(Первые части: 1 2 3 4 5). Надеюсь, разговор о естественном языке читателей ещё не утомил! По-моему, тематика действительно интересная (хотя популярность топиков явно идёт на убыль :) ). Что ж, посмотрим, на сколько частей меня ещё хватит. Думаю, экватор мы уже прошли, но три-четыре темы затронуть ещё можно.
На сей раз заметка полностью посвящена проекту XDG/XDK, который я пытаюсь изучать на досуге. Назвать себя специалистом по XDG пока ещё не могу. Но потихоньку двигаюсь.
Итак, мы остановились на том, что будем рассматривать dependency parsing, причём, по возможности, с непроективными конструкциями и множественной генерацией деревьев. Это естественным путём приводит нас к проекту XDG/XDK, удовлетворяющему все эти требования. Я сам пришёл «в тему» с симпатиями к lexicalized dependency parsing, но в остальном начинаю почти что с чистого листа, и выбор XDG продиктован холодным отсеиванием прочего. Изучал, что есть, выбирал, что лучше. На сегодня так оказалось, что XDG вроде как лучше (по крайней мере, в рамках заданной концепции).
Что же это такое? XDG расшифровывается как Extensible Dependency Grammar, а XDK, соответственно, как XDG Development Kit. XDG представляет собой формализм для описания допустимых связей между словами в предложении. Это лексикализованный формализм: для каждого конкретного слова языка придётся описать, каким же образом и с чем его можно клеить. XDK включает в себя набор инструментов, наиболее важным из которых является Solver, он же синтаксический анализатор. Solver принимает на входе грамматику языка и предложение на нём. На выходе генерируется множество деревьев, соответствующих разобранному предложению. Как видите, на словах всё очень просто :)
Что касается способа записи этих правил — мне он представляется достаточно очевидным и адекватным. Полагаю, что с помощью XDG можно описать не только естественный язык, но и, скажем, Паскаль. Конечно, такой парсер будет далёк от совершенства, но работать, по идее, должен :)
Даже не знаю, почему раньше никто за такую работу (dependency parser kit) не брался. Проект-то достаточно свежий, текущая версия датирована 2007 годом (впрочем, я уже говорил, что особых восторгов по поводу XDK не замечаю пока, и на данный момент проект не развивается).
Наверно, имеет смысл дать немного «пощупать» язык предлагаемых грамматик. Он зиждется на трёх базовых принципах:
Лексикализация. Элементами грамматики являются слова языка. Каждому слову может быть приписан набор атрибутов, собственно, и определяющий, что слово может приклеить к себе и к чему оно может приклеиться само. У каждого атрибута есть имя, тип и значение. Чаще всего используются типы «строка» и «множество строк».
Принципы создания графа. Помимо ограничений на «склейку», задаваемых на уровне отдельных слов, можно задать ограничения для всего графа разбора фразы. Такие ограничения называются «принципами». Простейший пример принципа — tree principle, требующий того, чтобы генерируемый граф был деревом. О некоторых других полезных принципах поговорим чуть позже.
Многомерность. Каждый атрибут слова определяется в некотором пространстве имён (задаваемом пользователем). Принципы создания графа также описываются в определённом простанстве имён. Каждое такое пространство называется «измерением». Граф разбора фразы для каждого измерения строится отдельно. Таким образом, можно получить сразу несколько графов разбора, отражающих те или иные структурные особенности предложения (то есть пользователь может посмотреть на предложение как бы под разными углами зрения). Например, наряду с dependency-графом можно построить вырожденный граф-список, показывающий порядок следования слов в предложении. Или, скажем, граф, соединяющий между собой все существительные фразы.
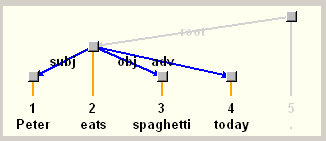
Спецификация атрибута out глагола «eats» указывает, что слово может присоединить к себе один субъект (subj), один объект (obj) и произвольное количество обстоятельств (adv*). Спецификация атрибута in слова «Peter» разрешает этому слову быть субъектом или объектом. Такова же и спецификация слова «spaghetti». Слово «today» описано как потенциальное обстоятельство. Таким образом, если мы скормим парсеру фразу «Peter eats spaghetti today», итоговое дерево будет иметь «eats» в качестве корня, «Peter» и «spaghetti» будут присоединены к корню в качестве субъекта и объекта, а слово «today» — в качестве обстоятельства.
Существует ещё «принцип упорядоченности» (пожертвую им ради экономии места), с помощью которого можно указать, что более раннее слово в предложении имеет приоритет в качестве субъекта (таким образом, «spaghetti» субъектом не станет).
Чтобы слово «Peter» присоединялось и теперь, придётся указать его атрибуты числа и лица:
Как видно из этих примеров, грамматика напрямую не поддерживает морфологию. Так, слова «eat» и «eats» для неё разные. Впрочем, я и не совсем понимаю, как в универсальный формализм можно запихнуть поддержку «морфологии вообще». Решается эта проблема, однако, достаточно просто: надо прогонять входное предложение через морфологический анализатор и генерировать правила грамматики (с правильными окончаниями и атрибутами слов) автоматически, «на лету».
Разбор заканчивается тогда, когда удалось собрать всю конструкцию и присоединить её к слову, имеющему атрибут «вершина дерева». Например, в качестве такого слова можно описать точку (ибо точкой кончается предложение):
Здесь предлагаю поставить если не точку, то точку с запятой, потому что «кратко» продолжить не получится. Следующий «блок мыслей» тянет на отдельный пост (завтра, вероятно?..) Продолжим про XDG, скорее всего.
Разве что, дабы не возвращаться к этому вопросу, перечислю проблемы XDK, бросающиеся в глаза. Во-первых, нынешний билд собран под ASCII с поддержкой западноевропейских языков. То есть кириллица превращается в крякозяблы (разбирать всё равно будет, но дебажить неудобно). Впрочем, проблема это небольшая, как мне кажется. Во-вторых, автор защитил диссер и ушёл работать в промышленность, больше он проект не поддерживает, а никто другой пока не подобрал, даром что open source. В-третьих, «войти в проект» не так-то просто, ибо всё написано на сравнительно маргинальной среде программирования Mozart/Oz в парадигме constraint programming. За это как раз автора сложно критиковать — задача уж очень специфическая. Я уже говорил, что полноценный разбор тянет на NP-полную задачу. Автор же рассмотрел парсинг как constraint satisfaction problem: даны узлы графа и дан набор условий, ограничивающих рёбра. Требуется найти удовлетворяющий условиям граф. То есть задачу поставили в более общем виде, и в итоге было решено применить специализированный инструмент для такого рода вещей. Правильно сделали. Есть ещё кое-что, не хватающее лично мне, но об этом в следующий раз.
На сей раз заметка полностью посвящена проекту XDG/XDK, который я пытаюсь изучать на досуге. Назвать себя специалистом по XDG пока ещё не могу. Но потихоньку двигаюсь.
Итак, мы остановились на том, что будем рассматривать dependency parsing, причём, по возможности, с непроективными конструкциями и множественной генерацией деревьев. Это естественным путём приводит нас к проекту XDG/XDK, удовлетворяющему все эти требования. Я сам пришёл «в тему» с симпатиями к lexicalized dependency parsing, но в остальном начинаю почти что с чистого листа, и выбор XDG продиктован холодным отсеиванием прочего. Изучал, что есть, выбирал, что лучше. На сегодня так оказалось, что XDG вроде как лучше (по крайней мере, в рамках заданной концепции).
Что же это такое? XDG расшифровывается как Extensible Dependency Grammar, а XDK, соответственно, как XDG Development Kit. XDG представляет собой формализм для описания допустимых связей между словами в предложении. Это лексикализованный формализм: для каждого конкретного слова языка придётся описать, каким же образом и с чем его можно клеить. XDK включает в себя набор инструментов, наиболее важным из которых является Solver, он же синтаксический анализатор. Solver принимает на входе грамматику языка и предложение на нём. На выходе генерируется множество деревьев, соответствующих разобранному предложению. Как видите, на словах всё очень просто :)
Сочинение грамматики
Откуда взять грамматику? Вот здесь я хотел бы подчеркнуть: да, в простейшем сценарии (хотя для разработчика он явно не самый простой :) ) грамматика пишется вручную. Однако не будем забывать, что грамматические правила представляют собой лишь точное формальное описание языковых конструкций. И откуда они получены — написаны экспертами или выведены каким-то образом из существующих текстов — вопрос второй. Как бы то ни было, для точного анализа предложений нужны правила, и грамматика — всего лишь разновидность их записи.Что касается способа записи этих правил — мне он представляется достаточно очевидным и адекватным. Полагаю, что с помощью XDG можно описать не только естественный язык, но и, скажем, Паскаль. Конечно, такой парсер будет далёк от совершенства, но работать, по идее, должен :)
Даже не знаю, почему раньше никто за такую работу (dependency parser kit) не брался. Проект-то достаточно свежий, текущая версия датирована 2007 годом (впрочем, я уже говорил, что особых восторгов по поводу XDK не замечаю пока, и на данный момент проект не развивается).
Наверно, имеет смысл дать немного «пощупать» язык предлагаемых грамматик. Он зиждется на трёх базовых принципах:
Лексикализация. Элементами грамматики являются слова языка. Каждому слову может быть приписан набор атрибутов, собственно, и определяющий, что слово может приклеить к себе и к чему оно может приклеиться само. У каждого атрибута есть имя, тип и значение. Чаще всего используются типы «строка» и «множество строк».
Принципы создания графа. Помимо ограничений на «склейку», задаваемых на уровне отдельных слов, можно задать ограничения для всего графа разбора фразы. Такие ограничения называются «принципами». Простейший пример принципа — tree principle, требующий того, чтобы генерируемый граф был деревом. О некоторых других полезных принципах поговорим чуть позже.
Многомерность. Каждый атрибут слова определяется в некотором пространстве имён (задаваемом пользователем). Принципы создания графа также описываются в определённом простанстве имён. Каждое такое пространство называется «измерением». Граф разбора фразы для каждого измерения строится отдельно. Таким образом, можно получить сразу несколько графов разбора, отражающих те или иные структурные особенности предложения (то есть пользователь может посмотреть на предложение как бы под разными углами зрения). Например, наряду с dependency-графом можно построить вырожденный граф-список, показывающий порядок следования слов в предложении. Или, скажем, граф, соединяющий между собой все существительные фразы.
Принцип валентности
Теперь пару слов о том, какие бывают принципы. Хочется прежде всего упомянуть принцип валентности, указывающий, что связь между двумя словами w1 и w2 может быть установлена только если атрибут out слова w1 совпадает с атрибутом in слова w2. Поясню на примере:
defentry { dim lex { word: "eats"}
dim syn {in: {root} out: {subj obj adv*}}}
defentry { dim lex {word: "Peter"}
dim syn {in: {subj? obj?} out: {} } }
defentry { dim lex {word: "spaghetti"}
dim syn {in: {subj? obj?} out: {} } }
defentry { dim lex {word: "today"}
dim syn {in: {adv?} out: {} } }Спецификация атрибута out глагола «eats» указывает, что слово может присоединить к себе один субъект (subj), один объект (obj) и произвольное количество обстоятельств (adv*). Спецификация атрибута in слова «Peter» разрешает этому слову быть субъектом или объектом. Такова же и спецификация слова «spaghetti». Слово «today» описано как потенциальное обстоятельство. Таким образом, если мы скормим парсеру фразу «Peter eats spaghetti today», итоговое дерево будет иметь «eats» в качестве корня, «Peter» и «spaghetti» будут присоединены к корню в качестве субъекта и объекта, а слово «today» — в качестве обстоятельства.
Существует ещё «принцип упорядоченности» (пожертвую им ради экономии места), с помощью которого можно указать, что более раннее слово в предложении имеет приоритет в качестве субъекта (таким образом, «spaghetti» субъектом не станет).
Принцип согласуемости
Это ещё один важный принцип, мимо которого пройти не могу. Он устанавливает следующее требование: связываемые слова должны согласоваться по какому-либо атрибуту. Например, можно указать, что глагол «eats» в качестве субъекта требует третье лицо, единственное число. В то же самое время глагол «eat» присоединит что угодно, кроме третьего лица, единственного числа:defentry { dim lex { word: "eats" }
dim syn { agrs: {["3" sg]}
agree: {subj} } }
defentry { dim lex { word: "eat" }
dim syn { agrs: {["1" sg] ["2" sg]
["1" pl] ["2" pl] ["3" pl]}
agree: {subj}}Чтобы слово «Peter» присоединялось и теперь, придётся указать его атрибуты числа и лица:
defentry { dim lex { word: "Peter" }
dim syn { agrs: {["3" sg]}
agree: {}} }Как видно из этих примеров, грамматика напрямую не поддерживает морфологию. Так, слова «eat» и «eats» для неё разные. Впрочем, я и не совсем понимаю, как в универсальный формализм можно запихнуть поддержку «морфологии вообще». Решается эта проблема, однако, достаточно просто: надо прогонять входное предложение через морфологический анализатор и генерировать правила грамматики (с правильными окончаниями и атрибутами слов) автоматически, «на лету».
Разбор заканчивается тогда, когда удалось собрать всю конструкцию и присоединить её к слову, имеющему атрибут «вершина дерева». Например, в качестве такого слова можно описать точку (ибо точкой кончается предложение):
defentry {
dim lex {word: "."}
dim syn {in: {}
out: {root}
agrs: top
}}Пуск!
Если полученную грамматику (разумеется, тут приведены лишь её фрагменты!) скормить анализатору вместе со входной строкой «Peter eats spaghetti today .», на выходе будет сгенерировано вполне ожидаемое дерево:Здесь предлагаю поставить если не точку, то точку с запятой, потому что «кратко» продолжить не получится. Следующий «блок мыслей» тянет на отдельный пост (завтра, вероятно?..) Продолжим про XDG, скорее всего.
Разве что, дабы не возвращаться к этому вопросу, перечислю проблемы XDK, бросающиеся в глаза. Во-первых, нынешний билд собран под ASCII с поддержкой западноевропейских языков. То есть кириллица превращается в крякозяблы (разбирать всё равно будет, но дебажить неудобно). Впрочем, проблема это небольшая, как мне кажется. Во-вторых, автор защитил диссер и ушёл работать в промышленность, больше он проект не поддерживает, а никто другой пока не подобрал, даром что open source. В-третьих, «войти в проект» не так-то просто, ибо всё написано на сравнительно маргинальной среде программирования Mozart/Oz в парадигме constraint programming. За это как раз автора сложно критиковать — задача уж очень специфическая. Я уже говорил, что полноценный разбор тянет на NP-полную задачу. Автор же рассмотрел парсинг как constraint satisfaction problem: даны узлы графа и дан набор условий, ограничивающих рёбра. Требуется найти удовлетворяющий условиям граф. То есть задачу поставили в более общем виде, и в итоге было решено применить специализированный инструмент для такого рода вещей. Правильно сделали. Есть ещё кое-что, не хватающее лично мне, но об этом в следующий раз.

