от объема данных: чем меньше вы пошлете HTML, тем быстрее он скачается и быстрее будет происходить всё остальное.
HTML состоит из верстки и данных — тех, которые мы запрашивали на сервере и на основании которых рендерили верстку. Их нужно отправить на клиент для дальнейшей работы приложения. Я считаю, что в верстке у нас не должно быть много лишнего, поэтому снова смотрю на данные.

Мы логируем размер payload’a. На картинке видно, что до gzip он может быть под 2 Мб. А в gzip данные вместе с версткой – 160 Кб. Больше половины этого размера составляет payload в сжатом виде. Этот размер можно посмотреть в консоли браузера.
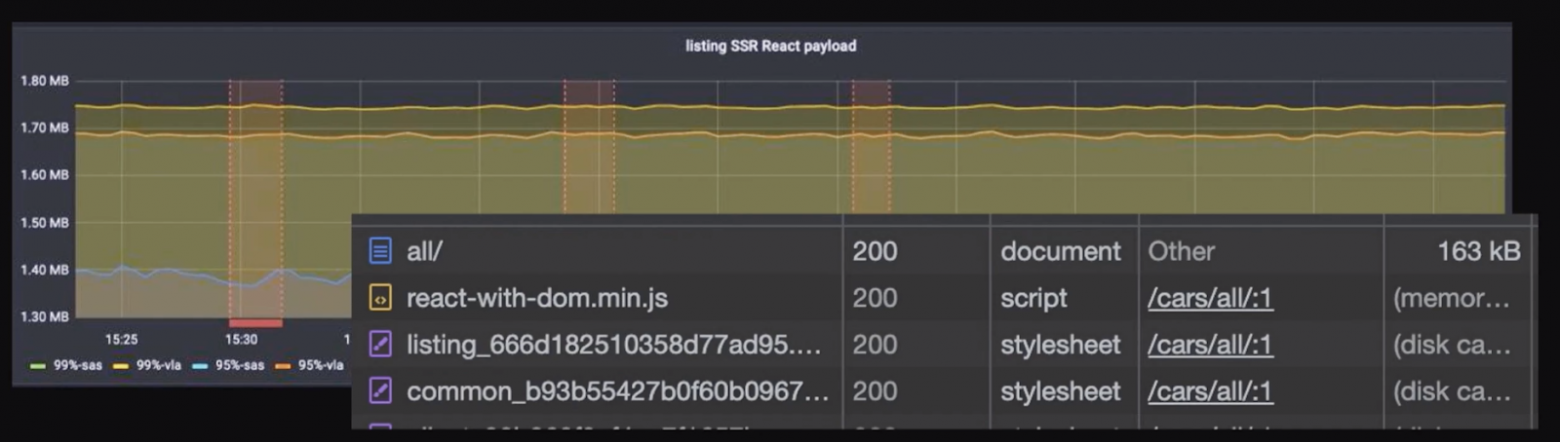
Когда мы уменьшили размер листинга и стали запрашивать в два раза меньше данных, то сократился и размер payload’a, и размер HTML.

Здесь видно, что TTFB изменился на 230 миллисекунд, а FCP изменился гораздо сильнее — на 400 миллисекунд. Это произошло потому, что мы стали гонять меньше данных по сети.
Еще я заметила, что в листинге мы отправляем в payload все данные, которые нам пришли по каждому объявлению, в том числе и текстовые описания от владельца авто, куда можно поместить хоть «Войну и мир» (при том, что на листинге описание мы вообще не показываем). Когда я удалила из payload’а описания объявлений, также случился прирост скорости. На тот момент я еще не знала, что буду выступать на HolyJS, поэтому скрины логов не сохранились. Но если вы будете работать над оптимизацией, то не повторяйте моих ошибок и сохраняйте всё!
После того, как клиенты начали скачивать HTML и парсить его, скорее всего, браузер найдет подключенные CSS и JS файлы и начнет их загружать. Здесь опять, чем меньше размер файлов, тем быстрее они скачаются. Но также важен порядок, в котором они подключены. Посмотрим на порядок загрузки CSS и JS для карточки объявления в мобильной версии Авто.ру.

Сначала импорт CSS и JS выглядел на карточке вот так:
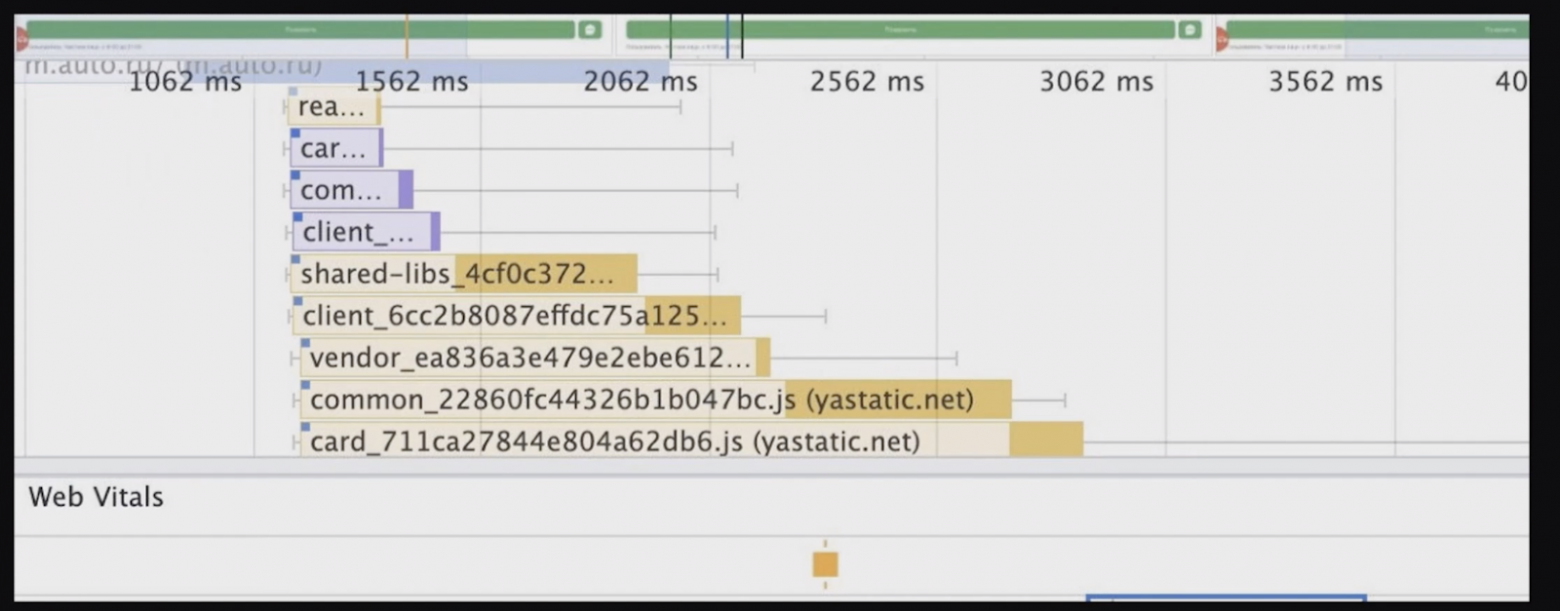
Браузер начинает парсить HTML, видит импорты и начинает всё грузить одной кучей. Казалось, что это неплохо, потому что всё грузится параллельно, и это всё нам очень нужно. Но когда мы грузим одновременно 10 файлов, то каждый конкретный файл скачивается медленнее, чем если бы мы скачивали их по отдельности.
Для рендеринга нам важнее CSS-файлы, поэтому я попробовала сначала грузить CSS, а позже JS. Порядок стал вот такой:
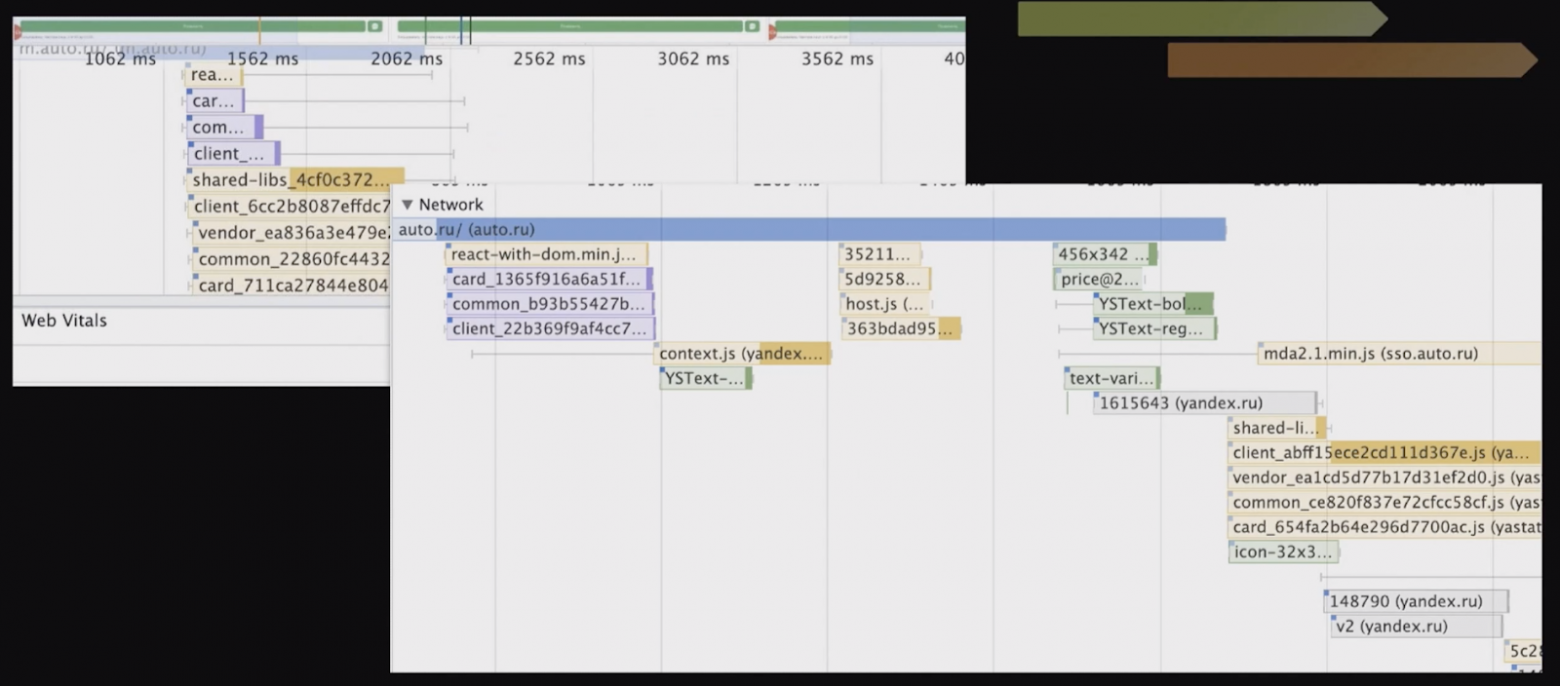
Это дало неплохой буст в FCP и LCP. Видно, что TTFB при этом не изменился, это чисто клиентская часть.
Поскольку JS теперь начинает грузиться немного позже, может немного пострадать TTI и total blocking time, но в данном случае этого не произошло. Но если вы начинаете играться с порядком импортов, то нужно понимать, что одни параметры могут улучшаться за счет ухудшения других.
В моем кейсе улучшение скорости было заметным:

Контент

После CSS и JS или, может быть, одновременно с ними, начинает грузиться контент — картинки, видео, шрифты, иконки.
Для LCP в карточке объявления, которую я показывала ранее, была важна самая первая фотография. Она начинает грузиться вот здесь:

Когда я смотрела на то, что происходит в консоли в network для этой карточки, я увидела, что первое фото начинает грузиться с большой задержкой. Всё потому, что на этом месте был скелетон и фото грузилось лениво:

Видимо, кто-то читал много советов по улучшению перфоманса и подумал, что все фотки нужно сделать с lazy-загрузкой. Когда мы убрали эту «ленивость», стало вот так:
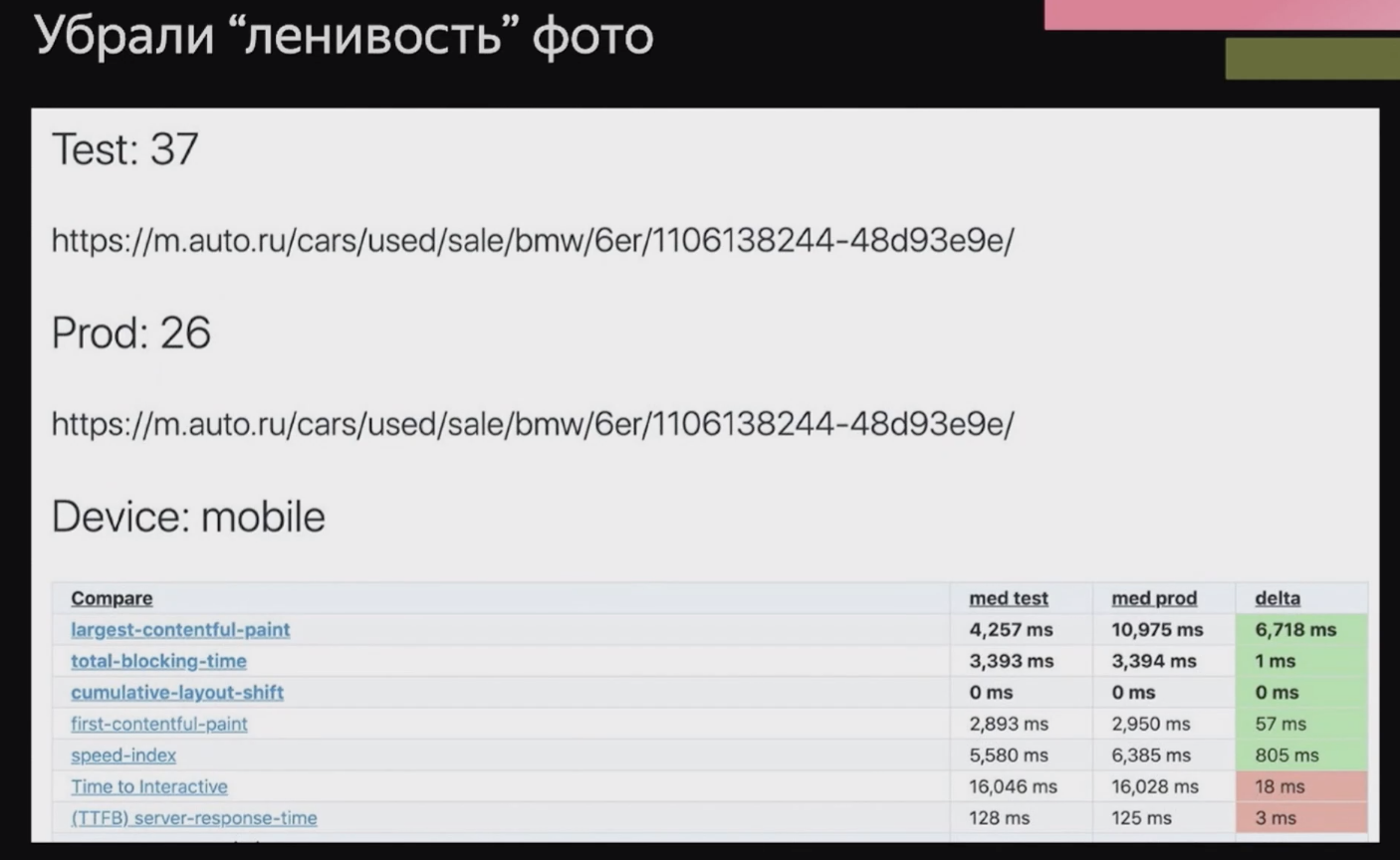
LCP драматически улучшился с 10 миллисекунд до 4 (при этом FCP и TTFB не поменялись).
Рендеринг

На скорость того, как клиент рендерит HTML и CSS, мы повлиять не можем. Но всё же, чем меньше мы ему пришлем HTML, тем быстрее он его отрисует. Мой пример про уменьшение листинга здесь также сработал.
Во время рендера у нас может появиться Cumulative Layout Shift. Это можно посмотреть на вкладке Lighthouse в консоли.
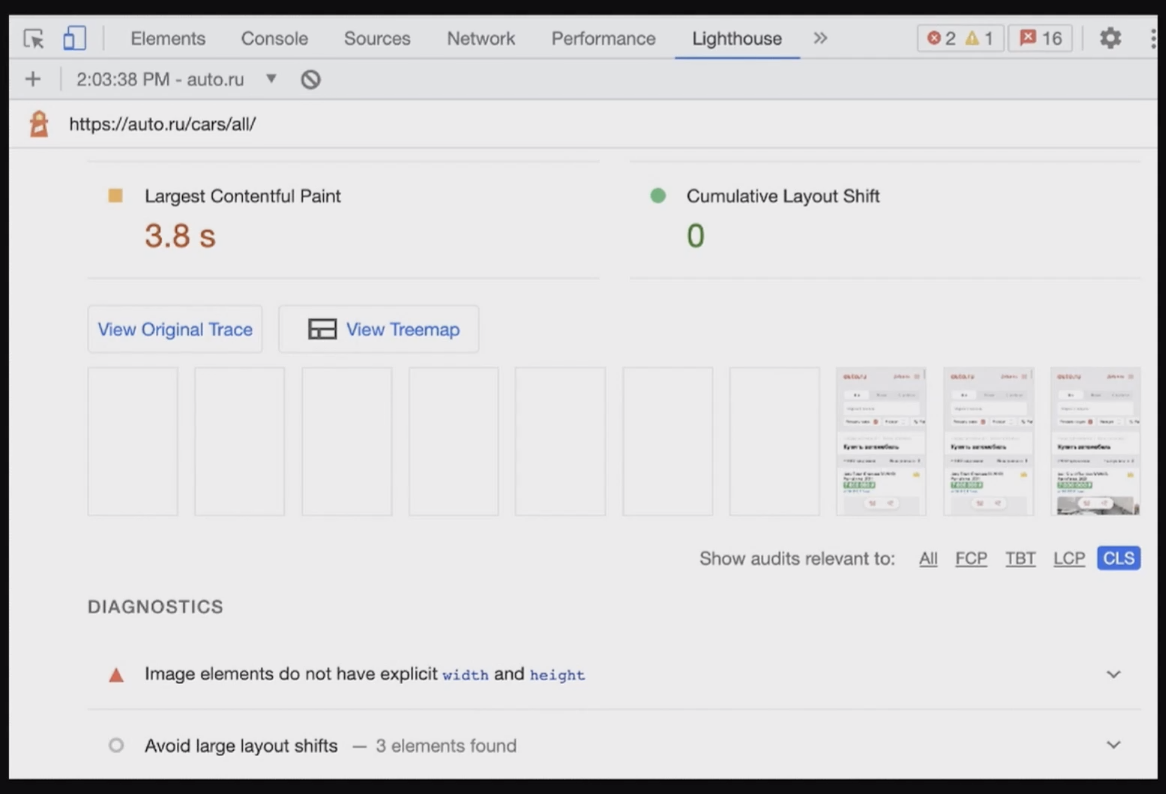
Здесь есть отдельный блок про CLS, там есть аналитика по конкретным элементам и советы, что можно сделать.
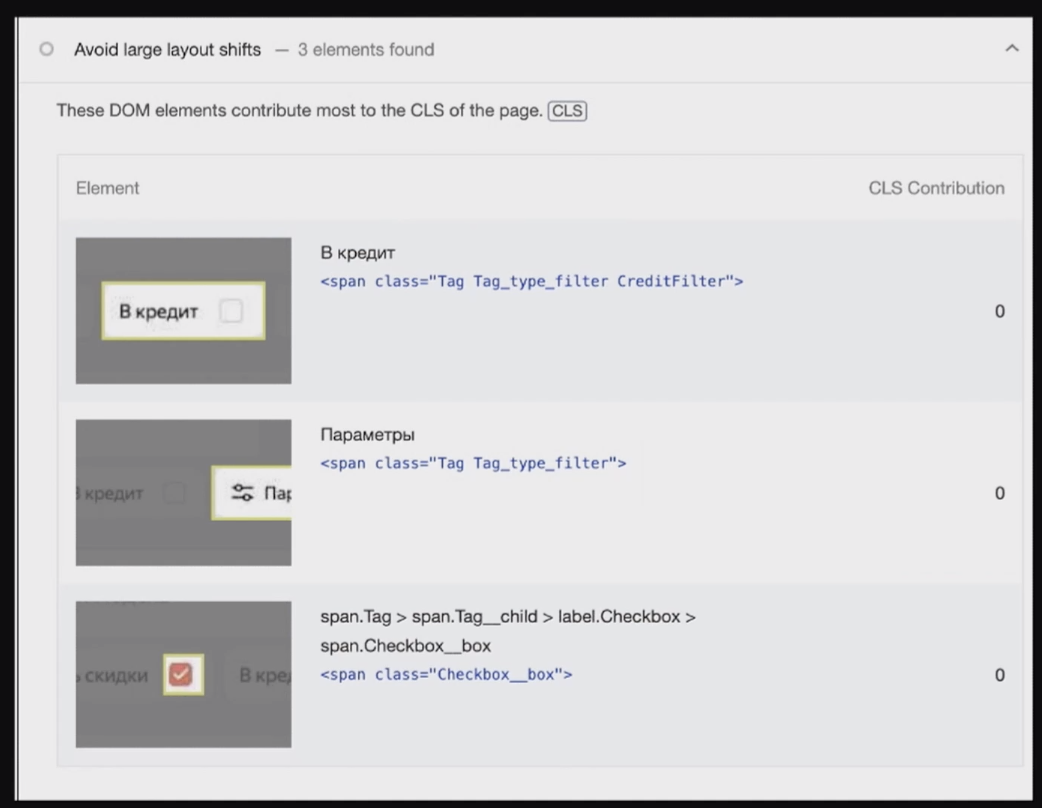
В отношении CLS это очень хороший инструмент, который работает довольно точно и говорит, что и где поправить.
Конкретно в этом месте с показателями у нас всё хорошо, поэтому примеров оптимизации я не покажу.
Выполнение JS

Последний этап работы нашего приложения — выполнение JavaScript.
Его также можно посмотреть в консоли и увидеть такую «красивую бороду»:
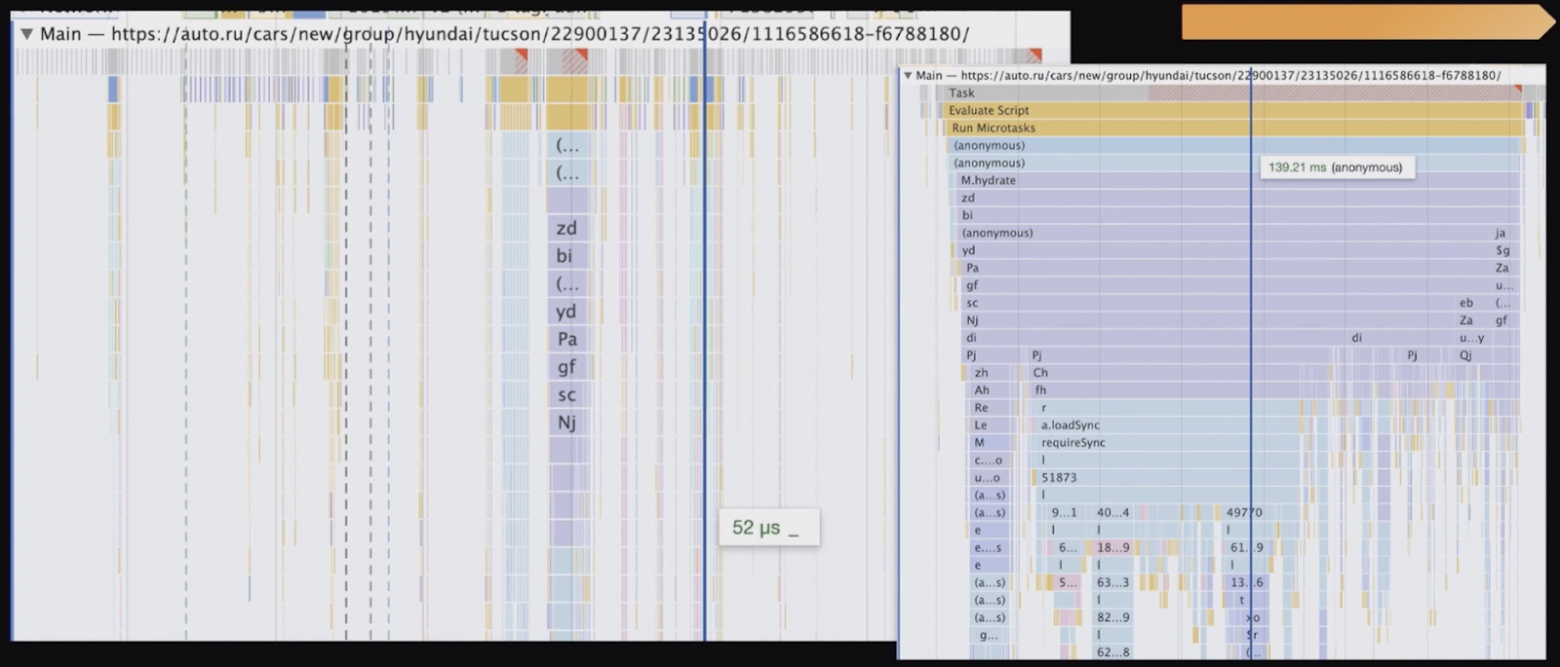
Честно говоря, я не очень понимаю, что полезного тут можно увидеть. Если вы понимаете, как с этим работать, позовите меня на свой воркшоп ?
Однажды я нашла в интернете видео «Как сделать стопроцентный score в Lighthouse». Там берут сайт, запускают Lighthouse аудит и смотрят, какая цифра получается. После этого начинают отключать разные штуки — например, чат-помощник, метрики, Google Analytics. И в конце, когда они отключили все скрипты и осталась одна верстка, у них получился score 100. Как способ оптимизации — сомнительно, но отсюда можно получить отличный метод оценки, сколько конкретная фича вашего приложения «стоит» для вашего перформанса.
И я в Авто.ру использовала этот подход: у нас есть разные скрипты, не относящиеся напрямую к контенту страницы, которые мы подключаем. Я пробовала их «отрывать», запускать тесты на скорость и смотреть, что будет получаться.
Этим способом я нашла, что скрипт антиробота, который определяет ботов, отрабатывал несколько секунд. Мы вынесли этот скрипт в iframe и он точно также работал, но не блокировал основной поток. Поэтому получилось урезать TTI на 4 секунды.

Еще один пример — много времени отнимает гидрация. Для React и ряда других библиотек после того, как сервер сгенерировал верстку и она попала на клиент, ее надо «оживить» и навесить обработчики событий — это и называется гидрацией. Изначально она происходит со всей страницей, от и до. Если в нашем листинге десятки объявлений, то пока они все не «оживятся», гидрация не закончится и пользователь не сможет начать взаимодействовать с контентом. Но пользователь при открытии страницы видит только первые 2-3 объявления, а не все сразу. Так что гидрацию можно сделать «ленивой» и гидрировать сниппеты по мере того, как они попадают во viewport пользователя.
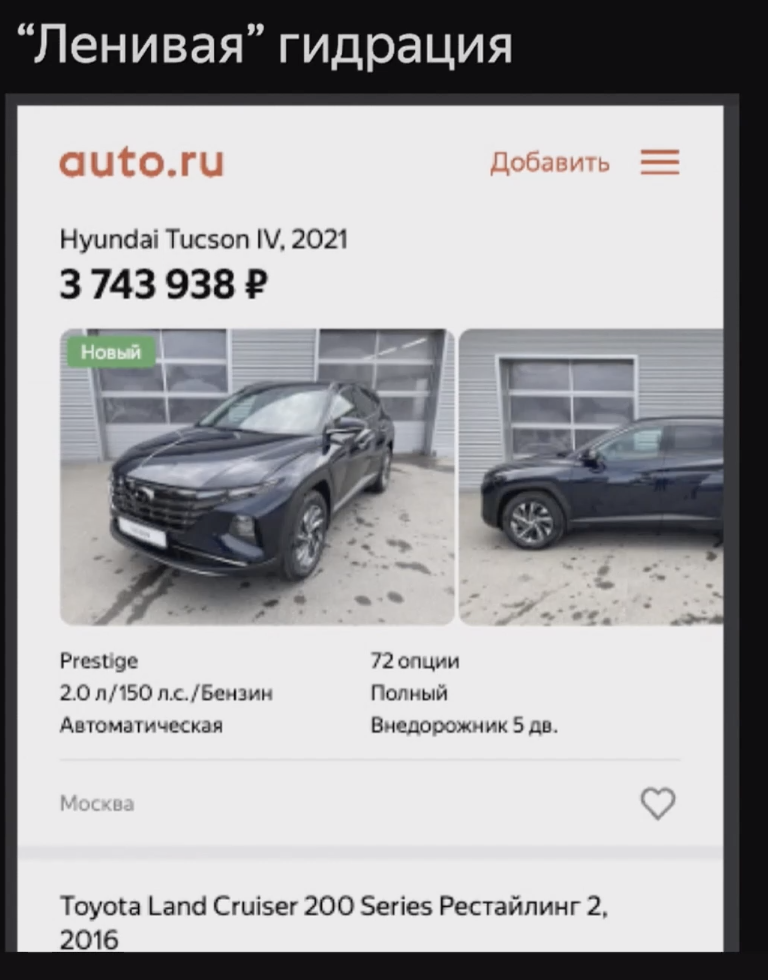
Для этого даже есть готовая библиотека для React. Там пять строчек кода и очень простая концепция, но она дает прирост в скорости:

Мы прошли по всем этапам работы приложения и везде, где смогли, улучшили его. Теперь поговорим об инструментах, которые помогали работать над перфомансом.
Метрики и инструменты
Самое простое, что есть для измерения скорости – это Pagespeed от Google, где можно ввести URL и получить аналитику. Этот инструмент включает в себя и Lighthouse-аудит, и данные, собранные на реальных пользователях.
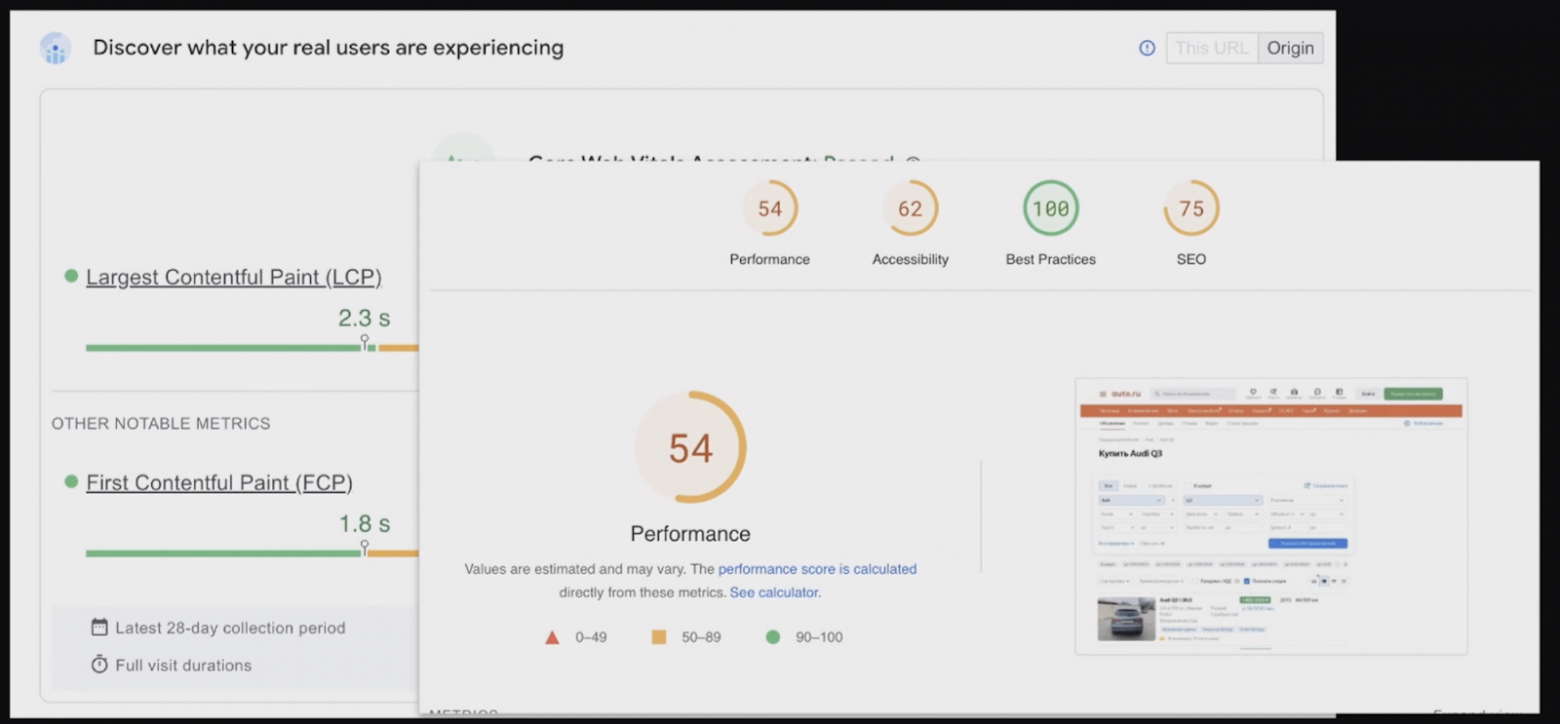
Если у вас большое приложение с несколькими тысячами URL, то, скорее всего, вы не будете их все туда вводить и составлять табличку в Excel. Но у Pagespeed есть API, и по нему можно собрать графики — например, такие, как я показывала ранее:

Также вы можете собрать графики по конкурентам, чтобы сравнивать ваши и их показатели.
Ещё, конечно, можно использовать Chrome Dev Tools.
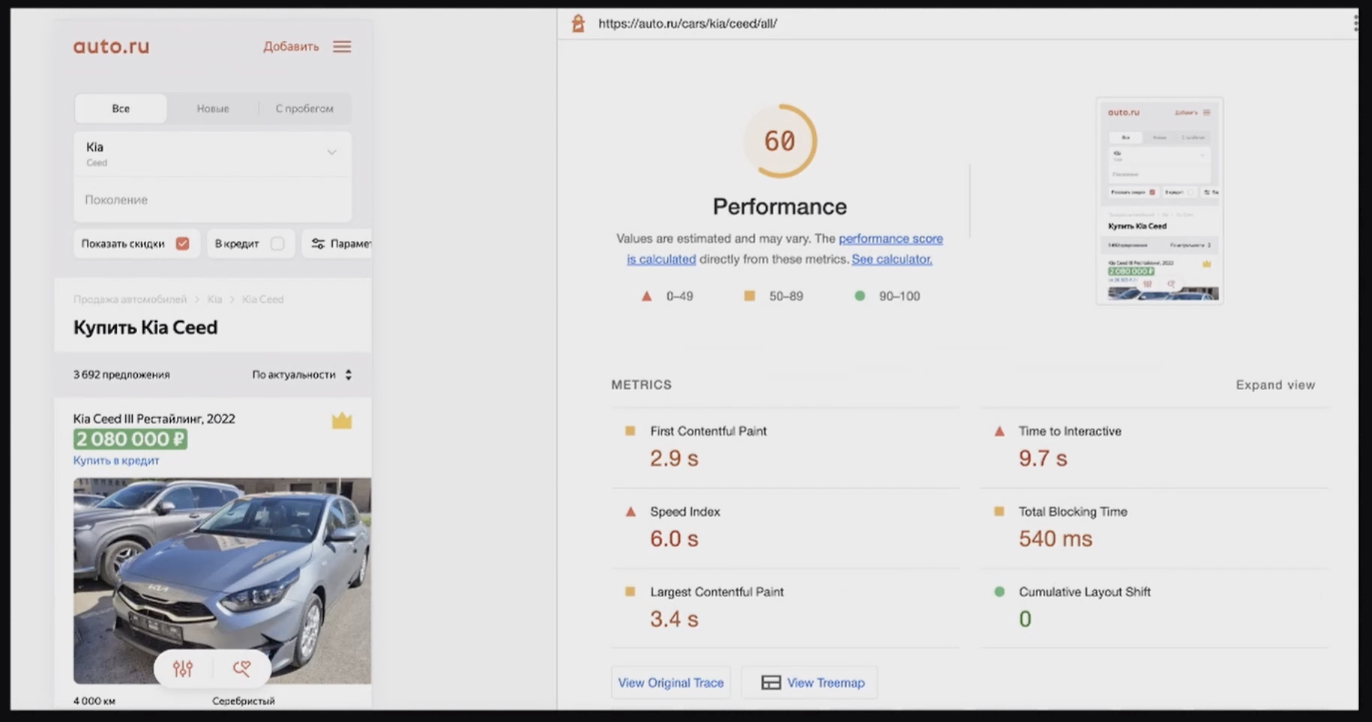
В нем есть инструменты Lighthouse-аудита и вкладка Performance, на которой в том числе видно, в каком порядке загружаются ресурсы, в каком порядке выполняется JS.

Инструмент, где я показывала сравнение наших метрик «до и после», написал наш коллега из отдела тестирования. Изначально его делали, чтобы собирать каждую ночь статистику по скорости, строить график и смотреть, не деградируем ли мы. Оказалось, что даже на большом количестве запусков разница между замерами получается существенная — даже на одной и той же версии, в одно и то же время суток перфоманс сильно гуляет. Поэтому сравнивать день ко дню не получилось. А вот сравнивать одновременно две версии оказалось очень удобно. Фишка в том, что можно запускать одновременно два аудита много раз, дальше считать всю статистику в виде такой таблички:

Еще одна моя любимая функция в нем — то, что мы реально можем экспериментировать, сделать что-то, что мы точно не хотим катить на живых пользователей (например, «оторвать» половину кода), получить метрики скорости и таким образом искать наиболее долгие, затратные, проблемные места в приложении.

Этот инструмент собран на базе sitespeed.io, он сравнивает две версии и его запуск можно конфигурировать. То есть можно настраивать количество тестов, включать мобильную версию, использовать или отключать кэш, задать cookies и т. д.
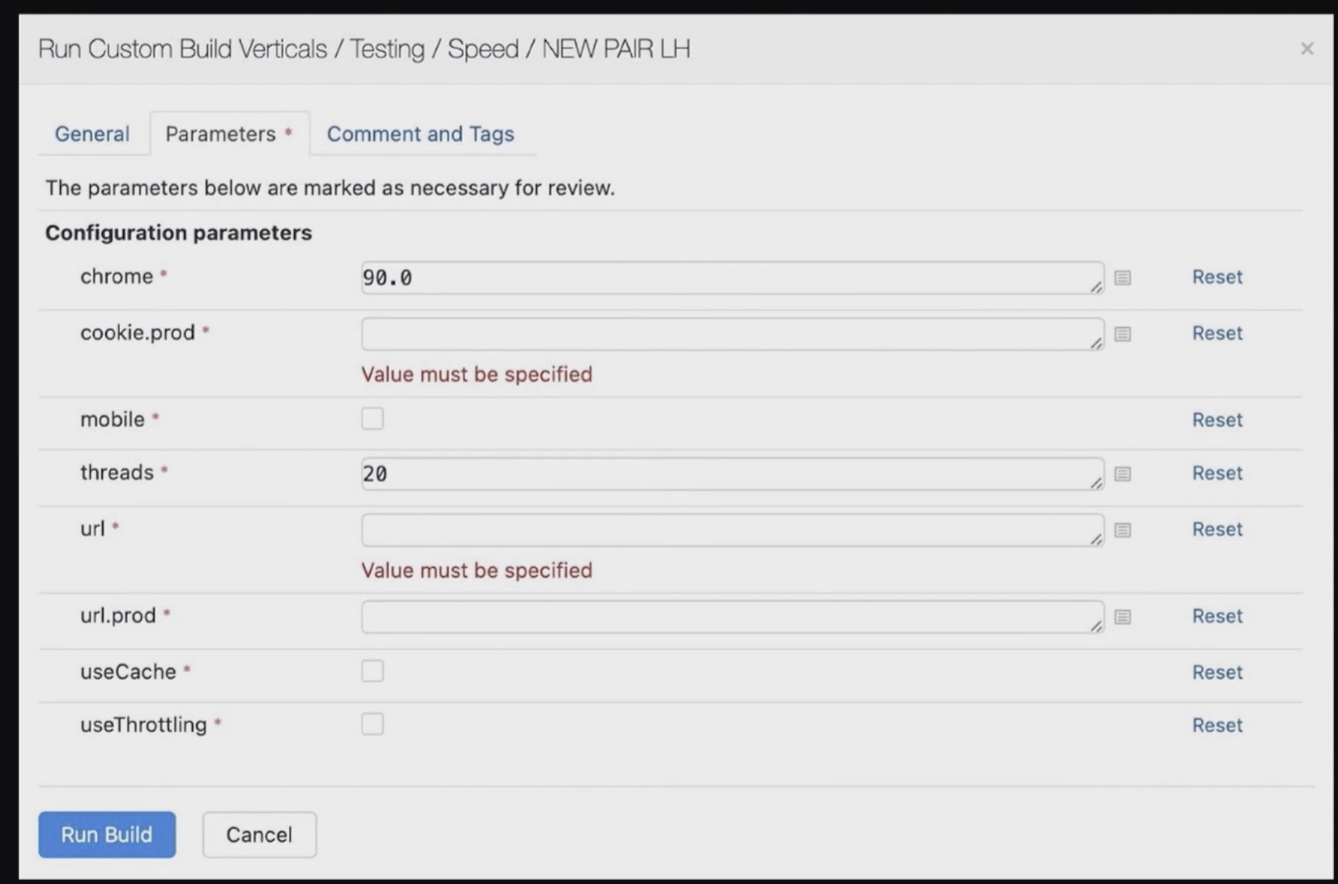
Если интересно, пишите мне в телеграм — я расскажу подробнее или дам контакты разработчика.
Также я немного показывала Real Using Monitoring (RUM).

Это метрики, которые собираются с реальных пользователей. Тут довольно много разных параметров и можно смотреть, как влияют на перфоманс эксперименты, которые вы выкатили на пользователей. Но, мне кажется, для тестирования гипотез он не подходит. Лучше использовать его для проверки того, что вы не деградируете и чтобы посмотреть показатели скорости у реальных пользователей.
Также для поиска проблемных мест в сервисе может подойти Google Search Console. Она дает вот такой отчет, в котором Google пишет, на каких URL какие показатели ему не нравятся:

В каждый из этих параметров можно провалиться и посмотреть проблемные URL.
Также я показывала трейсы в Jaeger — это опенсорс, так что можете себе прикрутить.

Еще я показывала метрики в Prometheus, которые мы используем для логирования времени и payload’а SSR.

Также показывала логи — это просто интерфейс в Grafana.

Спасибо за внимание!
Минутка рекламы: если вас заинтересовал этот доклад, наверняка что-то интересное для вас найдётся и на следующей HolyJS. Она пройдёт 15–16 мая в онлайне и 21–22 мая в формате «Москва + онлайн»: можно будет хоть лично прийти на конференционную площадку, хоть подключиться с другого конца света.


{kind=link}