О необходимости выполнения резервного копирования для любых важных данных, будь то файлы, образ ОС или базы данных, написано множество статей. Поэтому убеждать читателя в необходимости бэкапить СУБД MySQL я не буду. Напомню лишь, что помимо бэкапа необходимо регулярно проверять резервные копии на возможность восстановления.
Следующий раздел предназначен для тех, кто не читал статью по бэкапам PostgreSQL, так как он повторяет основные моменты теории резервного копирования.
Сколько терять и за сколько восстанавливать
Итак, вспомним такие понятия как RPO и RTO.
Recovery Point Objective – максимально допустимый интервал за который мы можем позволить себе потерять данные. Например, если у нас RPO равно двум часам, то в случае сбоя мы потеряем данные максимум за последние два часа.
Recovery Time Objective - промежуток времени, в течение которого БД может оставаться недоступной в случае сбоя. То есть это то время, за которое мы обязуемся восстановить наши данные из бэкапа.
На картинке расстояние до сбоя это RPO (обычно измеряется в часах) а RTO это то расстояние-время, которое у нас останется на восстановление.

Однако, RTO и RPO нельзя назвать чисто техническим понятиями, в определенной степени это характеристики, позволяющие обеспечивать непрерывность бизнес процессов. Значения величин RTO и RPO должны указываться владельцами бизнес систем, а ИТ специалисты должны в ответ выдвинуть свои требования относительно оборудования и программного обеспечения для выполнения этих требований. Например, если бизнесу необходимо, чтобы в случае аварии данные были потеряны не более чем за час, а процесс восстановления должен занимать не более 30 минут, то админы в ответ должны сказать хранилища какого размера им необходимы, с какими характеристиками по скорости работы дисков и каналов передачи данных. То есть ИТ готовит спецификацию на необходимое оборудование и ПО с ценами, бизнес посмотрев на все это пони мает, что может быть два или даже три часа простоя это не так уж и страшно, да и восстанавливаться можно подольше. В результате согласовываются новые значения RTO и RPO и стоимость спецификации снижается. Такой подход позволяет разделить ответственность между всеми сторонами. Однако очень часто присутствует другой подход к политике резервного копирования, когда ИТ сами устанавливают значения RTO и RPO и сами пытаются их выполнять без согласования с бизнесом, что является в корне неверным.
Виды бэкапов в MySQL
В СУБД MySQL имеются два вида бэкапов: логические и физические. Логический бэкап предполагает создание скрипта, в котором будут отражены все команды, которые необходимо выполнить для создания базы в ее текущем состоянии, со всеми актуальными данными.
Физический бэкап предполагает создание резервных копий на файловом уровне. В простейшем случае, мы просто останавливаем базу и копируем файлы из рабочей папки (/var/lib/mysql/db/). Просто и быстро. Но не стоит забывать, что при использовании для бэкапа команд операционной системы (например cp) возможны ситуации, когда полученные после копирования файлы окажутся поврежденными и база не будет работать корректно. Такое может произойти, например при копировании в моменты высокой загрузки сервера или при копировании по сети.
Недостатком физического бэкапа является необходимость полной совместимости новой инсталляции СУБД со старой версией. То есть, если мы не можем использовать другую версию СУБД при восстановлении.
А кроме того, остановка базы даже на короткое время в продакшене – идея не слишком хорошая, поэтому лучше все-таки делать бэкапы на лету.
Логический бэкап лишен этих недостатков, но восстановление большой БД может занять значительное время, так как выполнение всех команд из бэкапа процесс долгий.
Альтернативным вариантом является использование сторонних средств резервного копирования, например Percona XtraBackup.
Логический бэкап
Для экспорта информации из базы данных в формате SQL можно использовать утилиту mysqldump. Вот ее синтаксис:
$ mysqldump опции имя_базы [имя_таблицы] > файл.sql
Например:
mysqldump --all-databases > dump-data.sql
То есть мы указываем имя базы или таблицы и перенаправляем вывод в файл. Но бэкап можно делать также удаленно. Как правило в сети имеется централизованный сервер резервного копирования с которого осуществляются подключения к узлам для выполнения бэкапов. В таком случае синтаксис команды будет следующий:
mysqldump -h хост -P порт -u имя_пользователя -p имя_базы > data-dump.sql
Процесс восстановления тоже достаточно прост. Необходимо создать новую базу и в ней выполнить перенаправление скрипта из файла бэкапа.
mysql> CREATE DATABASE new_database;
shell> mysql < dump-data.sql
Однако, с практической точки зрения файлы бэкапов лучше сразу архивировать, особенно файлы логических бэкапов, потому что они являются по сути текстовыми и очень хорошо сжимаются.
В следующем примере мы делаем бэкап базы,заданной в переменной DBNAME и затем сжимаем полученный файл с помощью gzip.
mysqldump -uroot -p ${DBNAME} | gzip > /tmp/${DBNAME}.sql.gz
Когда нужно не все
Резервное копирование в больших базах может занимать значительное время. При этом, в процессе создания резервных копий увеличивается нагрузка на дисковую подсистему сервера и на сеть при передаче данных. Поэтому, бэкапы лучше делать в нерабочее время, например ночью. Но зачастую мы можем не успеть сделать полную копию БД за ночь так как данных слишком много. Решить эту проблему нам помогут инкрементальные резервные копии.
Суть заключается в том, что мы делаем полную резервную копию всех данных в выходные. А в будни по ночам бэкапим только изменения, произошедшие с момента последнего бэкапа. Тогда, при восстановлении нам сначала потребуется восстановить полную копию, а потом инкрементальные копии за каждый день, предшествовавший сбою.
Инкрементальная резервная копия содержит только ту информацию, которая изменилась после создания предыдущей резервной копии. Это существенно уменьшает размер резервных копий и позволяет вам делать такие резервные копии очень часто.
В MySQL вы можете реализовать создание инкрементальных резервных копий с помощью резервного копирования двоичных файлов журнала. Все транзакции, применяемые к серверу MySQL, последовательно записываются в двоичные файлы журнала. Следовательно, вы всегда можете восстановить исходную базу данных из этих файлов.
Для реализации такой стратегии нам необходимо прежде всего включить ведение двоичных журналов.
nano /etc/mysql/mysql.cnf
Укажем значение параметров log-bin, expire_log_days, max_binlog_size.
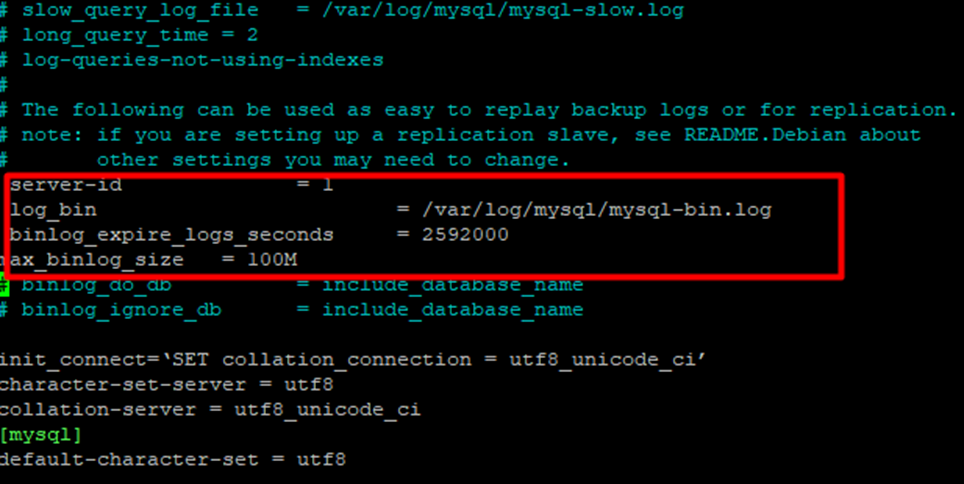
Далее перезапустим сервис.
service mysql restart
Каждая инкрементальная копия содержит изменения, которые были созданы с момента последней резервной копии, но самая первая резервная копия должна быть полной копией. Вам необходимо создать полную резервную копию через mysqldump, используя параметры --flush-log и --delete-master-logs, ––delete-master-logs удалит старые двоичные файлы журнала, а --flush-log инициализирует запись нового двоичного файла журнала. Результаты заархивируем.
mysqldump --flush-logs --delete-master-logs --single-transaction --all-databases | gzip > /var/backups/mysql/$(date +%d-%m-%Y_%H-%M-%S)-inc.gz
Мы не можем просто воспользоваться командой cp потому файлы журналов сейчас используются БД. Поэтому вам необходимо выполнить команду FLUSH BINARY LOGS, которая начнет запись в новый двоичный файл журнала. В этом случае все накопленные двоичные файлы журнала могут быть безопасно скопированы. После копирования двоичных файлов журнала они должны быть удалены, чтобы при следующем копировании они не дублировали уже созданные резервные копии данных. Для этого воспользуемся PURGE BINARY LOGS. Для автоматизации этих задач ниже приведен небольшой скрипт, который выполняет эти действия, а также помещает двоичные файлы журнала в архив.
#путь к файлу с двоичными журналами binlogs_path=/var/log/mysql/ #путь к каталогу с бэкапами backup_folder=/var/backups/mysql/ #создаем новый двоичный журнал sudo mysql -E --execute='FLUSH BINARY LOGS;' mysql #получаем список журналов binlogs=$(sudo mysql -E --execute='SHOW BINARY LOGS;' mysql | grep Log_name | sed -e 's/Log_name://g' -e 's/^[[:space:]]*//' -e 's/[[:space:]]*$//') #берем все, кроме последнего binlogs_without_Last=`echo "${binlogs}" | head -n -1` #отдельно последний, который не нужно копировать binlog_Last=`echo "${binlogs}" | tail -n -1` #формируем полный путь binlogs_fullPath=`echo "${binlogs_without_Last}" | xargs -I % echo $binlogs_path%` #сжимаем журналы zip $backup_folder/$(date +%d-%m-%Y_%H-%M-%S).zip $binlogs_fullPath #удаляем сохраненные файлы журналов echo $binlog_Last | xargs -I % sudo mysql -E --execute='PURGE BINARY LOGS TO "%";' mysql
Для регулярного выполнения данного скрипта его выполнение лучше всего прописать в планировщик cron. Вам необходимо запланировать как инкрементальное резервное копирование, так и полное резервное копирование. Выбирая временные интервалы, помните, что чем реже вы делаете полные резервные копии, тем больше времени потребуется на восстановление. Хорошим решением было бы запускать полную резервную копию каждую ночь и инкрементную резервную копию каждый час.
cron -e
0 0 * * * sudo mysqldump --flush-logs --delete-master-logs --single-transaction --all-databases | gzip > /var/backups/mysql/full_$(date +%d-%m-%Y_%H-%M-%S).gz
*/60 * * * * sudo bash ~/scripts/скрипт_инкрментального_бэкапа
Восстановление
Процесс восстановления должен выполняться в обратном порядке: сначала восстанавливаем полную копию, а затем инкрементальные бэкапы в отдельную папку.
gunzip < 01-10-2020_20-08-41-full.gz
unzip \*.zip -d logs
cd logs
В отличие от полной резервной копии, созданной с помощью mysqldump, двоичные файлы журнала содержат двоичные данные. Перед их восстановлением их необходимо преобразовать в sql-выражения, и за это отвечает утилита mysqlbinlog. Эта утилита получает двоичные файлы журнала в качестве входных данных и возвращает инструкции sql. Несколько файлов можно перечислить через пробел. Не забываем о том, что порядок перечисления файлов очень важен, именно в таком порядке SQL операторы и будут выполнены.
mysqlbinlog mysql-bin.000040 mysql-bin.000059 mysql-bin.000123 | sudo mysql -u root
А вообще можно не перечислять файлы вручную, а просто воспользоваться командой:
mysqlbinlog $(ls) | sudo mysql -u root
Таким образом можно снизить время, необходимое на создание бэкапов и сэкономить место для их хранения.
Заключение
В заключении хотелось бы напомнить материал предыдущей статьи, где говорилось о репликациях, а именно о том, что бэкапы лучше делать с реплики, так как это менее нагруженный узел и выполнение бэкапа не скажется на работе пользователей с базой.
Также напоминаю о том, что уже скоро в OTUS пройдет открытое занятие, посвященное погружению в PostgreSQL. Урок будет включать в себя:
Знакомство с базой данных – особенности, немножко истории, полезность и актуальность.
Способы развертывания и установки, сама установка.
Практическая часть: рассмотрим особенность, присущую этой базе данных – например, способ хранения данных, разбор сложной задачи и различных вариантов построения архитектуры ее решения.
Записаться можно на странице курса «Базы данных».

